introduction
Avez-vous déjà résolu un problème d'apprentissage automatique ponctuel?
Résoudre un problème à l'aide de l'apprentissage automatique n'est pas facile. Il comporte plusieurs étapes pour arriver à une solution précise. Le processus / pasos a seguir para resolver un problema de ml se conoce como ML PipelinePipeline es un término que se utiliza en diversos contextos, principalmente en tecnología y gestión de proyectos. Se refiere a un conjunto de procesos o etapas que permiten el flujo continuo de trabajo desde la concepción de una idea hasta su implementación final. En el ámbito del desarrollo de software, par exemple, un pipeline puede incluir la programación, pruebas y despliegue, garantizando así una mayor eficiencia y calidad en los... / Cycle ML.
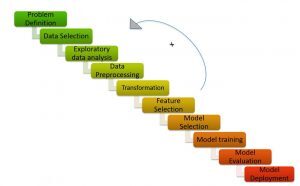
Pipeline de ML / Cycle ML (Crédits: https://medium.com/analytics-vidhya/machine-learning-development-life-cycle-dfe88c44222e)
Como se muestra en la chiffre"Chiffre" est un terme utilisé dans divers contextes, De l’art à l’anatomie. Dans le domaine artistique, fait référence à la représentation de formes humaines ou animales dans des sculptures et des peintures. En anatomie, désigne la forme et la structure du corps. En outre, en mathématiques, "chiffre" Il est lié aux formes géométriques. Sa polyvalence en fait un concept fondamental dans de multiples disciplines...., Le pipeline Machine Learning se compose de différentes étapes telles que:
Comprendre l'énoncé du problème, génération d'hypothèses, l'analyse exploratoire des données, prétraitement des données, ingénierie des fonctionnalités, sélection de fonctionnalité, construction de modèles, ajustement du modèle et implémentation du modèle.
Je recommanderais de lire les articles ci-dessous pour avoir une compréhension détaillée du pipeline d'apprentissage automatique:
- Explication du cycle de vie de l'apprentissage automatique!
- Étapes pour mener à bien un projet de machine learning
Le processus de résolutionLa "résolution" fait référence à la capacité de prendre des décisions fermes et d’atteindre les objectifs fixés.. Dans des contextes personnels et professionnels, Il s’agit de définir des objectifs clairs et d’élaborer un plan d’action pour les atteindre. La résolution est essentielle à la croissance personnelle et à la réussite dans divers domaines de la vie, car cela vous permet de surmonter les obstacles et de rester concentré sur ce qui compte vraiment.... de un problema de aprendizaje automático implica mucho tiempo y esfuerzo humano. Hourra! Ce n'est plus un processus fastidieux et chronophage! Merci à AutoML pour avoir fourni des solutions instantanées aux problèmes d'apprentissage automatique.
AutoML consiste à créer automatiquement le modèle hautes performances avec le moins d'intervention humaine.
Les bibliothèques AutoML offrent une programmation low-code et sans code.
Vous avez probablement entendu parler des termes « code bas » Oui « sans code ».
- Sans code Les frameworks sont des interfaces utilisateur simples qui permettent même aux utilisateurs non techniques de créer des modèles sans écrire une seule ligne de code.
- Code bas fait référence à l'encodage minimum.
Aunque las plataformas sin código facilitan el entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... de un modelo de aprendizaje automático mediante una interfaz de arrastrar y soltar, sont limités en termes de flexibilité. Le ML low-code, d'un autre côté, est le point optimal et le moyen terme, car ils offrent une flexibilité et un code facile à utiliser.
Dans cet article, Comprenons comment créer un modèle de classification de texte en quelques lignes de code à l'aide d'une bibliothèque AutoML low-code, PyCaret.
Table des matières
- Qu'est-ce que PyCaret?
- Pourquoi avons-nous besoin de PyCaret?
- Différentes approches pour résoudre la classification de texte dans PyCaret
- Modélisation thématique
- Count Vectorizer
- Étude de cas: classification de texte avec PyCaret
Qu'est-ce que PyCaret?
