introduction
L'analyse exploratoire des données est l'une des meilleures pratiques utilisées dans la science des données aujourd'hui. Au début d'une carrière dans la science des données, les gens ne connaissent généralement pas la différence entre l'analyse de données et l'analyse de données exploratoire. Il n'y a pas une grande différence entre les deux, mais ils ont tous deux des objectifs différents.

L'analyse exploratoire des données (AED): l'analyse exploratoire des données est un complément Statistiques déductives, qui a tendance à être assez rigide avec des règles et des formules. A un niveau avancé, L'EDA consiste à examiner et à décrire l'ensemble de données sous différents angles, puis à le résumer.
Analyse de données: l'analyse des données est la statistique et la probabilité de découvrir des tendances dans l'ensemble de données. Utilisé pour afficher les données historiques en utilisant certains outils d'analyse. Aide à décomposer les informations pour transformer les métriques, faits et chiffres sur les initiatives d'amélioration.
L'analyse exploratoire des données (AED)
Nous allons explorer un ensemble de données et effectuer une analyse exploratoire des données en Python. Vous pouvez consulter notre cours de python en ligne pour embarquer avec Python.
Les principaux sujets à traiter sont les suivants:
– Gérer la valeur manquante
– Supprimer les doublons
– Traitement des valeurs aberrantes
– Normalisation et mise à l'échelle (variables numériques)
– Codage des variables catégorielles (variables muettes)
– Analyse bivariée
# Importation de bibliothèques

# Chargement du jeu de données
Nous allons charger le fichier Excel des voitures EDA à l'aide de pandas. Pour ca, nous utiliserons le fichier read_excel.
Box plot après suppression des valeurs aberrantes
# Exploration des données de base
Dans cette étape, Nous allons effectuer les opérations suivantes pour vérifier de quoi est composé l'ensemble de données. Nous allons vérifier les choses suivantes:
– gestionnaire de jeux de données
– la forme de l'ensemble de données
– informations sur l'ensemble de données
– résumé de l'ensemble de données
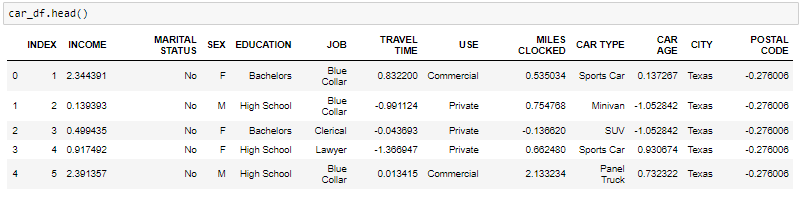
- La fonction head vous indiquera les meilleurs enregistrements de l'ensemble de données. Par défaut, Python ne vous montre que le 5 registres principaux.
-
L'attribut shape nous indique une série d'observations et de variables que nous avons dans l'ensemble de données. Il est utilisé pour vérifier la dimension des données. L'ensemble de données automobiles a 303 observations et 13 variables dans l'ensemble de données.

-
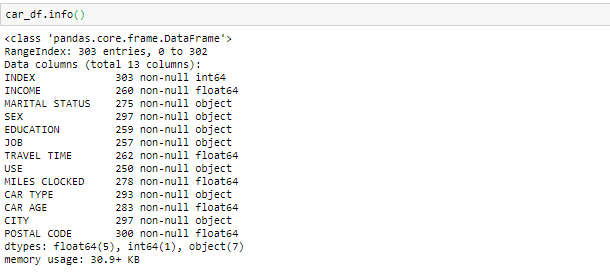
Info () utilisé pour vérifier les informations sur les données et les types de données de chaque attribut respectif.

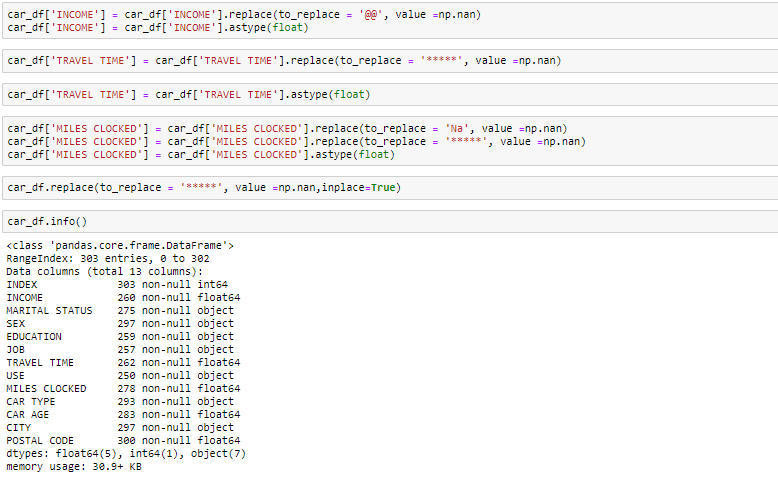
En regardant les données dans la fonction principale et dans les informations, on sait que la variable Revenu et le temps de trajet sont de type données flottantes au lieu de l'objet. Ensuite, nous en ferons le flotteur. En outre, il y a des valeurs invalides comme @@ et ‘*'Dans les données que nous traiterons comme des valeurs manquantes.

