Vue d'ensemble
- Voici une liste des 10 Meilleurs articles publiés cette année par DataPeaker
- Les articles ont été triés par ordre décroissant, en fonction de vos avis.
- N'hésitez pas à ajouter d'autres articles dans la section des commentaires que vous pensez que la communauté devrait lire..
introduction
L'écriture est le meilleur moyen d'améliorer la rétention. Transformer vos apprentissages en vos propres mots ne conduit pas seulement à une meilleure compréhension, cela conduit aussi à une observation innée, ce qui à son tour renforce la curiosité.
En résumé, l'écriture élève votre processus d'apprentissage à des niveaux insondables.
L'écriture est au cœur des principes DataPeaker. Nous avons toujours essayé d'offrir le meilleur contenu possible et 2020 ce n'était pas différent pour nous. Plus que 500 articles publiés cette année, le voyage d'écriture ne s'arrête jamais pour nous.
Dans cet article, nous soulignons le 10 Articles les plus lus par la communauté Data Science sur notre blog, publié cette année.
Alors lançons le bal!
L'article le plus performant de notre blog est celui basé sur les questions les plus fondamentales que vous posez à un data scientist ou à un analyste de données lors d'un entretien..
“Combien de projets de science des données avez-vous terminés jusqu'à présent?”

La réponse fait la différence. La science des données n'est pas un domaine où la compréhension théorique vous aide à démarrer. Ce sont les projets que vous réalisez et la pratique que vous avez qui déterminent votre probabilité de succès.
Suivre des cours ou obtenir des certifications ne suffit pas. Presque tout le monde que nous connaissons est certifié dans divers aspects de la science des données. Vous n'ajoutez aucune valeur à votre CV si vous ne le combinez pas avec une expérience pratique.
Mais, Quel projet de science des données dois-je choisir? Chez DataPeaker, nous aimons collecter les meilleurs projets de science des données chaque mois et, dans cet article, Nous avons compilé les meilleurs projets de science des données open source pour le mois de juin 2020.
Tu peux le vérifier ici.
L'échelle caractéristique vous aide à convertir plusieurs variables qui ont une myriade d'unités de mesure, en kilogrammes, roupies, ans, etc., en mesures sans unité. Mais la question est de savoir quelle méthode de mise à l'échelle utiliser?
L'un des obstacles auxquels chaque data scientist est confronté est le dilemme de choisir entre la normalisation et la standardisation.. La plupart des cours ne se concentrent pas sur ce sujet. L'échelle des caractéristiques est l'une des étapes de prétraitement les plus importantes et jouer avec ce concept sans une connaissance appropriée peut conduire à un modèle inexact ou biaisé..
L'article explique également pourquoi certains modèles d'apprentissage automatique s'améliorent considérablement avec la mise à l'échelle des fonctionnalités, tandis que d'autres ne bougent même pas un peu.
Vous pouvez lire l'article ici.
« Quels sont les meilleurs outils pour effectuer des tâches de science des données ?? Et quel outil devrait toi ramasser en tant que nouveau venu dans la science des données? “

L'essence de l'article est couverte dans la question ci-dessus. Une fois que nous avons identifié ce qu'il faut apprendre à un niveau personnel, ou faire à un niveau professionnel avec les données, nous devons identifier les outils qui conviennent le mieux à la tâche. Cet article concerne l'identification du meilleur outil de réglage.
La science des données est un sujet très vaste et chaque spectre nécessite que les données soient traitées de manière unique.. Et puisque leurs modèles ont tendance à avoir un grand impact sur les décisions de l'organisation, il est vraiment important d'identifier les outils à utiliser.
L'article est divisé en 2 les pièces, le premier porte sur les outils pour gérer le Big Data en termes de volume, variété et rapidité. La partie suivante parle des outils pour la science des données en termes de: reporting et veille économique, modélisation prédictive et apprentissage automatique, intelligence artificielle.
Vous pouvez lire l'article ici.
2020 restera dans les livres d'histoire comme l'année qui a changé toute l'humanité. Chaque facette de la vie a été affectée par le Coronavirus et il était impératif que des personnes de tous les domaines se réunissent et contribuent à résoudre ce problème..
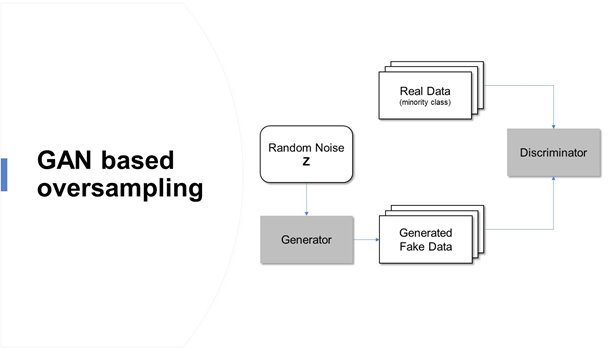
L'article couvre l'utilisation des réseaux contradictoires génératifs (GAN), une technique de suréchantillonnage des données Covid-19 biaisées en termes réels pour prédire le risque de mortalité. Cette histoire nous permet de mieux comprendre comment les étapes de préparation des données, comme gérer des données déséquilibrées, améliorera les performances de notre modèle.
Les données et le modèle central de cet article sont considérés à partir de l'étude récente (juillet de 2020) sur “Prédiction de la santé des patients COVID-19 à l'aide d'un algorithme de forêt aléatoire piloté” par Célestine Iwendi, Ali Kashif Bashir, Atharva Peshkar. et al. Cette étude a utilisé l'algorithme Random Forest alimenté par le modèle AdaBoost et a prédit la mortalité des patients individuels avec un 94% précision. Dans cet article, le même modèle et les mêmes paramètres de modèle ont été considérés pour analyser clairement l'amélioration de la précision du modèle existant en utilisant la technique de suréchantillonnage basée sur le GAN.
Vous pouvez lire l'article ici.
Pourquoi l'apprentissage en profondeur?
C'est une question parfaite. Nous sommes inondés d'algorithmes d'apprentissage automatique. Le comptage ne manque pas et tout type de données peut être résolu à l'aide de l'un de ces algorithmes.

