Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
Apprentissage renforcé pour le trading automatisé avec Python. Apprentissage renforcé pour le trading automatisé avec Python, Apprentissage renforcé pour le trading automatisé avec Python. Apprentissage renforcé pour le trading automatisé avec Python. Apprentissage renforcé pour le trading automatisé avec Python. Apprentissage renforcé pour le trading automatisé avec Python. Apprentissage renforcé pour le trading automatisé avec Python.
Chaque être humain veut réaliser son plein potentiel en bourse.. Il est très important de concevoir une stratégie équilibrée et à faible risque qui puisse profiter à la plupart des gens. Uno de estos enfoques habla sobre el uso de agentes de apprentissage par renforcementL’apprentissage par renforcement est une technique d’intelligence artificielle qui permet à un agent d’apprendre à prendre des décisions en interagissant avec un environnement. Par le biais de commentaires sous forme de récompenses ou de punitions, L’agent optimise son comportement pour maximiser les récompenses accumulées. Cette approche est utilisée dans une variété d’applications, Des jeux vidéo à la robotique en passant par les systèmes de recommandation, se démarquant par sa capacité à apprendre des stratégies complexes.... para proporcionarnos estrategias comerciales automatizadas basadas en datos históricos.
Apprentissage renforcé
L'apprentissage par renforcement est un type d'apprentissage automatique dans lequel il existe des environnements et des agents. Ces agents prennent des mesures pour maximiser les récompenses. L'apprentissage par renforcement a un énorme potentiel lorsqu'il est utilisé pour des simulations pour former un modèle d'IA. Il n'y a pas d'étiquette associée à des données, l'apprentissage par renforcement peut apprendre mieux avec très peu de points de données. toutes les décisions, dans ce cas, toutes les décisions. toutes les décisions.
Q – toutes les décisions
toutes les décisions. toutes les décisions. toutes les décisions. toutes les décisions, toutes les décisions, toutes les décisions, donc, toutes les décisions.
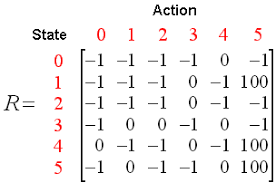
toutes les décisions. La qualité fait référence à la qualité de l'action en termes de bénéfices de cette récompense en fonction de l'action entreprise. Une table Q avec des dimensions est créée [Etat,action]Un agent interagit avec l'environnement de deux manières: exploiter et explorer. Une option d'exploitation suggère que toutes les actions soient envisagées et que celle qui donne le plus de valeur à l'environnement soit prise.. Une option d'exploration est une option dans laquelle une action aléatoire est envisagée sans tenir compte de la récompense future maximale.

Q de st et at est représenté par une formule qui calcule la récompense future actualisée maximale lorsqu'une action est effectuée dans un état s.
La función definida nos proporcionará la recompensa máxima al final del número n de ciclos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... o iteraciones.
Q de st et at est représenté par une formule qui calcule la récompense future actualisée maximale lorsqu'une action est effectuée dans un état s: Q de st et at est représenté par une formule qui calcule la récompense future actualisée maximale lorsqu'une action est effectuée dans un état s, Q de st et at est représenté par une formule qui calcule la récompense future actualisée maximale lorsqu'une action est effectuée dans un état s
Q de st et at est représenté par une formule qui calcule la récompense future actualisée maximale lorsqu'une action est effectuée dans un état s. Q de st et at est représenté par une formule qui calcule la récompense future actualisée maximale lorsqu'une action est effectuée dans un état s. Q de st et at est représenté par une formule qui calcule la récompense future actualisée maximale lorsqu'une action est effectuée dans un état s.
Q de st et at est représenté par une formule qui calcule la récompense future actualisée maximale lorsqu'une action est effectuée dans un état s
Q de st et at est représenté par une formule qui calcule la récompense future actualisée maximale lorsqu'une action est effectuée dans un état s. Le trading est une tâche continue sans aucun point de terminaison. La négociation est également un processus de décision markov partiellement observable., car nous n’avons pas d’informations complètes sur les traders sur le marché. Comme nous ne connaissons pas la fonction de récompense et la probabilité de transition, nous utilisons l’apprentissage par renforcement sans modèle, Qu’est-ce que Q-Learning.