-
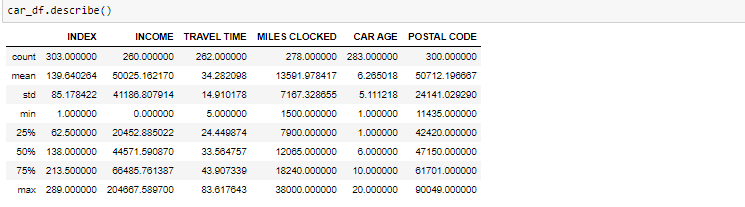
La méthode décrite aidera à voir comment les données ont été distribuées pour les valeurs numériques. On voit clairement la valeur minimale, valeurs moyennes, différentes valeurs centiles et valeurs maximales.


Gestion de la valeur manquante
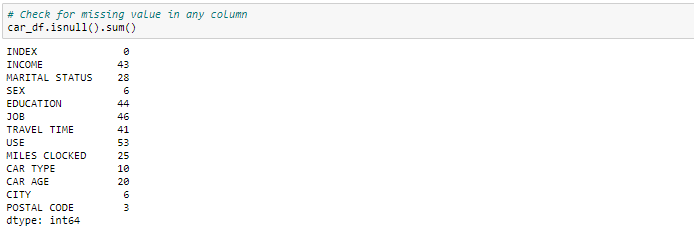
Nous pouvons voir que nous avons plusieurs valeurs manquantes dans les colonnes respectives. Il existe plusieurs façons de traiter les valeurs manquantes dans l'ensemble de données. Et quelle technique utiliser quand cela dépend vraiment du type de données que vous traitez.
- Éliminer les valeurs manquantes: dans ce cas, nous éliminons les valeurs manquantes de ces variables. En cas de très peu de valeurs manquantes, peut les supprimer.
- Imputer avec la valeur moyenne: pour la colonne numérique, vous pouvez remplacer les valeurs manquantes par des valeurs moyennes. Avant de remplacer par la valeur moyenne, il est conseillé de vérifier que la variable ne doit pas avoir de valeurs extrêmes.c'est-à-dire des valeurs aberrantes.
- Imputer avec la valeur médiane: pour la colonne numérique, vous pouvez également remplacer les valeurs manquantes par des valeurs médianes. Si vous avez des valeurs extrêmes, comme valeurs aberrantes, il est conseillé d'utiliser la méthode de la médiane.
- Imputer avec la valeur de mode: pour la colonne catégorielle, vous pouvez remplacer les valeurs manquantes par des valeurs de mode, c'est-à-dire, le fréquent.
Dans cet exercice, nous remplacerons les colonnes numériques par des valeurs médianes et, pour les colonnes catégorielles, nous supprimerons les valeurs manquantes.
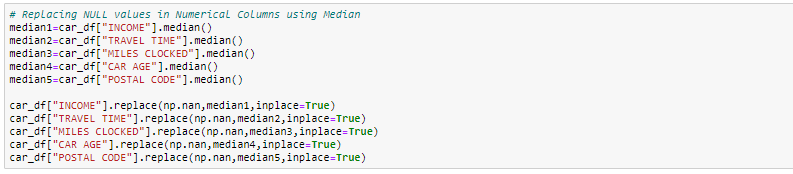
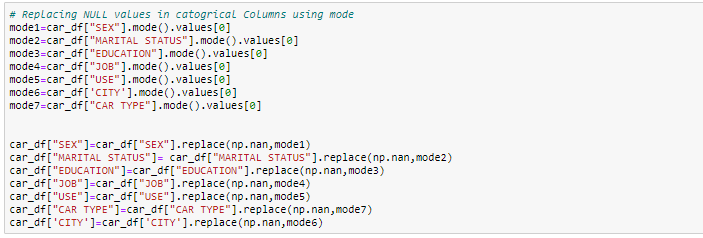

