Einführung
„Wenn du mit einem Mann in einer Sprache sprichst, die er versteht, es geht ihm zu Kopf. Wenn du mit ihm in seiner eigenen Sprache sprichst, wird dein Herz erreichen “. – Nelson Mandela
Die Schönheit der Sprache überwindet Grenzen und Kulturen. Das Erlernen einer anderen Sprache als unserer Muttersprache ist ein großer Vorteil. Aber der Weg zur Zweisprachigkeit, oder Mehrsprachigkeit, es kann oft lang und endlos sein.
Es gibt so viele kleine Nuancen, dass wir uns im Meer der Worte verlieren. Aber trotzdem, Mit Online-Übersetzungsdiensten ist vieles einfacher geworden (Ich schaue auf Google Übersetzer!).
Ich wollte schon immer eine andere Sprache als Englisch lernen. Ich habe versucht Deutsch zu lernen (o Deutsch) In 2014. Es hat Spaß gemacht und war eine Herausforderung. Ich musste endlich aufgeben, aber ich hegte den Wunsch, neu anzufangen.

Schneller Vorlauf zu 2019, Ich habe das Glück, einen Sprachübersetzer für jedes mögliche Sprachpaar bauen zu können. Was für ein großer Vorteil die Verarbeitung natürlicher Sprache war!!
In diesem Artikel, Wir besprechen die Schritte zur Erstellung eines Übersetzungsmodells für die deutsche Sprache in die englische Sprache mit Keras. Im Nachhinein werfen wir auch einen kurzen Blick auf die Geschichte der maschinellen Übersetzungssysteme..
Dieser Artikel setzt Vertrautheit mit RNN voraus, LSTM und Keras. Unten sind ein paar Artikel, um mehr darüber zu erfahren:
Inhaltsverzeichnis
- Automatische Übersetzung: eine kurze Geschichte
- Problembeschreibung verstehen
- Einführung in die Sequenz-für-Sequenz-Vorhersage
- Implementierung in Python mit Keras
Automatische Übersetzung: eine kurze Geschichte
Die meisten von uns wurden mit der maschinellen Übersetzung vertraut gemacht, als Google den Dienst einführte. Aber das Konzept gibt es schon seit Mitte des letzten Jahrhunderts.
Forschungsarbeiten in der maschinellen Übersetzung (MT) begann bereits im Jahrzehnt von 1950, hauptsächlich in den USA. Diese frühen Systeme basierten auf riesigen zweisprachigen Wörterbüchern, handcodierte Regeln und universelle Prinzipien, die der natürlichen Sprache zugrunde liegen.
In 1954, IBM hat eine erste öffentliche Demonstration einer maschinellen Übersetzung durchgeführt. Das System hatte einen ziemlich kleinen Wortschatz von nur 250 Wörter und konnte nur übersetzen 49 ausgewählte russische Sätze ins Englische. Die Zahl scheint jetzt winzig zu sein, aber das System wird weithin als wichtiger Meilenstein im Fortschritt der maschinellen Übersetzung angesehen.

Dieses Bild stammt von Forschungsarbeit Beschreibung des IBM-Systems
Bald entstanden zwei Denkschulen:
- Empirische Trial-and-Error-Ansätze, mit statistischen Methoden, Ja
- Theoretische Ansätze unter Einbeziehung der sprachwissenschaftlichen Grundlagenforschung
In 1964, die Regierung der Vereinigten Staaten hat das Beratungskomitee für die automatische Sprachverarbeitung eingerichtet (ALPAC) um den Fortschritt der maschinellen Übersetzung zu bewerten. ALPAC bestand ein wenig und veröffentlichte im November einen Bericht 1966 auf MT-Status. Unten sind die Highlights dieses Berichts:
- Er äußerte ernsthafte Zweifel an der Machbarkeit der maschinellen Übersetzung und nannte sie verzweifelt.
- Von der Finanzierung der TM-Forschung wurde abgeraten
- Es war ein ziemlich deprimierender Bericht für Forscher, die auf diesem Gebiet arbeiten..
- Die meisten von ihnen haben das Feld verlassen und eine neue Karriere gestartet.
Nicht gerade eine begeisterte Empfehlung!!
