Dieser Artikel wurde im Rahmen der Data Science Blogathon.
Überblick
wurden, Wahrheit? Wir gruppieren die Datenpunkte in 3 Gruppen aufgrund ihrer Ähnlichkeit oder Nähe.
Inhaltsverzeichnis
1.Einführung in K bedeutet
2.K bedeutet ++ Algorithmus
3.Wie wählt man den K-Wert in K bedeutet?
4.Praktische Überlegungen im mittleren K
5.Cluster-Trend
1. Einführung
Lassen Sie uns einfach die Gruppierung von K-Means anhand von Beispielen aus dem täglichen Leben verstehen. Wir wissen, dass heutzutage jeder gerne Webserien oder Filme auf Amazon Prime sieht, Netflix. Haben Sie jemals etwas beobachtet, wenn Sie Netflix öffnen?? nämlich, Gruppenfilme basierend auf ihrem Genre, nämlich, Verbrechen, ausgesetzt, etc., Ich hoffe ihr habt es beobachtet oder wisst es schon. Die Netflix-Genregruppierung ist also ein leicht verständliches Beispiel für die Gruppierung. Lassen Sie uns mehr über k verstehen, bedeutet Clustering-Algorithmus.
Definition: Gruppieren Sie Datenpunkte basierend auf ihrer Ähnlichkeit oder Nähe zueinander, in einfachen Worten, der Algorithmus muss die Datenpunkte finden, deren Werte einander ähnlich sind und, Daher, diese Punkte würden zur selben Gruppe gehören.
Dann, Wie findet der Algorithmus die Werte zwischen zwei Punkten, um sie zu gruppieren?? Der Algorithmus findet die Werte mit der Methode 'Distanzmessung'. hier ist das Entfernungsmaß 'Euklidische Distanz’
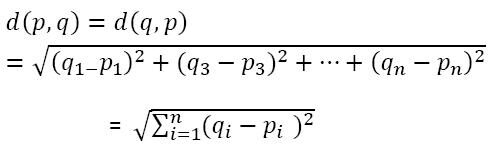
Beobachtungen, die einander am nächsten oder ähnlicher sind, haben einen geringen euklidischen Abstand und werden dann gruppiert.
Eine weitere Formel, die Sie kennen müssen, um die Mittelwerte von K zu verstehen, ist "Centroid".. Der k-Means-Algorithmus verwendet das Konzept des Schwerpunkts, um „k Gruppen“ zu erstellen..
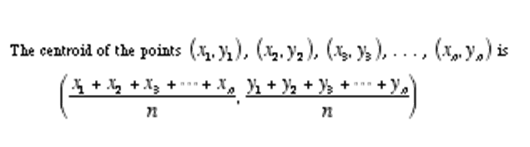
Jetzt sind Sie also bereit, die Schritte des k-Means-Clustering-Algorithmus zu verstehen.
Schritte in K-Mittel:
paso 1: wähle den k-Wert für ex: k = 2
paso 2: Schwerpunkte zufällig initialisieren
Paso 3: Berechnen Sie den euklidischen Abstand von den Zentroiden zu jedem Datenpunkt und bilden Sie Gruppen, die nahe an den Zentroiden liegen
paso 4: finde den Schwerpunkt jeder Gruppe und aktualisiere die Schwerpunkte
paso: 5 Schritt wiederholen 3
Jedes Mal, wenn Gruppen gebildet werden, Schwerpunkte aktualisieren, der aktualisierte Schwerpunkt ist der Mittelpunkt aller Punkte, die in die Gruppe fallen. Dieser Vorgang wird fortgesetzt, bis sich der Schwerpunkt nicht mehr ändert., nämlich, die Lösung konvergiert.
Sie können mit dem K-Means-Algorithmus herumspielen, indem Sie den folgenden Link verwenden, Versuch es.
https://stanford.edu/class/engr108/visualizations/kmeans/kmeans.html
Dann, Was kommt als nächstes? Wie wählt man die Anfangsschwerpunkte zufällig aus??
Hier kommt das Konzept des k-Means-Algorithmus ++.
2. Algorithmus K-Means ++:
Ich werde dich deswegen nicht stressen, Also mach dir keine Sorgen. Es ist sehr leicht zu verstehen. Dann, Was ist k-means ++ ??? Nehmen wir an, wir möchten zunächst zwei Schwerpunkte auswählen (k = 2), Sie können einen Schwerpunkt zufällig auswählen oder einen der Datenpunkte zufällig auswählen. Einfache Wahrheit? Unsere nächste Aufgabe besteht darin, einen anderen Schwerpunkt zu wählen, Wie wählt man es aus? irgendwelche Ideen?
Wir wählen den nächsten Schwerpunkt der Datenpunkte, der weit vom vorhandenen Schwerpunkt entfernt ist, oder denjenigen, der weit von einer bestehenden Gruppe entfernt ist und eine hohe Wahrscheinlichkeit hat, erfasst zu werden.
3.So wählen Sie den K-Wert in K-means:
1.Ellbogenmethode
Schritte:
Paso 1: Clustering-Algorithmus für verschiedene Werte von k . berechnen.
zum Beispiel k =[1,2,3,4,5,6,7,8,9,10]
paso 2: für jedes k, Berechne die Summe der Quadrate innerhalb des Clusters (WCSS).
Paso 3: Zeichnen Sie die WCSS-Kurve gemäß der Anzahl der Cluster.
Paso 4: Die Lage der Kurve auf dem Diagramm wird im Allgemeinen als Indikator für die ungefähre Anzahl von Clustern angesehen.
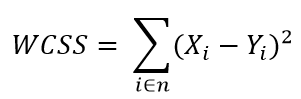
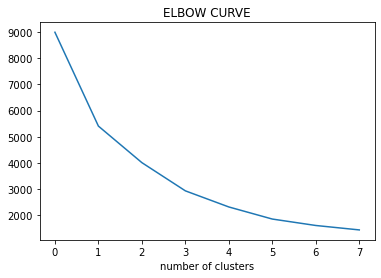
Praktische Überlegungen in K-Mitteln:
- Eine Reihe von Clustern, die im Voraus ausgewählt wurden (K).
- Datenstandardisierung (skaliert).
- Kategoriale Daten (kann mit K-Modus gelöst werden).
- Einfluss von Schwerpunkten und anfänglichen Ausreißern.
5. Cluster-Trend:
Bevor Sie einen Clustering-Algorithmus auf die gegebenen Daten anwenden, Es ist wichtig zu überprüfen, ob die angegebenen Daten einige signifikante Cluster aufweisen oder nicht. Der Prozess zur Auswertung der Daten, um zu überprüfen, ob die Daten für das Clustering geeignet sind oder nicht, wird als „Clustering-Trend“ bezeichnet., Daher sollten wir die Gruppierungsmethode nicht blind anwenden und den Gruppierungstrend überprüfen. Wie?
Wir verwenden die 'Hopkins-Statistik’ um zu wissen, ob Clustering für einen bestimmten Datensatz durchgeführt werden soll oder nicht. Untersuchen Sie, ob sich Datenpunkte signifikant von Daten unterscheiden, die im mehrdimensionalen Raum gleichmäßig verteilt sind.
Damit ist unser Artikel über den k-Means-Clustering-Algorithmus abgeschlossen.. In meinem nächsten Artikel, Ich werde über die Python-Implementierung des K-Means-Clustering-Algorithmus sprechen.
Vielen Dank!
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