Gestion des enregistrements en double
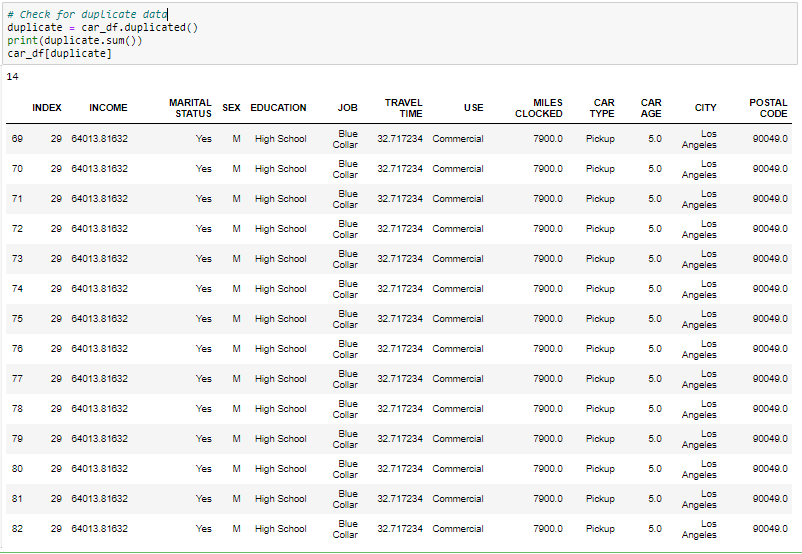
Depuis que nous avons 14 enregistrements en double dans les données, nous le supprimerons de l'ensemble de données pour n'obtenir que des enregistrements distincts. Après avoir supprimé le doublon, nous vérifierons si les doublons ont été supprimés de l'ensemble de données ou non.
![]()