Diesem unglücklichen Bericht folgte eine lange Dürreperiode. Schließlich, In 1981, ein neues System namens WETTER-System in Kanada für die Übersetzung der auf Französisch veröffentlichten Wettervorhersagen ins Englische eingesetzt. Es war ein ziemlich erfolgreiches Projekt, das in Betrieb blieb, bis 2001.
Das weltweit erste Web-Übersetzungstool, Babel Fisch, wurde von der Suchmaschine AltaVista unter gestartet 1997.
Und dann kam der Durchbruch, den wir alle kennen: Google Übersetzer. Seit damals, hat unsere Arbeitsweise verändert (und wir haben sogar gelernt) mit verschiedenen Sprachen.
Quelle: translate.google.com
Problembeschreibung verstehen
Gehen wir zurück zu dem Punkt, an dem wir im Einführungsabschnitt aufgehört haben, nämlich, Deutsch lernen. Aber trotzdem, Dieses Mal werde ich meine Maschine diese Aufgabe erledigen lassen. Ziel ist es, einen deutschen Satz mit Hilfe eines neuronalen maschinellen Übersetzungssystems in sein englisches Pendant umzuwandeln. (NMT).

Wir verwenden Daten aus deutsch-englischen Satzpaaren aus http://www.manythings.org/anki/. Sie können es herunterladen von hier.
Einführung in die Sequenz-für-Sequenz-Modellierung (Seq2Seq)
Sequenz-zu-Sequenz-Modelle (seq2seq) werden für eine Vielzahl von NLP-Aufgaben verwendet, als Textzusammenfassung, Spracherkennung, DNA-Sequenzmodellierung, unter anderem. Unser Ziel ist es, vorgegebene Sätze von einer Sprache in eine andere zu übersetzen.
Hier, Eingabe und Ausgabe sind Phrasen. Mit anderen Worten, Diese Sätze sind eine Folge von Wörtern, die in ein Muster hinein- und wieder herausgehen. Dies ist die Grundidee der Sequence-by-Sequence-Modellierung.. Die folgende Abbildung versucht diese Methode zu erklären.
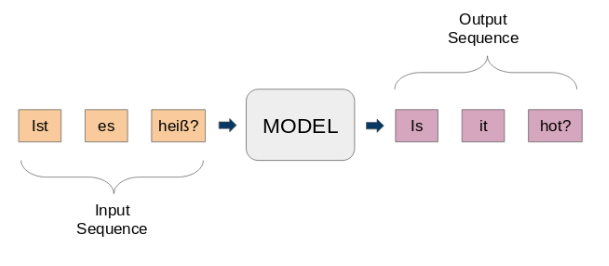
Ein typisches seq2seq-Modell hat 2 Hauptbestandteile:
ein) ein Encoder
B) ein Decoder
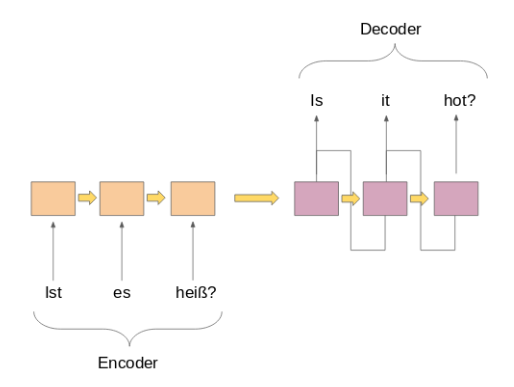
Beide Teile sind im Wesentlichen zwei verschiedene Modelle rekurrenter neuronaler Netze (RNN) in einem riesigen Netzwerk vereint:
Nachfolgend habe ich einige wichtige Anwendungsfälle der Sequenz-für-Sequenz-Modellierung aufgelistet (abgesehen von maschineller Übersetzung, Natürlich):
- Spracherkennung
- Entitätsextraktion / Betreffname, um das Hauptthema eines Textkörpers zu identifizieren
- Beziehungsklassifizierung zum Beschriften von Beziehungen zwischen mehreren Entitäten, die im vorherigen Schritt beschriftet wurden
- Chatbot-Fähigkeiten, um Konversationsfähigkeiten zu haben und mit Kunden zu interagieren
- Textzusammenfassung, um eine prägnante Zusammenfassung einer großen Textmenge zu erstellen
- Frage-Antwort-Systeme
Implementierung in Python mit Keras
Zeit, uns die Hände schmutzig zu machen! Es gibt kein besseres Gefühl, als ein Thema zu lernen, indem man die Ergebnisse aus erster Hand sieht.. Wir werden unsere bevorzugte Python-Umgebung starten (Jupyter Notebook für mich) und wir machen uns an die Arbeit.
