La source: https://www.serokell.io
Dans l'image ci-dessus, vous pouvez voir que les e-mails sont classés comme spam ou non. Ensuite, est un exemple de classement (classement binaire).
1. Régression logistique
2. Bayes ingénieux
3. Les voisins les plus proches
5. Arbre de décision
Nous verrons tous les algorithmes avec un petit code appliqué dans l'ensemble de données d'iris qui est utilisé pour les tâches de classification. L'ensemble de données a 150 instances (Lignes), 4 fonctionnalités (Colonnes) et ne contient aucune valeur nulle. Il y a 3 classes dans l'ensemble de données iris:
– Iris soyeux
– Iris Versicolor
– Iris Virginie
C'est un algorithme de classification très basique mais important en apprentissage automatique qui utilise une ou plusieurs variables indépendantes pour établir un résultat. La regresión logística intenta hallar la vinculación que mejor se ajuste entre la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... dependiente y un conjunto de variables independientes. La ligne la mieux ajustée dans cet algorithme ressemble à la forme S, como se muestra en la chiffre"Chiffre" est un terme utilisé dans divers contextes, De l’art à l’anatomie. Dans le domaine artistique, fait référence à la représentation de formes humaines ou animales dans des sculptures et des peintures. En anatomie, désigne la forme et la structure du corps. En outre, en mathématiques, "chiffre" Il est lié aux formes géométriques. Sa polyvalence en fait un concept fondamental dans de multiples disciplines.....
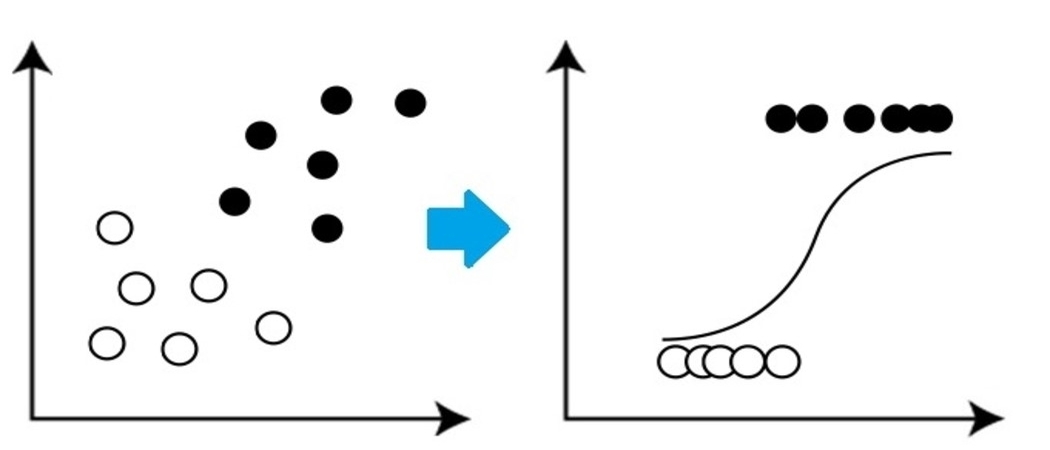
La source: https://www.equiskill.com
Avantages:
- C'est un algorithme très simple et efficace.
- Faible écart.
- Fournit probabilité note d'observation.
Les inconvénients:
- Mauvaise conduite un grand nombre de caractéristiques catégorielles.
- Supposons que les données sont exemptes de valeurs manquantes et que les prédicteurs sont indépendants les uns des autres.
Exemple:
à partir de sklearn.datasets importer load_iris à partir de sklearn.linear_model import LogisticRegression X, y = load_iris() LR_classifier = Régression Logistique(état_aléatoire=0) LR_classifier.fit(X, Oui) LR_classifier.predict(X[:3, :])
Production:
déployer([0, 0, 0]) il a prédit 0 classe pour tous 3 tests donnés pour prédire la fonction.
2. Bayes ingénieux
Naive Bayes se basa fr Théorème de Bayes ce qui donne une hypothèse d'indépendance entre les prédicteurs. Ce classificateur suppose que la présence d'une caractéristique particulière dans une classe n'est pas liée à la présence d'une autre
caractéristique / variable.
Les classificateurs Naive Bayes sont de trois types: Multinomial Naïf Bayes, Bernoulli Naïf Bayes, Bayes naïf gaussien.
Avantages:
- Cet algorithme fonctionne très rapidement.
- Il peut également être utilisé pour résoudre des problèmes de prédiction multi-classes., car c'est très utile avec eux.
- Este clasificador funciona mejor que otros modelos con menos datos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... si se mantiene el supuesto de independencia de las características.
