introduction
Les données et les informations sur le Web augmentent de façon exponentielle. Aujourd'hui, nous utilisons tous Google comme première source de connaissances, soit pour trouver des avis sur un lieu pour comprendre un nouveau terme. Toutes ces informations sont déjà disponibles sur le web.
Avec la quantité de données disponibles sur le Web, ouvre de nouveaux horizons de possibilités pour une Data scientist. Je crois fermement que le web scraping est une compétence indispensable pour tout data scientist.. Dans le monde réel, toutes les données dont vous avez besoin sont déjà disponibles sur internet; la seule chose qui vous empêche de les utiliser est la possibilité d'y accéder. A l'aide de cet article, vous pouvez également surmonter cette barrière.
La plupart des données disponibles sur le Web ne sont pas disponibles. Il est présent dans un format non structuré (Format HTML) et ne peut pas être téléchargé. Donc, des connaissances et de l'expérience sont nécessaires pour utiliser ces données construire un modèle utile.
Dans cet article, Je vais vous guider à travers le processus de grattage Web dans R. Avec cet article, vous acquerrez de l'expérience en utilisant tout type de données disponibles sur Internet.
Table des matières
- Qu'est-ce que le grattage Web?
- Pourquoi avons-nous besoin de Web Scraping dans Science des données?
- Façons d'extraire des données
- Conditions préalables
- Racler une page Web avec R
- Analyser les données extraites du Web
1. Qu'est-ce que le grattage Web?
Le grattage Web est une technique pour convertir les données présentes dans un format non structuré (Balises HTML) sur le Web au format structuré qui peut être facilement accessible et utilisé.
Presque tous les principaux langages fournissent des moyens d'effectuer du grattage Web. Dans cet article, Nous utiliserons R pour extraire les données des longs métrages les plus populaires de 2016 du IMDb site Web.
Nous obtiendrons une série de fonctions pour chacun des 100 longs métrages populaires sortis en 2016. En outre, nous examinerons les problèmes les plus courants auxquels on peut être confronté lors de l'extraction de données d'Internet en raison d'un manque de cohérence sur le site Web. code et voir comment résoudre ces problèmes.
Si vous vous sentez plus à l'aise avec Python, Je vous recommanderai de lire ce guide pour commencer avec le web scraping avec Python.
2. Pourquoi avons-nous besoin de Web Scraping?
Je suis sûr que les premières questions qui ont dû vous venir à l'esprit jusqu'à présent sont “Pourquoi avons-nous besoin de web scraping”? Comme j'ai dit avant, les possibilités avec le web scraping sont immenses.
Pour vous donner des connaissances pratiques, extrayons les données de IMDB. Certaines autres applications possibles pour lesquelles vous pouvez utiliser le grattage Web sont:
- Extraction des données de classement des films pour créer des moteurs de recommandation de films.
- Extraire des données textuelles de Wikipédia et d'autres sources pour créer des systèmes basés sur la PNL ou former des modèles d'apprentissage en profondeur pour des tâches telles que la reconnaissance de sujet d'un texte donné.
- Extraire des données d'images taguées à partir de sites Web comme Google, Flickr, etc. pour entraîner des modèles de classification d'images.
- Collecte de données à partir de sites de réseaux sociaux tels que Facebook et Twitter pour effectuer des tâches d'analyse des sentiments, sondage d'opinion, etc.
- Extraire les opinions et commentaires des utilisateurs de sites de commerce électronique comme Amazon, Flipkart, etc.
3. Façons d'extraire des données
Il existe plusieurs façons d'extraire des données du Web. Certains des moyens populaires sont:
- Copier et coller des humains: Il s'agit d'un moyen lent et efficace d'extraire des données du Web. Cela implique que les humains eux-mêmes analysent et copient les données sur le stockage local.
- Correspondance de modèle de texte: Une autre approche simple mais puissante pour extraire des informations du Web consiste à utiliser les fonctions de correspondance d'expressions régulières des langages de programmation.. Vous pouvez en savoir plus sur les expressions régulières ici.
- API d'Interfaz: De nombreux sites comme Facebook, Twitter, LinkedIn, etc. fournir des API publiques et / ou privé qui peut être appelé en utilisant un code standard pour récupérer les données dans le format prescrit.
- Analyse DOM: Grâce à l'utilisation de navigateurs Web, les programmes peuvent récupérer le contenu dynamique généré par les scripts côté client. Il est également possible d'analyser des pages Web dans une arborescence DOM, selon les programmes qui peuvent récupérer des parties de ces pages.
Nous utiliserons l'approche d'analyse DOM tout au long de cet article.. Et comptez sur les sélecteurs CSS de la page Web pour trouver les champs pertinents qui contiennent les informations souhaitées. Mais avant de commencer, certaines conditions préalables sont nécessaires pour extraire avec compétence des données de n'importe quel site Web.
