Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Nettoyage des données est le processus d'analyse des données pour trouver des valeurs incorrectes, corrompus et manquants et les supprimer pour les rendre adaptés à l'analyse des données et à divers algorithmes d'apprentissage automatique.
C'est l'étape principale et fondamentale qui est effectuée avant que toute analyse des données puisse être effectuée.. Il n'y a pas de règles définies à suivre pour le nettoyage des données. Cela dépend totalement de la qualité du jeu de données et du niveau de précision à atteindre.
Raisons de la corruption des données:
- Les données sont collectées à partir de diverses sources structurées et non structurées, puis combinées, conduisant à des valeurs en double et mal étiquetées.
- Différentes définitions de dictionnaire de données pour les données stockées dans plusieurs emplacements.
- Erreur de saisie manuelle / des erreurs typographiques.
- Mauvaise majuscule.
- Catégorie: / classes mal étiquetées.
Qualité des données
La qualité des données est de la plus haute importance pour l'analyse. Plusieurs critères de qualité doivent être vérifiés:

Attributs de qualité des données

- je le complète: Défini comme le pourcentage d'entrées complétées dans l'ensemble de données. Le pourcentage de valeurs manquantes dans l'ensemble de données est un bon indicateur de la qualité de l'ensemble de données..
- Précision: Il est défini comme la mesure dans laquelle les entrées dans l'ensemble de données sont proches de leurs valeurs réelles.
- Uniformité: Défini comme la mesure dans laquelle les données sont spécifiées en utilisant la même unité de mesure.
- Cohérence: Il est défini comme la mesure dans laquelle les données sont cohérentes au sein du même ensemble de données et entre plusieurs ensembles de données.
- Validité: Elle est définie comme la mesure dans laquelle les données sont conformes aux restrictions appliquées par les règles métier. Il y a plusieurs limites:

Rapport de profil de données
Le profilage des données est le processus d'exploration de nos données et de recherche d'informations à partir de celles-ci. Le rapport de profilage Pandas est le moyen le plus rapide d'extraire des informations complètes sur votre ensemble de données. La première étape du nettoyage des données consiste à effectuer une analyse exploratoire des données.
Comment utiliser le profilage des pandas:
Paso 1: La première étape consiste à installer le package de profilage pandas à l'aide de la commande pip:
pip install pandas-profilingPaso 2: Charger l'ensemble de données à l'aide de pandas:
import pandas as pddf = pd.read_csv(r"C:UsersDellDesktopDatasethousing.csv")
Paso 3: Lire les cinq premières lignes:
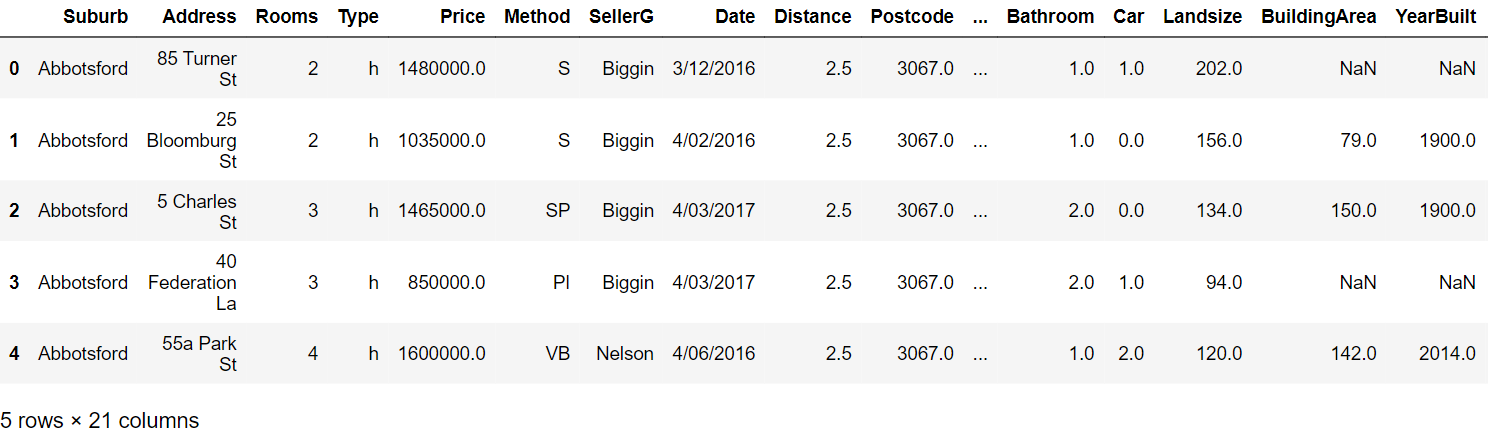
Paso 4: Générez le rapport de profilage avec les commandes suivantes:
from pandas_profiling importer un rapport de profilprof = ProfileReport(df)prof.to_file(output_file="output.html")
Rapport de profilage:
Le rapport de profilage se compose de cinq parties: description générale, variables, interactions, corrélation et valeurs manquantes.