Les inconvénients:
- Suppose
que toutes les fonctions sont indépendantes. Bien que cela puisse sembler bien dans
théorie, Mais dans la vraie vie, personne ne peut trouver un ensemble de caractéristiques indépendantes.
Exemple:
à partir de sklearn.datasets importer load_iris de sklearn.model_selection importer train_test_split de sklearn.naive_bayes importer GaussianNB X, y = load_iris(return_X_y=Vrai) X_train, X_test, y_train, y_test = train_test_split(X, Oui, taille_test=0.25, état_aléatoire=142) Naive_Bayes = GaussianNB() Naive_Bayes.fit(X_train, y_train) prédiction_résultats = Naive_Bayes.predict(X_test) imprimer(prédiction_résultats)
Production:
déployer([0, 1, 1, 2, 1, 1, 0, 0, 2, 1, 1, 1, 2, 0, 1, 0, 2, 1, 1, 2, 2, 1,0, 1, 2, 1, 2, 2, 0, 1, 2,
1, 2, 1, 2, 2, 1, 2])
Ce sont les classes prédites pour les données X_test par notre modèle naïf de Bayes.
3. Algorithme du voisin le plus proche K
Vous devez avoir entendu parler d'un dicton populaire:
« Oiseaux d'une plume volent ensemble. »
KNN fonctionne sur le même principe. Classer les nouveaux points de données en fonction de la classe de la plupart des points de données entre le voisin K, où K est le nombre de voisins à considérer. KNN capture l'idée de similitude (parfois appelé distance,
proximité ou proximité) avec quelques formules de distance mathématiques de base comme la distance euclidienne, distance de Manhattan, etc.

La source: https://www.javatpoint.com
Sélectionnez la valeur correcte pour K
Pour choisir le K approprié pour les données que vous souhaitez former, exécuter l'algorithme KNN plusieurs fois avec différentes valeurs K et choisir cette valeur K qui réduit le nombre d'erreurs dans les données invisibles.
Avantages:
- KNN est simple et facile à mettre en œuvre.
- Pas besoin de créer un modèle, ajustar varios paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... o hacer suposiciones adicionales como algunos de los otros algoritmos de clasificación.
- Peut être utilisé pour le classement, régression et recherche. Ensuite, c'est souple.
- El algoritmo se torna significativamente más lento a mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... que aumenta el número de ejemplos y / ou prédicteurs / variables indépendantes.
de sklearn.neighbors importer KNeighborsClassifier X_train, X_test, y_train, y_test = train_test_split(X, Oui, taille_test=0.25, état_aléatoire=142) knn = KNeighborsClassifier(n_voisins=3) knn.fit(X_train, y_train) prédiction_résultats = knn.predict(X_test[:5,:) imprimer(prédiction_résultats)
Production:
déployer([0, 1, 1, 2, 1]) Nous avons prédit nos résultats pour 5 exemples de lignes. On a donc 5 résultats dans le tableau.
4. SVM
SVM signifie Support Vector Machine. Il s'agit d'un algorithme d'apprentissage automatique supervisé qui est utilisé très fréquemment pour les défis de classification et de régression. Malgré cela, principalement utilisé dans les problèmes de classification. Le concept de base de Support Vector Machine et son fonctionnement peuvent être mieux compris avec cet exemple simple. Ensuite, imaginez que vous avez deux étiquettes: vert et bleu, et nos données ont deux caractéristiques: X Oui Oui. Nous voulons un classificateur qui, donné quelques (X, Oui) coordonnées, sorties si c'est vert O bleu. Tracez les données d'entraînement étiquetées sur un avion, puis essayez de trouver un avion (l'hyperplan des dimensions augmente) qui sépare très clairement les points de données des deux couleurs.

La source: https://www.javatpoint.com
Mais c'est le cas pour les données linéaires. Mais, Que faire si les données ne sont pas linéaires, puis utilisez l'astuce du noyau? Ensuite, pour gérer ça, aumentamos la dimension"Dimension" C’est un terme qui est utilisé dans diverses disciplines, comme la physique, Mathématiques et philosophie. Il s’agit de la mesure dans laquelle un objet ou un phénomène peut être analysé ou décrit. En physique, par exemple, On parle de dimensions spatiales et temporelles, alors qu’en mathématiques, il peut faire référence au nombre de coordonnées nécessaires pour représenter un espace. Sa compréhension est fondamentale pour l’étude et..., cela amène les données dans l'espace et maintenant les données deviennent linéairement séparables en deux groupes.
Avantages:
- SVM funciona relativamente bien cuando existe un claro margeLa marge est un terme utilisé dans divers contextes, comme la comptabilité, Économie et imprimerie. En comptabilité, fait référence à la différence entre les revenus et les coûts, qui permet d’évaluer la rentabilité d’une entreprise. Dans le domaine de l’édition, La marge est l’espace blanc autour du texte d’une page, qui le rend facile à lire et offre une présentation esthétique. Sa bonne gestion est essentielle.. de separación entre clases.
