Cet article a été publié dans le cadre du Blogathon sur la science des données.
“Gagner sur le marché, vous devez gagner au travail” –Steve Jobs, fondateur d'Apple Inc..
introduction
Pourquoi utilisons-nous la régression logistique pour analyser l'attrition des employés?
Si un employé va rester ou quitter une entreprise, ta réponse est simplement binomiale, c'est-à-dire, Peut être “OUI” O “NON”. Ensuite, nous pouvons voir que notre variable dépendante Attrition des employés n'est qu'une variable catégorielle. Dans le cas d'une variable dépendante catégorielle, nous ne pouvons pas utiliser la régression linéaire, dans ce cas, Nous devons utiliser "RÉGRESSION LOGISTIQUE".
Méthodologie
Ici, je vais porter 5 Étapes simples pour analyser l'attrition des employés à l'aide du logiciel R
- COLLECTE DE DONNÉES
- PRÉ-TRAITEMENT DES DONNÉES
- DIVISION DES DONNÉES EN DEUX PARTIES “ENTRAÎNEMENT” Oui “ESSAIS”
- CONSTRUIRE LE MODÈLE AVEC “ENSEMBLE DE DONNÉES D'ENTRAÎNEMENT”
- FAIRE LE TEST DE PRÉCISION À L'AIDE DU “ENSEMBLE DE DONNÉES DE TEST”
Exploration des données
Cet ensemble de données est collecté auprès du service des ressources humaines d'IBM. L'ensemble de données contient 1470 observations et 35 variables. Dans 35 variables, « Usure » est la variable dépendante.
Un rapide coup d'œil à l'ensemble de données:
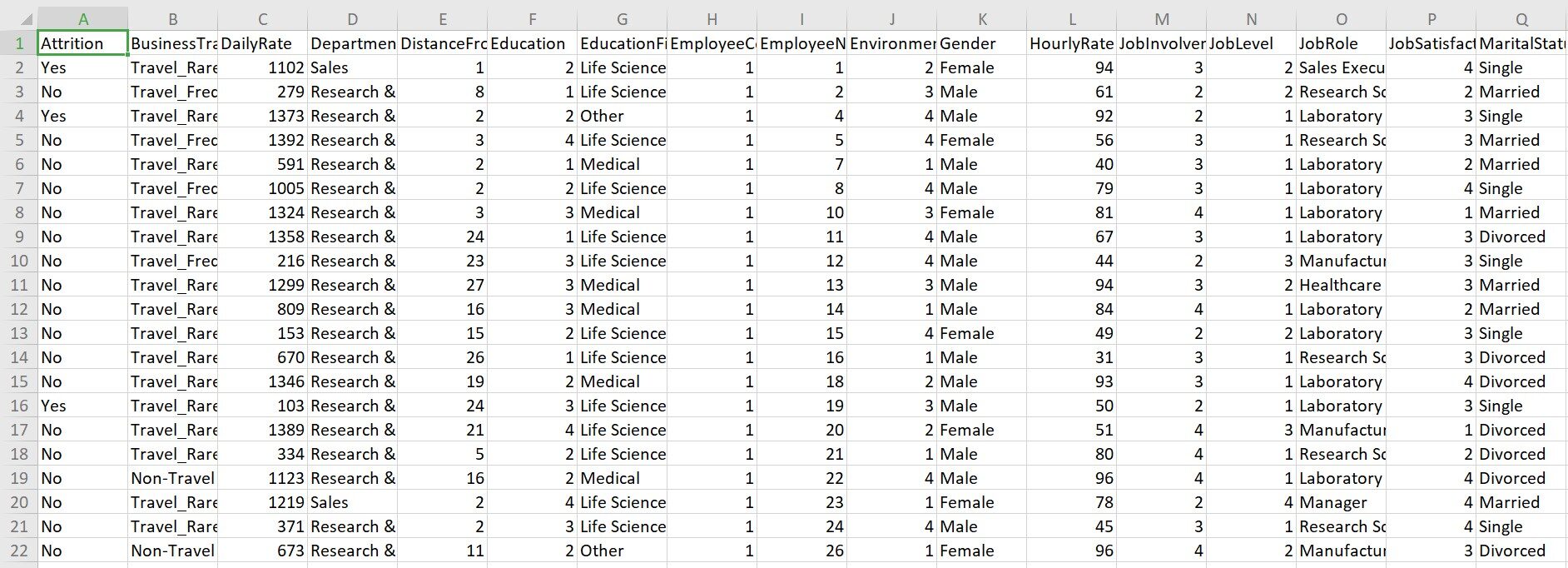
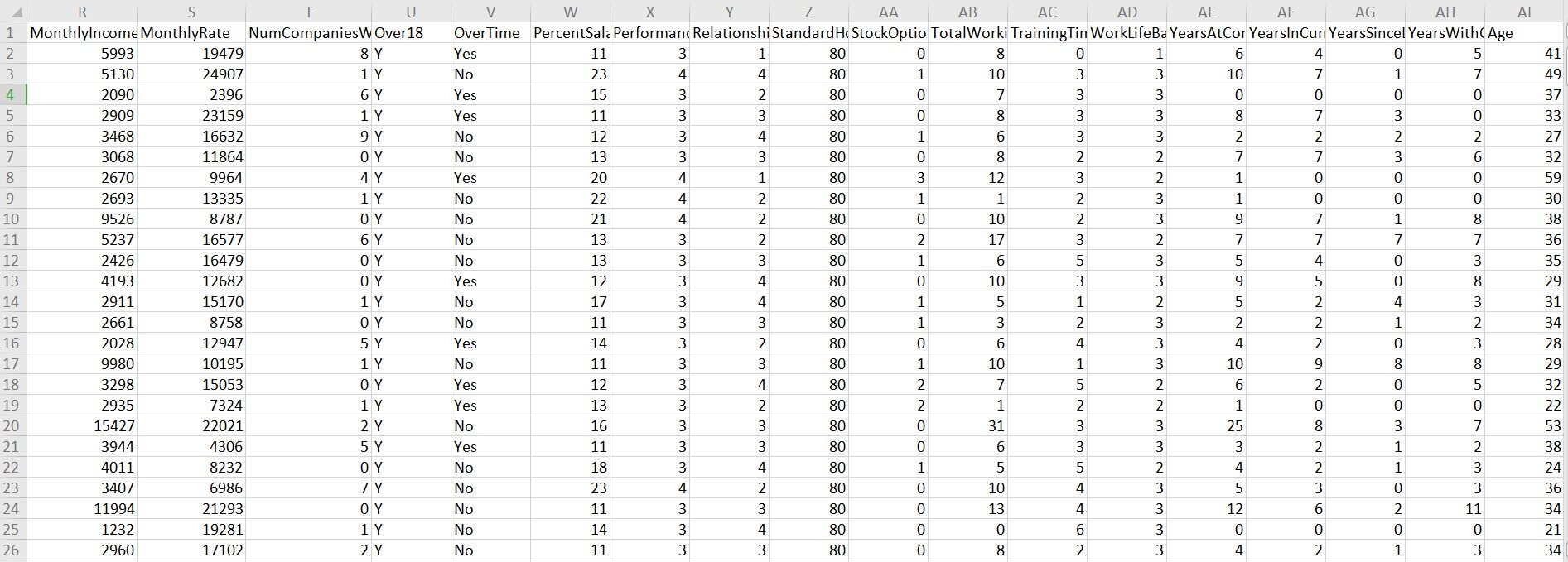
