A l'ère du Big Data, Python est devenu le langage le plus recherché. Dans cet article, Concentrons-nous sur un aspect particulier de Python qui en fait l'un des langages de programmation les plus puissants: multitraitement.
À présent, avant de plonger dans l'essentiel du multitraitement, Je vous propose de lire mon précédent article sur le Threading en Python, car il peut fournir un meilleur contexte pour l'article actuel.
Supposons que vous soyez un élève du primaire auquel on a confié la tâche ardue de multiplier 1200 paires de nombres comme devoirs. Supposons que vous puissiez multiplier une paire de nombres dans 3 secondes. Alors, en tout, besoin 1200 * 3 = 3600 secondes, Qu'est que c'est 1 le temps de résoudre tous les devoirs. Mais vous devez rattraper votre émission de télévision préférée sur 20 minutes.
Que ferais tu? Un étudiant intelligent, bien que malhonnête, appelez trois autres amis qui ont une capacité similaire et divisez la tâche. Ensuite, vous aurez 250 tâches de multiplication dans votre assiette, que vous compléterez dans 250 * 3 = 750 secondes, c'est-à-dire, 15 minutes. Donc, toi, avec son autre 3 copains, terminera la tâche dans 15 minutes, donnant 5 minutes de temps pour prendre une collation et s'asseoir pour regarder votre émission de télévision. La tâche n'a pris que 15 minutes quand 4 d'entre vous ont travaillé ensemble, qu'est-ce qui aurait autrement pris 1 temps.
