Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
SERRER POUR L'IMPACT! SERRER! SERRER! SERRER!
UPS!!! Notre avion s'est écrasé, mais heureusement nous sommes tous en sécurité. Nous sommes des data scientists, nous voulons donc ouvrir la boîte noire et voir quelles choses aléatoires ont été enregistrées à l'intérieur. Oui, passons à notre sujet.
Que sont les forêts aléatoires?
Vous devez avoir résolu au moins une fois un problème de probabilité dans votre lycée dans lequel vous étiez censé trouver la probabilité d'obtenir une balle d'une couleur spécifique dans un sac contenant des balles de différentes couleurs., étant donné le nombre de boules de chaque couleur. Les forêts aléatoires sont simples si nous essayons de les apprendre avec cette analogie à l'esprit.
Les forêts aléatoires (RF) ils sont essentiellement un sac contenant n arbres de décision (DT) qui ont un ensemble différent d'hyperparamètres et sont entraînés sur différents sous-ensembles de données. Disons que j'ai 100 arbres de décision dans mon sac forestier aléatoire! Comme je viens de le dire, ces arbres de décision ont un ensemble différent d'hyperparamètres et un sous-ensemble différent de données d'apprentissage, donc la décision ou la prédiction donnée par ces arbres peut varier considérablement. Considérons que j'ai en quelque sorte formé tous ces 100 arbres avec leur sous-ensemble respectif de données. Maintenant, je vais demander aux cent arbres de mon sac quelle est leur prédiction sur mes données de test. Il ne nous reste plus qu'à prendre une décision sur un exemple ou une donnée de test, nous le faisons au moyen d'un simple vote. Nous suivons ce que la plupart des arbres ont prédit pour cet exemple.
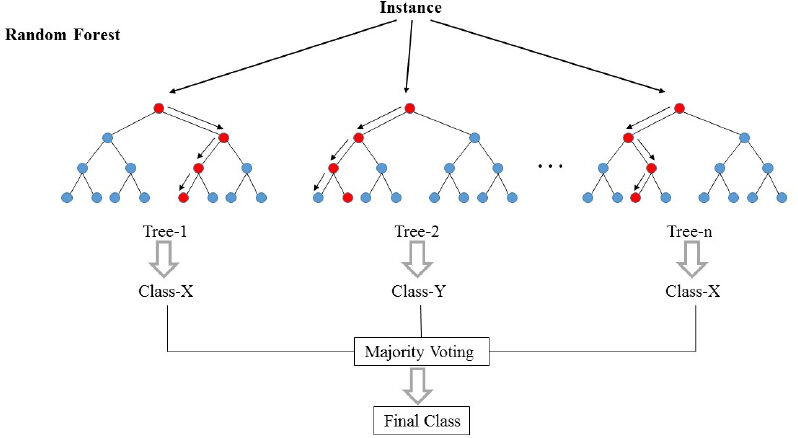
Dans l'image ci-dessus, nous pouvons voir comment un exemple est classé en utilisant n arbres où la prédiction finale est faite en prenant un vote de tous les n arbres.
Dans le langage de l'apprentissage automatique, Les RF sont également appelées méthodes d'assemblage ou d'ensachage. Je pense que le mot sac pourrait venir de l'analogie dont nous venons de parler !!
Rapprochons-nous un peu des ML Jargons !!
La forêt aléatoire est essentiellement un algorithme d'apprentissage supervisé. Cela peut être utilisé pour les tâches de régression et de classification. Mais nous discuterons de son utilisation pour la classification car elle est plus intuitive et plus facile à comprendre.. La forêt aléatoire est l'un des algorithmes les plus utilisés en raison de sa simplicité et de sa stabilité.
Lors de la création de sous-ensembles de données pour les arbres, mot “Aléatoire” entre en scène. Un sous-ensemble de données est créé en sélectionnant au hasard x nombre de caractéristiques (Colonnes) y y nombre d'exemples (Lignes) à partir de l'ensemble de données d'origine de n caractéristiques et m exemples.
Les forêts aléatoires sont plus stables et fiables qu'un simple arbre de décision. C'est simplement dire qu'il vaut mieux voter pour tous les ministres plutôt que d'accepter simplement la décision prise par le premier ministre..
Comme nous l'avons vu, les forêts aléatoires ne sont rien de plus que la collection d'arbres de décision, il devient essentiel de connaître l'arbre de décision. Alors plongeons dans les arbres de décision.
Qu'est-ce qu'un arbre de décision?
En mots très simples, c'est un “Un ensemble de règles” créé en apprenant à partir d'un ensemble de données qui peut être utilisé pour faire des prédictions sur les données futures. Nous allons essayer de comprendre cela avec un exemple.

Voici un petit jeu de données simple. Dans cet ensemble de données, les quatre premières caractéristiques sont des caractéristiques indépendantes et les quatre dernières sont des caractéristiques dépendantes. Les caractéristiques indépendantes décrivent les conditions météorologiques d'un jour donné et la caractéristique dépendante nous dit si nous avons pu jouer au tennis ce jour-là ou non..