Jeter un coup d'oeil:
Préparation des données
-
Modifier les types de données:
En premier lieu, nous devons changer le type de données de la variable dépendante “Porter”. Il est donné sous la forme "Oui" et "Non", c'est-à-dire, est une variable catégorielle. Pour faire un modèle approprié, nous devons le convertir sous forme numérique. Pour cela, nous attribuerons la valeur 1 à "Oui" et la valeur 0 à "Non" et nous le convertirons en numérique.
JOB_Attrition$Attrition[JOB_Attrition$Attrition=="Oui"]=1 JOB_Attrition$Attrition[JOB_Attrition$Attrition=="Non"]=0 JOB_Attrition$Attrition=as.numeric(JOB_Attrition$Attrition)
Suivant, nous allons changer toutes les variables de “personnage” une “Facteur”
Il y a 8 variables de caractère: voyage d'affaires, département, éducation, domaine de l'éducation, le genre, fonction de travail, état civil, au fil du temps. Les numéros de colonnes sont 2, 4, 6, 7, 11, 15, 17, 22 respectivement.
EMPLOI_Attrition[,c(2,4,6,7,11,15,17,22)]= appliquer(EMPLOI_Attrition[,c(2,4,6,7,11,15,17,22)],comme.facteur)
Finalement, il y a une autre variable “Plus de 18 ans” qui a toutes les entrées comme “Oui”. C'est aussi une variable de caractère. Nous allons transformer en numérique car il n'a qu'un seul niveau donc transformer en facteur ne donnera pas un bon résultat. Pour cela, nous attribuerons la valeur 1 à "Y" et nous le transformerons en numérique.