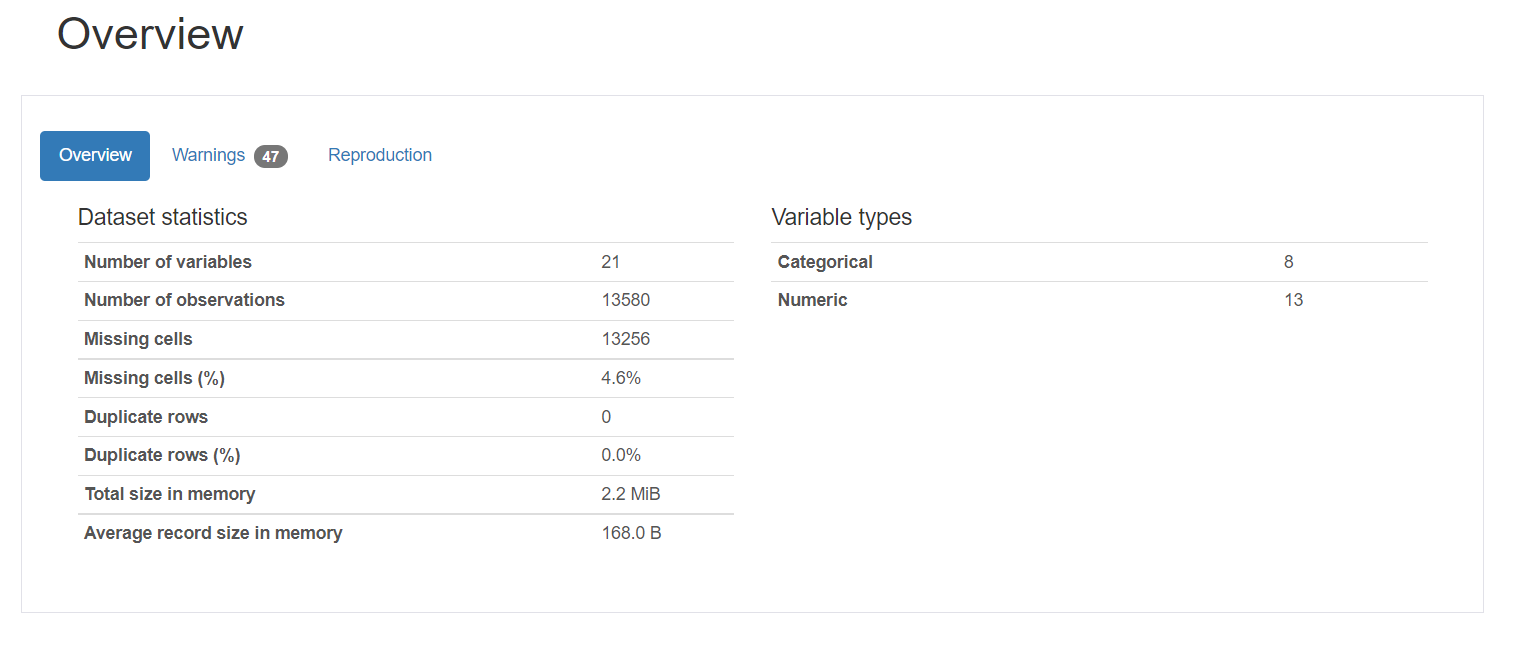
1. Aperçu fournit des statistiques générales sur le nombre de variables, le nombre d'observations, les valeurs manquantes, doublons et le nombre de variables catégorielles et numériques.