4. Exigences précédentes
Les prérequis pour effectuer du web scraping dans R sont divisés en deux groupes:
- Pour commencer avec le web scraping, doit avoir une connaissance pratique du langage R. Si vous débutez ou que vous souhaitez parfaire les bases, Je recommande fortement de suivre ce parcours d'apprentissage en R. Au cours de cet article, nous utiliserons le "package rvest"’ en R écrit par Hadley Wickham. Vous pouvez accéder à la documentation du package rvest ici. Assurez-vous que ce paquet est installé. Si vous n'avez pas encore ce pack, vous pouvez suivre le code ci-dessous pour l'installer.
install.paquets('veste')
- L'ajout de connaissances en HTML et CSS sera un bonus supplémentaire. L'une des meilleures sources que j'ai pu trouver pour apprendre le HTML et le CSS est est. J'ai observé que la plupart des data scientists ne sont pas très solides avec des connaissances techniques en HTML et CSS. Donc, Nous utiliserons un logiciel open source appelé Selector Gadget qui sera plus que suffisant pour que quiconque fasse du scraping Web. Vous pouvez accéder et télécharger l'extension Selector Gadget ici. Assurez-vous que cette extension est installée en suivant les instructions sur le site Web. J'ai fait la même chose. J'utilise Google Chrome et je peux accéder à l'extension dans la barre d'extension en haut à droite.
Avec ça, vous pouvez sélectionner les parties de n'importe quel site Web et obtenir les balises pertinentes pour accéder à cette partie simplement en cliquant sur cette partie du site Web. Veuillez noter qu'il s'agit d'un moyen d'apprendre le HTML et le CSS et de le faire manuellement. Mais pour maîtriser l'art du web scraping, Je vous recommande fortement d'apprendre HTML et CSS pour mieux comprendre et apprécier ce qui se passe sous le capot.
4. Racler une page web avec R
À présent, Commençons à chercher sur le site IMDb le 100 longs métrages les plus populaires sortis en 2016. Vous pouvez y accéder ici.
#Chargement du paquet rvest
une bibliothèque('veste')
#Spécification de l'url du site Web souhaité à gratter
URL <- 'http://www.imdb.com/search/title?compte=100&release_date=2016,2016&title_type=caractéristique'
#Lecture du code HTML du site
page Web <- lire_html(URL)
À présent, Nous extrairons les données suivantes de ce site Web.
- Rang: La gamme du film de 1 une 100 dans la liste des 100 films les plus populaires sortis en 2016.
- Qualification: Le titre du long métrage.
- La description: La description du long métrage.
- Temps d'exécution: La durée du long métrage.
- Genre: Le genre du long métrage,
- Classification: La cote IMDb du long métrage.
- Méta-score: Le metascore sur le site IMDb du long métrage.
- Votes: Votes en faveur du long métrage.
- Revenu_brut_en_milliers: La marge brute du long métrage en millions.
- Réalisateur: Le réalisateur principal du long métrage. Notez que, dans le cas de plusieurs administrateurs, je ne prendrai que le premier.
- Acteur: L'acteur principal du long métrage. Notez que, dans le cas de plusieurs acteurs, je ne prendrai que le premier.
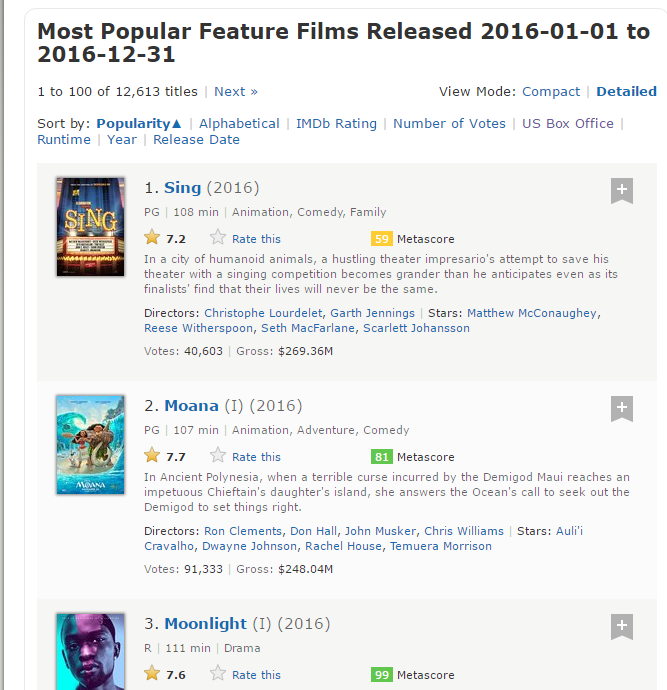
Voici une capture d'écran contenant comment tous ces champs sont organisés.
Paso 1: À présent, nous allons commencer par gratter le champ Range. Pour ça, nous utiliserons le gadget sélecteur pour obtenir les sélecteurs CSS spécifiques qui entourent les classifications. Vous pouvez cliquer sur l'extension dans votre navigateur et sélectionner le champ de tri avec votre curseur.