En outre, les algorithmes d'apprentissage en profondeur nécessitent une grande puissance de calcul. Ensuite, Est-il nécessaire d'utiliser ces algorithmes?
Cet article témoigne de toutes les requêtes qui remettent en question la nécessité du deep learning et de ses réseaux de neurones, comme les réseaux de neurones convolutifs (CNN), réseaux de neurones récurrents (RNN), réseaux de neurones artificiels (ANN), etc. L'apprentissage profond remplace l'apprentissage automatique en termes de limites de décision et d'ingénierie des fonctionnalités.
Vous pouvez lire l'article ici.
Beaucoup d'entre nous ne connaissent toujours pas les différents domaines de l'industrie des données. Nous utilisons toujours ces termes de manière interchangeable et cela cause beaucoup de confusion lors de la communication.

Il y a une augmentation de la demande pour l'analyse commerciale et la science des données. La taille de son marché devrait atteindre $ 100 milliards et $ 140 mille millions, respectivement, à 2025. Donc, il est logique de comprendre ce que signifient réellement les deux domaines, vos responsabilités et quelles sont les similitudes qui conduisent à l'utilisation de ces termes de manière interchangeable.
Un DataPeaker, nous avons rencontré de nombreux professionnels de l'analytique en herbe qui souhaitent choisir “Analyse d'affaires” O “Science des données” comme carrière, mais ils ne sont même pas sûrs de la distinction entre ces deux rôles. Avant de plonger dans votre propre choix, vous devez être clair sur le chemin que vous voulez prendre, vérité? Cela pourrait être un choix déterminant pour votre carrière!!
Cet article explore les similitudes et les différences entre l'analyse commerciale et la science des données et essaie de vous donner une meilleure image.
Vous pouvez lire l'article ici.
Certaines des tâches les plus simples, comment joindre des tables, peut sembler compliqué en python. Cet article est un guide simple pour le collage 2 tables utilisant la bibliothèque pandas sans problèmes.
Notre 7ème article le plus performant vous aidera à comprendre les différents types de combinaisons dans Pandas:
- Join intérieur dans Pandas
- Participez pleinement à Pandas
- La gauche syndicale chez les pandas
- Rejoignez la droite dans Pandas
Vous pouvez lire l'article ici.

Ceci est le deuxième article d'un projet de science des données open source à apparaître sur cette liste. Nous considérons cela comme un signe clair que l'apprentissage n'est pas passé au second plan lorsqu'il s'agit d'aspirants à la science des données..
Cet article contenait les meilleurs projets de science des données open source pour le mois d'avril. La liste comprend-
- Convertissez n'importe quelle image en photo 3D
- Transformer une image en illustration de dessin animé
- Suivi d'objets multiples en une seule prise
- Jukebox de OpenAI: un modèle génératif pour la musique
- ShyNet: analyse Web sans cookies et respectueuse de la vie privée
- Manuel d'analyse du football
Vous pouvez lire l'article ici.

Le codage est une expérience très personnelle pour tout data scientist, analyste d'affaires, analyste de données ou tout programmeur.
Nous avons tous atteint un point dans notre parcours de codage où nous pensons qu'un outil particulier nuit à notre efficacité.. La raison peut varier de votre style de codage, votre position sur le parcours d'apprentissage ou toute autre raison qui rend l'outil incompatible pour vous.
C'est là qu'intervient l'identification du bon IDE.. Un IDE nous aide à écrire et exécuter du code Python pour l'analyse, science des données, développement de logiciels et une foule d'autres tâches. Il existe actuellement plusieurs IDE sur le marché, avec son propre ensemble de fonctionnalités, avantages et inconvénients.
Vous pouvez lire l'article ici.
Comment représentons-nous ces données de manière à aider notre équipe de direction ou nos décideurs à parvenir rapidement à un consensus ??
La réponse à la question ci-dessus est une visualisation concise. Vous ne pouvez pas créer un modèle dans Excel ou Python et espérer simplement que les parties prenantes comprennent les implications.

Excel est un leader du marché en matière d'EDA et de tâches de visualisation depuis plus de 35 ans. La plupart des entreprises lui font confiance, surtout les petits en raison de leurs caractéristiques.
Dans cet article, nous analysons les panneaux suivants:
- Suivi des ventes en ligne
- Analyse marketing
- Gestion de projets
- Suivi des revenus
- Gestion des ressources humaines
Vous pouvez lire l'article ici.
Remarques finales
L'année 2020 c'était un grand pas pour la communauté de l'apprentissage automatique. J'espère que ces articles sur la science des données vous seront utiles dans votre parcours d'apprentissage.. Faites-nous part de vos réflexions dans les commentaires ci-dessous..
Continue d'apprendre! Et n'arrête jamais d'écrire!