PyCaret est une bibliothèque d'apprentissage automatique low-code et open source en Python qui vous permet de passer de la préparation de vos données à la mise en œuvre de votre modèle en quelques minutes..

PyCaret (Crédits: https://pycaret.org/)
PyCaret est essentiellement une bibliothèque low-code qui remplace des centaines de lignes de code dans scikit. 5-6 lignes de code. Augmente la productivité de l'équipe et aide l'équipe à se concentrer sur la compréhension du problème et les fonctionnalités d'ingénierie plutôt que sur l'optimisation du modèle.
PyCaret (Crédits: https://pycaret.org/about/)
PyCaret est construit sur une bibliothèque d'apprentissage scikit. Par conséquent, tous les algorithmes d'apprentissage automatique disponibles dans scikit learn sont disponibles dans pycaret. À partir de maintenant, PyCaret peut résoudre les problèmes liés à la classification, régression, regroupementLe "regroupement" Il s’agit d’un concept qui fait référence à l’organisation d’éléments ou d’individus en groupes ayant des caractéristiques ou des objectifs communs. Ce procédé est utilisé dans diverses disciplines, y compris la psychologie, Éducation et biologie, faciliter l’analyse et la compréhension de comportements ou de phénomènes. Dans le domaine de l’éducation, par exemple, Le regroupement peut améliorer l’interaction et l’apprentissage entre les élèves en encourageant le travail.., Détection d'une anomalie, classement de texte, règles et séries temporelles associées à l'exploration de données.
À présent, Analysons les raisons derrière l'utilisation de PyCaret.
Pourquoi avons-nous besoin de PyCaret?
PyCaret crée automatiquement le modèle de référence en fonction d'un ensemble de données dans 5-6 lignes de code. Voyons comment pycaret simplifie chaque étape du pipeline d'apprentissage automatique.
- Préparation des données: PyCaret effectue le nettoyage et le prétraitement des données avec le moins d'intervention manuelle.
- Ingénierie fonctionnelle: PyCaret crée automatiquement les caractéristiques mathématiques et sélectionne les caractéristiques les plus importantes nécessaires au modèle
- Construction du modèle: Simplifie grandement la partie modélisation de votre projet. Nous pouvons construire différents modèles et sélectionner les modèles les plus performants avec une seule ligne de code.
- Ajustement du modèle: PyCaret ajuste le modèle sans passer explicitement d'hyperparamètres à chaque modèle.
Ensuite, nous allons nous concentrer sur la résolution d'un problème de classification de texte dans PyCaret.
Différentes approches pour résoudre la classification de texte dans PyCaret
Résolvons un problème de classification de texte dans PyCaret en utilisant 2 différentes techniques:
- Modélisation thématique
- Count Vectorizer
Je toucherai chaque point en détail
Modélisation thématique
Modélisation thématique, Comme le nom l'indique, est une technique pour identifier les différents thèmes présents dans les données textuelles.
Les thèmes sont définis comme un groupe répétitif de symboles (ou des mots) statistiquement significatif dans un corpus. Ici, la signification statistique fait référence aux mots importants dans le document. En général, les mots qui apparaissent fréquemment avec des scores TF-IDF plus élevés sont considérés comme des mots statistiquement significatifs.
La modélisation de sujet est une technique non supervisée pour trouver automatiquement les sujets cachés dans les données textuelles. On peut également l'appeler l'approche d'exploration de texte pour trouver des modèles récurrents dans les documents texte.
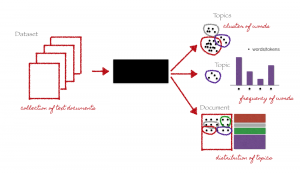
Modélisation thématique (Crédits: https://medium.com/analytics-vidhya/topic-modeling-using-lda-and-gibbs-sampling-explained-49d49b3d1045)
Voici quelques cas d'utilisation courants pour la modélisation de thèmes ::
- Résoudre des problèmes de classification / régression de texte
- Créer des balises pertinentes pour les documents
- Générer des informations pour les formulaires de commentaires des clients, Avis des clients, résultats du sondage, etc.