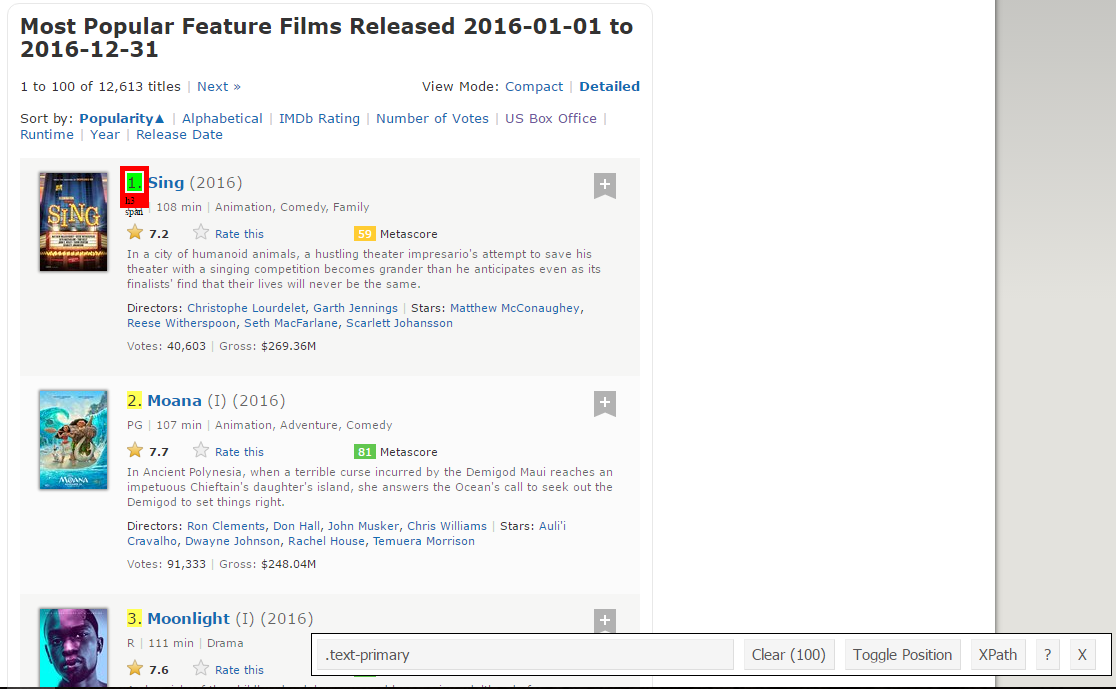
Assurez-vous que toutes les classifications sont sélectionnées. Vous pouvez sélectionner quelques sections de tri supplémentaires au cas où vous ne pourriez pas toutes les obtenir et vous pouvez également les désélectionner en cliquant sur la section sélectionnée pour vous assurer que vous n'avez que les sections en surbrillance que vous souhaitez gratter pour ce moment.. .
Paso 2: Une fois que vous êtes sûr d'avoir fait les bons choix, vous devez copier le sélecteur CSS correspondant que vous pouvez voir en bas au centre.
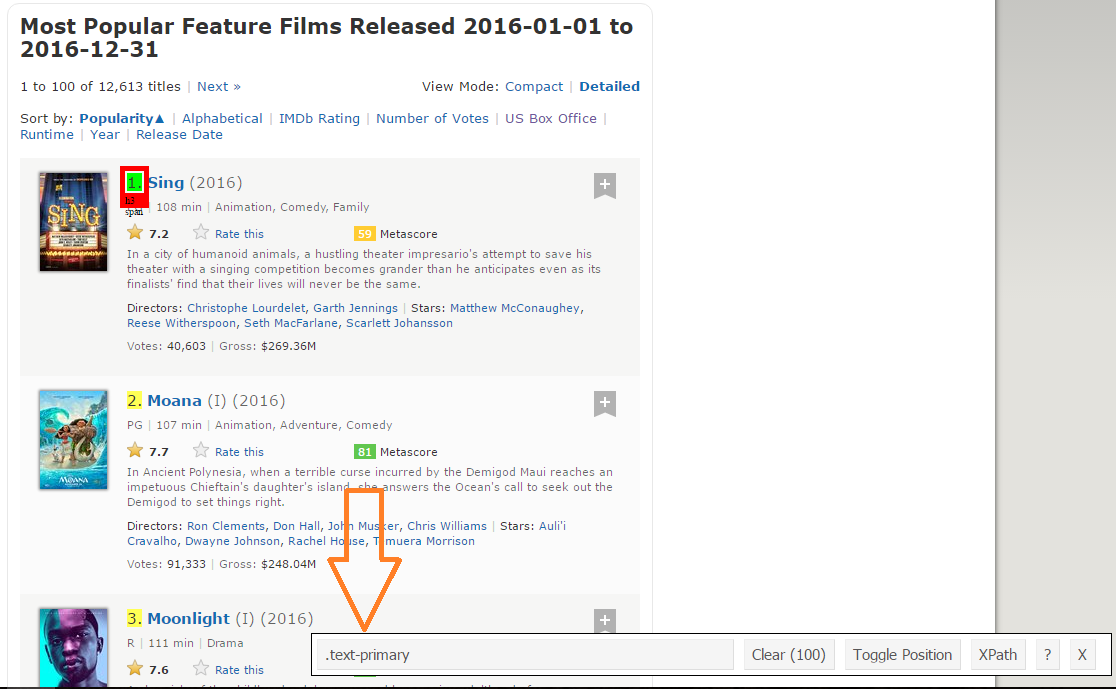
Paso 3: Une fois que vous connaissez le sélecteur CSS qui contient les classifications, vous pouvez utiliser ce simple code R pour obtenir toutes les notes:
#Utiliser des sélecteurs CSS pour gratter la section des classements rank_data_html <- html_nodes(page Web,'.text-primary') #Conversion des données de classement en texte rank_data <- html_texte(rank_data_html) #Regardons les classements diriger(rank_data) [1] "1." "2." "3." "4." "5." "6."
