introduction
R est l’un des langages de programmation les plus célèbres pour l’analyse statistique et l’informatique. Parce qu’il fournit beaucoup de fonctions, les chercheurs et les scientifiques des données l’utilisent pour la science des données et l’apprentissage automatique. certaines de ces fonctionnalités incluent des bibliothèques d’affichage interactives, rapide et open source, exécution de code sans compilateur, bonne communauté et bien d’autres.
L’une des principales raisons pour lesquelles il devient très célèbre est le grand nombre de packages R pour les projets de science des données., apprentissage automatique et intelligence artificielle. Lors de l’utilisation de ces packages, les modèles prédictifs peuvent être développés facilement et efficacement. Ce blog répertorie les 10 Top R packages que vous devriez connaître dans 2021 pour la science des données et l’apprentissage automatique.

Table des matières
- Dplyr
- ggplot2
- KernLab
- Explorateur de données
- Signe de classement
- au hasardForêt
- Brillant
- mboost
- comploter
- SuperML
Dplyr
C’est l’un des packages R les plus utilisés pour les tâches de science des données et d’apprentissage automatique.. Ce paquet est écrit par Hadley Wickham. Utilisé pour résoudre des tâches de manipulation de données. Dispose d’un ensemble de fonctions pour la manipulation des données. Aussi appelé grammaire de manipulation de données. Il a un ensemble de verbes qui nous aident à résoudre les tâches de manipulation de données les plus difficiles comme la mutation. (), pour sélectionner (), filtre (), résumer (), organiser ().
Pour installer ce package, utilisez le code suivant:
install.paquets('dplyr')


Pour plus d'informations, voir le lien ci-dessous: Introduction à dplyr
ggplot2
L’un des packages R les plus populaires et les plus utilisés pour la visualisation de données et l’analyse exploratoire de données. Vous pouvez créer des visualisations de données interactives avec ce package. Il fournit un large éventail de belles intrigues qui prennent soin des moindres détails et dessinent des légendes. Ce paquet fonctionne sous une grammaire profonde appelée « Graphiques de grammaire ». Fournit un large éventail de graphiques tels que des graphiques en nuages de points et des graphiques à bulles. Les diagrammes de fluctuation sont des graphiques, histogrammesLes histogrammes sont des représentations graphiques qui montrent la distribution d’un ensemble de données. Ils sont construits en divisant la plage de valeurs en intervalles, O "Bacs", et compter la quantité de données tombées dans chaque intervalle. Cette visualisation vous permet d’identifier des modèles, Tendances et variabilité des données, faciliter l’analyse statistique et la prise de décision éclairée dans diverses disciplines...., diagrammes de densité, boîtes à moustachesDiagrammes encadrés, Aussi connu sous le nom de diagrammes en boîte et à moustaches, sont des outils statistiques qui représentent la distribution d’un ensemble de données. Ces diagrammes montrent la médiane, quartiles et valeurs aberrantes, Permettre de visualiser la variabilité et la symétrie des données. Ils sont utiles pour la comparaison entre différents groupes et pour l’analyse exploratoire, faciliter l’identification des tendances et des modèles dans les données...., diagrammes de violon, dendrogrammes et bien d’autres.