EMPLOI_Attrition$Plus de18[JOB_Attrition$Over18=="Oui"]=1 JOB_Attrition$Over18=as.numeric(EMPLOI_Attrition$Plus de18)
Divisez l'ensemble de données en “entraînement” Oui “test”
Dans toute analyse de régression, nous devons diviser l'ensemble de données en 2 les pièces:
- ENSEMBLE DE DONNÉES D'ENTRAÎNEMENT
- ENSEMBLE DE DONNÉES DE TEST
Avec l'aide de l'ensemble de données d'entraînement, nous allons créer notre modèle et tester sa précision à l'aide de l'ensemble de données de test.
set.seed(1000)
ranuni=échantillon(x=c("Entraînement","Essai"),taille=nrow(EMPLOI_Attrition),remplacer=T,prob=c(0.7,0.3))
TrainingData=JOB_Attrition[ranuni =="Entraînement",]
TestingData=JOB_Attrition[ranuni =="Essai",]
maintenant(Données d'entraînement)
maintenant(Données de test)
Nous avons réussi à diviser l'ensemble de données en deux parties. Maintenant nous avons 1025 Données d'entraînement et 445 Données de test.
Construire le modèle
Maintenant, nous allons construire le modèle en suivant quelques étapes simples comme suit:
- Identifier les variables indépendantes
- Incorporer la variable dépendante “Porter” dans le modèle.
- Transformer le type de données du modèle “personnage” une “formule”
- Incorporer les données de FORMATION dans la formule et construire le modèle
variablesindépendantes = colnames(EMPLOI_Attrition[,2:35])
variables indépendantes
Modèle=coller(variables indépendantes,s'effondrer="+")
Modèle
Model_1=coller("Attrition~",Modèle)
Modèle_1
classer(Modèle_1)
formule=as.formule(Modèle_1)
formule
Production:

Prochain, Nous allons incorporer des « données d'entraînement » dans la formule à l'aide de la fonction « glm » et construire un modèle de régression logistique..
Modèle d'entraînement1=glm(formule = formule,données=Données d'entraînement,famille ="binôme")
À présent, nous allons concevoir le modèle par le “Sélection étape par étape”Méthode pour obtenir des variables significatives du modèle. L'exécution du code nous donnera une liste de sortie où les variables sont ajoutées et supprimées en fonction de notre importance du modèle. La valeur de l'AIC à chaque niveau reflète la qualité du modèle respectif. Comme la valeur continue de baisser, un modèle de régression logistique est obtenu qui s'ajuste mieux.
L'application du résumé sur le modèle final nous donnera la liste des variables significatives finales et leurs informations importantes respectives..
Modèle d'entraînement1=étape(objet = Trainingmodel1,direction = "les deux") sommaire(Modèle de formation1)
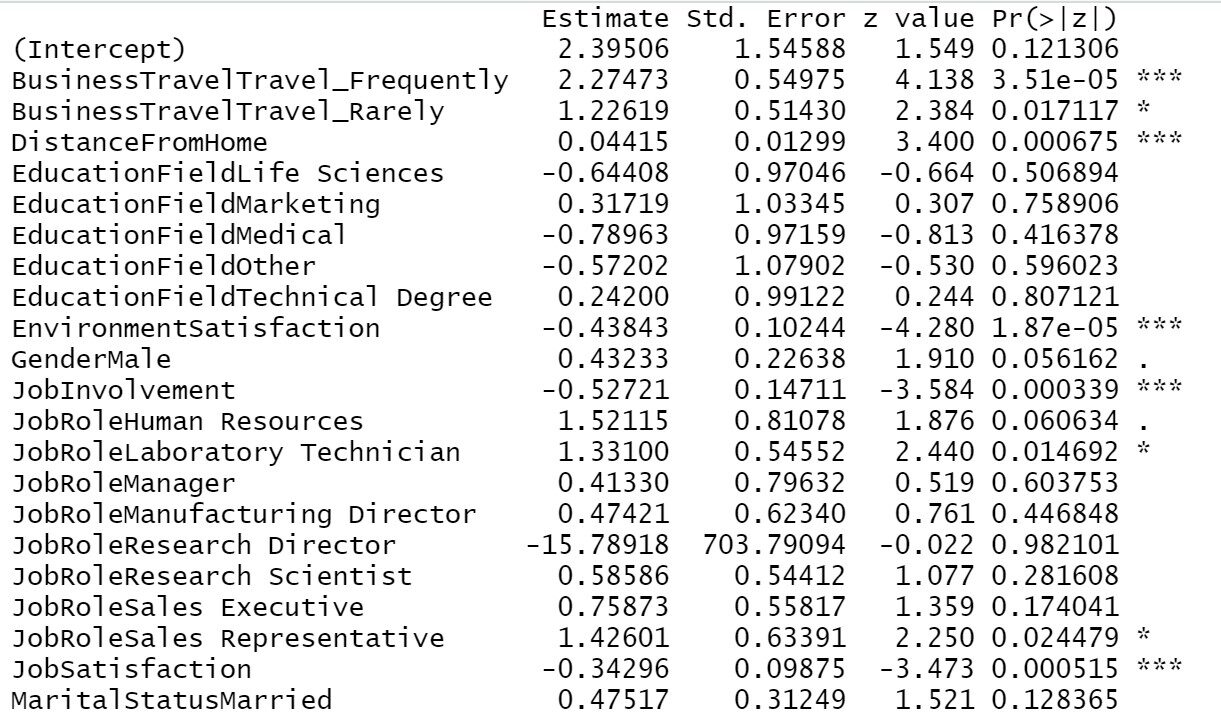
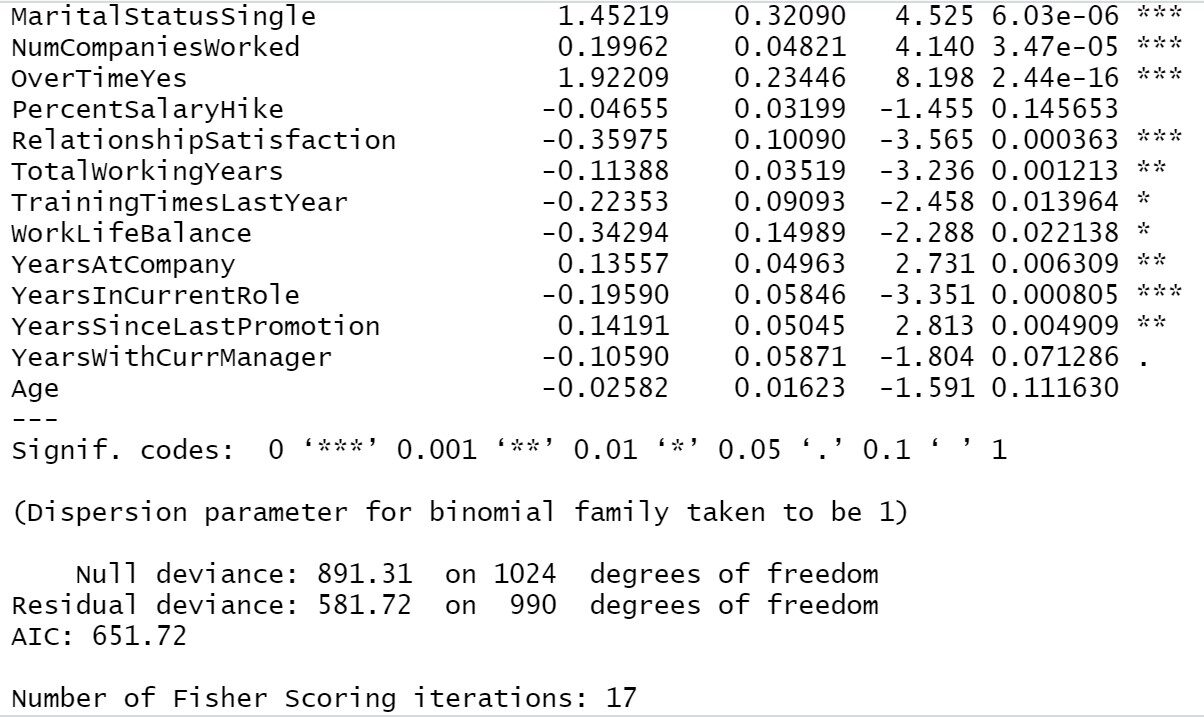
D'après notre résultat précédent, nous pouvons voir, Voyage d'affaires, Distance de la maison, Satisfaction avec l'environnement, Implication du travail, Satisfaction au travail, État civil, Nombre d'entreprises travaillées, Au fil du temps, Satisfaction dans les relations, Nombre total d'années de travail, Années dans l'entreprise, ans depuis la dernière promotion, années dans le poste actuel toutes ces variables sont les plus importantes pour déterminer l'attrition des employés. Si l'entreprise s'occupe principalement de ces domaines, il y aura moins de chance de perdre un employé.