Paso 4: Une fois que vous avez les données, assurez-vous qu'ils ont l'air dans le format souhaité. Je prétraite mes données pour les convertir au format numérique.
#Prétraitement des données: Conversion des classements en chiffres rank_data<-as.numeric(rank_data) #Revoyons le classement diriger(rank_data) [1] 1 2 3 4 5 6
Paso 5: Vous pouvez maintenant effacer la section du sélecteur et sélectionner tous les titres. Vous pouvez inspecter visuellement que tous les titres sont sélectionnés. Effectuez les ajouts et suppressions nécessaires à l'aide de votre curseur. j'ai fait pareil ici.
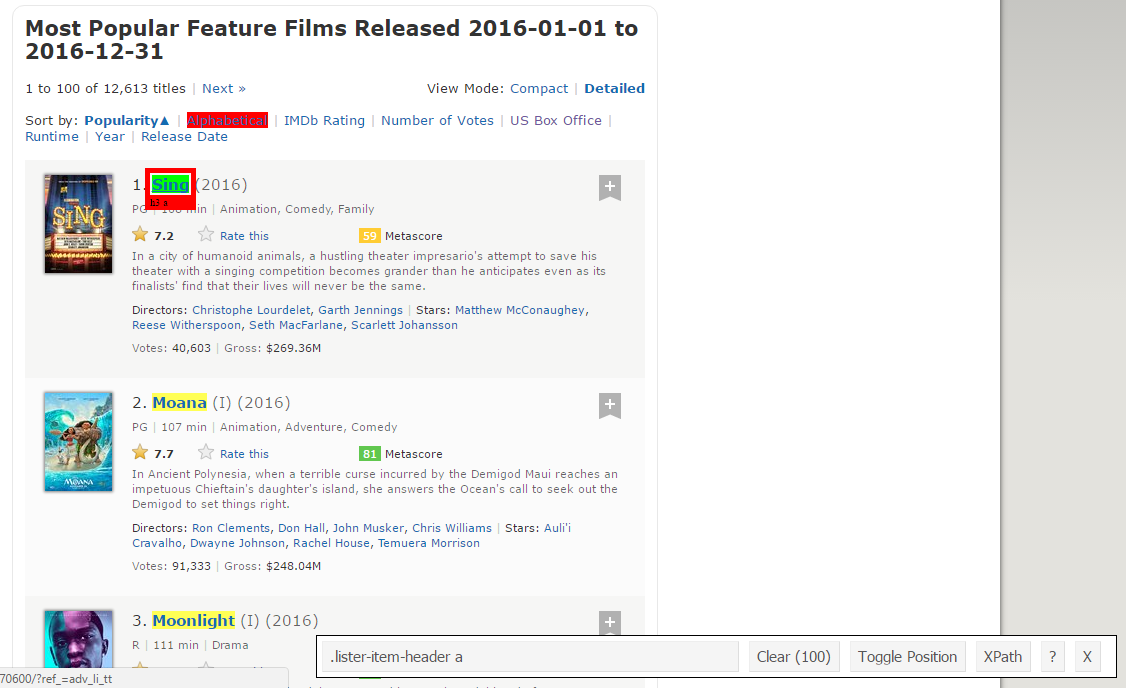
Paso 6: Encore, J'ai le sélecteur CSS correspondant pour les titres: .lister-item-header a. Je vais utiliser ce sélecteur pour gratter tous les titres en utilisant le code suivant.
#Utiliser des sélecteurs CSS pour gratter la section de titre title_data_html <- html_nodes(page Web,'.lister-item-header a') #Conversion des données du titre en texte title_data <- html_texte(title_data_html) #Regardons le titre diriger(title_data) [1] "Chanter" "Moana" "clair de lune" "Crête de scie à métaux" [5] "Passagers" "Trolls"
Paso 7: Dans le code suivant, j'ai fait la même chose pour le grattage: la description, temps d'exécution, le genre, qualification, métaponction, voix, revenu brut en milliers, données du réalisateur et de l'acteur.