Pour installer ce package, utilisez le code suivant:
install.paquets('gglpot2')
Vous trouverez ci-dessous quelques exemples de colis qui utilisent ce colis:
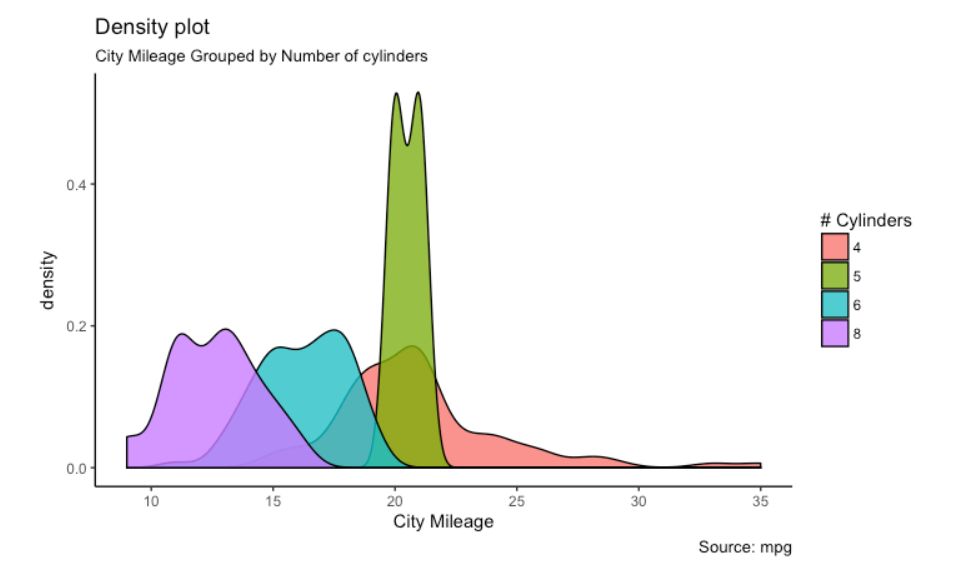

Pour plus d'informations, voir le lien ci-dessous: ggplot2
KernLab
Ce package est également appelé laboratoire d’apprentissage automatique basé sur le noyau. Ce package est utilisé pour la régression, classification, réduction de dimensionnalité, Détection d'une anomalie, regroupementLe "regroupement" Il s’agit d’un concept qui fait référence à l’organisation d’éléments ou d’individus en groupes ayant des caractéristiques ou des objectifs communs. Ce procédé est utilisé dans diverses disciplines, y compris la psychologie, Éducation et biologie, faciliter l’analyse et la compréhension de comportements ou de phénomènes. Dans le domaine de l’éducation, par exemple, Le regroupement peut améliorer l’interaction et l’apprentissage entre les élèves en encourageant le travail... Si vous souhaitez utiliser des algorithmes qui impliquent une approche basée sur le noyau, peut l’utiliser comme SVM, algorithme de classification, analyse des fonctionnalités du noyau et bien d’autres. Il est largement utilisé pour les implémentations SVM. Possède un large éventail de fonctions du noyau, comme pour la fonction noyau polynomial, nous pouvons utiliser polydot (), la fonction de noyau tangent hyperbolique pour tanhdot (), etc.
Pour installer ce package, utilisez le code suivant:
install.paquets('kernlab')
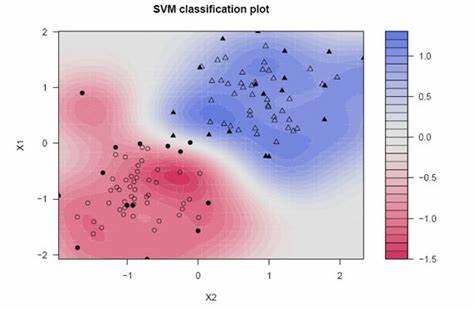
Pour plus d'informations, voir le lien ci-dessous: Package Kernlab
Explorateur de données
Ce package R est l’un des plus faciles à utiliser pour la science des données et l’apprentissage automatique. Ce paquet se concentre principalement sur trois objectifs:
- L'analyse exploratoire des données
- Ingénierie fonctionnelle
- Rapport de données
Ce package automatise l’analyse exploratoire des données pour les tâches de modélisation prédictive et d’analyse en visualisant chaque fonctionnalité présente dans notre ensemble de données..
