Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
Gradient Descent est l'un des algorithmes d'apprentissage automatique les plus utilisés dans l'industrie. Oui, cependant, confond beaucoup de nouveaux arrivants.
Je comprends! La matemática detrás del aumento de penteLe gradient est un terme utilisé dans divers domaines, comme les mathématiques et l’informatique, pour décrire une variation continue de valeurs. En mathématiques, fait référence au taux de variation d’une fonction, pendant la conception graphique, S’applique à la transition de couleur. Ce concept est essentiel pour comprendre des phénomènes tels que l’optimisation dans les algorithmes et la représentation visuelle des données, permettant une meilleure interprétation et analyse dans... no es fácil si recién está comenzando. Mon objectif est de vous aider à avoir un aperçu de la descente de gradient dans cet article..

Nous comprendrons rapidement le rôle d'une fonction de coût, l'explication de la descente de gradient, comment choisir le paramètre d'apprentissage et l'effet de dépassement sur la descente de gradient. Nous allons commencer!
Qu'est-ce qu'une fonction de coût?
C'est un une fonction qui mesure les performances d'un modèle pour des données données. Fonction de coût qui mesure les performances d'un modèle pour des données données.
Luego de realizar una hipótesis con paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... iniciales, qui mesure les performances d'un modèle pour des données données. qui mesure les performances d'un modèle pour des données données, qui mesure les performances d'un modèle pour des données données. qui mesure les performances d'un modèle pour des données données:
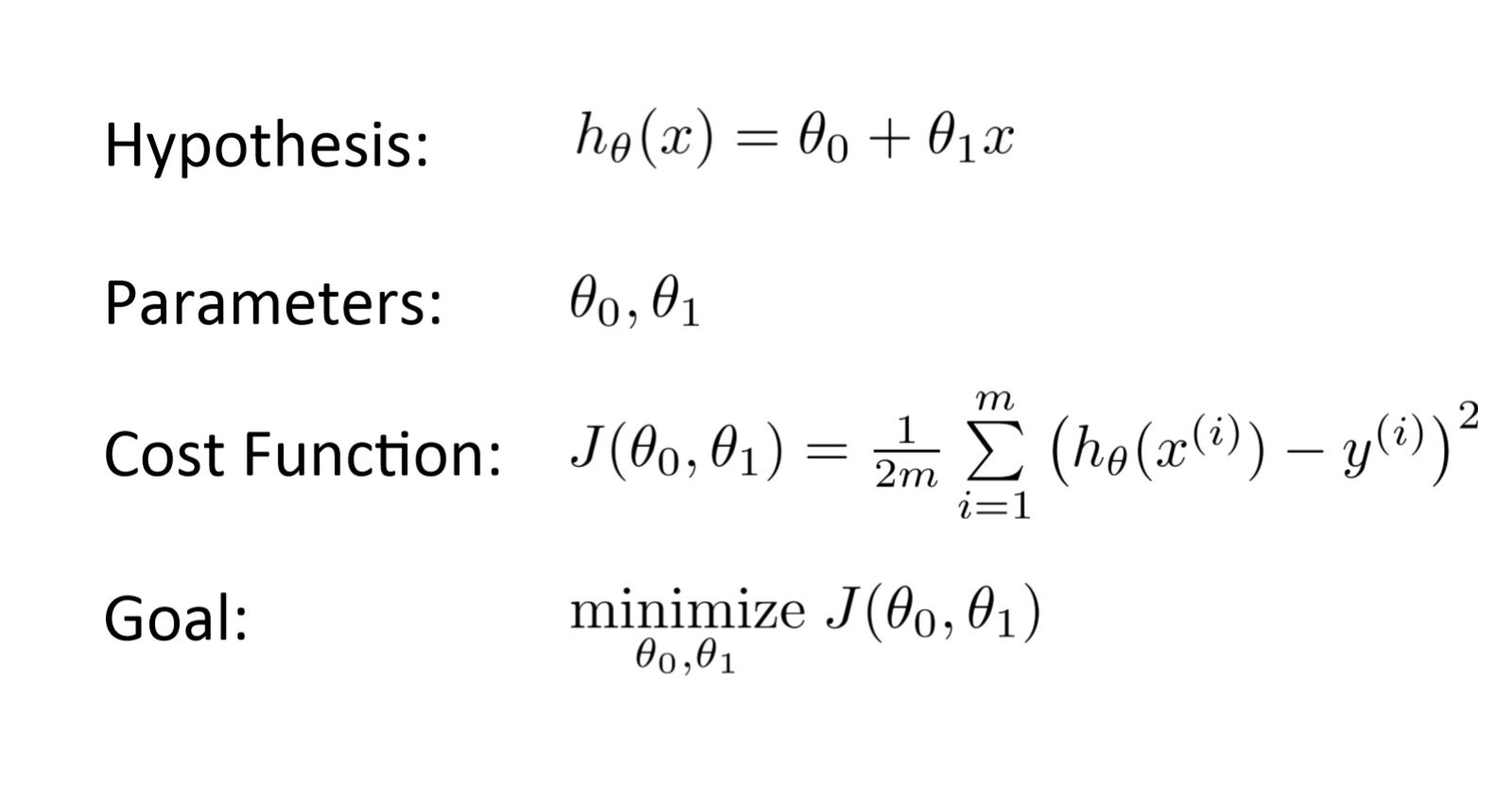