#Utiliser des sélecteurs CSS pour gratter la section de description
description_data_html <- html_nodes(page Web,'.ratings-bar+ .text-muted')
#Conversion des données de description en texte
description_données <- html_texte(description_data_html)
#Regardons les données de description
diriger(description_données)
[1] "nDans une ville d'animaux humanoïdes, la tentative d'un imprésario de théâtre pressé de sauver son théâtre avec un concours de chant devient plus grandiose qu'il ne l'avait prévu, même si ses finalistes découvrent que leur vie ne sera plus jamais la même."
[2] "nEn Polynésie ancienne, quand une terrible malédiction encourue par le demi-dieu Maui atteint l'île de la fille d'un chef impétueux, elle répond à l'appel de l'océan pour rechercher le demi-dieu pour arranger les choses."
[3] "nUne chronique de l'enfance, l'adolescence et l'âge adulte naissant d'un jeune, Afro-américain, homme gay qui a grandi dans un quartier difficile de Miami."
[4] "Médecin de l'armée américaine nWWII Desmond T. Doss, qui a servi pendant la bataille d'Okinawa, refuse de tuer des gens, et devient le premier homme de l'histoire américaine à recevoir la Medal of Honor sans tirer un coup de feu."
[5] "nUn vaisseau spatial voyageant vers une planète colonie lointaine et transportant des milliers de personnes a un dysfonctionnement dans ses chambres à coucher. Par conséquent, deux passagers sont réveillés 90 ans plus tôt."
[6] "nAprès l'invasion du village des Trolls par les Bergens, Coquelicot, le Troll le plus heureux jamais né, et la curmudgeonly Branch partit en voyage pour sauver ses amis.
#Prétraitement des données: suppression de 'n'
description_données<-gsub("m","",description_données)
#Regardons à nouveau les données de description
diriger(description_données)
[1] "Dans une ville d'animaux humanoïdes, la tentative d'un imprésario de théâtre pressé de sauver son théâtre avec un concours de chant devient plus grandiose qu'il ne l'avait prévu, même si ses finalistes découvrent que leur vie ne sera plus jamais la même."
[2] "Dans l'ancienne Polynésie, quand une terrible malédiction encourue par le demi-dieu Maui atteint l'île de la fille d'un chef impétueux, elle répond à l'appel de l'océan pour rechercher le demi-dieu pour arranger les choses."
[3] "Une chronique de l'enfance, l'adolescence et l'âge adulte naissant d'un jeune, Afro-américain, homme gay qui a grandi dans un quartier difficile de Miami."
[4] "Médecin de l'armée américaine de la Seconde Guerre mondiale Desmond T. Doss, qui a servi pendant la bataille d'Okinawa, refuse de tuer des gens, et devient le premier homme de l'histoire américaine à recevoir la Medal of Honor sans tirer un coup de feu."
[5] "Un vaisseau spatial voyageant vers une planète colonie lointaine et transportant des milliers de personnes a un dysfonctionnement dans ses chambres à coucher. Par conséquent, deux passagers sont réveillés 90 ans plus tôt."
[6] "Après que les Bergens envahissent Troll Village, Coquelicot, le Troll le plus heureux jamais né, et la curmudgeonly Branch partit en voyage pour sauver ses amis."
#Utilisation de sélecteurs CSS pour gratter la section d'exécution du film
runtime_data_html <- html_nodes(page Web,'.text-muted .runtime')
#Conversion des données d'exécution en texte
runtime_data <- html_texte(runtime_data_html)
#Regardons le temps d'exécution
diriger(runtime_data)
[1] "108 min" "107 min" "111 min" "139 min" "116 min" "92 min"
#Prétraitement des données: suppression des minutes et conversion en numérique
runtime_data<-gsub(" min","",runtime_data)
runtime_data<-as.numeric(runtime_data)
#Jetons un autre regard sur les données d'exécution
diriger(runtime_data)
[1] 1 2 3 4 5 6
#Utiliser des sélecteurs CSS pour gratter la section Genre du film
genre_data_html <- html_nodes(page Web,'.genre')
#Conversion des données de genre en texte
genre_data <- html_texte(genre_data_html)
#Regardons le temps d'exécution
diriger(genre_data)
[1] "nAnimation, Comédie, Famille "
[2] "nAnimation, Aventure, Comédie "
[3] "nDrame "
[4] "nBiographie, Drame, Histoire "
[5] "nAventure, Drame, Romance "
[6] "nAnimation, Aventure, Comédie "
#Prétraitement des données: suppression m