Étapes pour exécuter un agent RL:
-
Installer des bibliothèques
-
Obtenez les données
-
Définir l’agent Q-Learning
-
Former l’agent
-
Tester l’agent
-
Tracer les signaux
Installer des bibliothèques
Installer et importer les bibliothèques financières NumPy nécessaires, pandas, matplotlib, seaborn et yahoo.
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set() !pip install yfinance --upgrade --no-cache-dir from pandas_datareader import data as pdr import fix_yahoo_finance as yf from collections import deque import random Import tensorflow.compat.v1 as tf tf.compat.v1.disable_eager_execution()
Obtenez les données
Utilisez la bibliothèque Yahoo Finance pour obtenir les données d’un stock particulier. Les actions utilisées ici pour notre analyse sont les actions d’Infosys.
yf.pdr_override()
df_full = pdr.get_data_yahoo("INFY", début ="2018-01-01").reset_index()
df_full.to_csv (en anglais seulement)('INFY.csv',index=Faux)
df_full.head()
Ce code créera un cadre de données appelé df_full qui contiendra les cours des actions d’INFY au cours de la 2 ans.
Définir l’agent Q-Learning
la première fonction est que la classe d’agent définit la taille de l’état, taille de la fenêtre, La taille du lot, deque quelle est la mémoire utilisée, inventaire sous forme de liste. Il définit également certaines variables statiques comme epsilon, Il définit également certaines variables statiques comme epsilon, gamma, etc. Se definen dos capas de neuronal rougeLes réseaux de neurones sont des modèles computationnels inspirés du fonctionnement du cerveau humain. Ils utilisent des structures appelées neurones artificiels pour traiter et apprendre des données. Ces réseaux sont fondamentaux dans le domaine de l’intelligence artificielle, permettant des avancées significatives dans des tâches telles que la reconnaissance d’images, Traitement du langage naturel et prédiction de séries temporelles, entre autres. Leur capacité à apprendre des motifs complexes en fait des outils puissants.. para la compra, Il définit également certaines variables statiques comme epsilon. Il définit également certaines variables statiques comme epsilon.
Il définit également certaines variables statiques comme epsilon. Il définit également certaines variables statiques comme epsilon. Il définit également certaines variables statiques comme epsilon. Il définit également certaines variables statiques comme epsilon. 1 Il définit également certaines variables statiques comme epsilon, tandis que 2 Il définit également certaines variables statiques comme epsilon. A chaque itération, el estado se determina sobre la base del cual se toma una acción que comprará o venderá algunas acciones. Las recompensas generales se almacenan en la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... de beneficio total.
df= df_full.copy()
nom="Agent Q-learning"
Agent de classe:
def __init__(soi, state_size, window_size, tendance, sautiller, taille du lot):
self.state_size = state_size
self.window_size = window_size
self.half_window = window_size // 2
self.trend = trend
self.skip = skip
self.action_size = 3
self.batch_size = batch_size
self.memory = deque(maxlen = 1000)
self.inventory = []
self.gamma = 0.95
self.epsilon = 0.5
self.epsilon_min = 0.01
self.epsilon_decay = 0.999
tf.reset_default_graph()
self.sess = tf. InteractiveSession()
même. X = tf.placeholder(tf.float32, [Rien, self.state_size])
même. Y = tf.espace réservé(tf.float32, [Rien, self.action_size])
feed = tf.layers.dense(même. X, 256, activation = tf.nn.relu)
self.logits = tf.layers.dense(nourrir, self.action_size)