Importieren Sie die erforderlichen Bibliotheken
Import-String
Importieren
aus numpy import array, argmax, willkürlich, nehmen
Pandas als pd importieren
von keras.models importieren Sequential
aus keras.layers importieren dicht, LSTM, Einbettung, Vektor wiederholen
aus keras.preprocessing.text import Tokenizer
aus keras.callbacks importieren ModelCheckpoint
aus keras.preprocessing.sequence import pad_sequences
aus keras.models import load_model
von keras Importoptimierern
import matplotlib.pyplot als plt
%matplotlib inline
pd.set_option('display.max_colwidth', 200)
Lesen Sie die Daten in unserer IDE
Unsere Daten sind eine Textdatei (.TXT) Englisch-Deutsche Satzpaare. Zuerst, Wir werden die Datei mit der unten definierten Funktion lesen.
# Funktion zum Lesen von Rohtextdateien
def read_text(Dateiname):
# öffne die Datei
Datei = öffnen(Dateiname, Modus="rt", Kodierung='utf-8')
# Alle Texte lesen
text = file.read()
Datei.schließen()
Rückgabetext
Lassen Sie uns eine weitere Funktion definieren, um den Text in englisch-deutsche Paare zu unterteilen, die durch getrennt sind ‘ n'. Später, wir werden diese Paare in englische Sätze und deutsche Sätze aufteilen, beziehungsweise.
# einen Text in Sätze aufteilen
def to_lines(Text):
sends = text.strip().Teilt('n')
sendet = [Ich teile('T') für ich in sends]
Rücksendungen
Jetzt können wir diese Funktionen verwenden, um den Text in einem Array in unserem gewünschten Format zu lesen.
data = read_text("deu.txt")
deu_eng = to_lines(Daten)
deu_eng = array(deu_eng)
Die tatsächlichen Daten enthalten mehr als 150.000 Satzpaare. Aber trotzdem, wir werden nur das erste verwenden 50,000 Satzpaare, um die Trainingszeit des Modells zu verkürzen. Sie können diese Zahl entsprechend der Rechenleistung Ihres Systems ändern (Oder wenn Sie Glück haben!).
deu_eng = deu_eng[:50000,:]
Textvorverarbeitung
Ein sehr wichtiger Schritt in jedem Projekt, vor allem im NLP. Die Daten, mit denen wir arbeiten, sind oft unstrukturiert, Es gibt also einige Dinge, um die wir uns kümmern müssen, bevor wir zum Gebäudeteil des Modells übergehen.
(ein) Textreinigung
Schauen wir uns zuerst unsere Daten an. Dies hilft uns bei der Entscheidung, welche Vorverarbeitungsschritte erforderlich sind.
deu_eng
Array([['Hi.', 'Hallo!'],
['Hi.', 'Grüß Gott!'],
['Lauf!', 'Lauf!'],
...,
['Mary hat sehr langes Haar.', 'Maria hat sehr langes Haar.'],
["Mary ist Toms Sekretärin.", 'Maria ist Toms Sekretärin.'],
['Mary ist eine verheiratete Frau.', 'Maria ist eine verheiratete Frau.']],
dtyp="<U380")
Wir werden die Satzzeichen entfernen und dann den gesamten Text in Kleinbuchstaben umwandeln.