Pour installer ce package, utilisez le code suivant:
install.paquets('DataExplorer')
Pour trouver un aperçu complet de notre ensemble de données, nous pouvons utiliser le code suivant:
Introduit(Les données)
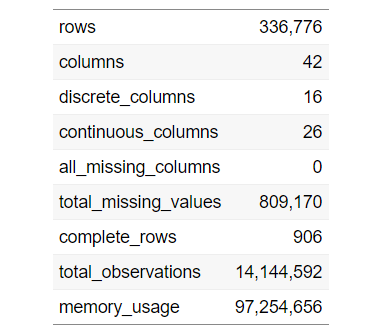
Pour afficher le tableau ci-dessus, utilisez le code suivant:
plot_intro(Les données)
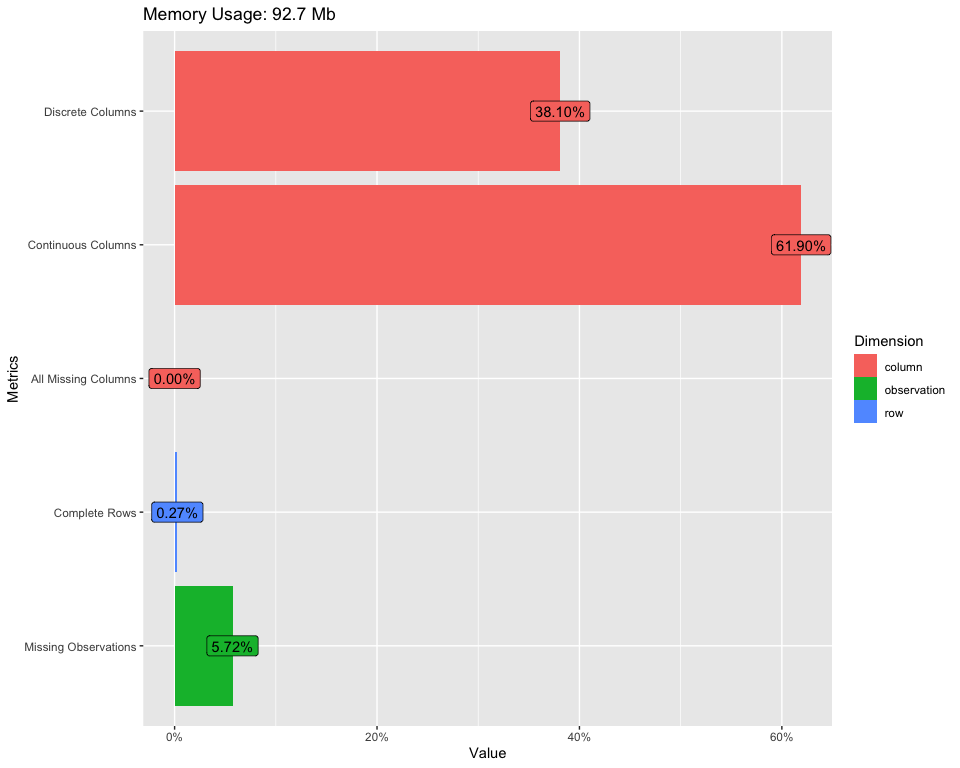
Pour plus d'informations, voir le lien ci-dessous: Introduction à DataExplorer
Signe de classement
Cela s'appelle aussi entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... de clasificación y regresión. C’est l’un des meilleurs packages pour les tâches de science des données et d’apprentissage automatique. Contient un ensemble de fonctions utilisées pour créer des modèles prédictifs. Il a d’autres fonctionnalités, ainsi que la sélection des fonctionnalités, division des données, prétraitement des données, réglage du modèle, importance des fonctionnalités et bien d’autres.
Pour installer ce package, utilisez le code suivant:
install.paquets('caret')
Pour plus d'informations, voir le lien ci-dessous: Forfait Caret
au hasardForêt
Random Forest est l’un des packages R les plus populaires pour l’apprentissage automatique. ce package est utilisé pour créer des forêts aléatoires dans r. Peut être utilisé pour les tâches de classification et de régression. Nous pouvons également l’utiliser pour entraîner les valeurs perdues et les valeurs aberrantes. Ce paquet utilise l’algorithme de forêt aléatoire de Breiman pour construire des arbres de décision.