genre_data<-gsub("m","",genre_data)
#Prétraitement des données: supprimer les espaces en excès
genre_data<-gsub(" ","",genre_data)
#ne prenant que le premier genre de chaque film
genre_data<-gsub(",.*","",genre_data)
#Conversation de chaque genre du texte au facteur
genre_data<-comme.facteur(genre_data)
#Jetons un autre regard sur les données de genre
diriger(genre_data)
[1] Animation Animation Drame Biographie Aventure Animation
10 Niveaux: Action Aventure Animation Biographie Comédie Crime Drame ... Polar
#Utiliser des sélecteurs CSS pour gratter la section d'évaluation IMDB
rating_data_html <- html_nodes(page Web,'.ratings-imdb-rating fort')
#Conversion des données d'évaluation en texte
cote_données <- html_texte(rating_data_html)
#Regardons les cotes
diriger(cote_données)
[1] "7.2" "7.7" "7.6" "8.2" "7.0" "6.5"
#Prétraitement des données: conversion des notes en numérique
cote_données<-as.numeric(cote_données)
#Jetons un autre coup d'œil aux données d'évaluation
diriger(cote_données)
[1] 7.2 7.7 7.6 8.2 7.0 6.5
#Utiliser des sélecteurs CSS pour gratter la section des votes
votes_data_html <- html_nodes(page Web,'.sort-num_votes-visible span:nième-enfant(2)')
#Conversion des données de votes en texte
votes_données <- html_texte(votes_data_html)
#Regardons les données des votes
diriger(votes_données)
[1] "40,603" "91,333" "112,609" "177,229" "148,467" "32,497"
#Prétraitement des données: suppression de virgules
votes_données<-gsub(",","",votes_données)
#Prétraitement des données: convertir les votes en nombres
votes_données<-as.numeric(votes_données)
#Jetons un autre regard sur les données des votes
diriger(votes_données)
[1] 40603 91333 112609 177229 148467 32497
#Utiliser des sélecteurs CSS pour gratter la section des réalisateurs
directeurs_données_html <- html_nodes(page Web,'.text-muted+ p a:nième-enfant(1)')
#Conversion des données du réalisateur en texte
directeurs_données <- html_texte(directeurs_données_html)
#Jetons un coup d'œil aux données des administrateurs
diriger(directeurs_données)
[1] "Christophe Lourdelet" "Ron Clément" "Barry Jenkins"
[4] "Mel Gibson" "Morten Tyldum" "Walt Dohrn"
#Prétraitement des données: convertir les données des directeurs en facteurs
directeurs_données<-comme.facteur(directeurs_données)
#Utiliser des sélecteurs CSS pour gratter la section des acteurs
acteurs_data_html <- html_nodes(page Web,'.lister-item-content .ghost+ a')
#Conversion des données brutes des acteurs en texte
acteurs_données <- html_texte(acteurs_data_html)
#Regardons les données des acteurs
diriger(acteurs_données)
[1] "Matthew McConaughey" "Auli'i Cravalho" "Mahershala Ali"
[4] "Andrew Garfield" "Jennifer Lawrence" "Anna Kendrick"
#Prétraitement des données: convertir les données des acteurs en facteurs
acteurs_données<-comme.facteur(acteurs_données)
Mais je veux que vous gardiez un œil attentif sur ce qui se passe lorsque je fais la même chose avec les données Metascore.
#Utiliser des sélecteurs CSS pour gratter la section metascore
metascore_data_html <- html_nodes(page Web,'.metascore')
#Conversion des données d'exécution en texte
metascore_data <- html_texte(metascore_data_html)
#Regardons le métascore
responsable des données(metascore_data)
[1] "59 " "81 " "99 " "71 " "41 "
[6] "56 "
#Prétraitement des données: suppression de l'espace supplémentaire dans le métascore
metascore_data<-gsub(" ","",metascore_data)
#Permet de vérifier la longueur des données de métascore
longueur(metascore_data)
[1] 96
Paso 8: La longueur des données de métascore est 96 pendant que nous récupérons les données de 100 films. La raison pour laquelle cela s'est produit est qu'il y a 4 films qui n'ont pas de champs Metascore correspondants.
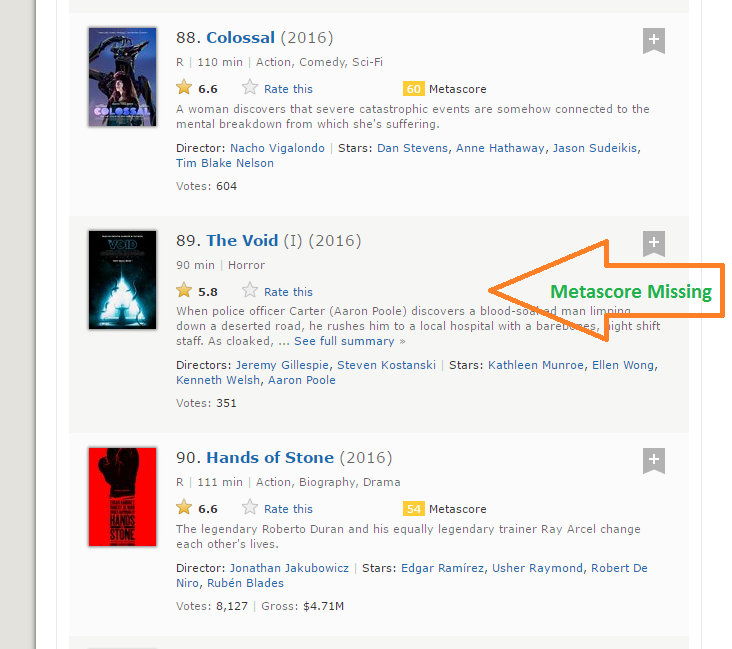
Paso 9: C'est une situation pratique qui peut survenir lors du grattage de n'importe quel site Web. Malheureusement, si nous ajoutons simplement NA au dernier 4 billets, NA sera attribué comme Metascore pour les films 96 une 100, alors qu'en réalité, les données sont manquantes pour certains autres films. Après une inspection visuelle, J'ai trouvé que le Metascore pour les films manquait 39, 73, 80 Oui 89. J'ai écrit la fonction suivante pour résoudre ce problème.
