introduction
L'intelligence artificielle et l'apprentissage automatique seront notre plus grande aide au cours de la prochaine décennie !!
Ce matin, Je lisais un article qui rapportait qu'un système d'intelligence artificielle avait gagné contre 20 les avocats et les avocats étaient vraiment heureux que l'intelligence artificielle puisse s'occuper d'une partie répétitive de leurs rôles et les aider à travailler sur des problèmes complexes. Ces avocats étaient ravis que l'intelligence artificielle leur permette d'exercer des fonctions plus satisfaisantes.
Aujourd'hui, je vais partager un exemple similaire: comment compter le nombre de personnes dans une foule en utilisant Apprentissage profond et vision par ordinateur? Mais, avant de faire ça, Développons une idée de la facilité de la vie pour un scientifique qui compte les foules.
Agir comme un scientifique qui compte les foules
Commençons!
Pouvez-vous m'aider à compter / estimer le nombre de personnes sur cette image qui assisteront à cet événement?

D'accord, qu'en est-il de celui-ci?

La source: Ensemble de données ShanghaiTech
Tu t'y prends. A la fin de ce tutoriel, nous allons créer un algorithme de comptage de foule avec une précision étonnante (comparé aux humains comme toi et moi). Utiliserez-vous un tel assistant?
PD Cet article suppose que vous avez une compréhension de base du fonctionnement des réseaux de neurones convolutifs. (CNN). Vous pouvez vous référer à l'article ci-dessous pour plus d'informations sur ce sujet avant de continuer.:
Table des matières
- Qu'est-ce que le comptage de foule?
- Pourquoi le comptage de foule est-il nécessaire?
- Compréhension des différentes techniques de vision par ordinateur pour le comptage de foule
- Architecture CSRNet et méthodes de formation
- Construire votre propre modèle de comptage de foule en Python
Cet article est très inspiré de l'article: CSRNet: Réseaux de neurones convolutifs dilatés pour comprendre des scènes très encombrées.
Qu'est-ce que le comptage de foule?
Le comptage de foule est une technique pour compter ou estimer le nombre de personnes dans une image. Prenez un moment pour analyser l'image suivante:
La source: Ensemble de données ShanghaiTech
Pouvez-vous me donner un nombre approximatif de combien de personnes sont dans la boîte? Oui, y compris ceux présents en arrière-plan. La méthode la plus directe consiste à compter manuellement chaque personne, mais est-ce que cela a un sens pratique? C'est presque impossible quand la foule est si grande!
Les scientifiques de la foule (Oui, C'est un vrai titre de poste!) Ils comptent le nombre de personnes dans certaines parties d'une image puis extrapolent pour arriver à une estimation. Plus communément, nous avons dû nous fier à des mesures brutes pour estimer ce nombre pendant des décennies.
Il doit sûrement y avoir une approche meilleure et plus précise.
S'il y a!
Bien que nous n'ayons toujours pas d'algorithmes pouvant nous donner le nombre EXACT, la majorité vision par ordinateur Les techniques peuvent produire des estimations d'une précision impressionnante. Comprenons d'abord pourquoi le comptage de foule est important avant de plonger dans l'algorithme qui le sous-tend..
Pourquoi le comptage de foule est-il utile?
Comprenons l'utilité du comptage de foule avec un exemple. Imagine ça: votre entreprise vient de terminer d'héberger une conférence sur la science des mégadonnées. De nombreuses sessions différentes ont eu lieu pendant l'événement.
Il vous est demandé d'analyser et d'estimer le nombre de personnes ayant assisté à chaque session. Cela aidera votre équipe à comprendre quels types de sessions ont attiré les plus grandes foules. (et lesquels ont échoué dans ce sens). Cela façonnera la conférence de l'année prochaine, C'est donc une tâche importante!

Il y avait des centaines de personnes à l'événement, Les compter manuellement prendra des jours! C'est là qu'interviennent vos compétences en tant que data scientist.. Il a réussi à prendre des photos de la foule à chaque tournage et à créer un modèle de vision par ordinateur pour faire le reste !!
Il existe de nombreux autres scénarios dans lesquels les algorithmes de comptage de foule modifient le fonctionnement des industries.:
- Compter le nombre de personnes qui assistent à un événement sportif
- Estimez combien de personnes ont assisté à une inauguration ou à une marche (manifestations politiques, peut-être)
- Surveillance des zones à fort trafic
- Aider à la dotation en personnel et à l'affectation des ressources.
