Combien d'algorithmes d'impulsion connaissez-vous?
Pouvez-vous nommer au moins deux algorithmes d'impulsion en apprentissage automatique?
Les algorithmes Boost existent depuis des années et, cependant, ce n'est que récemment qu'ils sont devenus courants dans la communauté de l'apprentissage automatique. Mais, Pourquoi ces algorithmes de boost sont devenus si populaires?
L'une des principales raisons de l'augmentation de l'adoption des algorithmes d'impulsion est les compétences en apprentissage automatique.. Les algorithmes Boost donnent aux modèles d'apprentissage automatique des super-pouvoirs pour améliorer leur précision de prédiction. Un aperçu des compétitions Kaggle et Hackaton DataHack est une preuve suffisante – Les algorithmes de boost sont très populaires!
En peu de mots, les algorithmes de momentum surpassent souvent les modèles plus simples comme la régression logistique et arbres de décision. En réalité, La plupart des finalistes de notre plateforme DataHack utilisent un algorithme de boost ou une combinaison de plusieurs algorithmes de boost.

Dans cet article, Je vais vous présenter quatre algorithmes de boost populaires que vous pouvez utiliser dans votre prochain apprentissage automatique hackathon ou projet.
4 Algorithmes de pilotage dans l'apprentissage automatique
- Máquina de aumento de penteLe gradient est un terme utilisé dans divers domaines, comme les mathématiques et l’informatique, pour décrire une variation continue de valeurs. En mathématiques, fait référence au taux de variation d’une fonction, pendant la conception graphique, S’applique à la transition de couleur. Ce concept est essentiel pour comprendre des phénomènes tels que l’optimisation dans les algorithmes et la représentation visuelle des données, permettant une meilleure interprétation et analyse dans... (GBM)
- Machine d'augmentation de gradient extrême (XGBM)
- LightGBM
- ChatBoost
Présentation rapide du Boosting (Qu'est-ce qui booste?)
Imaginez ce scénario:
Vous avez créé un modèle de régression linéaire qui vous donne une précision décente de la 77% dans le jeu de données de validation. Ensuite, décide d'élargir son portefeuille en créant un modèle k-plus proche voisin (KNN) et un arbre de décision modèle sur le même ensemble de données. Ces modèles lui ont donné une précision de 62% et le 89% dans l'ensemble de validation, respectivement.
Il est évident que les trois modèles fonctionnent de manières complètement différentes.. Par exemple, le modèle de régression linéaire tente de capturer les relations linéaires dans les données, tandis que le modèle d'arbre de décision essaie de capturer la non-linéarité dans les données.
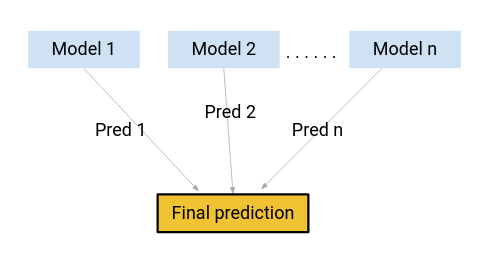
Et si, plutôt que d'utiliser l'un de ces modèles pour faire les prédictions finales, nous utilisons une combinaison de tous ces modèles?
Je pense à une moyenne des prédictions de ces modèles. En faisant cela, nous pourrions capturer plus d'informations à partir des données, vérité?
C'est principalement l'idée derrière l'apprentissage ensemble.. Et d'où vient l'envie?
L'impulsion est l'une des techniques utilisées par le concept d'apprentissage conjoint. Un algorithme d'impulsion combine plusieurs modèles simples (également appelés apprenants faibles ou estimateurs de base) pour générer le résultat final.
Nous examinerons certains des algorithmes de quantité de mouvement importants dans cet article..
1. Machine d'augmentation de gradient (GBM)
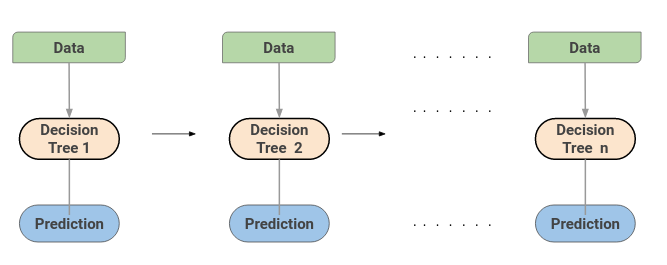
Une machine d'augmentation de gradient ou GBM combine les prédictions de plusieurs arbres de décision pour générer les prédictions finales. Notez que tous les élèves faibles sur une machine d'augmentation de gradient sont des arbres de décision.
Mais si nous utilisons le même algorithme, Comment vaut-il mieux utiliser une centaine d'arbres de décision que d'utiliser un seul arbre de décision? Comment différents arbres de décision capturent-ils différents signaux / informations de données?
voici l'astuce: les nœuds de chaque arbre de décision prennent un sous-ensemble différent de caractéristiques pour sélectionner la meilleure répartition. Cela signifie que les arbres individuels ne sont pas tous les mêmes et, donc, peut capturer différents signaux à partir des données.
En outre, chaque nouvel arbre prend en compte les erreurs ou fautes commises par les arbres précédents. Donc, chaque arbre de décision successif est basé sur les erreurs des arbres précédents. C'est ainsi que les arbres dans un algorithme de machine d'augmentation de gradient sont construits séquentiellement.
Voici un article expliquant le processus de réglage des hyperparamètres pour l'algorithme GBM:
2. Machine d'augmentation de gradient extrême (XGBM)
Extreme Gradient Boosting ou XGBoost est un autre algorithme de boost populaire. En réalité, XGBoost est simplement une version de fortune de l'algorithme GBM !! La procédure de travail de XGBoost est la même que celle de GBM. Les arbres dans XGBoost sont construits séquentiellement, essayer de corriger les erreurs des arbres ci-dessus.
Voici un article qui explique intuitivement les mathématiques derrière XGBoost et implémente également XGBoost en Python:

Mais il y a certaines fonctionnalités qui rendent XGBoost un peu meilleur que GBM:
- L'un des points les plus importants est que XGBM implémente le prétraitement parallèle (a nivel de nœudNodo est une plateforme digitale qui facilite la mise en relation entre les professionnels et les entreprises à la recherche de talents. Grâce à un système intuitif, Permet aux utilisateurs de créer des profils, Partager des expériences et accéder à des opportunités d’emploi. L’accent mis sur la collaboration et le réseautage fait de Nodo un outil précieux pour ceux qui souhaitent élargir leur réseau professionnel et trouver des projets qui correspondent à leurs compétences et à leurs objectifs....) ce qui le rend plus rapide que GBM.
- XGBoost también incluye una variedad de técnicas de régularisationLa régularisation est un processus administratif qui vise à formaliser la situation de personnes ou d’entités qui opèrent en dehors du cadre légal. Cette procédure est essentielle pour garantir les droits et les devoirs, ainsi que pour promouvoir l’inclusion sociale et économique. Dans de nombreux pays, La régularisation est appliquée dans les contextes migratoires, Droit du travail et fiscalité, permettre aux personnes en situation irrégulière d’accéder à des prestations et de se protéger d’éventuelles sanctions.... que reducen el sobreajuste y mejoran el rendimiento general. Vous pouvez sélectionner la technique de régularisation en définissant les hyperparamètres de l'algorithme XGBoost
Obtenga información sobre los diferentes hiperparámetros de XGBoost y cómo juegan un papel en el proceso de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... del modelo aquí:
En outre, si vous utilisez l'algorithme XGBM, vous n'avez pas à vous soucier de l'imputation des valeurs manquantes dans votre ensemble de données. Le modèle XGBM peut gérer seul les valeurs manquantes. Pendant le processus de formation, le modèle apprend si les valeurs manquantes doivent être dans le nœud gauche ou droit.
