introduction
Ça fait longtemps, Je faisais le modèle prédictif en utilisant la régression linéaire et j'ai trouvé une variable dont le coefficient de régression non standardisé (bêta ou estimation) proche de zéro, mais après quelques analyses, Je trouve que c'est statistiquement significatif (signifie la valeur p <0.05 ). Sabemos que si una variable es significativa para un modelo en particular, significa que el valor de su coeficiente es significativo y distinto de cero. Entonces, la pregunta que ocurre es "¿Por qué el valor del coeficiente es cercano a cero pero esa variable es significativa para nuestro modelo predictivo?".
La solution à cette question réside dans la différence entre les coefficients de régression standardisés et non standardisés.. Ensuite, dans ce post, nous verrons les concepts de base derrière ces coefficients et en quoi ils diffèrent les uns des autres avec leurs avantages et inconvénients.
Le concept de normalisation ou de coefficients standard entre en jeu lorsque les variables indépendantes ou le prédicteur d'un modèle particulier sont exprimés dans différentes unités.. Par exemple, disons que nous avons trois caractéristiques indépendantes, a savoir, la taille, âge et poids. Votre taille est en pouces, votre poids en kilogrammes et votre âge en années. Si nous voulons catégoriser ces prédicteurs en fonction du coefficient non standardisé (qui vient directement lorsque nous formons un modèle de régression), ce ne serait pas une comparaison équitable puisque les unités de tous les prédicteurs sont différentes.
Coefficients de régression non standardisés
1. Que sont les coefficients de régression non standardisés?
Les coefficients non standardisés sont ceux qui sont produits par le modèle de régression linéaire après son apprentissage en utilisant les variables indépendantes qui sont mesurées sur leurs échelles d'origine., En d'autres termes, dans les mêmes unités dans lesquelles l'ensemble de données est extrait de la source pour entraîner le modèle.
– Le coefficient non standardisé ne doit pas être utilisé pour exclure ou catégoriser les prédicteurs (également appelées variables indépendantes), puisqu'il n'élimine pas l'unité de mesure.
Par exemple, Prenons un exemple hypothétique où nous voulons prédire les revenus (en roupies) d'une personne en fonction de son âge (dans des années), la taille (et cm) Et poids (en kg). Ensuite, ici, les entrées pour notre modèle de régression sont l'âge, hauteur et largeur, et la production est un revenu. Ensuite,
Revenu (roupies) = A0 + a1 * âge (ans) + a2 * la taille (cm) + a3 * poids (kg) + e (eqn-1)
2. Comment interpréter les coefficients de régression non standardisés?
Ils sont utilisés pour interpréter l'effet de chaque variable indépendante sur le résultat. (réponse / Sortir). Son interprétation est simple et intuitive.
– Toutes les autres variables sont maintenues constantes, un changement de 1 unité à Xi (prédicteurs) implique qu'il y a un changement moyen des unités ai dans Y (Résultat).
Dans l'exemple ci-dessus, et a1 = 0.3, a2 = 0.2 y a3 = 0.4 (et nous supposons qu'ils sont tous statistiquement significatifs), alors nous interprétons ces coefficients comme:
Pour avoir 1 année est associée à une augmentation de 0,3 en revenu, en supposant que les autres variables sont constantes (signifie qu'il n'y a pas de changement de taille et de poids).
Équivalent, on peut aussi interpréter le coefficient pour d'autres variables indépendantes.
Représente le montant par lequel la variable dépendante change si nous modifions la variable indépendante d'une unité, en gardant les autres variables indépendantes constantes..
3. Limites des coefficients de régression non standardisés
– Les coefficients non standardisés sont excellents pour interpréter le lien entre une variable indépendante X et un résultat Y. Malgré cela, ne sont pas utiles pour comparer l'effet d'une variable indépendante avec une autre dans le modèle.
– Par exemple, Quelle variable a le plus d'impact sur le revenu, l'âge, taille ou poids?
Nous pouvons essayer de répondre à cette question en examinant l'équation-1 et supposer à nouveau que a1 = 0.3, a2 = 0.2 y a3 = 0.4, nous concluons que:
“Une augmentation de 20 cm de hauteur a le même effet sur la prise de poids 10 fois”
Même comme ça, Cela ne répond pas à la question de savoir quelle variable affecte le plus le revenu.
Spécifiquement, l'affirmation selon laquelle « l'effet de la prise de poids sur 10 fois = l'effet de l'augmentation de la hauteur de 20 cm » n'a aucun sens sans préciser à quel point il est difficile d'augmenter la hauteur de 20 cm, spécifiquement pour quelqu'un qui ne connaît pas cette échelle.
Ensuite, finalement, nous concluons qu'une comparaison directe des coefficients de régression pour l'une ou l'autre des deux variables indépendantes n'a aucun sens ou n'est pas utile puisque ces variables indépendantes sont sur des échelles différentes (Age en années, poids en kg et taille en cm).