Exemple de modélisation de thème
Supposons que vous travaillez pour un cabinet d'avocats et que vous travaillez avec une entreprise où de l'argent a été détourné et que vous sachiez qu'il y a des informations clés dans les e-mails qui ont été distribués dans l'entreprise.
- Ensuite, vérifier les e-mails et il y a des centaines de milliers d'e-mails. À présent, ce que vous devez faire est de savoir lesquels sont liés à l'argent par rapport à d'autres sujets.
- Vous pouvez les étiqueter à la main en fonction de ce que vous lisez dans le texte, ce qui prendrait beaucoup de temps, ou vous pouvez utiliser la technique appelée modélisation de thème pour savoir quelles sont ces balises et baliser automatiquement tous ces emails.
Comme expliqué ci-dessus, le but de la modélisation thématique est d'extraire différents thèmes du texte brut. Mais, Quel est l'algorithme sous-jacent pour y parvenir?
Cela nous amène aux différents algorithmes / techniques de modélisation de thèmes: affectation de dirichlet latente (LDA), factorisation matricielle non négative (NNMF), assignation sémantique latente (LSA).
Je vous recommande de vous référer aux ressources suivantes pour lire en détail les algorithmes
- Partie 2: Modélisation thématique et assignation Dirichlet latente (LDA) en utilisant Gensim et Sklearn
- Guide du débutant sur la modélisation de thèmes en Python
- Modélisation de thèmes avec LDA: une introduction pratique
Venir à la modélisation de thème, est un processus de 2 Pas:
- Répartition des thèmes à terme: Trouver les sujets les plus importants dans le corpus.
- Distribution de document à sujet: Attribuez des notes pour chaque sujet à chaque document.
Avoir compris la modélisation thématique, nous verrons comment résoudre la classification de texte en utilisant la modélisation thématique à l'aide d'un exemple.
Considérons un corpus:
- Document 1: Je veux avoir des fruits pour le petit déjeuner.
- Document 2: j'aime manger des amandes, oeufs et fruits.
- Document 3: J'emporterai des fruits et des biscuits avec moi quand j'irai au zoo.
- Document 4: Le gardien du zoo nourrit le lion très soigneusement.
- Document 5: Des biscuits de bonne qualité doivent être donnés à vos chiens.
L'algorithme de modélisation de thème (LDA) identifie les sujets les plus importants dans les documents.
- Thème 1: 30% des fruits, 15% des œufs, 10% biscuits,… (repas)
- Thème 2: 20% Lion, 10% chiens, 5% zoo,… (les animaux)
Ensuite, attribuer des notes pour chaque sujet aux documents comme suit.
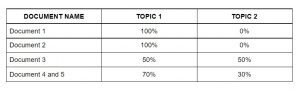
Attribuer des sujets à chaque document à l'aide de LDA
Cette matrice agit comme des caractéristiques de l'algorithme d'apprentissage automatique. Ensuite, nous verrons le sac de mots.
Sac de mots
Sac de mots (ARC) est un autre algorithme populaire pour représenter le texte en nombres. Cela dépend de la fréquence des mots dans le document. BOW a de nombreuses applications telles que la classification de documents, modélisation de thème et similarité de texte. Et ARC, chaque document est représenté par la fréquence des mots présents dans le document. Ensuite, la fréquence des mots représente l'importance des mots dans le document.
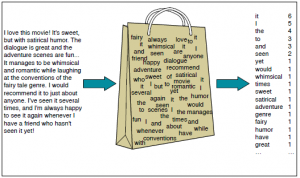
Sac de mots (Crédits: Jurafsky et al., 2018)
Suivez l'article ci-dessous pour avoir une compréhension détaillée de Bag Of Words:
Dans la section suivante, nous allons résoudre le problème de classification de texte dans PyCaret.
Étude de cas: classification de texte avec PyCaret
Comprenons l'énoncé du problème avant de le résoudre.