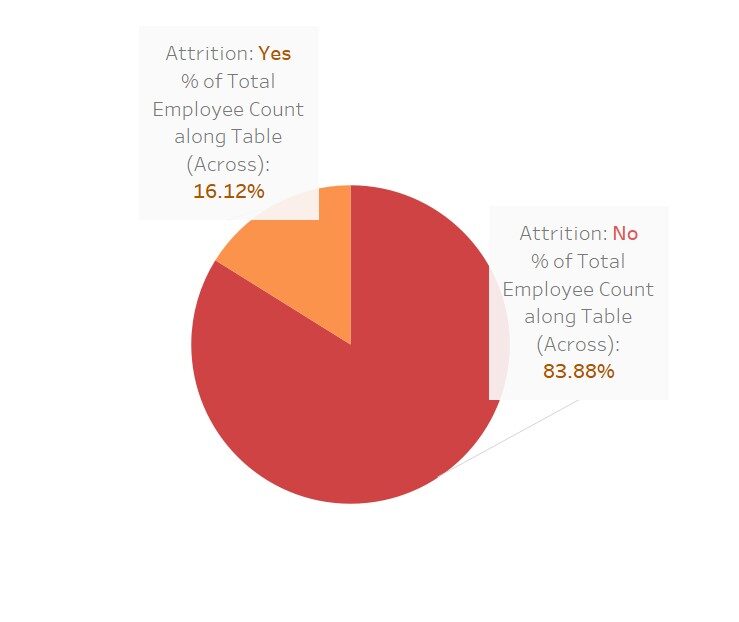
Une visualisation rapide pour voir à quel point ces variables affectent le “porter”
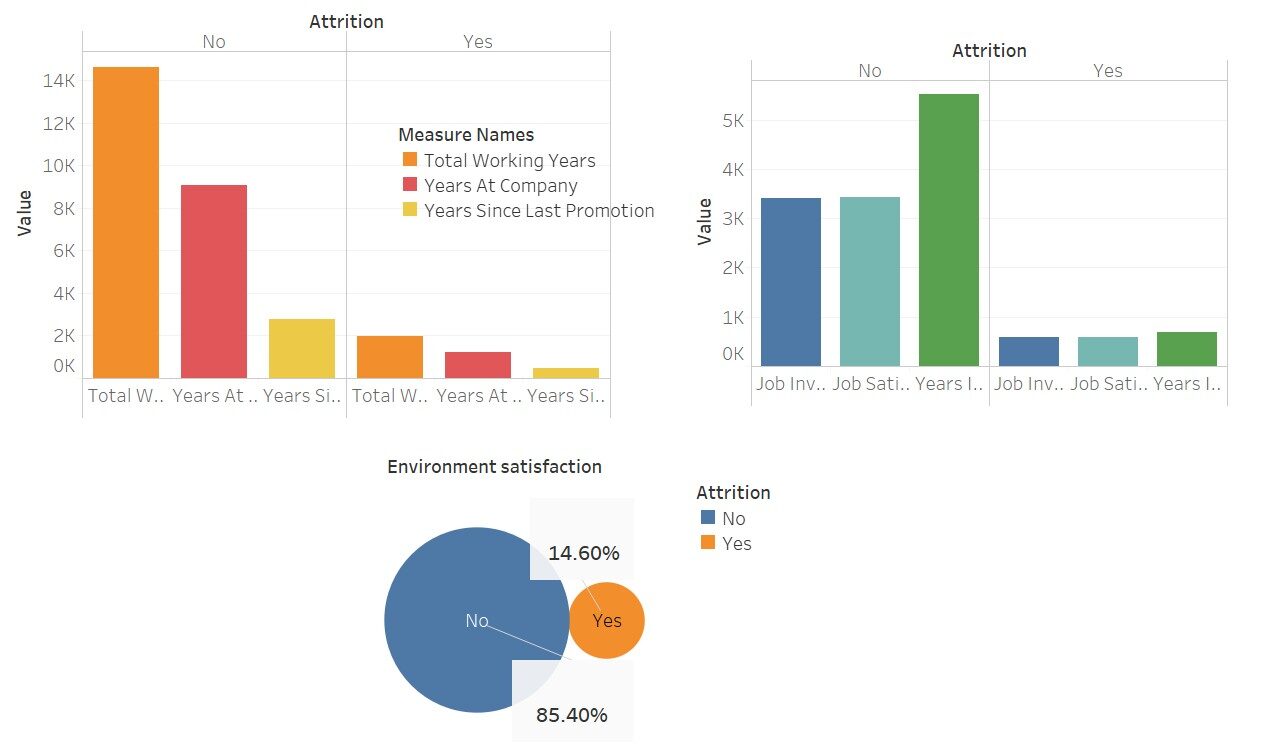
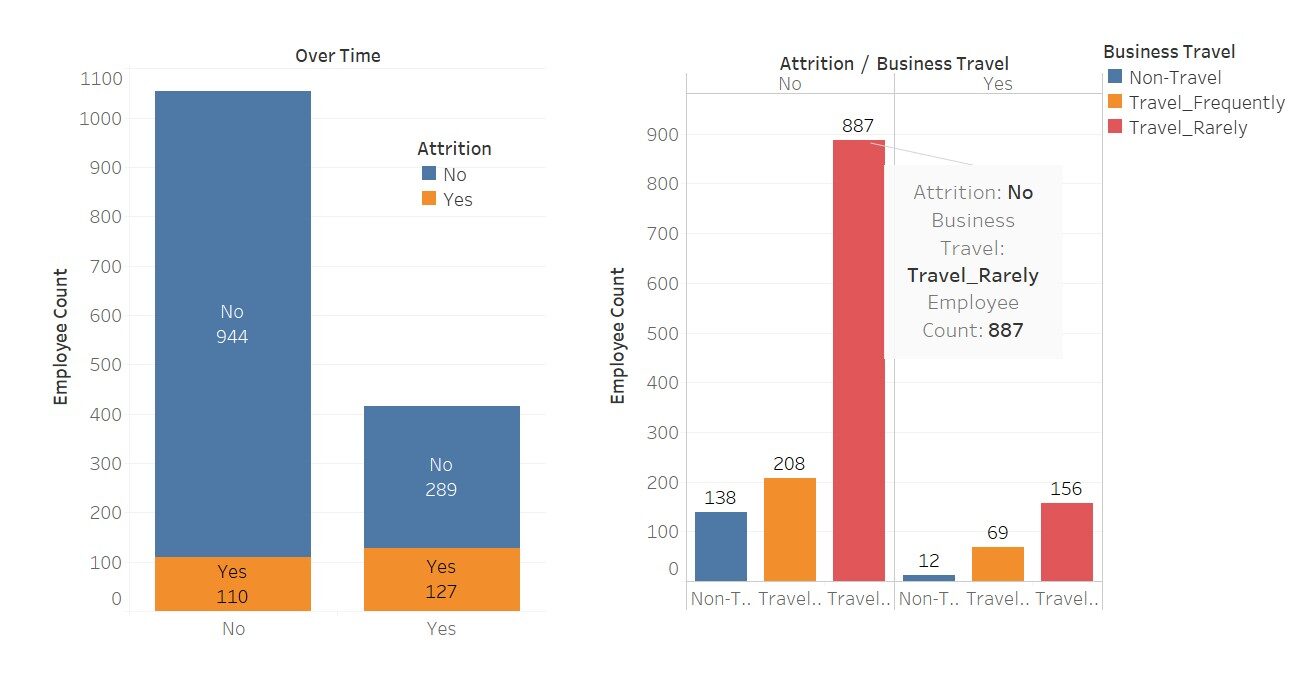
Ici, j'ai utilisé Tableau pour ces visualisations; pas beau Ce logiciel ne fait que nous faciliter la tâche.
À présent, on peut se rendre compte le spectacle Hoshimer-Lemes test d'adéquation sur l'ensemble de données, pour juger de la précision de la probabilité prédite du modèle.
L'hypothèse est:
H0: Le modèle s'adapte bien.
H1: Le modèle ne s'adapte pas bien.
Et, valeur p> 0,05 nous accepterons H0 et rejetterons H1.
Pour effectuer le test dans R, nous devons installer le mkMisc emballer.
HLgof.test(fit=Formationmodel1$fitted.values,obs=Modèle d'entraînement1$y)

Ici, nous pouvons voir que la valeur p est supérieure à 0.05, donc nous accepterons H0. À présent, il est prouvé que notre modèle est bien ajusté.
Génération d'une courbe ROC pour les données d'entraînement
Une autre technique pour analyser la qualité de l'ajustement de la régression logistique est la Mesures ROC (caractéristiques de fonctionnement du récepteur). Les mesures ROC sont la sensibilité, spécificité 1, faux positif et faux négatif. Les deux mesures que nous utilisons abondamment sont la sensibilité et la spécificité.. La sensibilité mesure la qualité de la précision du modèle, tandis que la spécificité mesure la faiblesse du modèle.