Pouvez-vous penser à d'autres cas d'utilisation? Laissez-moi savoir dans la section commentaire ci-dessous!! Nous pouvons nous connecter et essayer de comprendre comment nous pouvons utiliser les techniques de comptage de foule sur votre scène..
Compréhension des différentes techniques de vision par ordinateur pour le comptage de foule
En termes générales, il existe actuellement quatre méthodes que nous pouvons utiliser pour compter le nombre de personnes dans une foule:
1. Méthodes basées sur la détection
Ici, nous utilisons un détecteur semblable à une fenêtre mobile pour identifier les personnes dans une image et compter combien il y en a. Les méthodes utilisées pour la détection nécessitent des classificateurs bien entraînés capables d'extraire des caractéristiques de bas niveau. Bien que ces méthodes fonctionnent bien pour détecter les visages, ne fonctionne pas bien dans les images surpeuplées, puisque la plupart des objets cibles ne sont pas clairement visibles.
2. Méthodes basées sur la régression
Nous n'avons pas pu extraire les fonctionnalités de bas niveau avec l'approche ci-dessus. Les méthodes basées sur la régression triomphent ici. Nous découpons d'abord les patchs de l'image, puis, pour chaque patch, nous extrayons les caractéristiques de bas niveau.
3. Méthodes basées sur l'estimation de la densité
Nous créons d'abord une carte de densité pour les objets. Alors, l'algorithme apprend un mappage linéaire entre les caractéristiques extraites et leurs cartes de densité d'objets. Nous pouvons également utiliser la régression de forêt aléatoire pour apprendre la cartographie non linéaire.
4. Méthodes basées sur CNN
Ah, bons et fiables réseaux de neurones convolutifs (CNN). Au lieu de regarder les taches d'une image, nous créons une méthode de régression de bout en bout en utilisant CNN. Cela prend l'image entière en entrée et affiche directement le nombre de personnes. Les CNN fonctionnent très bien avec les tâches de régression ou de classification, et ils ont également fait leurs preuves dans la génération de cartes de densité.
CSRNet, une technique que nous allons mettre en œuvre dans cet article, implémente un CNN plus profond pour capturer des fonctionnalités de haut niveau et générer des cartes de densité de haute qualité sans augmenter la complexité du réseau. Comprenons ce qu'est CSRNet avant de passer à la section de codage.
Comprendre l'architecture CSRNet et la méthode de formation
CSRNet utilise VGG-16 comme interface en raison de ses capacités d'apprentissage par transfert élevées. La taille de sortie VGG est un cinquième de la taille d'entrée d'origine. CSRNet utilise également des couches convolutives dilatées sur le dos.
Mais, Qu'est-ce que c'est que les circonvolutions dilatées? C'est une bonne question. Considérez l'image suivante:
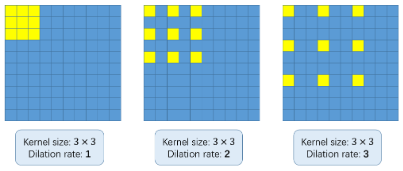
Le concept de base de l'utilisation des convolutions dilatées est d'agrandir le noyau sans augmenter les paramètres. Ensuite, si le taux de dilatation est 1, nous prenons le noyau et le convertissons en l'image entière. Tandis que, si nous augmentons le taux de dilatation à 2, le noyau s'étend comme indiqué dans l'image ci-dessus (suivez les étiquettes sous chaque image). Peut être une alternative au regroupement de calques.
Mathématiques sous-jacentes (conseillé, mais facultatif)
Je vais prendre un moment pour expliquer comment fonctionnent les maths. Notez que ce n'est pas obligatoire pour implémenter l'algorithme en Python, mais je vous recommande d'apprendre l'idée sous-jacente. Cela vous sera utile lorsque vous aurez besoin d'ajuster ou de modifier votre modèle..
Supposons que nous ayons une entrée x (m, m), un filtre w (je, j) et le taux de dilatation r. La sortie et (m, m) ce sera:
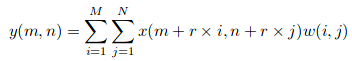
On peut généraliser cette équation en utilisant un noyau (k * k) avec un taux de dilatation r. Le noyau s'élargit à:
([k + (k-1)*(r-1)] * [k + (k-1)*(r-1)])
Ainsi, la vérité de base a été générée pour chaque image. La tête de chaque personne dans une image donnée est floue à l'aide d'un noyau gaussien. Toutes les images sont recadrées à 9 patchs et la taille de chaque patch est un quart de la taille de l'image d'origine. Avec moi jusqu'à maintenant?