pour (je en c(39,73,80,89)){
une<-metascore_data[1:(i-1)]
b<-metascore_data[je:longueur(metascore_data)]
metascore_data<-ajouter(une,liste("N / A"))
metascore_data<-ajouter(metascore_data,b)
}
#Prétraitement des données: conversion du métascore en numérique
metascore_data<-as.numeric(metascore_data)
#Regardons à nouveau en détail les données du métascore
longueur(metascore_data)
[1] 100
#Regardons les statistiques récapitulatives
sommaire(metascore_data)
Min. 1Saint-Qu. Médiane Moyenne 3ème Qu. Max. Notre
23.00 47.00 60.00 60.22 74.00 99.00 4
Paso 10: La même chose se produit avec la variable Gross qui représente le revenu brut de ce film en millions. J'ai utilisé la même solution pour travailler à ma façon:
#Utiliser des sélecteurs CSS pour gratter la section des revenus bruts
gross_data_html <- html_nodes(page Web,'.ghost~ .text-muted+ span')
#Conversion des données de revenus bruts en texte
données_gross <- html_texte(gross_data_html)
#Regardons les données des votes
diriger(données_gross)
[1] "$269.36M" "$248.04M" "$27.50M" "$67.12M" "$99.47M" "$153.67M"
#Prétraitement des données: suppression des signes '$' et 'M'
données_gross<-gsub("M","",données_gross)
données_gross<-sous-chaîne(données_gross,2,6)
#Vérifions la longueur des données brutes
longueur(données_gross)
[1] 86
#Remplir les entrées manquantes avec NA
pour (je en c(17,39,49,52,57,64,66,73,76,77,80,87,88,89)){
une<-données_gross[1:(i-1)]
b<-données_gross[je:longueur(données_gross)]
données_gross<-ajouter(une,liste("N / A"))
données_gross<-ajouter(données_gross,b)
}
#Prétraitement des données: conversion brut en numérique
données_gross<-as.numeric(données_gross)
#Regardons à nouveau la longueur des données brutes
longueur(données_gross)
[1] 100
sommaire(données_gross)
Min. 1Saint-Qu. Médiane Moyenne 3ème Qu. Max. Notre
0.08 15.52 54.69 96.91 119.50 530.70 14
Paso 11: Nous avons maintenant réussi à supprimer le 11 fonctions de 100 films les plus populaires sortis en 2016. Combinons-les pour créer un bloc de données et inspecter sa structure.
#Combiner toutes les listes pour former un bloc de données films_df<-trame de données(Rang = rank_data, Titre = title_data, Description = description_data, Runtime = runtime_data, Genre = genre_data, Note = note_données, Metascore = metascore_data, Votes = votes_data, Gross_Earning_in_Mil = gross_data, Directeur = directeurs_données, Acteur = acteurs_données) #Structure de la trame de données str(films_df) 'trame de données': 100 obs. de 11 variables: $ Rang : sur une 1 2 3 4 5 6 7 8 9 10 ... $ Titre : Facteur avec 99 niveaux "10 Voie Cloverfield",..: 66 53 54 32 58 93 8 43 97 7 ... $ La description : Facteur avec 100 niveaux "19-Billy Lynn, un an, est ramené à la maison pour une tournée de victoire après une bataille déchirante en Irak. À travers des flashbacks, le film montre ce que"| __tronqué__,..: 57 59 3 100 21 33 90 14 13 97 ... $ Durée : sur une 108 107 111 139 116 92 115 128 111 116 ... $ Genre : Facteur avec 10 niveaux "action","Aventure",..: 3 3 7 4 2 3 1 5 5 7 ... $ Évaluation : sur une 7.2 7.7 7.6 8.2 7 6.5 6.1 8.4 6.3 8 ... $ Méta-score : sur une 59 81 99 71 41 56 36 93 39 81 ... $ Votes : sur une 40603 91333 112609 177229 148467 ... $ Gross_Earning_in_Mil: sur une 269.3 248 27.5 67.1 99.5 ... $ Réalisateur : Facteur avec 98 niveaux "Andrew Stanton",..: 17 80 9 64 67 95 56 19 49 28 ... $ Acteur : Facteur avec 86 niveaux "Aaron Eckhart",..: 59 7 56 5 42 6 64 71 86 3 ...
Vous avez maintenant gratté avec succès le site Web IMDb pour le 100 longs métrages les plus populaires sortis en 2016.