C'est l'idéologie de base du multitraitement. Si vous avez un algorithme qui peut être divisé en différents travailleurs (processeurs), alors vous pouvez accélérer le programme. Aujourd'hui, les machines sont livrées avec 4,8 Oui 16 noyaux, qui peut ensuite être mis en œuvre en parallèle.
Traitement multiple en science des données
Le multitraitement a deux applications cruciales en science des données.
1. Processus d'E/S
Tout pipeline gourmand en données a des processus d'entrée et de sortie où des millions d'octets de données circulent dans tout le système. Comme d'habitude, le processus de lecture (entrée) des données ne prendra pas longtemps, mais le processus d'écriture des données dans les magasins de données prend beaucoup de temps. Le processus d'écriture peut se faire en parallèle, gagner beaucoup de temps.
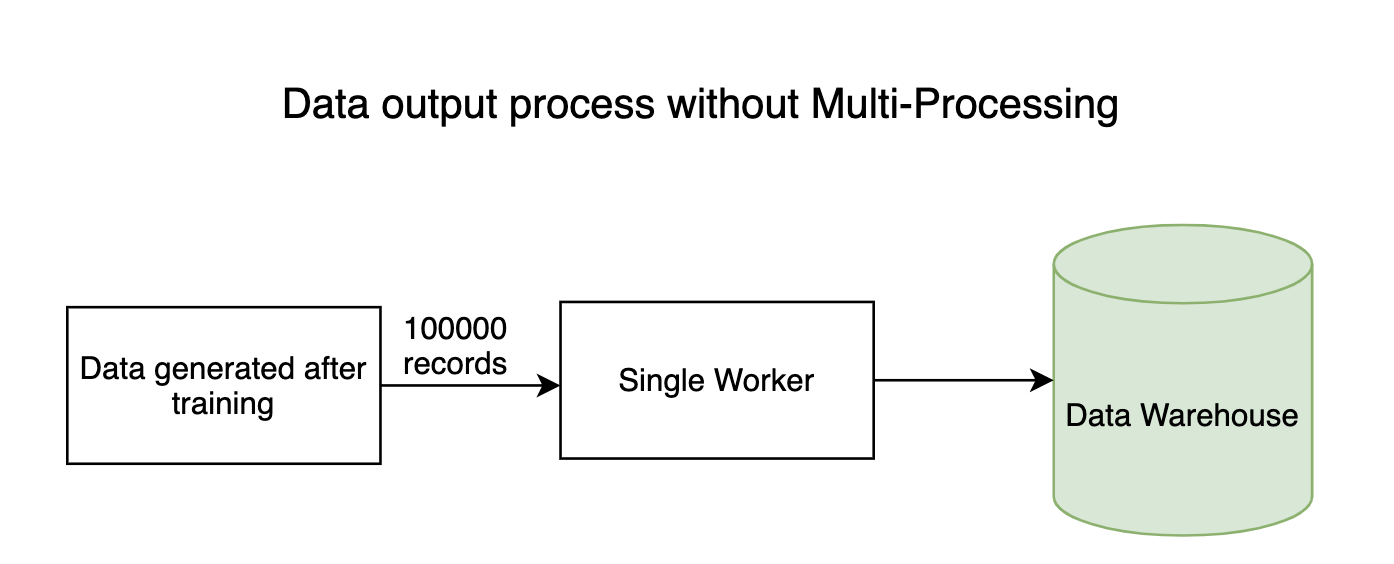
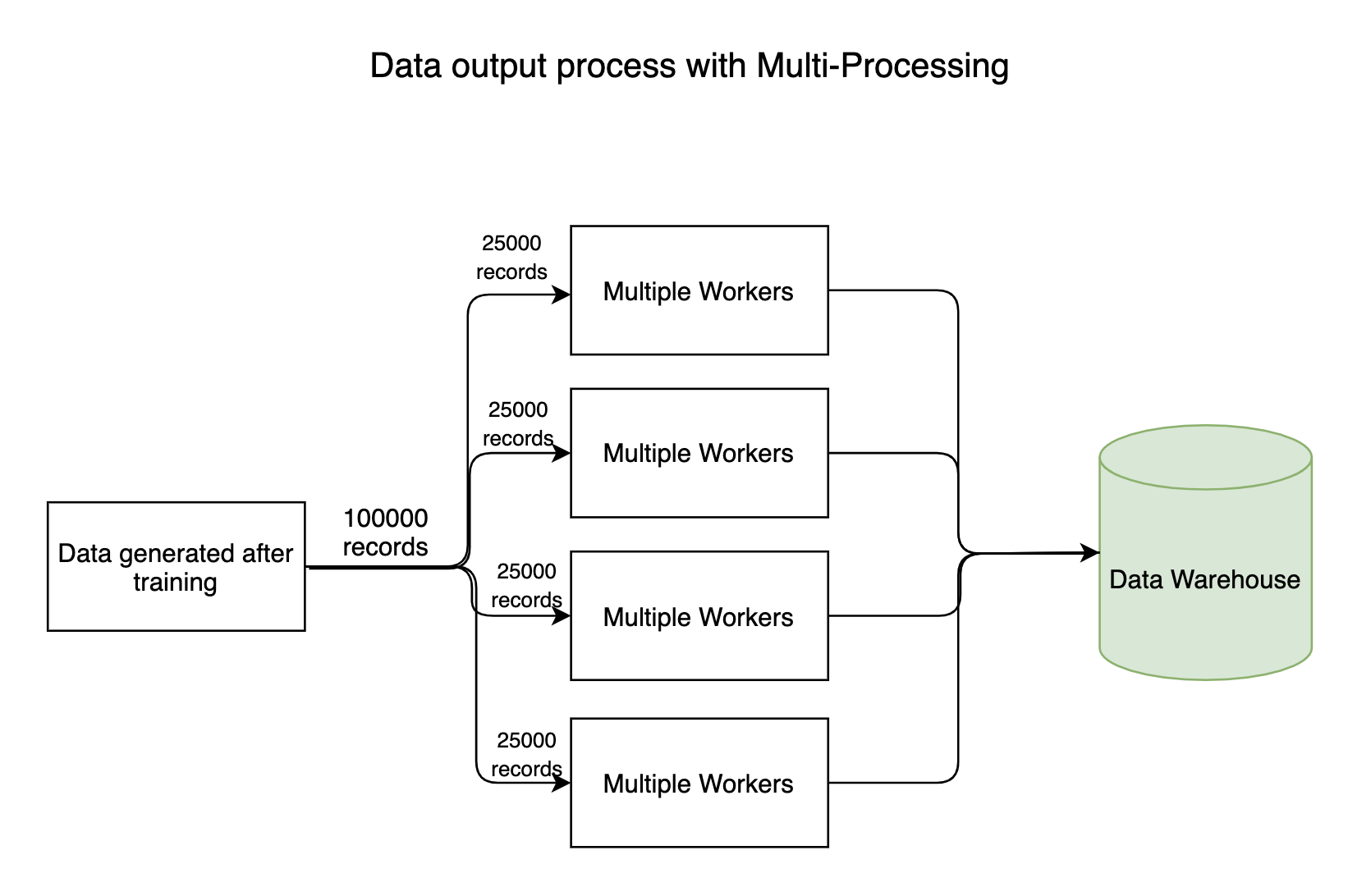
2. Modèles de formation
Bien que tous les modèles ne puissent pas être entraînés en parallèle, pocos modelos tienen características inherentes que les permitan entrenarse mediante el procesamiento en paraleloEl procesamiento en paralelo es una técnica que permite ejecutar múltiples operaciones simultáneamente, dividiendo tareas complejas en