Pour trouver un aperçu complet de notre ensemble de données, nous pouvons utiliser le code suivant:
install.paquets('randomForest')
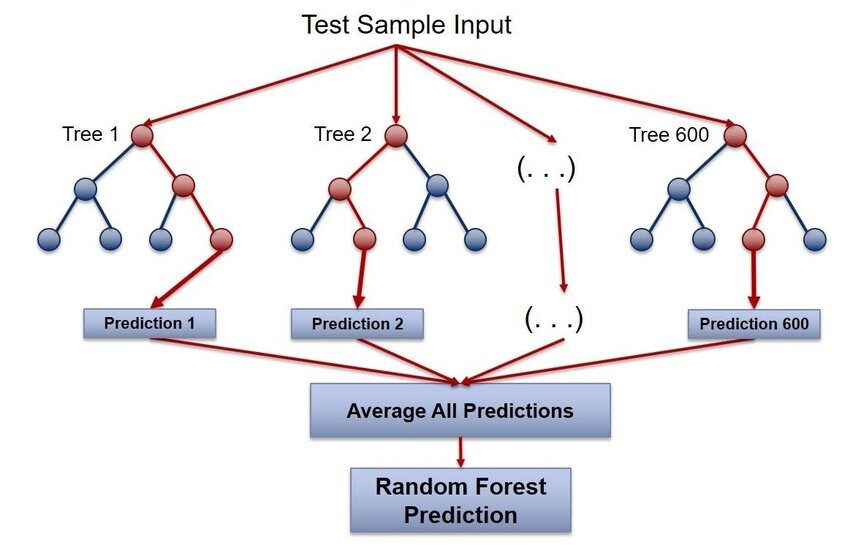
Pour plus d'informations, voir le lien ci-dessous: Forêt aléatoire
Brillant

Il s’agit d’un package R utilisé pour créer une application Web interactive pour la science des données. Nous aide à créer des applications Web R sans trop d’efforts. Shiny crée des applications Web qui sont déployées sur le Web à l’aide de son serveur ou de ses services d’hébergement R shiny. Les fonctionnalités de R shiny incluent la création d’une application avec moins de connaissances sur les outils Web, fournit des vues en direct, fonctions de rendu et bien d’autres.
Exemple d’application Web Shiny:
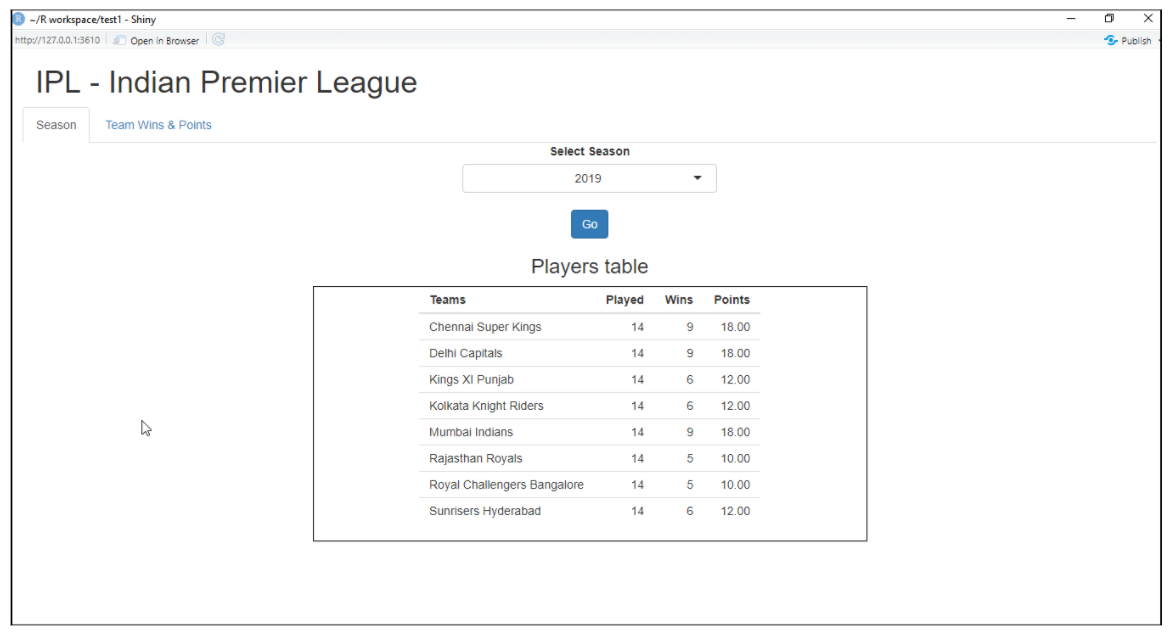
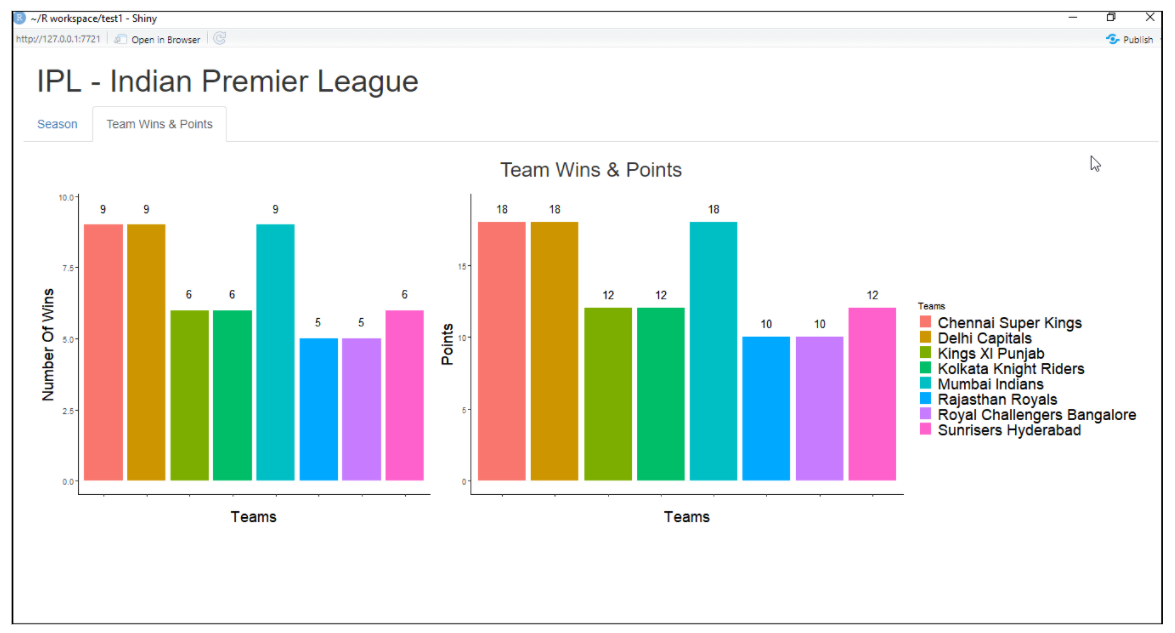
Pour plus d'informations, voir le lien ci-dessous: Brillant
mboost
Este paquete se utiliza en ciencia de datos para paquetes de impulso basados en modelos y tiene un algoritmo funcional de descenso de penteLe gradient est un terme utilisé dans divers domaines, comme les mathématiques et l’informatique, pour décrire une variation continue de valeurs. En mathématiques, fait référence au taux de variation d’une fonction, pendant la conception graphique, S’applique à la transition de couleur. Ce concept est essentiel pour comprendre des phénomènes tels que l’optimisation dans les algorithmes et la représentation visuelle des données, permettant une meilleure interprétation et analyse dans... para optimizar los árboles de decisión. También proporciona un modelo de interacción para datos potencialmente de alta dimension"Dimension" C’est un terme qui est utilisé dans diverses disciplines, comme la physique, Mathématiques et philosophie. Il s’agit de la mesure dans laquelle un objet ou un phénomène peut être analysé ou décrit. En physique, par exemple, On parle de dimensions spatiales et temporelles, alors qu’en mathématiques, il peut faire référence au nombre de coordonnées nécessaires pour représenter un espace. Sa compréhension est fondamentale pour l’étude et....
Pour installer ce package, utilisez le code suivant:
install.paquets('mboost')
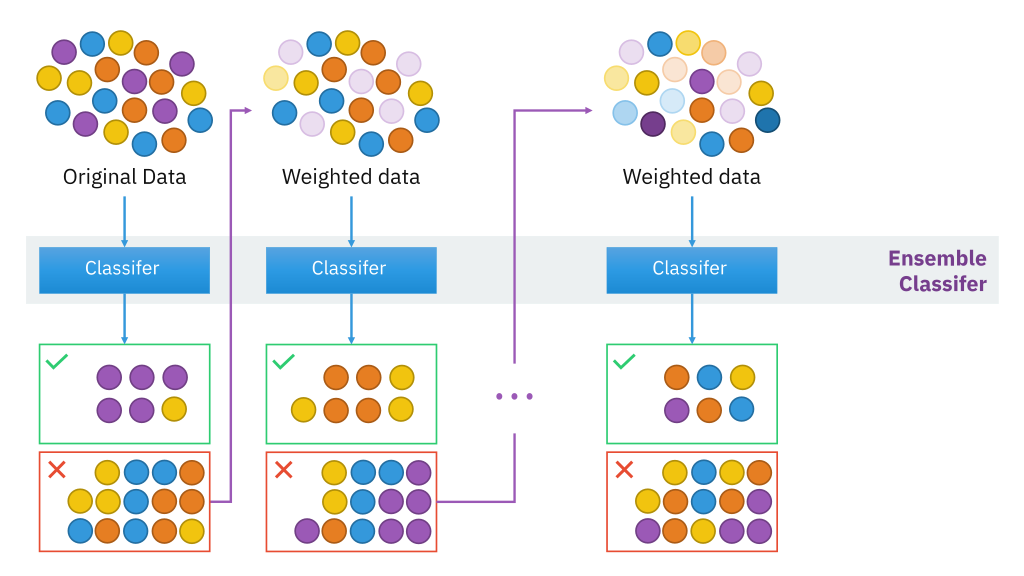
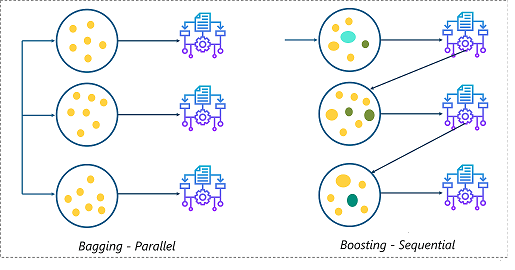
Pour plus d'informations, voir le lien ci-dessous: mboost
comploter
Il s’agit d’une bibliothèque graphique qui crée des graphiques interactifs. C’est une interface de haut niveau pour l’intrigue.js, basé sur d3.js. Fournit une interface utilisateur facile à utiliser pour générer des graphiques D3 interactifs élégants. Ces graphiques interactifs offrent de nombreuses fonctionnalités, tels que la possibilité de zoomer et de dézoomer sur les graphiques, survolez un point pour obtenir des informations supplémentaires, filtrer les données et bien plus encore.

Fournit un exemple de graphiques sous forme de nuages de points, diagrammes linéaires, diagramme à barres, chariots circulaires, diagrammes à bulles, boîtes à moustaches, histogrammes, barres d’erreur, diagrammes de violon et bien plus encore.
Pour plus d'informations, voir le lien ci-dessous: comploter
SuperML
Superml est l’un des célèbres packages R pour l’IA qui fournit une interface standard aux clients utilisant des dialectes de programmation Python et R pour construire des modèles d’IA.. Ce package fournit essentiellement les points forts de Scikit Learn et prédit l’interface pour la préparation des modèles d’IA dans R. En plus de construire des modèles d’IA, il existe des fonctionnalités pratiques pour effectuer l’ingénierie des fonctions.
Pour installer ce package, utilisez le code suivant:
install.paquets('superml')
Pour plus d'informations, voir le lien ci-dessous: SuperML
Merci d'avoir lu cet article et de votre patience.. Laissez-moi dans la section commentaire sur les commentaires. Partagez cet article, cela me donnera la motivation d'écrire plus de blogs pour la communauté de la science des données.
Merci d'avoir lu ceci. Si vous aimez cet article, Partage-le avec tes amis. En cas de suggestion / doute, commentaires ci-dessous.
Identification de l'e-mail: [email protégé]
Suivez-moi sur LinkedIn: LinkedIn
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