6. Analyser les données extraites du Web
Une fois que vous avez les données, peut effectuer diverses tâches comme analyser les données, faire des déductions à partir d'eux, former des modèles d'apprentissage automatique sur ces données, etc. J'ai continué à créer une visualisation intéressante à partir des données que nous venons d'extraire. Suivez les visualisations et répondez aux questions ci-dessous. Postez vos réponses dans la section commentaire ci-dessous.
une bibliothèque('ggplot2')
qplot(données = films_df,Durée,remplir = Genre,bacs = 30)
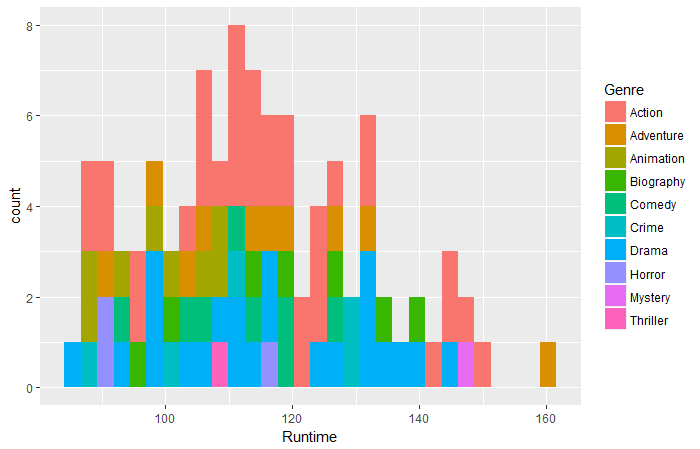
Question 1: Selon les données ci-dessus, Quel film de quel genre a eu la durée la plus longue?
ggplot(films_df,aes(x=Durée d'exécution,y=Note))+ geom_point(aes(taille = voix,col=Genre))
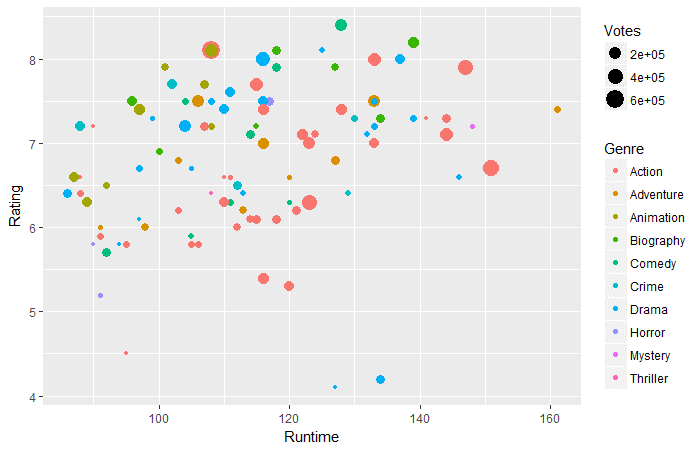
Question 2: Selon les données ci-dessus, à l'exécution de 130-160 minutes, Quel genre a les votes les plus élevés?
ggplot(films_df,aes(x=Durée d'exécution,y=Gross_Earning_in_Mil))+ geom_point(aes(taille = évaluation,col=Genre))
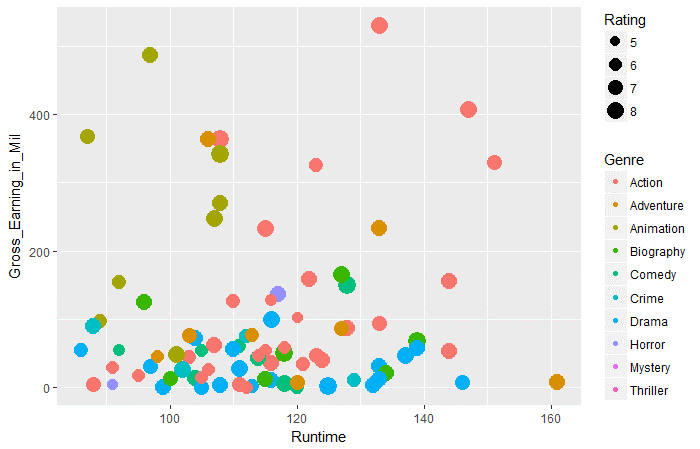
Question 3: Selon les données ci-dessus, dans tous les genres, quel genre a les revenus bruts moyens les plus élevés au moment de l'exécution de 100 une 120.
Remarques finales
Je pense que cet article vous aurait donné une compréhension complète du grattage Web dans R. À présent, vous avez également une idée précise des problèmes que vous pourriez rencontrer et comment vous pouvez les résoudre. Comme la plupart des données sur le Web sont présentes dans un format non structuré, le web scraping est une compétence très utile pour tout data scientist.
En outre, vous pouvez poster les réponses aux trois questions ci-dessus dans la section commentaire ci-dessous. Avez-vous aimé lire cet article? Partagez vos opinions avec moi. Si vous avez des doutes / question, n'hésitez pas à l'envoyer ci-dessous.





