Cet article a été publié dans le cadre du Blogathon sur la science des données
salut les gars! Dans ce blog, Je vais discuter de tout sur la classification des images.
Dans les années récentes, Le Deep Learning s'est avéré être un outil très puissant en raison de sa capacité à gérer de grandes quantités de données. L'utilisation de couches cachées dépasse les techniques traditionnelles, surtout pour la reconnaissance de formes. L'un des réseaux de neurones profonds les plus populaires est les réseaux de neurones convolutifs (CNN).
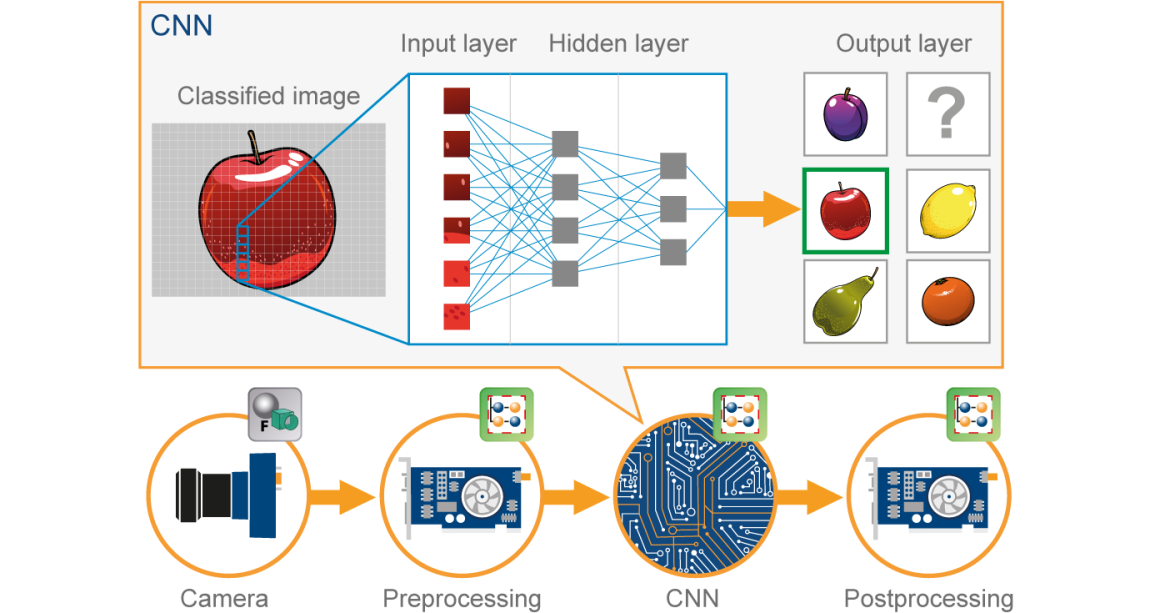
Un réseau de neurones convolutifs (CNN) c'est une sorte de Neuronal artificiel rouge (ANN) utilisé dans la reconnaissance et le traitement d'images, qui est spécialement conçu pour traiter les données (pixels).
Source de l'image: Google.fr
Avant de continuer, nous devons comprendre ce qu'est le réseau de neurones. Allons-y…
Neuronal rouge:
Un réseau de neurones est construit à partir de plusieurs nœuds interconnectés appelés “Neurones”. Les neurones sont disposés en couche d'entrée, couche cachée et couche de sortie. La couche d'entrée correspond à nos prédicteurs / caractéristiques et la couche de sortie à nos variables de réponse.