Il s'avère que les effets de ces variables peuvent être comparés en utilisant la version standardisée de leurs coefficients. Et c'est ce dont nous allons discuter ensuite.
Coefficients de régression standardisés
1. Que sont les coefficients de régression standardisés?
Les coefficients de régression standardisés sont obtenus par apprentissage (ou courir) un modèle de régression linéaire sous la forme standardisée des variables.
Les variables standardisées sont calculées en soustrayant la moyenne et en divisant par l'écart type de chaque observation., En d'autres termes, calculer le score Z. je voudrais dire 0 et écart type 1. Ensuite, ils ne représentent pas leurs échelles d'origine car ils n'ont pas d'unité.
Pour chaque observation “j” de la variable X, nous calculons le z-score en utilisant la formule:
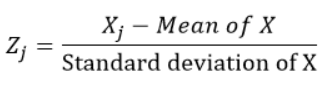
2. Quelles variables devons-nous standardiser pour trouver les coefficients de régression standardisés, En d'autres termes, à la fois le prédicteur et la solution ou l'un d'entre eux?
Oui, nous normalisons à la fois les variables dépendantes (réponse) comme les indépendants (prédicteurs) avant d'exécuter le modèle de régression linéaire (puisque c'est la pratique largement acceptée lorsque l'on veut trouver la forme standardisée des variables).
3. Comment interpréter les coefficients de régression standardisés?
L'interprétation des coefficients de régression standardisés n'est pas intuitive par rapport à leurs versions non standardisées:
Un changement de 1 l'écart type de X est associé à un changement des écarts types de Y.
Noter:
– S'il y a une variable catégorielle au lieu d'une variable numérique dans notre analyse, alors son coefficient standardisé ne peut pas être interprété car cela n'a aucun sens de changer X en 1 écart-type. En général, ce n'est pas un obstacle pour notre modèle, puisque ces coefficients ne sont pas destinés à être interprétés individuellement, mais à comparer entre elles pour se faire une idée de la pertinence de chaque variable dans le modèle de régression linéaire.
Le coefficient standardisé est mesuré en unités d'écart type. Une valeur bêta de 2.25 indique qu'un changement d'un écart type dans la variable indépendante entraîne une augmentation de 2.25 écarts types dans la variable dépendante.
4. Quelle est l'utilisation réelle des coefficients standardisés?
Ils sont principalement utilisés pour catégoriser les prédicteurs (o variables indépendantes ou explicatives) puisqu'ils éliminent les unités de mesure des variables indépendantes et dépendantes). On peut catégoriser les variables indépendantes avec une valeur absolue de coefficients standardisés. La variable la plus importante aura la valeur absolue maximale du coefficient standardisé.
Par exemple:
Y =0 + b1 X1 + b2 X2 + e
Si les coefficients normalisés β1 = 0.5 oui2 = 1, nous pouvons conclure que:
X2 est deux fois plus important que X1 dans la prévision de Y, en supposant que les deux X1 et X2 suivent à peu près la même distribution et leurs écarts types ne sont pas si différents.
5. Limites des coefficients de régression standardisés
Les coefficients standardisés sont trompeurs si les variables du modèle ont des écarts types différents, cela signifie que toutes les variables ont des distributions différentes.
Jetez un œil à la prochaine équation de régression linéaire:
Revenu ($) =0 + b1 Âge (ans) + b2 De l'expérience (ans) + e
Parce que nos variables indépendantes Age et Expérience sont sur la même échelle (ans) et s'il est raisonnable de supposer que leurs écarts types diffèrent grandement, alors pour ce cas:
– Ses coefficients non standardisés doivent être utilisés pour comparer sa pertinence / influence sur le modèle.
– La standardisation de ces variables ferait, en réalité, qui étaient à une autre échelle (des écarts types différents ou suit une distribution différente)
Calcul des coefficients normalisés
1. Pour la régression linéaire (une autre approche, puisque nous voyons un focus dans la partie précédente du post)
Le coefficient standardisé est obtenu en multipliant le coefficient non standardisé par le rapport des écarts types de la variable indépendante et de la variable dépendante..

2. Pour la régression logistique

Remarques finales
Cet article couvrait quelques concepts de base mais nécessaires lorsque l'on travaille sur un projet réel en apprentissage automatique et en intelligence artificielle.. J'espère que vous avez très bien compris les concepts expliqués dans ce post. Dans ce post dans la dernière partie, Nous ne voyons que la formulation liée aux concepts mais nous n'approfondissons pas beaucoup les mathématiques qui les sous-tendent, Nous discuterons de cette partie dans un autre post.
Si vous avez des questions, Faites le moi savoir dans la section commentaire!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