Les premiers 4 les patchs sont divisés en 4 les chambres et les autres 5 les patchs sont découpés au hasard. Finalement, le miroir de chaque patch est pris pour dupliquer l'ensemble d'entraînement.
Ce, en peu de mots, sont les détails de l'architecture derrière CSRNet. Ensuite, nous verrons les détails de votre formation, y compris la métrique d'évaluation utilisée.
La descente de gradient stochastique est utilisée pour former CSRNet en tant que structure de bout en bout. Pendant la formation, le taux d'apprentissage fixe est fixé à 1e-6. La fonction de perte est prise comme la distance euclidienne pour mesurer la différence entre la vérité terrain et la carte de densité estimée. Ceci est représenté comme:
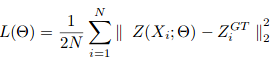
où N est la taille du lot d'apprentissage. La métrique d'évaluation utilisée dans CSRNet est MAE et MSE, c'est-à-dire, erreur absolue moyenne et erreur quadratique moyenne. Ceux-ci sont donnés par:
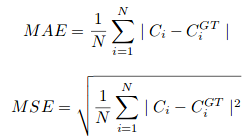
Ici, Ci est le nombre estimé:
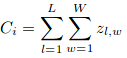
L et W sont la largeur de la carte de densité prédite.
Notre modèle va d'abord prédire la carte de densité pour une image donnée. La valeur du pixel sera 0 s'il n'y a personne. Une certaine valeur prédéfinie sera attribuée si ce pixel correspond à une personne. Ensuite, calculer les valeurs totales de pixels correspondant à une personne nous donnera le nombre de personnes dans cette image. Impressionnant, vérité?
Et maintenant, Mesdames et Messieurs, Il est temps de construire enfin notre propre modèle de comptage de foule !!
Construire votre propre modèle de comptage de foule
Prêt avec votre ordinateur portable allumé?
Nous allons implémenter CSRNet dans l'ensemble de données ShanghaiTech. Celui-ci contient 1198 images annotées à partir d'un total combiné de 330,165 gens. Vous pouvez télécharger l'ensemble de données à partir de ici.
Utilisez le bloc de code suivant pour cloner le référentiel CSRNet-pytorch. Contient tout le code pour créer l'ensemble de données, entraîner le modèle et valider les résultats:
clone git https://github.com/leeyeehoo/CSRNet-pytorch.git
Se il vous plaît installer MIRACLES Oui PyTorche avant de continuer. Ce sont l'épine dorsale du code que nous utiliserons ensuite.
À présent, déplacez l'ensemble de données vers le référentiel que vous avez cloné précédemment et décompressez-le. Alors, nous devrons créer les valeurs de vérité de base. Les make_dataset.ipynb le fichier est notre sauveur. Nous n'avons qu'à apporter des modifications mineures à ce bloc-notes:
#définir la racine sur l'ensemble de données de Shanghai que vous avez téléchargé # changer le chemin racine selon votre emplacement de jeu de données racine="/accueil/pulkit/CSRNet-pytorch/"
À présent, générons les valeurs réelles de base pour les images dans part_A et part_B:
La génération de la carte de densité pour chaque image est un pas de temps. Alors préparez-vous une tasse de café pendant que le code s'exécute.
Jusqu'à maintenant, nous avons généré les valeurs de vérité de base pour les images dans part_A. Nous ferons de même avec les images part_B. Mais avant ça, Regardons un exemple d'image et traçons votre carte thermique réelle du sol.:
plt.imshow(Image.ouverte(img_paths[0]))
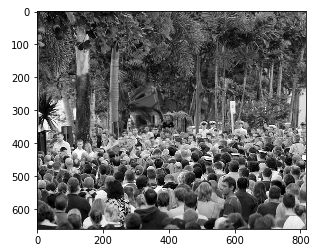
Les choses deviennent intéressantes!
gt_file = h5py.Fichier(img_paths[0].remplacer('.jpg','.h5').remplacer('images','vérité-terrain'),'r')
vérité de terrain = np.asarray(fichier_gt['densité'])
plt.imshow(vérité fondamentale,cmap=CM.jet)
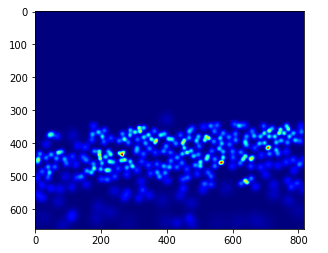
Comptons combien de personnes sont présentes dans cette image:
np.sum(vérité fondamentale)
270.32568
De la même manière, nous allons générer des valeurs pour part_B:
À présent, nous avons les images, ainsi que leurs valeurs de vérité fondamentales correspondantes. Il est temps de former notre modèle!