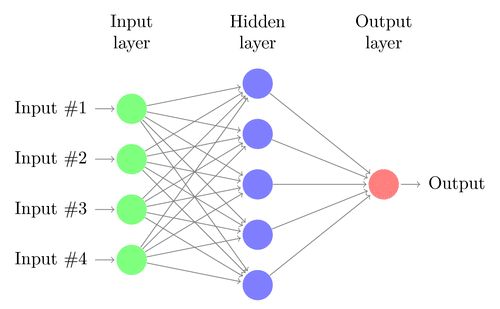
Source de l'image: Google.fr
Perceptron multicouche (MLP):
Le réseau de neurones avec une couche d'entrée, une ou plusieurs couches cachées et une couche de sortie est appelée perceptron multicouche (MLP). MLP est inventé par Frank Rosenblatt L'année de 1957. MLP montré ci-dessous a 5 nœuds d'entrée, 5 nœuds cachés avec deux couches cachées et un nœud de sortie
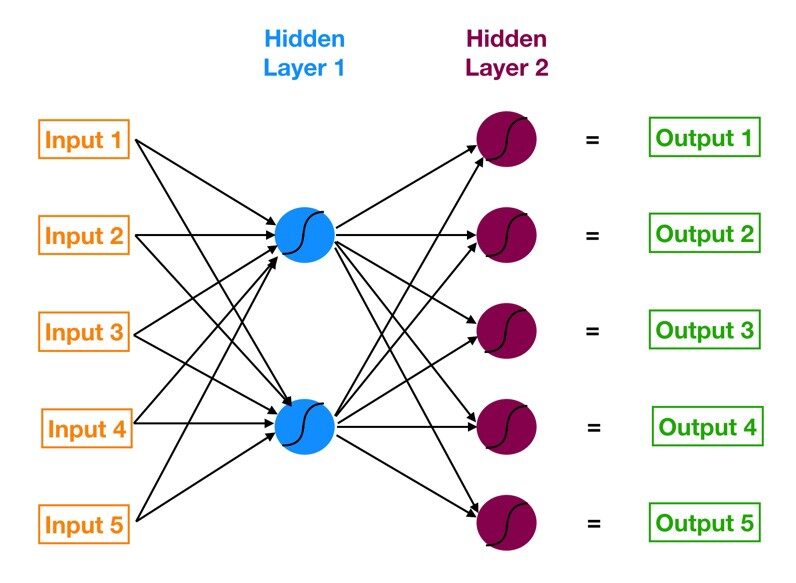
Source de l'image: Google.fr
Comment ce réseau de neurones?
– Les neurones de la couche d'entrée reçoivent des informations entrantes à partir des données qu'ils traitent et distribuent au calques cachés.
– Ces informations, en même temps, est traité par des couches cachées et transmis à la sortie. neurones.
– Les informations de ce réseau de neurones artificiels (ANN) est traité en termes de fonction de réveil. Cette fonction imite en fait les neurones du cerveau.
– Chaque neurone contient une valeur de fonctions de déclenchement et un valeur de seuil.
– Les valeur de seuil est la valeur minimale que doit avoir l'entrée pour qu'elle soit activée.
– La tâche du neurone est d'effectuer une somme pondérée de tous les signaux d'entrée et d'appliquer la fonction d'activation sur la somme avant de la transmettre à la couche suivante. (caché ou sortie).
Comprenons quelle est la somme de pondération.
Disons que nous avons des valeurs 𝑎1, 2, 3, 𝑎4 pour l'entrée et les poids comme 𝑤1, 2, 𝑤3, 𝑤4 comme entrée de l'un des neurones de la couche cachée, disons, alors la somme pondérée est représentée par
= σ 𝑖 = 1à4 𝑤𝑖 * ?? + ??
où: biais dû au nœud
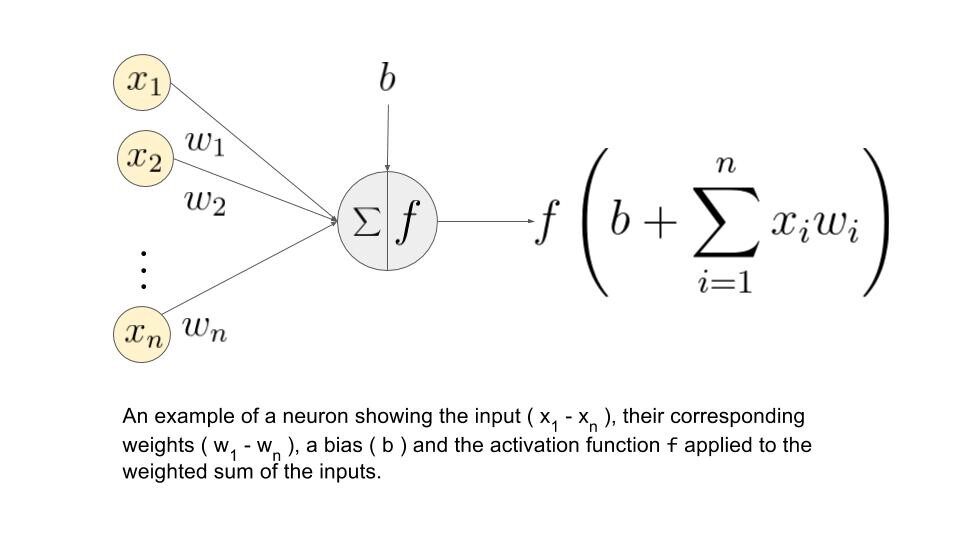
Source de l'image: Google.fr
Quelles sont les fonctions d'activation?