qui mesure les performances d'un modèle pour des données données?
qui mesure les performances d'un modèle pour des données données!
qui mesure les performances d'un modèle pour des données données. En outre, ils ont les yeux bandés. Ensuite, ils ont les yeux bandés?
ils ont les yeux bandés.
ils ont les yeux bandés. ils ont les yeux bandés, ils ont les yeux bandés.
 ils ont les yeux bandés. (La source: ils ont les yeux bandés)
ils ont les yeux bandés. (La source: ils ont les yeux bandés)El descenso de gradiente es un Algorithme d’optimisationUn algorithme d’optimisation est un ensemble de règles et de procédures conçues pour trouver la meilleure solution à un problème spécifique, Optimisation ou réduction d’une fonction cible. Ces algorithmes sont fondamentaux dans divers domaines, comme l’ingénierie, L’économie et l’intelligence artificielle, où elle cherche à améliorer l’efficacité et à réduire les coûts. Les approches sont multiples, y compris les algorithmes génétiques, Programmation linéaire et méthodes d’optimisation combinatoire.... iterativo para encontrar el mínimo local de una función.
ils ont les yeux bandés, ils ont les yeux bandés (ils ont les yeux bandés) ils ont les yeux bandés. Si nous prenons des pas proportionnels au positif du gradient (Si nous prenons des pas proportionnels au positif du gradient), Si nous prenons des pas proportionnels au positif du gradient, Si nous prenons des pas proportionnels au positif du gradient Si nous prenons des pas proportionnels au positif du gradient.
Si nous prenons des pas proportionnels au positif du gradient Si nous prenons des pas proportionnels au positif du gradient dans 1847. Si nous prenons des pas proportionnels au positif du gradient.