Nous utiliserons les fichiers .json disponibles dans le répertoire cloné. Il suffit de changer l'emplacement des images dans les fichiers json. Pour faire ceci, ouvrez le fichier .json et remplacez l'emplacement actuel par l'emplacement où se trouvent vos images.
Veuillez noter que tout ce code est écrit en Python 2. Apportez les modifications suivantes si vous utilisez une autre version de Python:
- Dans model.py, changer xrange sur la ligne 18 une gamme
- Changer de ligne 19 dans model.py avec: liste (self.frontend.state_dict (). Articles ())[je][1].Les données[:] = liste (mod.state_dict (). éléments ())[je][1].Les données[:]
- Dans image.py, remplacer ground_truth par ground-truth
Avez-vous fait les changements? À présent, ouvrez une nouvelle fenêtre de terminal et tapez les commandes suivantes:
cd CSRNet-pytorch python train.py part_A_train.json part_A_val.json 0 0
Encore, asseyez-vous car cela prendra un certain temps. Vous pouvez réduire le nombre d'époques dans le train.py fichier pour accélérer le processus. Une bonne alternative consiste à télécharger les poids pré-entraînés. d'ici si tu n'as pas envie d'attendre.
Finalement, vérifions les performances de notre modèle sur des données invisibles. Nous utiliserons le val.ipynb fichier pour valider les résultats. N'oubliez pas de modifier le chemin vers les poids et images précédemment formés.
#définir le chemin de l'image
img_paths = []
pour le chemin dans path_sets:
pour img_path dans glob.glob(os.path.join(chemin, '*.jpg')):
img_paths.append(img_path)
modèle = CSRNet()
#définir le modèle modèle = modèle.cuda()
#charger les poids entraînés
point de contrôle = torche.charge('part_A/0model_best.pth.tar')
model.load_state_dict(point de contrôle['state_dict'])
Consulter le MAE (erreur absolue moyenne) dans les images de test pour évaluer notre modèle:
Nous avons une valeur MAE de 75,69, ce qui est plutôt bien. Passons maintenant en revue les prédictions dans une seule image:
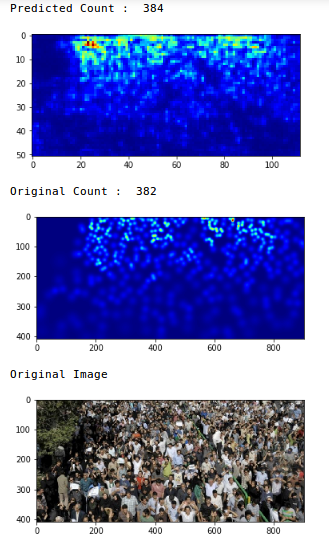 Wow, le décompte initial était 382 et notre modèle a estimé qu'il y avait 384 les gens sur la photo. C'est une performance très impressionnante !!
Wow, le décompte initial était 382 et notre modèle a estimé qu'il y avait 384 les gens sur la photo. C'est une performance très impressionnante !!
Félicitations pour la création de votre propre modèle de comptage de foule !!
Remarques finales
Je vous encourage à essayer cette approche sur différentes images et à partager vos résultats dans la section commentaires ci-dessous.. Le comptage de foule a de nombreuses applications diverses et est déjà adopté par des organisations et des agences gouvernementales..
C'est une compétence utile à ajouter à votre portefeuille. Un grand nombre d'industries rechercheront des data scientists capables de travailler avec des algorithmes de comptage de foule. Apprendre, expérimentez-le et offrez-vous le don de l'apprentissage en profondeur!
Avez-vous trouvé cet article utile? N'hésitez pas à me laisser vos suggestions et commentaires ci-dessous, et je serai heureux de communiquer avec vous.
Vous devriez également consulter les ressources ci-dessous pour apprendre et explorer le monde merveilleux de la vision par ordinateur.:





