Le monde de la détection d'objets
J'aime travailler dans l'espace d'apprentissage profond. Franchement, est un vaste domaine avec une pléthore de techniques et de cadres à analyser et à apprendre. Et le vrai plaisir de créer des modèles de vision par ordinateur et d'apprentissage en profondeur vient lorsque je vois des applications du monde réel telles que la reconnaissance faciale et le suivi de balle dans le cricket., entre autres choses.
Et l'un de mes concepts préférés de vision industrielle et d'apprentissage en profondeur est la détection d'objets.. La possibilité de construire un modèle qui peut passer par des images et me dire quels objets sont présents, C'est un sentiment inestimable!

Quand les humains regardent une image, nous reconnaissons l'objet d'intérêt en quelques secondes. Ce n'est pas le cas des machines. Donc, la détection d'objets est un problème de vision par ordinateur pour localiser des instances d'objets dans une image.
Ce sont les bonnes nouvelles: les applications de détection d'objets sont plus faciles à développer que jamais. Les approches actuelles d'aujourd'hui se concentrent sur le pipeline de bout en bout qui a considérablement amélioré les performances et a également aidé à développer des cas d'utilisation en temps réel.
Dans cet article, Je vais vous expliquer comment créer un modèle de détection d'objets à l'aide de la populaire API TensorFlow. Si vous êtes un nouveau venu dans le deep learning, vision par ordinateur et le monde de la détection d'objets, Je vous recommande de consulter les ressources suivantes:
Table des matières
- Un cadre général pour la détection d'objets
- Qu'est-ce qu'une API? Pourquoi avons-nous besoin d'une API?
- API de détection d'objets TensorFlow
Un cadre général pour la détection d'objets
Normalement, nous suivons trois étapes lors de la création d'un cadre de détection d'objets:
- Premier, un algorithme ou un modèle d'apprentissage en profondeur est utilisé pour générer un grand ensemble de cadres de délimitation qui s'étendent sur l'ensemble de l'image (c'est-à-dire, un composant localisateur d'objets)

- Ensuite, les caractéristiques visuelles sont extraites pour chacun des cadres de délimitation. Ils sont évalués et il est déterminé si et quels objets sont présents dans les boîtes en fonction des caractéristiques visuelles (c'est-à-dire, un composant de classification d'objets)

- Dans la dernière étape de post-traitement, les cadres qui se chevauchent sont combinés en un seul cadre de délimitation (c'est-à-dire, suppression non maximale)




C'est tout, Vous êtes prêt avec votre premier framework de détection d'objets!
Qu'est-ce qu'une API? Pourquoi avons-nous besoin d'une API?
API signifie Interface de programmation d'applications. Une API fournit aux développeurs un ensemble d'opérations courantes afin qu'ils n'aient pas à écrire du code à partir de zéro.
Pensez à une API comme un menu de restaurant qui fournit une liste de plats ainsi qu'une description de chaque plat. Quand on précise quel plat on veut, le restaurant fait le travail et nous fournit des plats finis. Nous ne savons pas exactement comment le restaurant prépare cette nourriture, et ce n'est vraiment pas nécessaire.
En quelque sorte, Les API font gagner beaucoup de temps. Ils offrent également une commodité aux utilisateurs dans de nombreux cas. Pensez-y: Utilisateurs de Facebook (y compris moi!) Ils apprécient la possibilité de se connecter à de nombreuses applications et sites en utilisant leur identifiant Facebook. Comment pensez-vous que cela fonctionne? Utiliser les API Facebook, bien sûr!
Ensuite, dans cet article, nous verrons l'API TensorFlow développée pour la tâche de détection d'objets.
API de détection d'objets TensorFlow
L'API de détection d'objets TensorFlow est le cadre permettant de créer un réseau d'apprentissage en profondeur qui résout les problèmes de détection d'objets.
Il existe déjà des modèles déjà formés dans leur cadre qu'ils appellent Zoo Modèle. Cela comprend une collection de modèles préalablement formés et formés sur l'ensemble de données COCO., le jeu de données KITTI et le jeu de données d'images ouvertes. Ces modèles peuvent être utilisés pour des inférences si nous ne nous intéressons qu'aux catégories de cet ensemble de données.
Ils sont également utiles pour initialiser vos modèles lors de l'entraînement sur le nouveau jeu de données. Les différentes architectures utilisées dans le modèle pré-entraîné sont décrites dans ce tableau:

MobileNet-SSD
L'architecture SSD est un réseau de convolution unique qui apprend à prédire les emplacements des cadres de délimitation et à classer ces emplacements en un seul passage. Donc, Le SSD peut être formé de bout en bout. Le réseau SSD est constitué d'une architecture de base (MobileNet dans ce cas) suivi de plusieurs couches de convolution:

SSD fonctionne sur des cartes de caractéristiques pour détecter l'emplacement des cadres de délimitation. Rappelles toi: une carte de caractéristiques a la taille Df * Df * M. Pour chaque emplacement sur la carte des caractéristiques, k boîtes englobantes sont prédites. Chaque cadre de délimitation comporte les informations suivantes:
- Boîte englobante 4 coins compenser Emplacements (cx, cy, w, h)
- Probabilités de classe C (c1, c2,… cp)
SSD non prédire la forme de la boîte, plutôt où est la boîte. Les k boîtes englobantes ont chacune une forme par défaut. Les formulaires sont définis avant la formation proprement dite. Par exemple, dans la figure précédente, il y a 4 casillas, ce qui signifie k = 4.
Perte sur MobileNet-SSD
Avec l'ensemble final de carrés appariés, nous pouvons calculer la perte de cette façon:
L = 1/N (classe L + L boîte)
Ici, N est le nombre total de boîtes appariées. La classe L est la perte softmax pour le classement et la 'box L’ est la soft loss L1 qui représente l'erreur des boîtes appariées. La perte douce L1 est une modification de la perte L1 qui est plus robuste aux valeurs aberrantes. Dans le cas où N est 0, la perte est également fixée à 0.
MobileNet
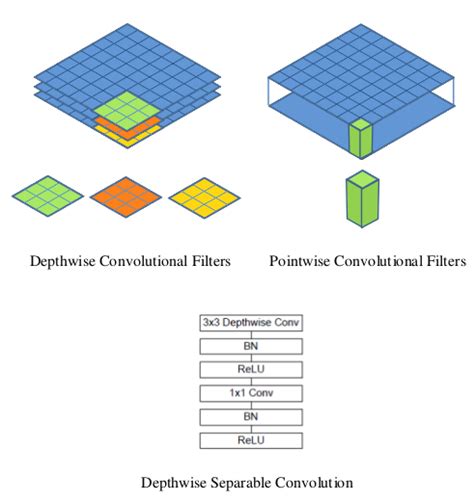
Le modèle MobileNet est basé sur des convolutions séparables en profondeur qui sont une forme de convolutions factorisées. Ceux-ci prennent en compte une convolution standard en une convolution de profondeur et une convolution de 1 × 1 appelée convolution ponctuelle.
Pour les réseaux mobiles, la convolution de profondeur applique un seul filtre à chaque canal d'entrée. La convolution ponctuelle applique ensuite une convolution 1 × 1 combiner les sorties de la convolution en profondeur.
Une convolution standard filtre et combine les entrées dans un nouvel ensemble de sorties en une seule étape. La convolution séparable en profondeur la divise en deux couches: un calque séparé pour filtrer et un calque séparé pour combiner. Cette factorisation a pour effet de réduire drastiquement le calcul et la taille du modèle..
Comment charger le modèle?
Vous trouverez ci-dessous le processus étape par étape à suivre dans Google Colab afin que vous puissiez facilement visualiser la détection d'objets. Vous pouvez également suivre le code.
Installer le modèle
Assurez-vous que vous avez pycocotools installée:
Avoir tensorflow/models O cd dans le répertoire principal du référentiel:
Construisez des protobufs et installez le détection_objet emballer:
Importez les bibliothèques requises
Importer le module de détection d'objets:
Préparation du modèle
Chargeur
Chargement de la carte des étiquettes
Étiquetez les cartes d'index de carte avec des noms de catégorie afin que lorsque notre réseau de convolution prédit 5, Faites-nous savoir que cela correspond à un avion:
Pour des raisons de simplicité, nous allons tester dans 2 images:
Modèle de détection d'objets utilisant l'API TensorFlow
Charger un modèle de détection d'objet:
Vérifier la signature d'entrée du modèle (attendez-vous à un lot d'images de 3 couleurs de type int8):
Ajouter une fonction wrapper pour appeler le modèle et nettoyer les sorties:
Exécutez-le sur chaque image de test et affichez les résultats:
Ci-dessous, l'exemple d'image testé sur ssd_mobilenet_v1_coco (MobileNet-SSD activé sur le jeu de données COCO):

Accueil-SSD
L'architecture du modèle Inception-SSD est similaire à celle du précédent MobileNet-SSD. La différence est que l'architecture de base ici est le modèle Inception. Pour en savoir plus sur le réseau domestique, Va ici: Comprendre le réseau de démarrage à partir de zéro.
Comment charger le modèle?
Il suffit de changer le nom du modèle dans la partie Découverte de l'API:
Alors, faire la prédiction en suivant les étapes que nous avons suivies ci-dessus. Voila!
RCNN plus rapide
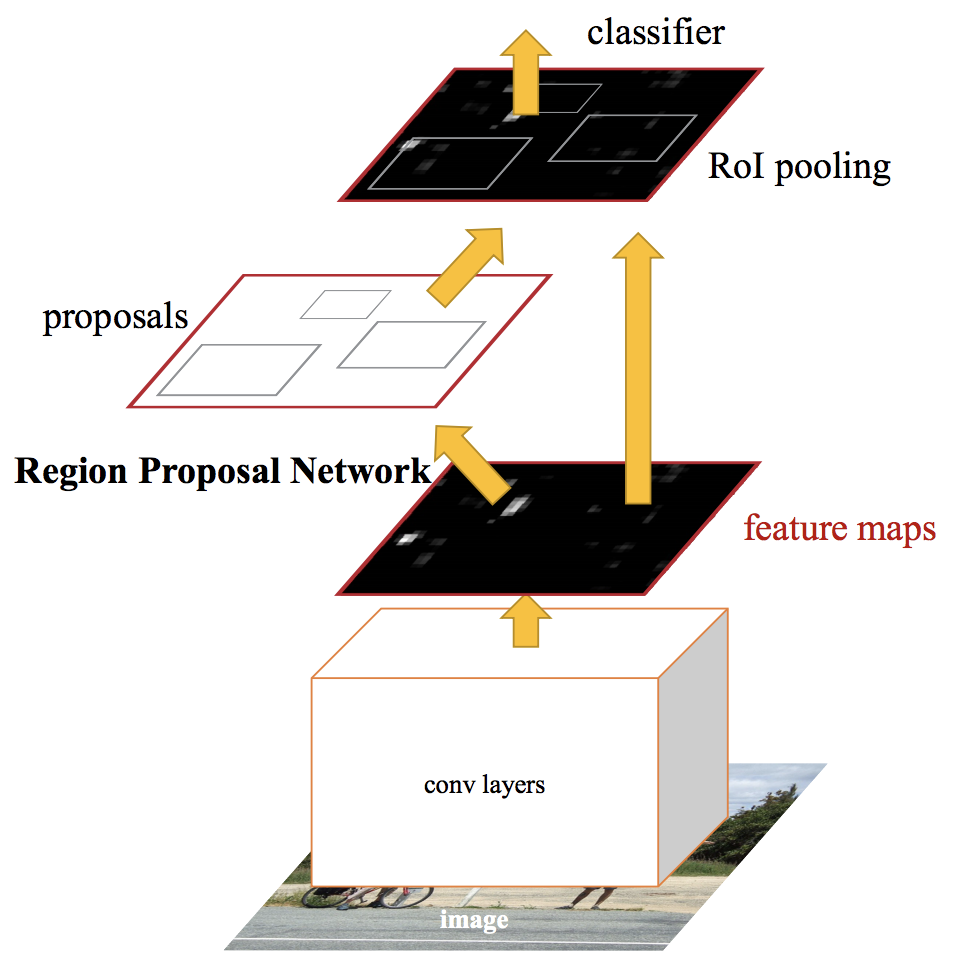
Les réseaux de détection d'objets à la pointe de la technologie s'appuient sur des algorithmes de proposition de région pour formuler des hypothèses sur l'emplacement des objets. Des avancées telles que SPPnet et Fast R-CNN ont réduit le temps d'exécution de ces réseaux de détection, exposer le calcul de la proposition de région comme un goulot d'étranglement.
Un RCNN plus rapide, nous transmettons l'image d'entrée au réseau de neurones convolutifs pour générer une carte des caractéristiques convolutives. A partir de la carte des caractéristiques convolutives, nous identifions la région des propositions et les déformons en carrés. Et lors de l'utilisation d'une couche de regroupement de ROI (couche de région d'intérêt), nous les remodelons dans une taille fixe afin qu'ils puissent s'intégrer dans une couche entièrement connectée.
À partir du vecteur de caractéristiques RoI, nous utilisons une couche softmax pour prédire la classe de la région proposée ainsi que les valeurs de décalage pour la boîte englobante.
Pour en savoir plus sur Faster RCNN, lire cet article incroyable – Une implémentation pratique de l'algorithme Faster R-CNN pour la détection d'objets (Partie 2 – avec des codes Python).
Comment charger le modèle?
Il suffit de changer à nouveau le nom du modèle dans la partie Découverte de l'API:
Alors, faire la prédiction en suivant les mêmes étapes que nous avons suivies précédemment. Vous trouverez ci-dessous l'exemple d'image lorsqu'il est fourni à un modèle RCNN plus rapide:

Comme tu peux le voir, c'est bien mieux que le modèle SSD-Mobilenet. Mais cela vient avec un compromis: il est beaucoup plus lent que le modèle précédent. Ce sont les types de décisions que vous devrez prendre lorsque vous choisirez le bon modèle de détection d'objets pour votre projet d'apprentissage en profondeur et de vision par ordinateur..
Quel modèle de détection d'objets dois-je choisir?
En fonction de vos besoins spécifiques, vous pouvez choisir le bon modèle à partir de l'API TensorFlow. Si nous voulons un modèle à haute vitesse qui peut fonctionner dans la détection de la transmission vidéo à un fps élevé, le réseau de détection monocoup (SSD) fonctionne mieux. Comme son nom l'indique, Le réseau SSD détermine toutes les probabilités de la zone de délimitation à la fois; pourtant, c'est un modèle beaucoup plus rapide.
Cependant, avec détection de coup unique, gagner en vitesse au détriment de la précision. Con plus rapideRCNN, nous obtiendrons une haute précision mais une faible vitesse. Alors explorez et dans le processus, vous réaliserez à quel point cette API TensorFlow peut être puissante.