Ces fonctions sont nécessaires pour introduire une non-linéarité dans le réseau. La fonction de déclenchement est appliquée et cette sortie est transmise à la couche suivante.
* Fonctions possibles *
• Sigmoïde: la fonction sigmoïde est dérivable. Produit une sortie entre 0 Oui 1.
• Tangente hyperbolique: La tangente hyperbolique est également dérivable. Cela produit une sortie entre -1 Oui 1.
• ReLU: ReLU est la fonction la plus populaire. ReLU est largement utilisé dans le deep learning.
• Softmax: la fonction softmax est utilisée pour les problèmes de classification de classes multiples. C'est une généralisation de la fonction sigmoïde. Il produit également une sortie entre 0 Oui 1
À présent, allons-y avec notre thème CNN …
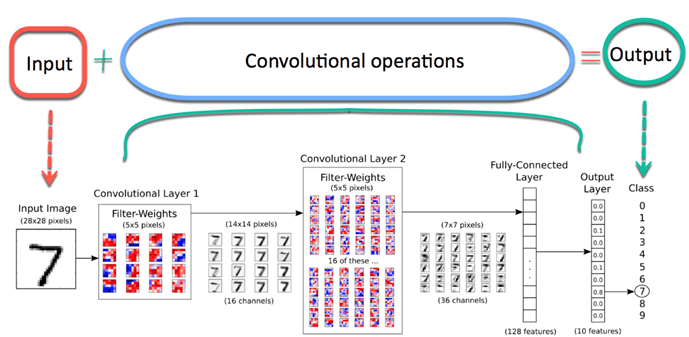
CNN:
Imaginez maintenant qu'il y a une image d'un oiseau, et vous voulez l'identifier si c'est vraiment un oiseau ou autre chose. La première chose que vous devez faire est de transmettre les pixels de l'image sous forme de tableaux à la couche d'entrée du réseau de neurones (Les réseaux MLP sont utilisés pour classer de telles choses). Les couches cachées transportent l'extraction de caractéristiques en effectuant divers calculs et opérations. Il y a plusieurs couches cachées comme la convolution, le ReLU et la couche de regroupement qui effectue l'extraction des caractéristiques de votre image. Ensuite, finalement, il y a une couche entièrement connectée que vous pouvez voir qui identifie l'objet exact dans l'image. Vous pouvez comprendre très facilement à partir de la figure suivante:
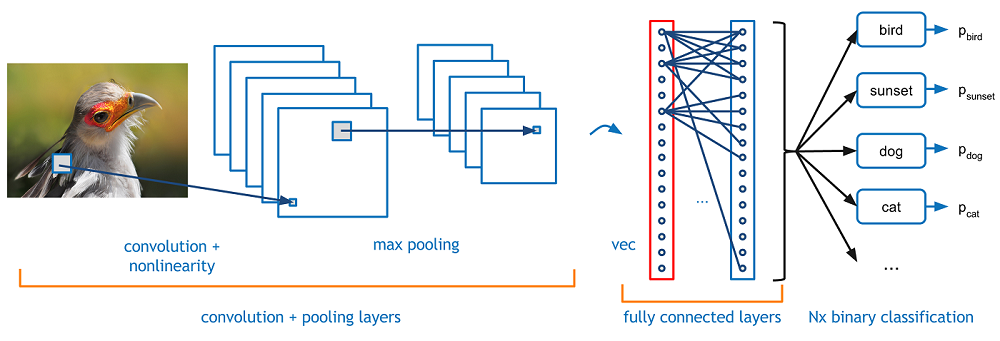
Source de l'image: Google.fr
Convolution:-
L'opération de convolution implique des opérations arithmétiques matricielles et chaque image est représentée comme un tableau de valeurs (pixels).