# Satzzeichen entfernen
deu_eng[:,0] = [übersetzen(p.maketrans('', '', Zeichenfolge.Interpunktion)) für s in deu_eng[:,0]]
deu_eng[:,1] = [übersetzen(p.maketrans('', '', Zeichenfolge.Interpunktion)) für s in deu_eng[:,1]]
deu_eng
Array([['Hi', 'Hallo'],
['Hi', 'Grüß Gott'],
['Lauf', 'Lauf'],
...,
[„Mary hat sehr lange Haare“, 'Maria hat sehr langes Haar'],
["Mary ist Toms Sekretärin", 'Maria ist Toms Sekretärin'],
[„Mary ist eine verheiratete Frau“, 'Maria ist eine verheiratete Frau']],
dtyp="<U380")
# Text in Kleinbuchstaben umwandeln
für mich in Reichweite(len(deu_eng)):
deu_eng[ich,0] = deu_eng[ich,0].untere()
deu_eng[ich,1] = deu_eng[ich,1].untere()
deu_eng
Array([['Hi', 'hallo'],
['Hi', 'grüß gott'],
['Lauf', 'lauf'],
...,
["Mary hat sehr lange Haare", 'maria hat sehr langes haar'],
["Mary ist Toms Sekretärin", 'maria ist toms sekretärin'],
[„Mary ist eine verheiratete Frau“, 'maria ist eine verheiratete frau']],
dtyp="<U380")
(B) Konvertieren von Text in eine Sequenz
Ein Seq2Seq-Modell erfordert, dass wir sowohl Eingabe- als auch Ausgabesätze in ganzzahlige Sequenzen fester Länge umwandeln.
Aber bevor du das tust, visualisieren wir die Länge der Sätze. Wir erfassen die Länge aller Sätze in zwei separaten Listen für Englisch und Deutsch, beziehungsweise.
# leere Listen
ger_l = []
deu_l = []
# fülle die Listen mit Satzlängen aus
für ich in deu_eng[:,0]:
ger_l.append(len(Ich teile()))
für ich in deu_eng[:,1]:
deu_l.append(len(Ich teile()))
length_df = pd.DataFrame({'ger':ger_l, 'es gab':deu_l})
length_df.hist(Behälter = 30)
plt.zeigen()
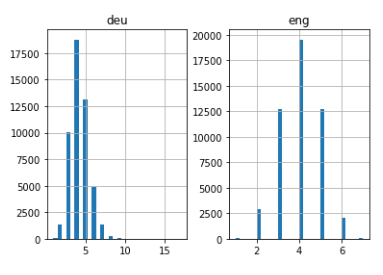
Ganz intuitiv: die maximale Satzlänge im Deutschen beträgt 11 und das der Sätze im Englischen ist 8.
Dann, Vektorisieren Sie unsere Textdaten mit Keras Tokenizador () Klasse. Es wird unsere Sätze in Folgen ganzer Zahlen umwandeln. Dann können wir diese Folgen mit Nullen auffüllen, um alle Folgen gleich lang zu machen.
Bitte beachten Sie, dass wir Tokenizer für die Sätze in Deutsch und Englisch vorbereiten:
# Funktion zum Erstellen eines Tokenizers
def Tokenisierung(Linien):
Tokenisierer = Tokenisierer()
tokenizer.fit_on_texts(Linien)
Tokenisierer zurückgeben
# Bereiten Sie den englischen Tokenizer vor
eng_tokenizer = Tokenisierung(deu_eng[:, 0])
eng_vocab_size = len(eng_tokenizer.word_index) + 1
ger_länge = 8
drucken('Größe des englischen Wortschatzes: %D' % eng_vocab_size)
Größe des englischen Wortschatzes: 6453
# Bereiten Sie den deutschen Tokenizer vor
deu_tokenizer = Tokenisierung(deu_eng[:, 1])
deu_vocab_size = len(deu_tokenizer.word_index) + 1
deu_length = 8
drucken('Deutsche Wortschatzgröße: %D' % deu_vocab_size)
Größe des deutschen Vokabulars: 10998
Der folgende Codeblock enthält eine Funktion zur Vorbereitung der Sequenzen. Es führt auch Sequence Padding bis zu einer maximalen Satzlänge durch, wie oben erwähnt.
# Sequenzen codieren und auffüllen
def encode_sequences(Tokenisierer, Länge, Linien):
# integer encode sequences
seq = tokenizer.texts_to_sequences(Linien)
# Pad-Sequenzen mit 0 values
seq = pad_sequences(seq, maxlen=Länge, padding='post')
Zurück seq
Bau des Modells
Jetzt werden wir die Daten in Trainings- und Test-Set für das Modelltraining und die Evaluierung aufteilen, beziehungsweise.
aus sklearn.model_selection import train_test_split # Daten in Zug- und Testset aufteilen Bahn, test = train_test_split(deu_eng, test_size=0.2, random_state = 12)
Zeit, die Sätze zu codieren. Wir werden codieren Sätze in deutscher Sprache als Eingabesequenzen Ja Englische Sätze als Zielsequenzen. Dies sollte sowohl für den Zug als auch für die Testdatensätze erfolgen.
# Trainingsdaten vorbereiten trainX = encode_sequences(deu_tokenizer, deu_länge, Bahn[:, 1]) trainY = encode_sequences(eng_tokenizer, ger_länge, Bahn[:, 0]) # Validierungsdaten vorbereiten testX = encode_sequences(deu_tokenizer, deu_länge, Prüfung[:, 1]) testY = encode_sequences(eng_tokenizer, ger_länge, Prüfung[:, 0])
Jetzt kommt der spannende Teil!
Wir beginnen mit der Definition unserer Seq2Seq-Modellarchitektur:
- Für den Encoder, Wir werden eine Keying-Schicht und eine LSTM-Schicht verwenden
- Für Decoder, wir werden einen weiteren LSTM-Mantel verwenden, gefolgt von einem dichten Mantel

Modellarchitektur
# NMT-Modell bauen
def define_model(in_vocab,out_vocab, in_timesteps,out_timesteps,Einheiten):
Modell = Sequentiell()
model.add(Einbettung(in_vocab, Einheiten, input_length=in_timesteps, mask_zero=Wahr))
model.add(LSTM(Einheiten))
model.add(Vektor wiederholen(out_timesteps))
model.add(LSTM(Einheiten, return_sequences=Wahr))
model.add(Dicht(out_vocab, Aktivierung='Softmax'))
Rückgabemodell
Wir verwenden den RMSprop-Optimierer für dieses Modell, da es normalerweise eine gute Option ist, wenn mit rekurrenten neuronalen Netzen gearbeitet wird.
# Modellzusammenstellung model = define_model(deu_vocab_size, eng_vocab_size, deu_länge, ger_länge, 512)
rms = Optimizers.RMSprop(lr=0,001) model.compile(Optimierer=rms, Verlust="spärliche_kategoriale_Kreuzentropie")
Bitte beachten Sie, dass wir verwendet haben ‘spärliche_kategoriale_Kreuzentropie'Als Verlustfunktion. Dies liegt daran, dass die Funktion es uns ermöglicht, die Zielsequenz unverändert zu verwenden, anstelle des heißen codierten Formats. Die Hot-Codierung der Zielsequenzen mit einem so großen Vokabular könnte den gesamten Speicher unseres Systems verbrauchen.
Wir sind bereit, unser Modell zu trainieren!
Wir schulen Sie während 30 mal und mit einer Losgröße von 512 mit einer Validierungsabteilung der 20%. Das 80% der Daten werden verwendet, um das Modell zu trainieren und der Rest, um es auszuwerten. Sie können diese Hyperparameter ändern und damit spielen.
Wir werden auch die ModellCheckpoint () Funktion zum Speichern des Modells mit dem geringsten Validierungsverlust. Ich persönlich bevorzuge diese Methode dem frühen Stopp.
Dateiname="model.h1.24_jan_19"
checkpoint = ModelCheckpoint(Dateiname, überwachen="Wertverlust", ausführlich=1, save_best_only=Wahr, Modus="Mindest")
# Zugmodell
Geschichte = model.fit(ZugX, trainY.reshape(trainY.shape[0], trainY.shape[1], 1),
Epochen=30, batch_size=512, validierung_split = 0.2,Rückrufe=[Kontrollpunkt],
ausführlich=1)
Vergleichen wir den Trainingsverlust und den Validierungsverlust.