Nous allons maintenant essayer de créer des règles en utilisant des caractéristiques indépendantes pour prédire des caractéristiques dépendantes. Juste par observation, nous pouvons voir que si Outlook est nuageux, le jeu est toujours oui, indépendamment des autres caractéristiques. de la même manière, nous pouvons créer toutes les règles pour décrire complètement l'ensemble de données. Voici toutes les règles.
-
- R1: Et (Outlook = ensoleillé) Oui (Humidité = élevée) Puis Jouer = Non
- R2: Et (Outlook = ensoleillé) Oui (Humidité = Normale) Puis Jouer = Oui
- R3: Et (Outlook = Nuageux) Puis Jouer = Oui
- R4: Et (Perspectives = Pluie) Oui (Vent = fort) Puis Jouer = Non
- R5: Et (Perspective = Pluie) Oui (Vent = faible) Alors Payer = Oui
Nous pouvons facilement convertir ces règles en un diagramme en arbre. Voici l'arborescence.
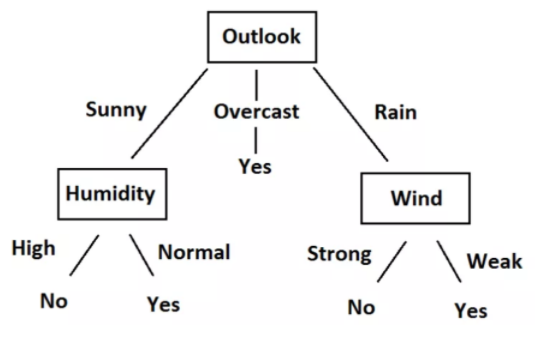
En regardant les données, les règles et l'arbre, Vous l'aurez compris, nous pouvons désormais prédire si nous devons ou non jouer au tennis., compte tenu de la situation climatique basée sur des caractéristiques indépendantes. Tout ce processus de création de règles pour une donnée donnée n'est rien de plus que l'apprentissage du modèle d'arbre de décision.
Nous pourrions définir des règles et créer un arbre simplement en regardant ici parce que l'ensemble de données est si petit. Mais, Comment entraînons-nous l'arbre de décision sur un ensemble de données plus important? Pour ça, nous devons savoir un peu de maths. Nous allons maintenant essayer de comprendre les mathématiques derrière l'arbre de décision.
Concepts mathématiques derrière l'arbre de décision
Cette section se compose de deux concepts importants: Entropie et gain d'informations.
Entropie
L'entropie est une mesure du caractère aléatoire d'un système. L'entropie de l'espace échantillon S est le nombre attendu de bits nécessaires pour coder la classe d'un membre tiré au hasard de S. Ici nous avons 14 lignes dans nos données, Pour ce que 14 membres.
Entropie E (S) = -∑p (X) * Journal2(p (X))
L'entropie du système est calculée en utilisant la formule ci-dessus, où p (X) est la probabilité d'obtenir la classe x de ceux 14 membres. Nous avons deux classes ici, l'un est Oui et l'autre est Non dans la colonne Lecture. Ont 9 Oui et 5 Pas dans notre ensemble de données. Ensuite, le calcul d'entropie ici sera le suivant
E (S) = -[p(Oui)*Journal(p(Oui))+ p(Non)*Journal(p(Non))]= -[(9/14)*Journal((9/14))+ (5/14*Journal((5/14)))]= 0,94
Gain d'informations
Le gain d'information est la quantité dans laquelle l'entropie du système est réduite en raison de la division que nous avons faite. Nous avons créé l'arbre en utilisant des observations. Mais, Comment se fait-il que nous ayons décidé de diviser les données d'abord en fonction d'Outlook et non d'une autre fonction? La raison en est que cette division réduisait l'entropie de la quantité maximale, mais nous l'avons fait intuitivement dans l'exemple ci-dessus.
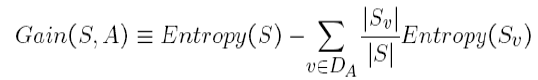

La division de l'arbre ci-dessus nous montre que 9 Oui et 5 Ils n'ont pas été divisés comme (2 Oui, 3 N), (4 Oui, 0 N), (3 Oui, 2 N), quand on fait la division selon la perspective. Les valeurs E en dessous de chaque division montrent les valeurs d'entropie se considérant comme un système complet et utilisant la formule d'entropie ci-dessus. Alors, nous avons calculé le gain d'informations pour la répartition des prospects en utilisant la formule de gain ci-dessus.
de la même manière, nous pouvons calculer le gain d'informations pour chaque division de caractéristiques indépendamment. Et on obtient les résultats suivants:
-
- Gagner (S, Perspectives) = 0,247
- Gagner (S, humidité) = 0,151
- Gagner (S, vent) = 0.048
- Gagner (S, Température) = 0.029
Nous pouvons voir que nous obtenons le gain d'informations maximal en divisant la fonction Outlook. Nous répétons cette procédure pour créer l'arbre entier. J'espère que vous avez apprécié la lecture de l'article. Si vous aimez l'article, Partagez avec vos collègues et amis. Bonne lecture!!!