Comprenons l'exemple:
un = [2,5,8,4,7,9]
b = [1,2,3]
Dans l'opération de convolution, les matrices sont multipliées une par une en termes d'éléments, et le produit est groupé ou additionné pour créer une nouvelle matrice représentant une * b.
Les trois premiers éléments du tableau une maintenant multiplier par les éléments du tableau B. Le produit est ajouté pour obtenir le résultat et est stocké dans une nouvelle matrice de une * b.
Ce processus reste continu jusqu'à ce que l'opération soit terminée..
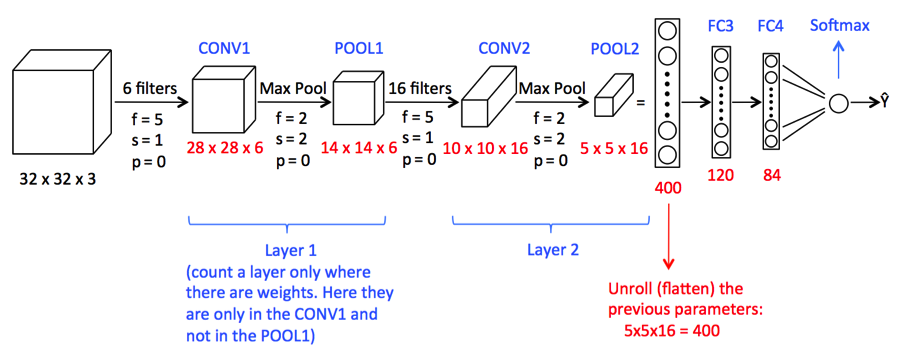
Source de l'image: Google.fr
Regroupement:
Après la circonvolution, il existe une autre opération appelée regroupement. Ensuite, Dans la chaîne, la convolution et le regroupement sont appliqués séquentiellement sur les données afin d'extraire certaines caractéristiques des données. Après les couches séquentielles groupées et convolutives, les données sont aplaties
dans un réseau de neurones de rétroaction également appelé perceptron multicouche.
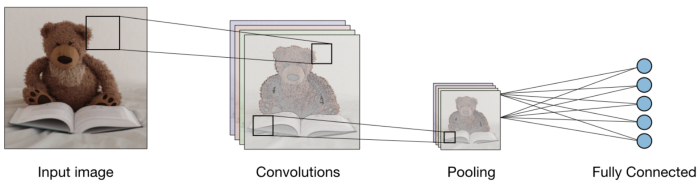
Source de l'image: Google.fr
Jusque là, nous avons vu des concepts qui sont importants pour notre modèle de construction CNN.
Maintenant, nous allons aller de l’avant pour voir une étude de cas CNN.
1) Ici, nous allons importer les bibliothèques nécessaires pour effectuer des tâches CNN.
import NumPy as np
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import TensorFlow as tf
tf.compat.v1.set_random_seed(2019)
2) Ici, nous avons besoin du code suivant pour former le modèle CNN
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16,(3,3),activation = "reprendre" , input_shape = (180,180,3)) ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32,(3,3),activation = "reprendre") ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3),activation = "reprendre") ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128,(3,3),activation = "reprendre"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Aplatir(),
tf.hard.layers.Dense(550,activation="reprendre"), #Adding the Hidden layer
tf.keras.layers.Dropout(0.1,semence = 2019),
tf.hard.layers.Dense(400,activation ="reprendre"),
tf.keras.layers.Dropout(0.3,semence = 2019),
tf.hard.layers.Dense(300,activation="reprendre"),
tf.keras.layers.Dropout(0.4,semence = 2019),
tf.hard.layers.Dense(200,activation ="reprendre"),
tf.keras.layers.Dropout(0.2,semence = 2019),
tf.hard.layers.Dense(5,activation = "softmax") #Ajout de la couche de sortie
])
Une image alambiquée peut être trop grande et, donc, rétrécit sans perdre de caractéristiques ou de motifs, donc le regroupement est fait.
Ici, Créer un réseau neuronal, c’est initialiser le réseau à l’aide du modèle séquentiel Keras.
Aplatir (): l’aplatissement transforme un tableau bidimensionnel d’entités en un vecteur d’entités.