plt.plot(Geschichte.Geschichte['Verlust']) plt.plot(Geschichte.Geschichte['val_loss']) plt.legende(['Bahn','Validierung']) plt.zeigen()
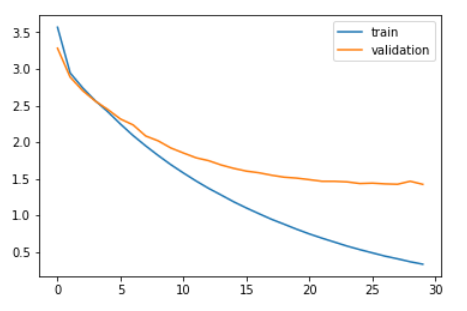
Wie Sie in der Grafik oben sehen können, der Validierungsverlust hörte nach auf, abzunehmen 20 Epochen.
Schließlich, wir können das gespeicherte Modell laden und Vorhersagen zu den unsichtbaren Daten machen: testX.
model = load_model('model.h1.24_jan_19')
preds = model.predict_classes(testX.reshape((testX.shape[0],testX.shape[1])))
Diese Vorhersagen sind Folgen von ganzen Zahlen. Wir müssen diese ganzen Zahlen in ihre entsprechenden Wörter umwandeln. Dazu definieren wir eine Funktion:
def get_word(n, Tokenisierer):
für Wort, index in tokenizer.word_index.items():
if index == n:
Rückgabewort
zurück
Vorhersagen in Text umwandeln (Englisch):
preds_text = []
für ich in preds:
Temperatur = []
für j im Bereich(len(ich)):
t = get_word(ich[J], eng_tokenizer)
wenn j > 0:
Wenn (t == get_word(ich[j-1], eng_tokenizer)) oder (t == Keine):
temp.anhängen('')
anders:
temp.append else:
Wenn(t == Keine):
temp.anhängen('')
anders:
temp.append
preds_text.append(' '.beitreten(temp))
Setzen wir die englischen Originalsätze in den Testdatensatz und die vorhergesagten Sätze in einen Datenrahmen:
pred_df = pd.DataFrame({'tatsächlich' : Prüfung[:,0], 'vorhergesagt' : preds_text})
Wir können nach dem Zufallsprinzip einige tatsächliche Instanzen im Vergleich zu den erwarteten ausdrucken, um zu sehen, wie unser Modell funktioniert:
# drucken 15 Reihen zufällig pred_df.sample(15)
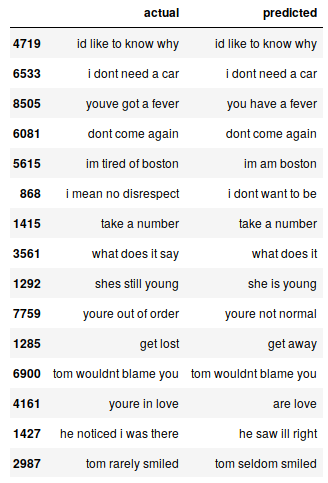
Unser Seq2Seq-Modell macht einen ordentlichen Job. Es gibt jedoch mehrere Fälle, in denen Sie Ihr Verständnis von Schlüsselwörtern verlieren. Zum Beispiel, es übersetzt “Ich habe Boston satt” von “Ich komme aus Boston”.
Dies sind die Herausforderungen, denen Sie im NLP regelmäßig begegnen werden. Aber das sind keine unbeweglichen Hindernisse. Wir können diese Herausforderungen mildern, indem wir mehr Trainingsdaten verwenden und ein besseres Modell erstellen. (oder komplexer).
Sie können auf den vollständigen Code von diesem Github zugreifen Repository.
Abschließende Anmerkungen
Selbst mit einem sehr einfachen Seq2Seq-Modell, die ergebnisse sind sehr ermutigend. Wir können diese Leistung leicht verbessern, indem wir ein komplexeres Codec-Modell für einen größeren Datensatz verwenden..
Ein weiteres Experiment, das mir einfällt, ist das Testen des seq2seq-Ansatzes an einem Datensatz, der längere Sätze enthält. Je mehr ich erlebe, mehr erfahren Sie über diesen riesigen und komplexen Raum.
Wenn Sie Kommentare zu diesem Artikel oder Fragen haben / Frage, Bitte teilen Sie es im Kommentarbereich unten.