subtareas más pequeñas. Esta metodología optimiza el uso de recursos computacionales y reduce el tiempo de procesamiento, siendo especialmente útil en aplicaciones como el análisis de grandes volúmenes de datos, simulaciones y renderización gráfica. Su implementación se ha vuelto esencial en sistemas de alto rendimiento y en la computación moderna..... Par exemple, l'algorithme Random Forest implémente plusieurs arbres de décision pour prendre une décision cumulative. Ces arbres peuvent être construits en parallèle. En réalité, l'API sklearn est livrée avec un paramètre appelé n_emplois, qui offre la possibilité d'utiliser plusieurs travailleurs.
Traitement multiple en Python à l'aide Traiter classe-
Maintenant mettons la main dessus multiprocessus bibliothèque Python.
Jetez un oeil au code suivant
heure d'importation
def sleepy_man():
imprimer('Commencer à dormir')
le sommeil de temps(1)
imprimer('Fini de dormir')
tic = heure.heure()
sleepy_man()
sleepy_man()
toc = heure.heure()
imprimer('Fait en {:.4F} secondes'.format(toc-tic))
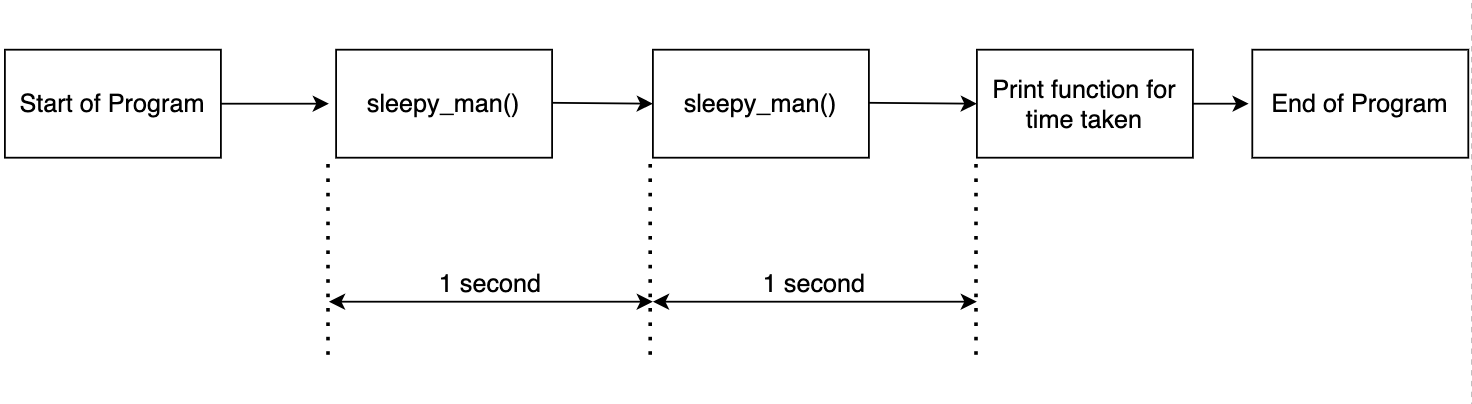
Le code ci-dessus est simple. La fonction sleepy_man dormir une seconde et nous appelons la fonction deux fois. Nous enregistrons le temps requis pour les deux appels de fonction et imprimons les résultats. La sortie est comme indiqué ci-dessous.