3) Regardons maintenant un résumé du modèle de CNN
modèle.résumé()
Vous imprimerez la sortie suivante
Modèle: "séquentiel" _________________________________________________________________ Couche (taper) Paramètre de forme de sortie # ================================================================= conv2d (Conv2D) (Rien, 178, 178, 16) 448 _________________________________________________________________ max_pooling2d (MaxPooling2D) (Rien, 89, 89, 16) 0 _________________________________________________________________ conv2d_1 (Conv2D) (Rien, 87, 87, 32) 4640 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (Rien, 43, 43, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (Rien, 41, 41, 64) 18496 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (Rien, 20, 20, 64) 0 _________________________________________________________________ conv2d_3 (Conv2D) (Rien, 18, 18, 128) 73856 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (Rien, 9, 9, 128) 0 _________________________________________________________________ flatten (Aplatir) (Rien, 10368) 0 _________________________________________________________________ dense (Dense) (Rien, 550) 5702950 _________________________________________________________________ dropout (Abandonner) (Rien, 550) 0 _________________________________________________________________ dense_1 (Dense) (Rien, 400) 220400 _________________________________________________________________ abandon_1 (Abandonner) (Rien, 400) 0 _________________________________________________________________ dense_2 (Dense) (Rien, 300) 120300 _________________________________________________________________ dropout_2 (Abandonner) (Rien, 300) 0 _________________________________________________________________ dense_3 (Dense) (Rien, 200) 60200 _________________________________________________________________ dropout_3 (Abandonner) (Rien, 200) 0 _________________________________________________________________ dense_4 (Dense) (Rien, 5) 1005 ================================================== ================ Paramètres totaux: 6,202,295 Paramètres entraînables: 6,202,295 Paramètres non entraînables: 0
4) Nous sommes donc obligés de spécifier des optimiseurs.
à partir de tensorflow.keras.optimizers importer RMSprop,EUR,Adam
adam=Adam(lr=0.001)
modèle.compile(optimiseur="Adam", perte ="catégorique_crossentropie", métriques = ['acc'])
L’optimiseur est utilisé pour réduire le coût calculé par entropie croisée
la fonction de perte est utilisée pour calculer l’erreur.
Le terme métriques est utilisé pour représenter l’efficacité du modèle.
5) Dans cette étape, nous verrons comment configurer le répertoire de données et générer des données d’image.
bs=30 #Setting batch size train_dir = "ré:/Science des données/Ensembles de données d’images/FastFood/train/" #Setting training directory validation_dir = "ré:/Science des données/Jeux de données d’images/FastFood/test/" #Setting testing directory from tensorflow.keras.preprocessing.image import ImageDataGenerator # Toutes les images seront redimensionnées par 1./255. train_datagen = ImageDataGenerator( redimensionner = 1.0/255. ) test_datagen = ImageDataGenerator( redimensionner = 1.0/255. ) # Flux d’images d’entraînement par lots de 20 using train_datagen generator #Flow_from_directory function lets the classifier directly identify the labels from the name of the directories the image lies in train_generator=train_datagen.flow_from_directory(train_dir,batch_size=bs,class_mode="catégorique",target_size=(180,180)) # Images de validation de flux par lots de 20 using test_datagen generator validation_generator = test_datagen.flow_from_directory(validation_dir, batch_size=bs, class_mode="catégorique", target_size=(180,180))
La salida será:
Trouvé 1465 images appartenant à 5 Classes. Trouvé 893 images appartenant à 5 Classes.
6) Paso final del modelo de ajuste.