Traitement des valeurs aberrantes
Valeurs aberrantes, étant les observations les plus extrêmes, peut inclure le maximum ou le minimum de l'échantillon, les deux, selon qu'ils sont extrêmement élevés ou faibles. Cependant, le maximum et le minimum de l'échantillon ne sont pas toujours des valeurs aberrantes car ils peuvent ne pas être anormalement éloignés des autres observations.
Nous identifions généralement les valeurs aberrantes à l'aide de la boîte à moustaches, donc ici, la boîte à moustaches montre certains des points de données en dehors de la plage de données.
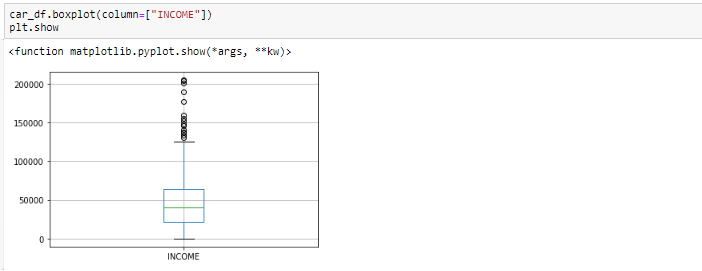
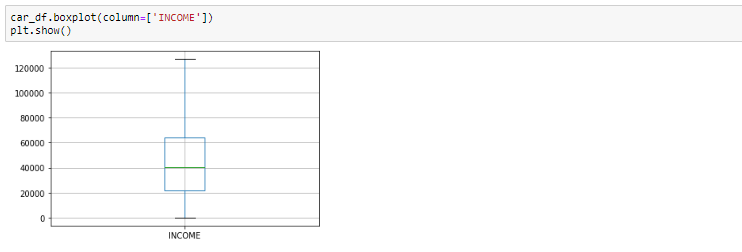
Box plot avant suppression des valeurs aberrantes
En regardant le box plot, il semble que les variables REVENU, ont des valeurs aberrantes présentes dans les variables. Ces valeurs aberrantes doivent être prises en compte et il existe plusieurs façons de les traiter:
- Supprimer la valeur aberrante
- Remplacer la valeur aberrante à l'aide de l'IQR
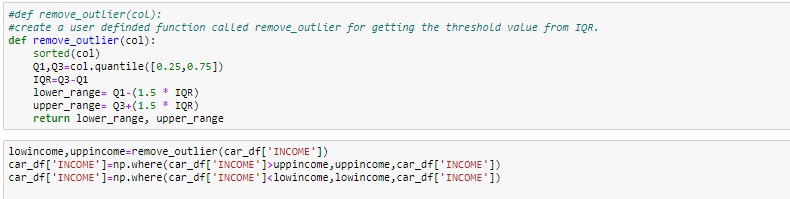
#Boxplot Après suppression de la valeur aberrante
Analyse bivariée
Quand on parle d'analyse bivariée, signifie analyser 2 variables. Comme nous savons qu'il existe des variables numériques et catégorielles, il existe un moyen d'analyser ces variables comme indiqué ci-dessous:
-
Numérique vs numérique
1. Diagramme de dispersion
2. Graphique linéaire
3. Carte thermique pour la corrélation
4. Terrain commun -
Catégorique vs Numérique
1. Graphique à barres
2. Cadre de violon
3. Box plot catégoriel
4.parcelle chaleureuse -
Deux variables catégorielles
1. Graphique à barres
2. Graphique à barres groupées
3. Graphique à points
Si nous devons trouver la corrélation-
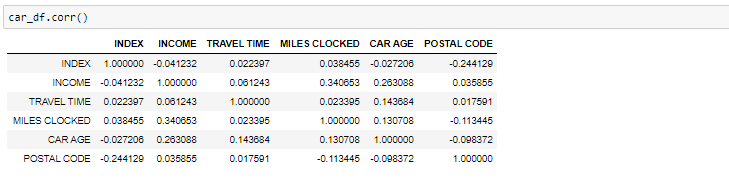
Corrélation entre toutes les variables
Normaliser et mettre à l'échelle
Souvent, les variables de l'ensemble de données sont d'échelles différentes, c'est-à-dire, une variable est en millions et d'autres en seulement 100. Par exemple, dans notre jeu de données, le revenu a des valeurs en milliers et l'âge en seulement deux chiffres. Étant donné que les données de ces variables sont d'échelles différentes, il est difficile de comparer ces variables.
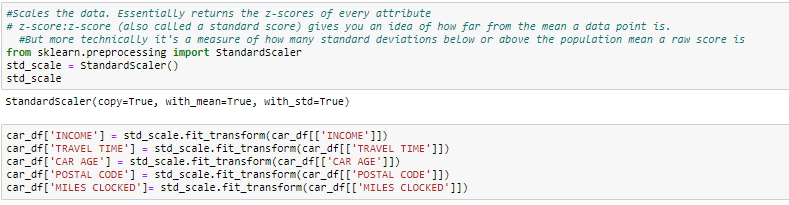
L'échelle des caractéristiques (également connu sous le nom de normalisation des données) est la méthode utilisée pour normaliser l'éventail des caractéristiques des données. Étant donné que la plage de valeurs de données peut varier considérablement, devient une étape nécessaire dans le prétraitement des données tout en utilisant des algorithmes d'apprentissage automatique.
Dans cette méthode, nous convertissons des variables avec différentes échelles de mesure en une seule échelle. StandardScaler normalise les données à l'aide de la formule (x-moyenne) / écart-type. Nous le ferons uniquement pour les variables numériques.
CODAGE
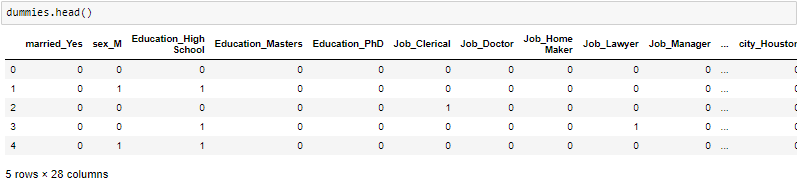
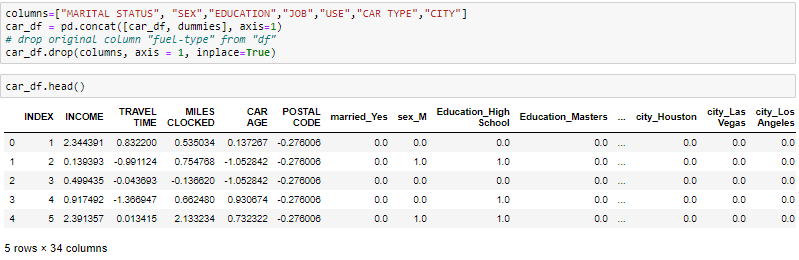
One-Hot-Encoding est utilisé pour créer des variables fictives pour remplacer les catégories dans une variable catégorielle dans les caractéristiques de chaque catégorie et la représenter en utilisant 1 O 0 selon la présence ou l'absence de la valeur catégorielle dans le registre.
Ceci est nécessaire, puisque les algorithmes d'apprentissage automatique ne fonctionnent qu'avec des données numériques. C'est pourquoi il est nécessaire de convertir la colonne catégorique en numérique.
get_dummies est la méthode qui crée une variable fictive pour chaque variable catégorielle.

A propos de l'auteur

Ritika Singh | – Data scientist
Je suis data scientist de profession et blogueur par passion. J'ai travaillé sur des projets d'apprentissage automatique pendant plus de 2 ans. Vous trouverez ici des articles sur « L'apprentissage automatique, Statistiques, L'apprentissage en profondeur, PNL et Intelligence Artificielle".