self.cost = tf.reduce_mean(tf.carré(même. Y - self.logits))
self.optimizer = tf.train.GradientDescentOptimizer(1e-5).minimiser(
auto-coût
)
self.sess.run(tf.global_variables_initializer())
def act(soi, Etat):
si random.random() <= self.epsilon:
renvoyer random.randrange(self.action_size)
retour np.argmax(
self.sess.run(self.logits, feed_dict = {même. X: Etat})[0]
)
def get_state(soi, t):
window_size = self.window_size + 1
d = t - window_size + 1
bloc = self.trend[ré : t + 1] si d >= 0 else -d * [self.trend[0]] + self.trend[0 : t + 1]
res = []
pour moi à portée(window_size - 1):
res.append(bloquer[je + 1] - bloquer[je])
retourner np.array([res])
def replay(soi, taille du lot):
mini_batch = []
l = len(self.memory)
pour moi à portée(je - taille du lot, je):
mini_batch.append(self.memory[je])
replay_size = len(mini_batch)
X = np.vide((replay_size, self.state_size))
Y = np.vide((replay_size, self.action_size))
états = np.array([une[0][0] forums en mini_batch])
new_states = np.array([une[3][0] forums en mini_batch])
Q = self.sess.run(self.logits, feed_dict = {même. X: États})
Q_new = self.sess.run(self.logits, feed_dict = {même. X: new_states})
pour moi à portée(longueur(mini_batch)):
Etat, action, récompense, next_state, fait = mini_batch[je]
cible = Q[je]
cible[action] = reward
if not done:
cible[action] += self.gamma * np.amax(Q_new[je])
X[je] = state
Y[je] = target
cost, _ = self.sess.run(
[auto-coût, self.optimizer], feed_dict = {même. X: X, même. Y: Oui}
)
si self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
return cost
def buy(soi, initial_money):
starting_money = initial_money
states_sell = []
states_buy = []
inventaire = []
état = self.get_state(0)
pour t dans la gamme(0, longueur(self.trend) - 1, self.skip):
action = self.act(Etat)
next_state = self.get_state(t + 1)
si action == 1 et initial_money >= self.trend inventory.append(self.trend initial_money -= self.trend states_buy.append imprimer('jour %d: acheter 1 unité au prix %f, solde total %f'% (t, self.trend elif action == 2 et len(inventaire):
bought_price = inventaire.pop(0)
initial_money += self.trend states_sell.append essayer:
investir = ((fermer sauf:
investir = 0
imprimer(
'jour %d, vendre 1 unité au prix %f, investissement %f %%, solde total %f,'
% (t, fermer
)
state = next_state
invest = ((initial_money - starting_money) / starting_money) * 100
total_gains = initial_money - starting_money
return states_buy, states_sell, total_gains, invest
def train(soi, itérations, point de contrôle, initial_money):
pour moi à portée(itérations):
total_profit = 0
inventaire = []
état = self.get_state(0)
starting_money = initial_money
for t in range(0, longueur(self.trend) - 1, self.skip):
action = self.act(Etat)
next_state = self.get_state(t + 1)
si action == 1 et starting_money >= self.trend inventory.append(self.trend starting_money -= self.trend elif action == 2 et len(inventaire) > 0:
bought_price = inventaire.pop(0)
total_profit += self.trend starting_money += self.trend invest = ((starting_money - initial_money) / initial_money)
self.memory.append((Etat, action, investir,
next_state, starting_money < initial_money))
state = next_state
batch_size = min(self.batch_size, longueur(self.memory))
coût = self.replay(taille du lot)
si (i+1) % point de contrôle == 0:
imprimer(« époque »: %ré, récompenses totales: %f.3, Coût: %F, somme d’argent: %f'%(je + 1, total_profit, Coût,
starting_money))
Former l’agent
Una vez definido el agente, inicialícelo. Especifique el número de iteraciones, dinero inicial, etc. para capacitar al agente para que decida las opciones de compra o venta.