Pour ce faire dans R, nous devons installer un package PROC.
troc=roc(réponse=Modèle d'entraînement1$y,prédicteur = Trainingmodel1$fitted.values,tracé=T) troc$auc
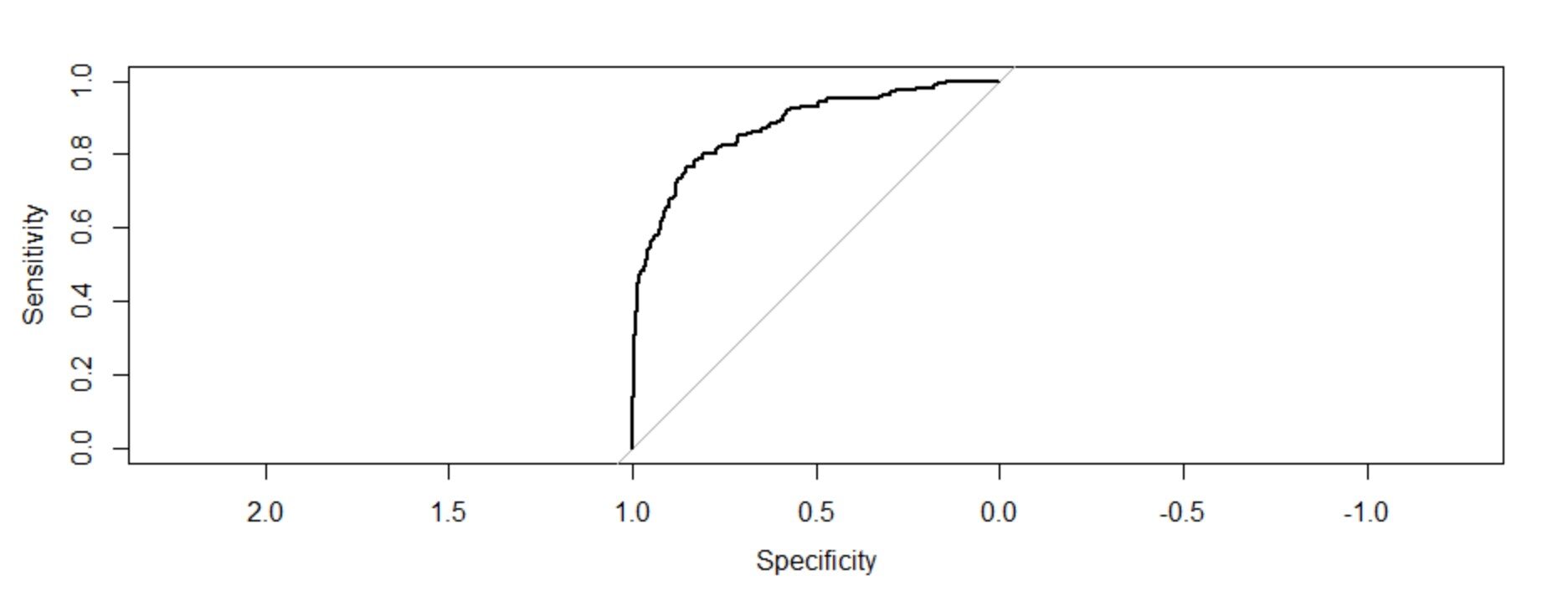
L'aire sous la courbe: 0.8759
Interprétation de la figure:
Le graphique de ces deux mesures nous donne un graphique concave qui montre comment la sensibilité augmente 1-la spécificité augmente mais à un taux décroissant. La valeur C (ASC) o la valeur de l'indice de concordance donne la mesure de l'aire sous la courbe ROC. Si c = 0,5, aurait signifié que le modèle ne peut pas parfaitement discriminer entre 0 Oui 1 réponses. Cela implique alors que le modèle initial ne peut pas dire parfaitement quels salariés vont partir et qui vont rester..
Mais ici, nous pouvons voir que notre valeur c est beaucoup plus grande que 0.5. Il est 0,8759. Notre modèle peut parfaitement discriminer entre 0 Oui 1. Donc, nous pouvons conclure avec succès qu'il s'agit d'un modèle bien ajusté.
Création du classement pour l'ensemble de données d'entraînement:
trpred=ifelse(test=Formationmodel1$fitted.values>0.5,oui = 1, non = 0) tableau(Modèle d'entraînement1$y,trpred)
Les jeux de codes ci-dessus, la valeur prédite de la probabilité supérieure à 0, .5, alors la valeur de l'état est 1, sinon c'est 0. sur la base de ce critère, ce code ré-étiquette les réponses “Oui” Oui “Non” de “Porter”. À présent, il est important de comprendre le pourcentage de prédictions qui correspondent à la croyance initiale obtenue à partir de l'ensemble de données. Ici, nous allons comparer la paire (1-1) Oui (0-0).
Ont 1025 données d'entraînement. nous avons prédit {(839 + 78) / 1025} * 100 =89% correctement.