Comprendre l'énoncé du problème
Steam est un service de distribution de jeux vidéo numériques avec une vaste communauté de joueurs dans le monde entier. De nombreux joueurs écrivent des critiques sur la page du jeu et ont la possibilité de choisir s'ils recommanderaient ou non ce jeu à d'autres.. Cependant, déterminer ce sentiment automatiquement à partir du texte peut aider Steam à marquer automatiquement les critiques tirées d'autres forums Internet et peut les aider à mieux juger de la popularité des jeux.
Compte tenu du texte de l'avis avec la recommandation de l'utilisateur, la tâche consiste à prédire si le critique a recommandé les titres de jeux disponibles dans l'ensemble de test en fonction du texte de la critique et d'autres informations.
En termes plus simples, la tâche à accomplir est d'identifier si un avis d'utilisateur donné est bon ou mauvais. Vous pouvez télécharger l'ensemble de données à partir de ici.
Mise en œuvre
Pour évaluer les critiques de jeux Steam à l'aide de PyCaret, J'ai discuté 2 différentes approches dans l'article.
- La première approche utilise la modélisation thématique à l'aide de PyCaret.
- La deuxième approche utilise les fonctionnalités de Bag Of Words. Utilisez ces fonctions pour la classification à l'aide de PyCaret.
Nous allons mettre en œuvre l'approche BOW maintenant.
Noter: Le tutoriel est implémenté dans Google Colab. Je recommanderais d'exécuter le code dedans.
Installation de PyCaret
Vous pouvez installer PyCaret comme n'importe quelle autre bibliothèque Python.
- Installer PyCaret sur Google Colab ou Azure Notebooks
Importation de bibliothèques
Chargement des données
Comment PyCaret ne prend pas en charge le vectoriseur de comptage, importer le module CountVectorizer de sklearn.feature_extraction.
Alors, inicializo un objeto CountVectorizer llamado ‘tf_vectorizer’.
Que fait exactement la fonction fit_transform avec vos données?
- « Régler » extrait les caractéristiques de l'ensemble de données.
- « Transformer » effectue réellement les transformations sur l'ensemble de données.
Convertissons la sortie de fit_transform en bloc de données.
À présent, concaténer les caractéristiques et l'objectif le long de la colonne.
Ensuite, nous allons diviser l'ensemble de données en données de test et d'entraînement.
Maintenant que l'extraction des caractéristiques est terminée. Utilisons ces fonctions pour construire différents modèles. Ensuite, la prochaine étape consiste à configurer l'environnement dans PyCaret.
Paramétrage de l'environnement
- Cette fonction met en place le cadre de formation et construit le processus de transition. La fonction de configuration doit être appelée avant toute autre fonction peut être appelée.
- Le seul paramètre obligatoire est la donnée et l'objectif.
Création de modèles
Ajustement du modèle
De la sortie précédente, nous pouvons voir que les métriques du modèle ajusté sont meilleures que les métriques du modèle de base.
Évaluer et prédire le modèle
Ici, J'ai prédit les valeurs des drapeaux pour notre ensemble de données traitées, ‘tuned_lightgbm’.
Remarques finales
PyCaret, formation de modèles d'apprentissage automatique dans un environnement low-code, a piqué mon intérêt. Depuis votre environnement d'ordinateur portable préféré, PyCaret vous aide à passer de la préparation des données à la mise en œuvre du modèle en quelques secondes. Avant d'utiliser PyCaret, J'ai essayé d'autres méthodes traditionnelles pour résoudre le problème du hackathon JanataHack NLP, Mais les résultats n'étaient pas très satisfaisants !!
PyCaret s'est avéré exponentiellement rapide et efficace par rapport aux autres bibliothèques d'apprentissage automatique open source et a également l'avantage de remplacer plusieurs lignes de code par quelques mots..
Ici, si vous évitez la première partie de mon approche où j'utilise les techniques d'intégration du vectoriseur de comptage dans mon ensemble de données, puis passe à la configuration et à la création de modèles à l'aide de PyCaret, alors vous pouvez remarquer que toutes les transformations, comme le codage à chaud , l'imputation des valeurs perdues, etc., se passera automatiquement dans les coulisses, et ensuite vous obtiendrez une trame de données avec des prédictions, Comme ce que nous avons!
J'espère avoir clarifié mon approche générale du hackathon.