Commencer à dormir Fini de dormir Commencer à dormir Fini de dormir Fait en 2.0037 secondes
Ceci est attendu car nous appelons la fonction deux fois et enregistrons le temps. Le flux est montré dans le diagramme suivant.
Incorporons maintenant le multitraitement dans le code.
importer le multitraitement heure d'importation
def sleepy_man():
imprimer('Commencer à dormir')
le sommeil de temps(1)
imprimer('Fini de dormir')
tic = heure.heure()
p1 = multitraitement.Process(cible = sleepy_man)
p2 = multitraitement.Processus(cible = sleepy_man)
p1.start()
p2.start()
toc = heure.heure()
imprimer('Fait en {:.4F} secondes'.format(toc-tic))
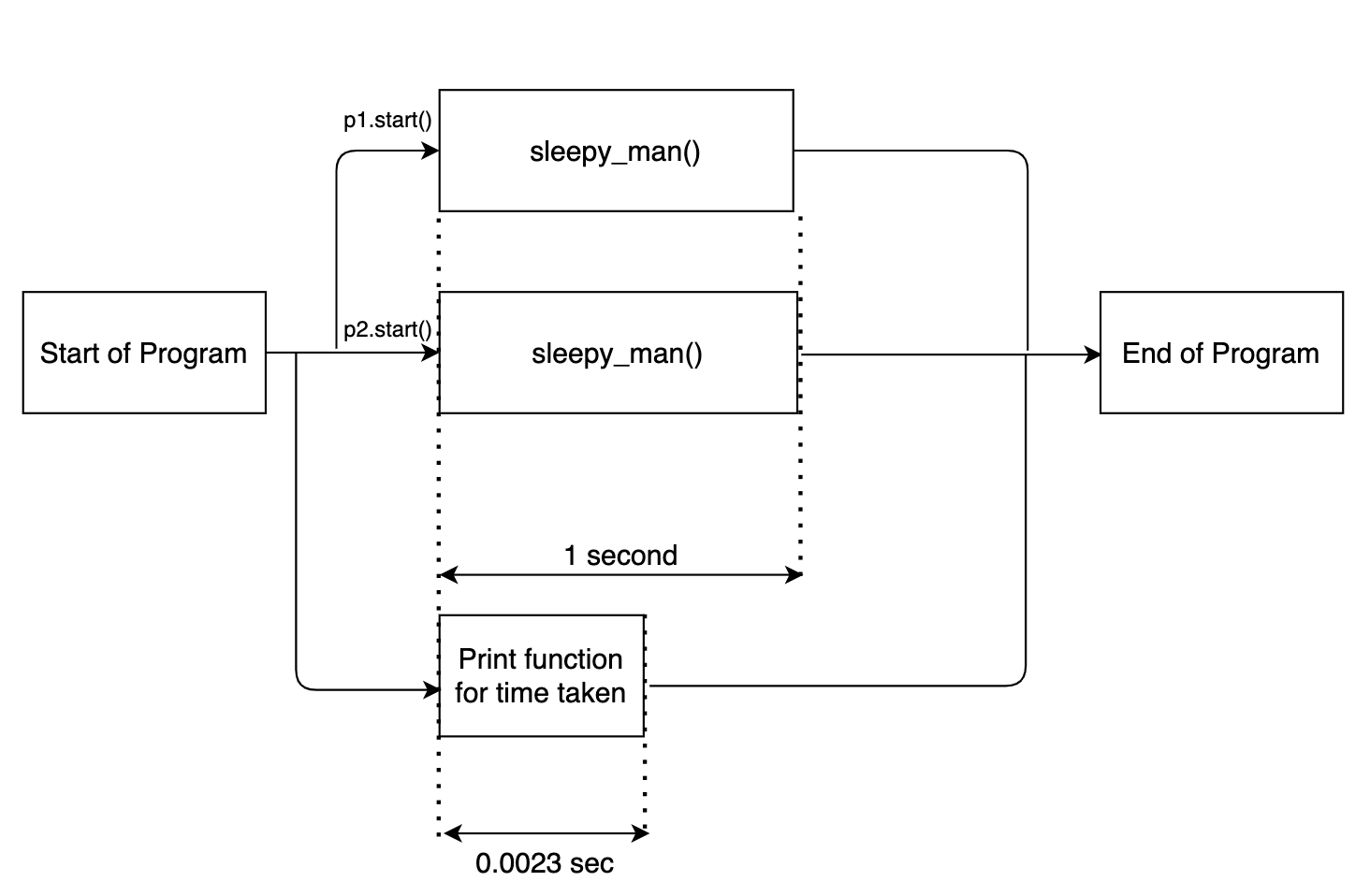
Ici multitraitement.processus (cible = sleepy_man) définit une instance multithread. Nous passons la fonction requise à exécuter, sleepy_man, comme argument. Nous activons les deux instances en p1.start ().
La sortie est la suivante:
Fait en 0.0023 secondes Commencer à dormir Commencer à dormir Fini de dormir Fini de dormir
Maintenant remarque une chose. L'instruction d'impression d'horodatage a été exécutée en premier. Ceci est dû au fait, ainsi que les instances multithread activées pour le sleepy_man une fonction, le code principal de la fonction a été exécuté séparément en parallèle. L'organigramme ci-dessous clarifiera les choses.
Pour exécuter le reste du programme après l'exécution des fonctions multithread, nous devons exécuter la fonction entrer().
importer le multitraitement
heure d'importation
def sleepy_man():
imprimer('Commencer à dormir')
le sommeil de temps(1)
imprimer('Fini de dormir')
tic = heure.heure()
p1 = multitraitement.Process(cible = sleepy_man)
p2 = multitraitement.Processus(cible = sleepy_man)
p1.start()
p2.start()
p1.joindre()
p2.joindre()
toc = heure.heure()
imprimer('Fait en {:.4F} secondes'.format(toc-tic))
À présent, le reste du bloc de code ne sera exécuté qu'une fois les tâches de multitraitement terminées. La sortie est montrée ci-dessous.
Commencer à dormir Commencer à dormir Fini de dormir Fini de dormir Fait en 1.0090 secondes
L'organigramme est présenté ci-dessous.
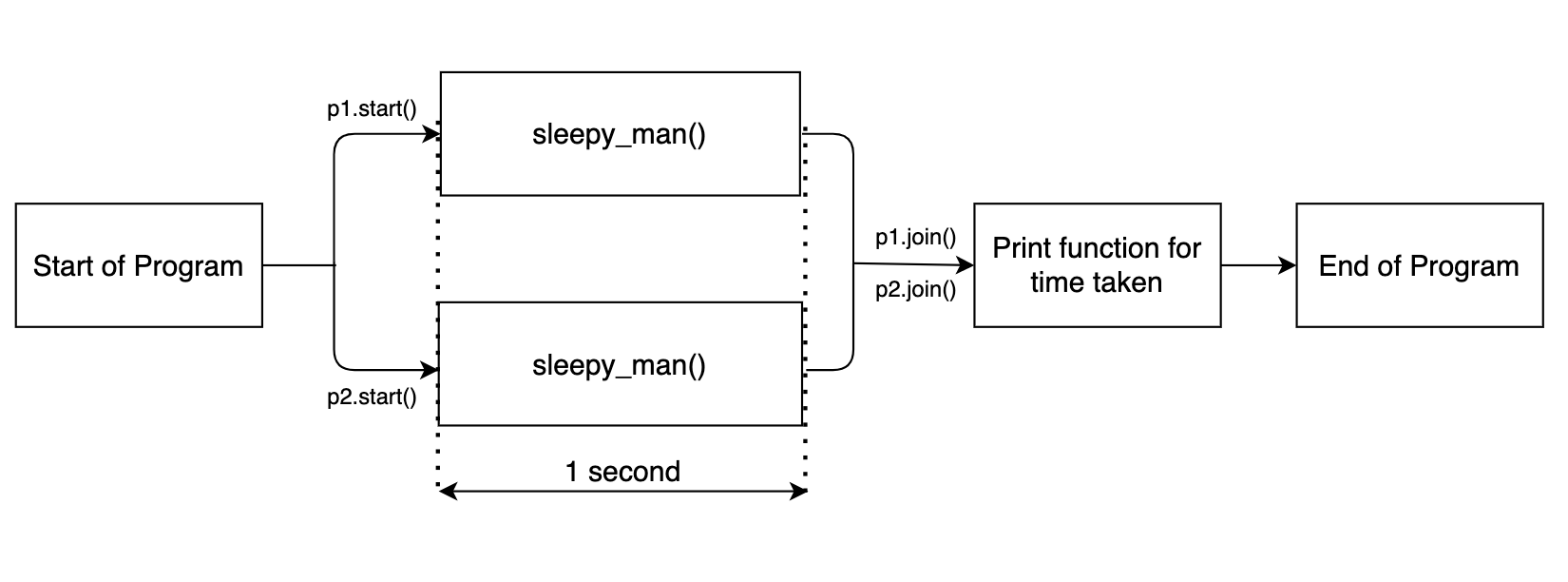
Étant donné que les deux fonctions de suspension fonctionnent en parallèle, la fonction dans son ensemble prend environ 1 seconde.
Nous pouvons définir n'importe quel nombre d'instances de multitraitement. Regardez le code ci-dessous. Définir 10 différentes instances de multitraitement utilisant une boucle for a.
importer le multitraitement
heure d'importation
def sleepy_man():
imprimer('Commencer à dormir')
le sommeil de temps(1)
imprimer('Fini de dormir')
tic = heure.heure()
liste_processus = []
pour moi à portée(10):
p = multitraitement.Processus(cible = sleepy_man)
p.start()
process_list.append(p)
pour le processus dans process_list:
processus.rejoindre()
toc = heure.heure()
imprimer('Fait en {:.4F} secondes'.format(toc-tic))
La sortie du code ci-dessus est affichée ci-dessous.
Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fait en 1.0117 secondes
Ici, les dix exécutions de fonction sont traitées en parallèle et, donc, l'ensemble du programme ne prend qu'une seconde. Maintenant ma machine n'a pas 10 processeurs. Quand nous définissons plus de processus que notre machine, la bibliothèque de multitraitement a une logique pour planifier les travaux. Donc tu n'as pas à t'en soucier.
On peut aussi passer des arguments au Traiter fonction utilisant arguments.
importer le multitraitement
heure d'importation
def sleepy_man(seconde):
imprimer('Commencer à dormir')
le sommeil de temps(seconde)
imprimer('Fini de dormir')
tic = heure.heure()
liste_processus = []
pour moi à portée(10):
p = multitraitement.Processus(cible = sleepy_man, arguments = [2])
p.start()
process_list.append(p)
pour le processus dans process_list:
processus.rejoindre()
toc = heure.heure()
imprimer('Fait en {:.4F} secondes'.format(toc-tic))
La sortie du code ci-dessus est affichée ci-dessous.
Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Commencer à dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fini de dormir Fait en 2.0161 secondes
Puisque nous passons un argument, les sleepy_man fonction dormi pendant 2 secondes au lieu de 1 seconde.
Traitement multiple en Python à l'aide Piscine classe-
Dans le dernier extrait de code, nous exécutons 10 différents processus utilisant une boucle for. Au lieu, nous pouvons utiliser le Piscine méthode pour faire de même.
importer le multitraitement
heure d'importation
def sleepy_man(seconde):
imprimer('Commencer à dormir pour {} secondes'.format(seconde))
le sommeil de temps(seconde)
imprimer('Fini de dormir pour {} secondes'.format(seconde))
tic = heure.heure()
pool = multiprocessing.Pool(5)
pool.map(sleepy_man, gamme(1,11))
piscine.fermer()
toc = heure.heure()
imprimer('Fait en {:.4F} secondes'.format(toc-tic))
Multitraitement de pool (5) définit le nombre de travailleurs. Ici, nous définissons le nombre comme 5. pool.map () est la méthode qui déclenche l'exécution de la fonction. Nous appelons pool.map (sleepy_man, rang (1,11)). Ici, sleepy_man es la función que se llamará con los paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... para las ejecuciones de funciones definidas por rang (1,11) (généralement une liste est transmise). La sortie est la suivante:
Commencer à dormir pour 1 secondes Commencer à dormir pour 2 secondes Commencer à dormir pour 3 secondes Commencer à dormir pour 4 secondes Commencer à dormir pour 5 secondes Fini de dormir pour 1 secondes Commencer à dormir pour 6 secondes Fini de dormir pour 2 secondes Commencer à dormir pour 7 secondes Fini de dormir pour 3 secondes Commencer à dormir pour 8 secondes Fini de dormir pour 4 secondes Commencer à dormir pour 9 secondes Fini de dormir pour 5 secondes Commencer à dormir pour 10 secondes Fini de dormir pour 6 secondes Fini de dormir pour 7 secondes Fini de dormir pour 8 secondes Fini de dormir pour 9 secondes Fini de dormir pour 10 secondes Fait en 15.0210 secondes
Piscine La classe est un meilleur moyen d'implémenter le multitraitement car elle distribue les tâches aux processeurs disponibles à l'aide du programme First In, premier sorti. Il est presque similaire à l'architecture map-reduce, en substance, attribue l'entrée à différents processeurs et collecte la sortie de tous les processeurs sous forme de liste. Les processus en cours d'exécution sont stockés dans la mémoire et les autres processus non en cours d'exécution sont stockés hors de la mémoire.
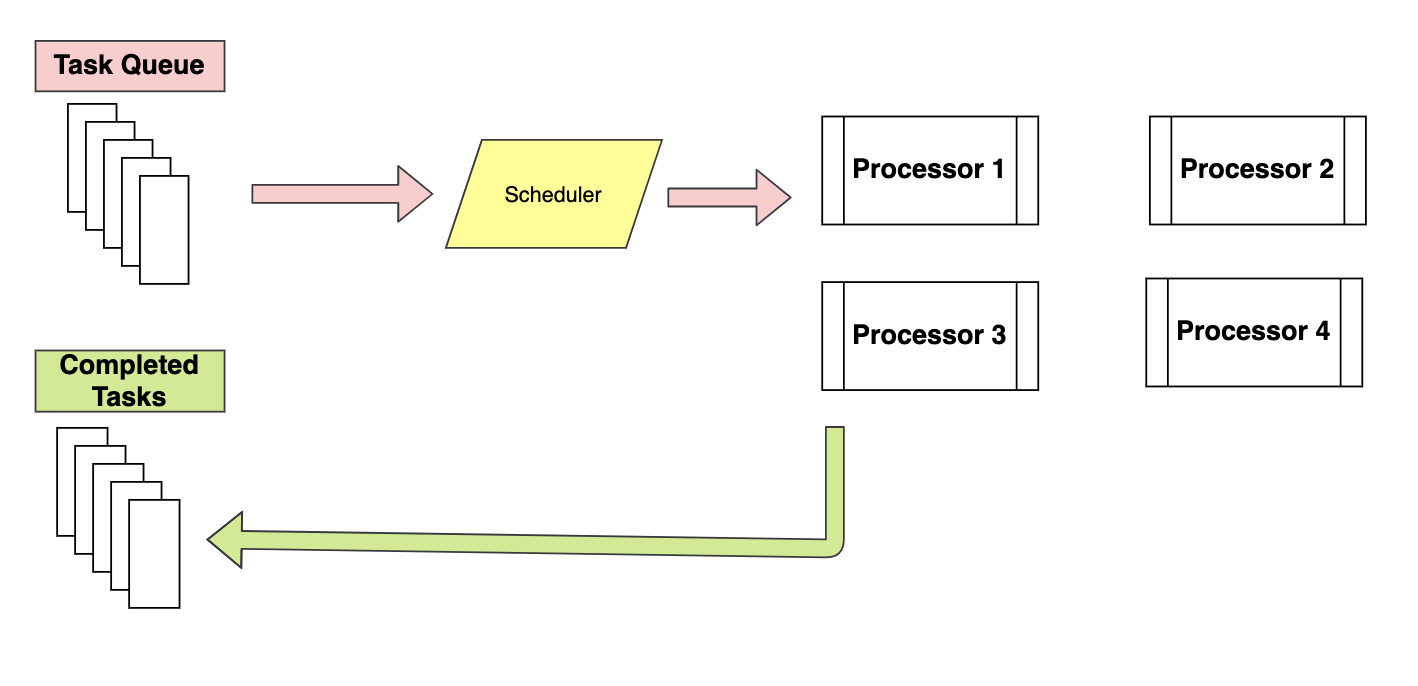
Alors que dans Traiter classe, tous les processus sont exécutés en mémoire et l'exécution est planifiée au moyen de la politique FIFO.