histoire = model.fit(train_generator,
validation_data=validation_generator,
steps_per_epoch=150 // Bs,
époques=30,
validation_steps=50 // Bs,
verbeux=2)
La salida será:
Époque 1/30 5/5 - 4s - perte: 0.8625 - acc: 0.6933 - perte_val: 1.1741 - val_acc: 0.5000 Époque 2/30 5/5 - 3s - perte: 0.7539 - acc: 0.7467 - perte_val: 1.2036 - val_acc: 0.5333 Époque 3/30 5/5 - 3s - perte: 0.7829 - acc: 0.7400 - perte_val: 1.2483 - val_acc: 0.5667 Époque 4/30 5/5 - 3s - perte: 0.6823 - acc: 0.7867 - perte_val: 1.3290 - val_acc: 0.4333 Époque 5/30 5/5 - 3s - perte: 0.6892 - acc: 0.7800 - perte_val: 1.6482 - val_acc: 0.4333 Époque 6/30 5/5 - 3s - perte: 0.7903 - acc: 0.7467 - perte_val: 1.0440 - val_acc: 0.6333 Époque 7/30 5/5 - 3s - perte: 0.5731 - acc: 0.8267 - perte_val: 1.5226 - val_acc: 0.5000 Époque 8/30 5/5 - 3s - perte: 0.5949 - acc: 0.8333 - perte_val: 0.9984 - val_acc: 0.6667 Époque 9/30 5/5 - 3s - perte: 0.6162 - acc: 0.8069 - perte_val: 1.1490 - val_acc: 0.5667 Époque 10/30 5/5 - 3s - perte: 0.7509 - acc: 0.7600 - perte_val: 1.3168 - val_acc: 0.5000 Époque 11/30 5/5 - 4s - perte: 0.6180 - acc: 0.7862 - perte_val: 1.1918 - val_acc: 0.7000 Époque 12/30 5/5 - 3s - perte: 0.4936 - acc: 0.8467 - perte_val: 1.0488 - val_acc: 0.6333 Époque 13/30 5/5 - 3s - perte: 0.4290 - acc: 0.8400 - perte_val: 0.9400 - val_acc: 0.6667 Époque 14/30 5/5 - 3s - perte: 0.4205 - acc: 0.8533 - perte_val: 1.0716 - val_acc: 0.7000 Époque 15/30 5/5 - 4s - perte: 0.5750 - acc: 0.8067 - perte_val: 1.2055 - val_acc: 0.6000 Époque 16/30 5/5 - 4s - perte: 0.4080 - acc: 0.8533 - perte_val: 1.5014 - val_acc: 0.6667 Époque 17/30 5/5 - 3s - perte: 0.3686 - acc: 0.8467 - perte_val: 1.0441 - val_acc: 0.5667 Époque 18/30 5/5 - 3s - perte: 0.5474 - acc: 0.8067 - perte_val: 0.9662 - val_acc: 0.7333 Époque 19/30 5/5 - 3s - perte: 0.5646 - acc: 0.8138 - perte_val: 0.9151 - val_acc: 0.7000 Époque 20/30 5/5 - 4s - perte: 0.3579 - acc: 0.8800 - perte_val: 1.4184 - val_acc: 0.5667 Époque 21/30 5/5 - 3s - perte: 0.3714 - acc: 0.8800 - perte_val: 2.0762 - val_acc: 0.6333 Époque 22/30 5/5 - 3s - perte: 0.3654 - acc: 0.8933 - perte_val: 1.8273 - val_acc: 0.5667 Époque 23/30 5/5 - 3s - perte: 0.3845 - acc: 0.8933 - perte_val: 1.0199 - val_acc: 0.7333 Époque 24/30 5/5 - 3s - perte: 0.3356 - acc: 0.9000 - perte_val: 0.5168 - val_acc: 0.8333 Époque 25/30 5/5 - 3s - perte: 0.3612 - acc: 0.8667 - perte_val: 1.7924 - val_acc: 0.5667 Époque 26/30 5/5 - 3s - perte: 0.3075 - acc: 0.8867 - perte_val: 1.0720 - val_acc: 0.6667 Époque 27/30 5/5 - 3s - perte: 0.2820 - acc: 0.9400 - perte_val: 2.2798 - val_acc: 0.5667 Époque 28/30 5/5 - 3s - perte: 0.3606 - acc: 0.8621 - perte_val: 1.2423 - val_acc: 0.8000 Époque 29/30 5/5 - 3s - perte: 0.2630 - acc: 0.9000 - perte_val: 1.4235 - val_acc: 0.6333 Époque 30/30 5/5 - 3s - perte: 0.3790 - acc: 0.9000 - perte_val: 0.6173 - val_acc: 0.8000
La función anterior entrena la red neuronal utilizando el conjunto de entrenamiento y evalúa su rendimiento en el conjunto de prueba. Las funciones devuelven dos métricas para cada época 'acc’ y 'val_acc’ qui sont la précision des prédictions obtenues dans l'ensemble d'apprentissage et la précision atteinte dans l'ensemble de test, respectivement.
conclusion:
Pourtant, nous voyons qu'il a été rencontré avec une précision suffisante. Cependant, tout le monde peut exécuter ce modèle en augmentant le nombre d'époques ou tout autre paramètre.
j'espère que vous avez aimé mon article. Partage avec tes amis, collègues.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