3. LightGBM
L'algorithme de boost LightGBM devient de plus en plus populaire de jour en jour en raison de sa vitesse et de son efficacité. LightGBM peut gérer facilement de grandes quantités de données. Mais notez que cet algorithme ne fonctionne pas bien avec un petit nombre de points de données.
Prenons un moment pour comprendre pourquoi c'est le cas..
Les arbres dans LightGBM ont une croissance foliaire, au lieu d'une croissance des niveaux. Après la première division, la division suivante est effectuée uniquement sur le nœud feuille qui a la perte delta la plus élevée.
Considérez l'exemple que j'ai illustré dans l'image suivante:
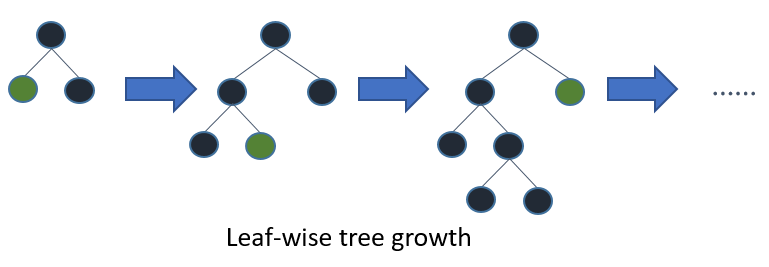
Après la première division, le nœud gauche a subi une perte plus importante et est sélectionné pour la division suivante. À présent, nous avons trois nœuds feuilles et le nœud feuille du milieu a subi la plus grande perte. La division de l'algorithme LightGBM par feuilles vous permet de travailler avec de grands ensembles de données.
Pour accélérer le processus de formation, LightGBM utiliza un método basado en histogrammesLes histogrammes sont des représentations graphiques qui montrent la distribution d’un ensemble de données. Ils sont construits en divisant la plage de valeurs en intervalles, O "Bacs", et compter la quantité de données tombées dans chaque intervalle. Cette visualisation vous permet d’identifier des modèles, Tendances et variabilité des données, faciliter l’analyse statistique et la prise de décision éclairée dans diverses disciplines.... para seleccionar la mejor división. Para cualquier variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... continu, au lieu d'utiliser les valeurs individuelles, ceux-ci sont divisés en conteneurs ou seaux. Cela accélère le processus d'entraînement et réduit l'utilisation de la mémoire..
Voici un excellent article comparant les algorithmes LightGBM et XGBoost:
4. ChatBoost
Comme le nom le suggère, CatBoost est un algorithme boost qui peut gérer des variables catégorielles dans les données. La plupart des algorithmes d'apprentissage automatique ne peuvent pas fonctionner avec des chaînes ou des catégories dans les données. Donc, la conversion de variables catégorielles en valeurs numériques est une étape de pré-traitement essentielle.
CatBoost peut gérer en interne les variables catégorielles dans les données. Ces variables sont transformées en numérique à l'aide de diverses statistiques sur des combinaisons de caractéristiques.
Si vous voulez comprendre les mathématiques derrière la façon dont ces catégories sont converties en nombres, vous pouvez lire cet article:

Une autre raison pour laquelle CatBoost est largement utilisé est qu'il fonctionne bien avec l'ensemble d'hyperparamètres par défaut. Donc, en tant qu'utilisateur, nous n'avons pas à passer beaucoup de temps à ajuster les hyperparamètres.
Voici un article qui implémente CatBoost dans un défi d'apprentissage automatique:
Remarques finales
Dans cet article, Nous couvrons les bases de l'apprentissage d'ensemble et discutons des 4 types d'algorithmes de renforcement. Êtes-vous intéressé à découvrir d'autres méthodes d'apprentissage commun?? Vous devriez vous référer à l'article suivant:
Avec quels autres algorithmes d'impulsion avez-vous travaillé? Avez-vous eu du succès avec ces algorithmes de boost? Partagez vos pensées et votre expérience avec moi dans la section commentaire ci-dessous..