Comparer les performances temporelles pour calculer des nombres parfaits-
Jusqu'à maintenant, on joue avec multiprocessus fonctions dans dormir les fonctions. Prenons maintenant une fonction qui vérifie si un nombre est un nombre parfait ou non. Pour ceux qui ne savent pas, un nombre est un nombre parfait si la somme de ses diviseurs positifs est égale au nombre lui-même. Nous allons lister les nombres parfaits inférieurs ou égaux à 100000. Nous le mettrons en œuvre à partir de 3 formes: en utilisant une boucle for régulière, en utilisant multiprocess.Process () y multiprocess.Pool ().
Utiliser une boucle régulière pour
heure d'importation
def est_parfait(m):
somme_facteurs = 0
pour moi à portée(1, m):
si (m % je == 0):
sum_factors = sum_factors + je
si (sum_factors == n):
imprimer('{} est un nombre parfait'.format(m))
tic = heure.heure()
pour n dans la plage(1,100000):
est parfait(m)
toc = heure.heure()
imprimer('Fait en {:.4F} secondes'.format(toc-tic))
Le résultat du programme ci-dessus est montré ci-dessous.
6 est un nombre parfait 28 est un nombre parfait 496 est un nombre parfait 8128 est un nombre parfait Fait en 258.8744 secondes
Utiliser une classe de processus
heure d'importation
importer le multitraitement
def est_parfait(m):
somme_facteurs = 0
pour moi à portée(1, m):
si(m % je == 0):
sum_factors = sum_factors + je
si (sum_factors == n):
imprimer('{} est un nombre parfait'.format(m))
tic = heure.heure()
processus = []
pour moi à portée(1,100000):
p = multitraitement.Processus(cible=est_parfait, arguments=(je,))
processus.append(p)
p.start()
pour le processus dans les processus:
processus.rejoindre()
toc = heure.heure()
imprimer('Fait en {:.4F} secondes'.format(toc-tic))
Le résultat du programme ci-dessus est montré ci-dessous.
6 est un nombre parfait 28 est un nombre parfait 496 est un nombre parfait 8128 est un nombre parfait Fait en 143.5928 secondes
Comment pourrais-tu voir, nous avons obtenu une réduction de 44,4% à temps lorsque nous implémentons le multitraitement en utilisant Traiter classer, au lieu d'une boucle for régulière.
Utiliser une classe Pool
heure d'importation
importer le multitraitement
def est_parfait(m):
somme_facteurs = 0
pour moi à portée(1, m):
si(m % je == 0):
sum_factors = sum_factors + je
si (sum_factors == n):
imprimer('{} est un nombre parfait'.format(m))
tic = heure.heure()
pool = multiprocessing.Pool()
pool.map(est parfait, gamme(1,100000))
piscine.fermer()
toc = heure.heure()
imprimer('Fait en {:.4F} secondes'.format(toc-tic))
Le résultat du programme ci-dessus est montré ci-dessous.
6 est un nombre parfait 28 est un nombre parfait 496 est un nombre parfait 8128 est un nombre parfait Fait en 74.2217 secondes
Comme tu peux le voir, par rapport à une boucle for normale, nous avons obtenu une réduction de 71,3% en temps de calcul, et par rapport au Traiter classe, nous avons obtenu une réduction de 48,4% en temps de calcul.
Donc, Il est bien évident qu'en mettant en œuvre une méthode appropriée dès le multiprocessus une bibliothèque, nous pouvons obtenir une réduction significative du temps de calcul.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