fermer = df. Fermer.valeurs.tolist()
initial_money = 10000
window_size = 30
sauter = 1
taille_bat = 32
agent = Agent(state_size = window_size,
window_size = window_size,
tendance = fermer,
skip = sauter,
batch_size = batch_size)
agent.train(itérations = 200, point de contrôle = 10, initial_money = initial_money)
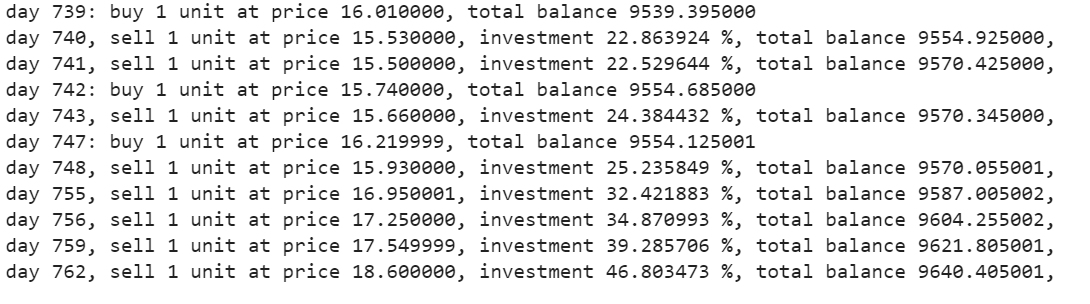
Production –

Tester l’agent
La función de compra devolverá las cifras de compra, vendre, profit et investissement.
états_acheter, states_sell, total_gains, investir = agent.acheter(initial_money = initial_money)
tracer les appels
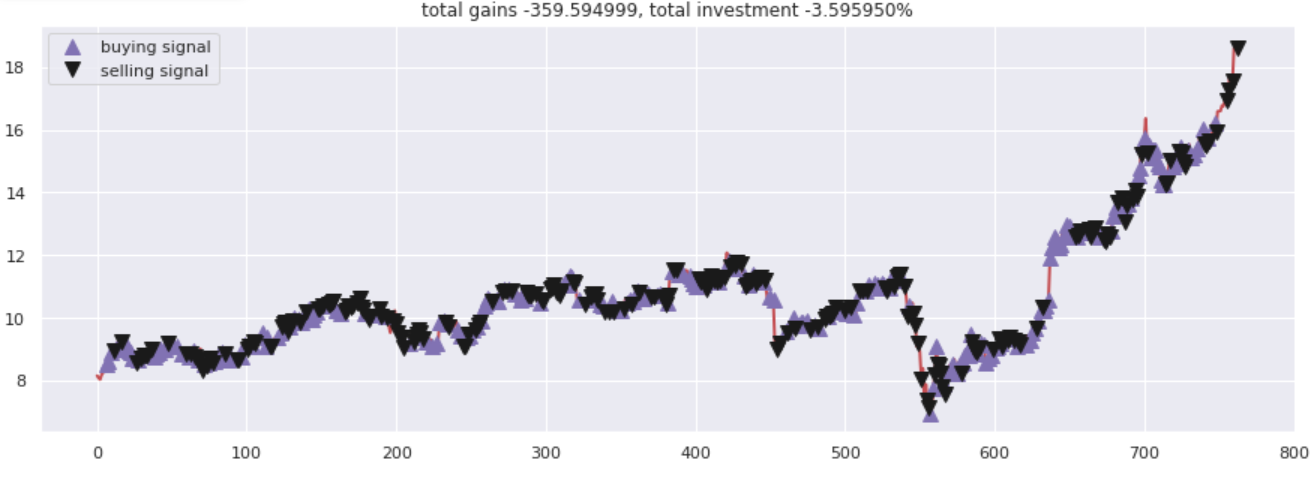
Tracer les gains totaux par rapport aux chiffres investis. Tous les appels d'achat et de vente ont été correctement marqués en fonction des options d'achat / réseau de neurones a suggéré de vendre.
fig = plt.figure(taille de la figue = (15,5))
plt.plot(fermer, couleur="r", lw=2.)
plt.plot(fermer, '^', taille du marqueur = 10, couleur="m", étiquette="signal d'achat", markevery = states_buy)
plt.plot(fermer, 'v', taille du marqueur = 10, couleur="k", étiquette="signal de vente", markevery = états_vente)
plt.titre('gains totaux %f, investissement total %f%%'%(total_gains, investir))
plt.légende()
plt.savefig(nom+'.png')
plt.show()
Production –
Remarques finales
Le Q-Learning est une technique qui vous aide à développer une stratégie de trading automatisée. Peut être utilisé pour expérimenter des options d'achat ou de vente. Il existe de nombreux autres agents d'apprentissage par renforcement commerciaux à expérimenter. Essayez de jouer avec les différents types d'agents RL avec différentes actions.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