Comparaison du résultat avec les données du test:
Nous allons maintenant comparer le modèle avec les données de test. C'est un peu comme un test de précision.
testpred=predict.glm(object=Trainingmodel1,newdata=TestingData,taper = "réponse") test tsroc=roc(response=TestingData$Attrition,prédicteur = testpred,tracé=T) tsroc$auc
À présent, nous avons incorporé les données de test dans le modèle d'entraînement et nous verrons le ROC.
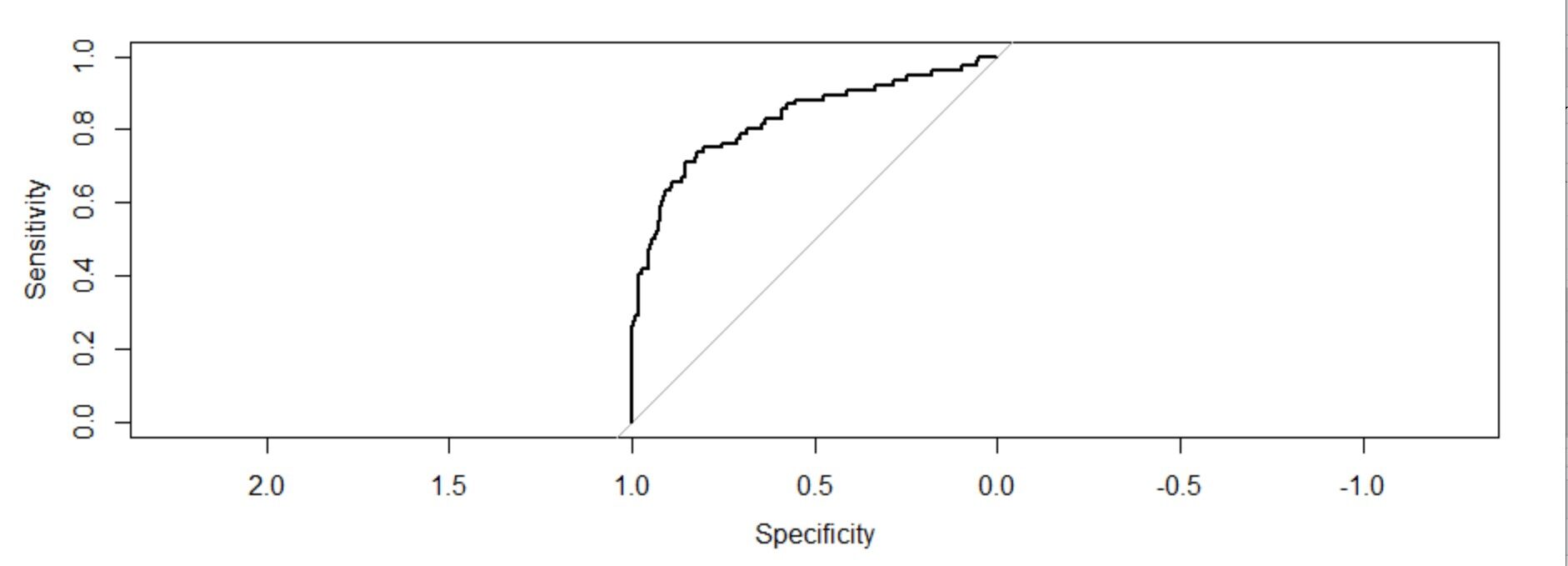
L'aire sous la courbe: 0,8286 (valeur c). Il est également de loin supérieur à 0,5. C'est aussi un modèle bien ajusté.
Créer la table de classification pour l'ensemble de données de test
testpred = ifelse(test = testpred>0.5,oui=1,non=0) tableau(Tester l'attrition des données $,test)

Ont 445 données de test. nous avons bien prédit {(362 + 28) / 445} * 100 =87,64%.
Comme conséquence, nous pouvons dire que notre modèle de régression logistique est un modèle très bien ajusté. Tout ensemble de données sur l'attrition des employés peut être analysé à l'aide de ce modèle.
Que pensez-vous est un bon modèle? Commentaires ci-dessous
CONCLUSION:
Nous avons appris avec succès à analyser l'attrition des employés à l'aide de la « RÉGRESSION LOGISTIQUE » à l'aide du logiciel R. Juste avec quelques codes et un ensemble de données approprié, une entreprise peut facilement comprendre les domaines dont elle doit s'occuper afin de rendre le lieu de travail plus confortable pour ses employés et de redonner de l'énergie à ses ressources humaines pour une plus longue période.
L'image en vedette est tirée de trainingjournal.com
Lien vers mon profil LinkedIn:
https://www.linkedin.com/in/tiasa-patra-37287b1b4/