- SVM est plus efficace dans les grands espaces.
Les inconvénients:
- SVM ne convient pas aux grands ensembles de données.
- SVM ne fonctionne pas très bien lorsque le jeu de données a plus de bruit, En d'autres termes, lorsque les classes cibles se chevauchent. Ensuite, doit être manipulé.
Exemple:
de sklearn importer svm svm_clf = svm.SVC() X_train, X_test, y_train, y_test = train_test_split(X, Oui, taille_test=0.25, état_aléatoire=142) svm_clf.fit(X_train, y_train) prédiction_resultats = svm_clf.predict(X_test[:7,:]) imprimer(prédiction_résultats)
Production:
déployer([0, 1, 1, 2, 1, 1, 0])
5.Arbre de décision
L'arbre de décision est l'un des algorithmes d'apprentissage automatique les plus utilisés. Ils sont utilisés pour les problèmes de classification et de régression. Les arbres de décision imitent la pensée au niveau humain, il est donc très facile de comprendre les données et de faire de bonnes intuitions et interprétations. En réalité, vous faire voir la logique des données pour l'interpréter. Les arbres de décision ne sont pas comme les algorithmes de boîte noire comme SVM, les réseaux de neurones, etc.
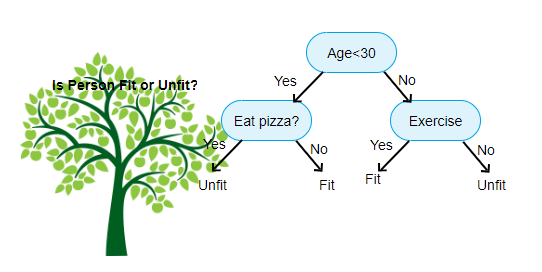
La source: https://www.aitimejournal.com
Par exemple, si nous classons une personne comme apte ou inapte, l'arbre de décision ressemble un peu à ceci dans l'image.
Ensuite, en résumé, un árbol de decisión es un árbol donde cada nœudNodo est une plateforme digitale qui facilite la mise en relation entre les professionnels et les entreprises à la recherche de talents. Grâce à un système intuitif, Permet aux utilisateurs de créer des profils, Partager des expériences et accéder à des opportunités d’emploi. L’accent mis sur la collaboration et le réseautage fait de Nodo un outil précieux pour ceux qui souhaitent élargir leur réseau professionnel et trouver des projets qui correspondent à leurs compétences et à leurs objectifs.... representa un
caractéristique / attribut, chaque branche représente une décision, une règle et chaque feuille représente un résultat. Ce résultat peut être de valeur catégorique ou continue. Catégorique en cas de classement et continu en cas d'applications de régression.
Avantages:
- Par rapport à d'autres algorithmes, les arbres de décision nécessitent moins d'efforts pour la préparation des données tout au long du prétraitement.
- Tampoco requieren la standardisationLa normalisation est un processus fondamental dans diverses disciplines, qui vise à établir des normes et des critères uniformes afin d’améliorer la qualité et l’efficacité. Dans des contextes tels que l’ingénierie, Formation et administration, La standardisation facilite la comparaison, Interopérabilité et compréhension mutuelle. Lors de la mise en œuvre des normes, La cohésion est favorisée et les ressources sont optimisées, qui contribue au développement durable et à l’amélioration continue des processus.... de datos ni el escalado.
- Le modèle développé dans l'arbre de décision est très intuitif et facile à expliquer à la fois aux équipes techniques et aux parties prenantes..
Les inconvénients:
- Si même une petite modification est apportée aux données, qui peut conduire à un grand changement dans la structure de l'arbre de décision provoquant une instabilité.
- Parfois, le calcul peut être beaucoup plus complexe par rapport à d'autres algorithmes.
- Les arbres de décision prennent généralement plus de temps pour entraîner le modèle.
Exemple:
à partir de l'arbre d'importation sklearn dtc = arbre.DecisionTreeClassifier() X_train, X_test, y_train, y_test = train_test_split(X, Oui, taille_test=0.25, état_aléatoire=142) dtc.fit(X_train, y_train) prédiction_résultats = dtc.predict(X_test[:7,:]) imprimer(prédiction_résultats)
Production:
déployer([0, 1, 1, 2, 1, 1, 0])
Remarques finales
Ceux-ci sont le 5 algorithmes de classement les plus populaires, il y a beaucoup plus et aussi des algorithmes avancés. Explorez-les plus loin. Connectons-nous LinkedIn
Merci d'avoir lu si vous êtes arrivé ici
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