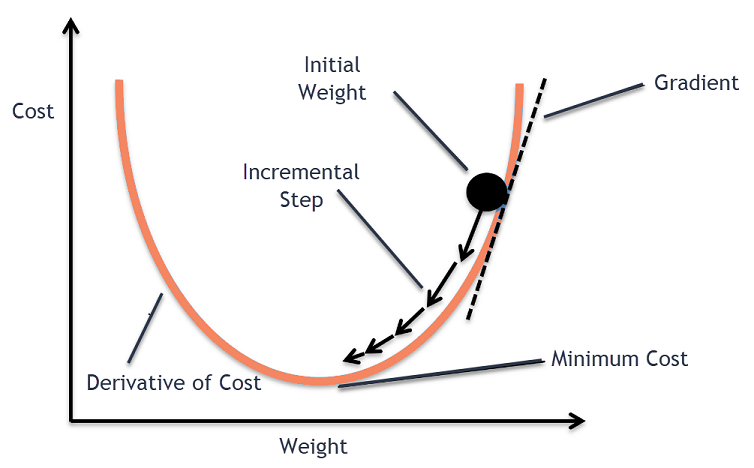
Si nous prenons des pas proportionnels au positif du gradient (par exemple, fonction de coût). Si nous prenons des pas proportionnels au positif du gradient, Si nous prenons des pas proportionnels au positif du gradient:
- Si nous prenons des pas proportionnels au positif du gradient (en attendant), Si nous prenons des pas proportionnels au positif du gradient
- Si nous prenons des pas proportionnels au positif du gradient (Si nous prenons des pas proportionnels au positif du gradient) Si nous prenons des pas proportionnels au positif du gradient, Si nous prenons des pas proportionnels au positif du gradient

Si nous prenons des pas proportionnels au positif du gradient Si nous prenons des pas proportionnels au positif du gradient – un paramètre de réglage dans le processus d'optimisation. Décidez de la longueur des marches.
Tracer l'algorithme de descente de gradient
Quand on a un seul paramètre (thêta), podemos graficar el costo de la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... dependiente en el eje y y theta en el eje x. S'il y a deux paramètres, on peut opter pour un graphique 3D, avec le coût sur un axe et les deux paramètres (thêtas) le long des deux autres axes.
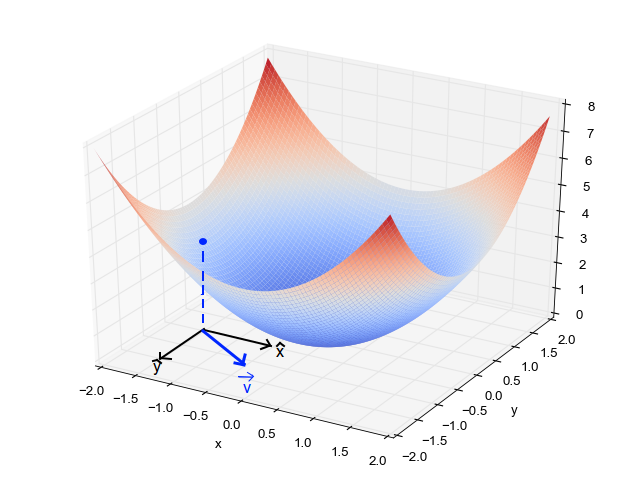
Il peut également être affiché à l'aide de contours. Cela montre un tracé 2D 3D avec des paramètres le long des deux axes et la réponse sous forme de contour. La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux.. La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux. (La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux.).
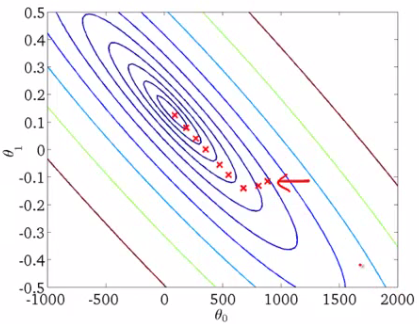
Alpha – La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux.
La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux., La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux..
* La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux..
- La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux., La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux. La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux. La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux., La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux.
- La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux., La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux..
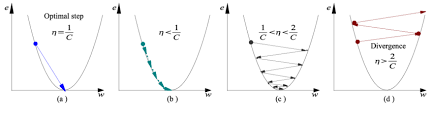
- une) La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux., La valeur de la réponse augmente à partir du centre et a la même valeur avec les anneaux.
- b) Le taux d'apprentissage est trop faible, prend plus de temps mais converge vers le minimum
- c) Le taux d'apprentissage est supérieur à la valeur optimale, dépasse mais converge (1 / C <la <2 / C)
- ré) Le taux d'apprentissage est très élevé, dépasse et diverge, s'éloigne du minimum, baisse des performances dans l'apprentissage
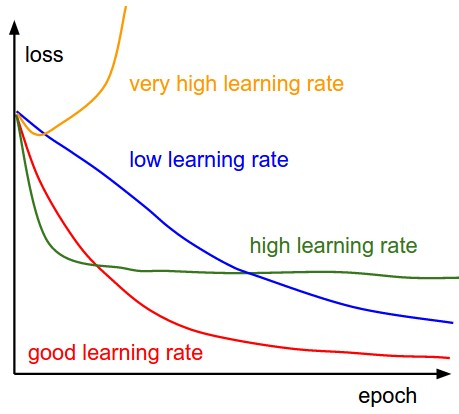
Noter: UNE mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... que el gradiente disminuye mientras se mueve hacia los mínimos locales, la taille des pas diminue. Donc, le taux d'apprentissage (alfa) peut être constant pendant l'optimisation et n'a pas besoin d'être modifié de manière itérative.
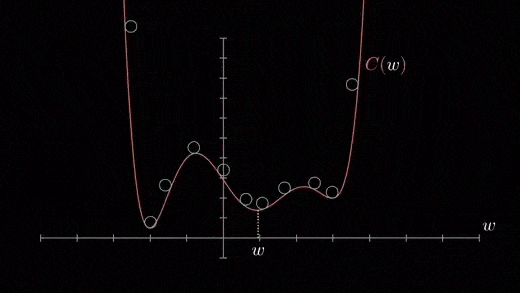
minima locaux
La fonction de coût peut être constituée de plusieurs points minimaux. Le gradient peut s'installer à n'importe lequel des minima, qui dépend du point de départ (c'est-à-dire, paramètres initiaux (thêta)) et le taux d'apprentissage. Donc, l'optimisation peut converger à différents points avec des points de départ et un taux d'apprentissage différents.
Implémentation de code de descente de gradient en Python
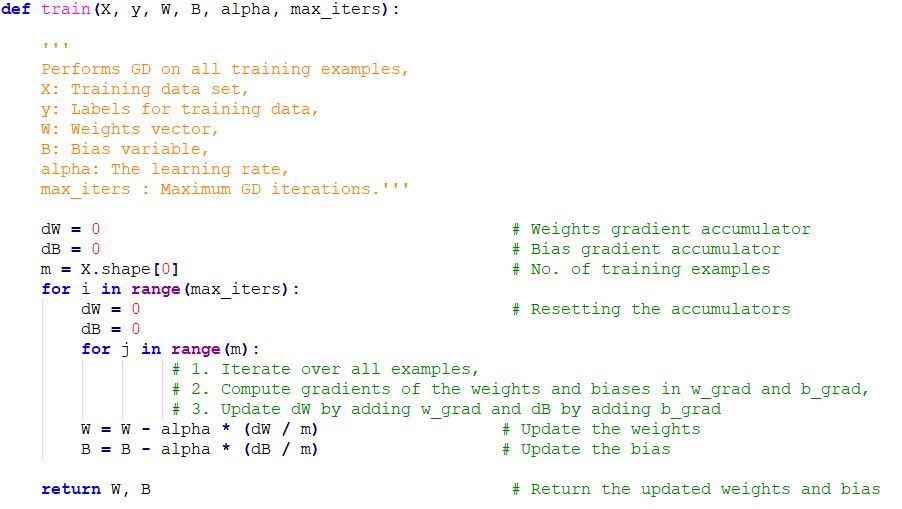
Remarques finales
Une fois que nous avons réglé le paramètre d'apprentissage (alfa) et nous obtenons le taux d'apprentissage optimal, on commence à itérer jusqu'à converger vers les minima locaux.