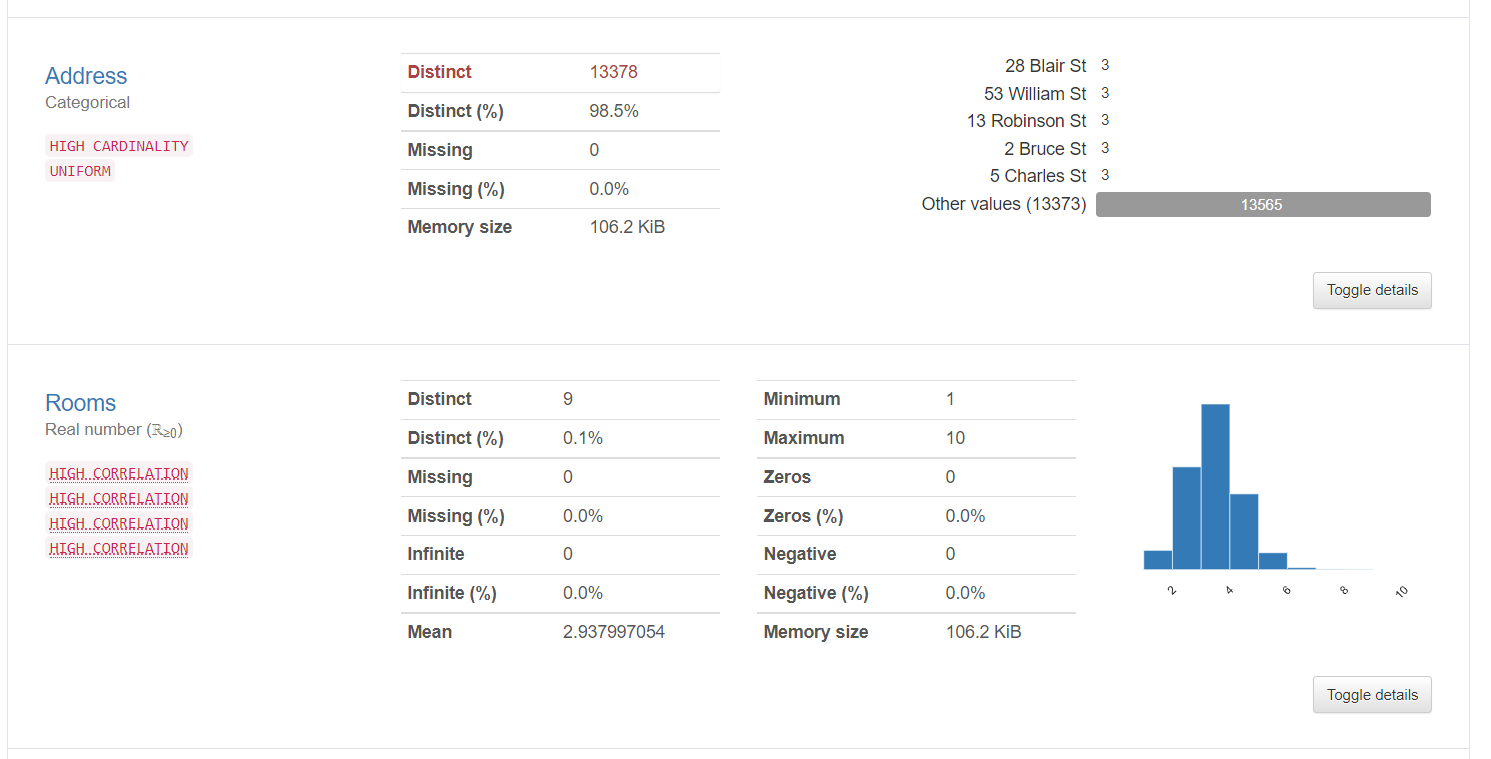
2. Les informations variables fournissent des informations détaillées sur des valeurs distinctes, les valeurs manquantes, La moyenne, la médiane, etc. Voici les statistiques sur une variable catégorielle et une variable numérique:
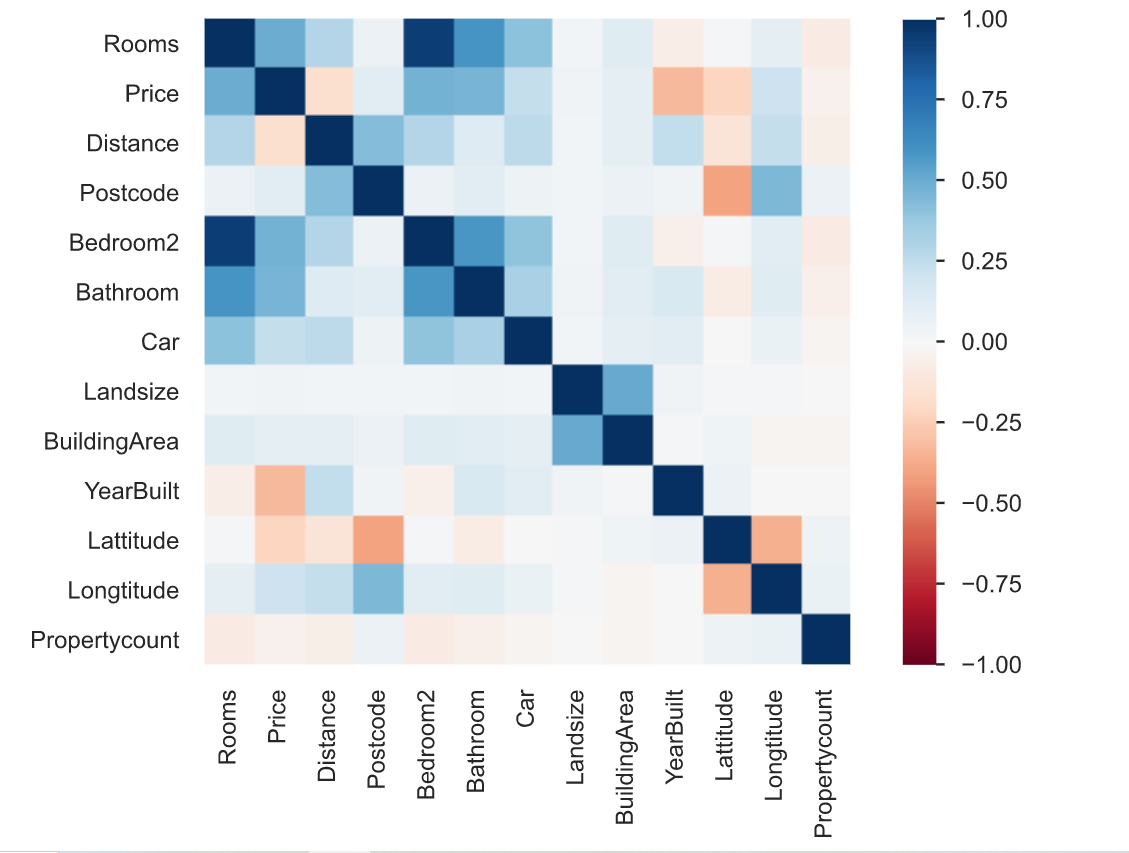
3. La corrélation est définie comme le degré auquel deux variables sont liées l'une à l'autre. Le rapport de profilage décrit la corrélation de différentes variables entre elles sous la forme d'une carte thermique.
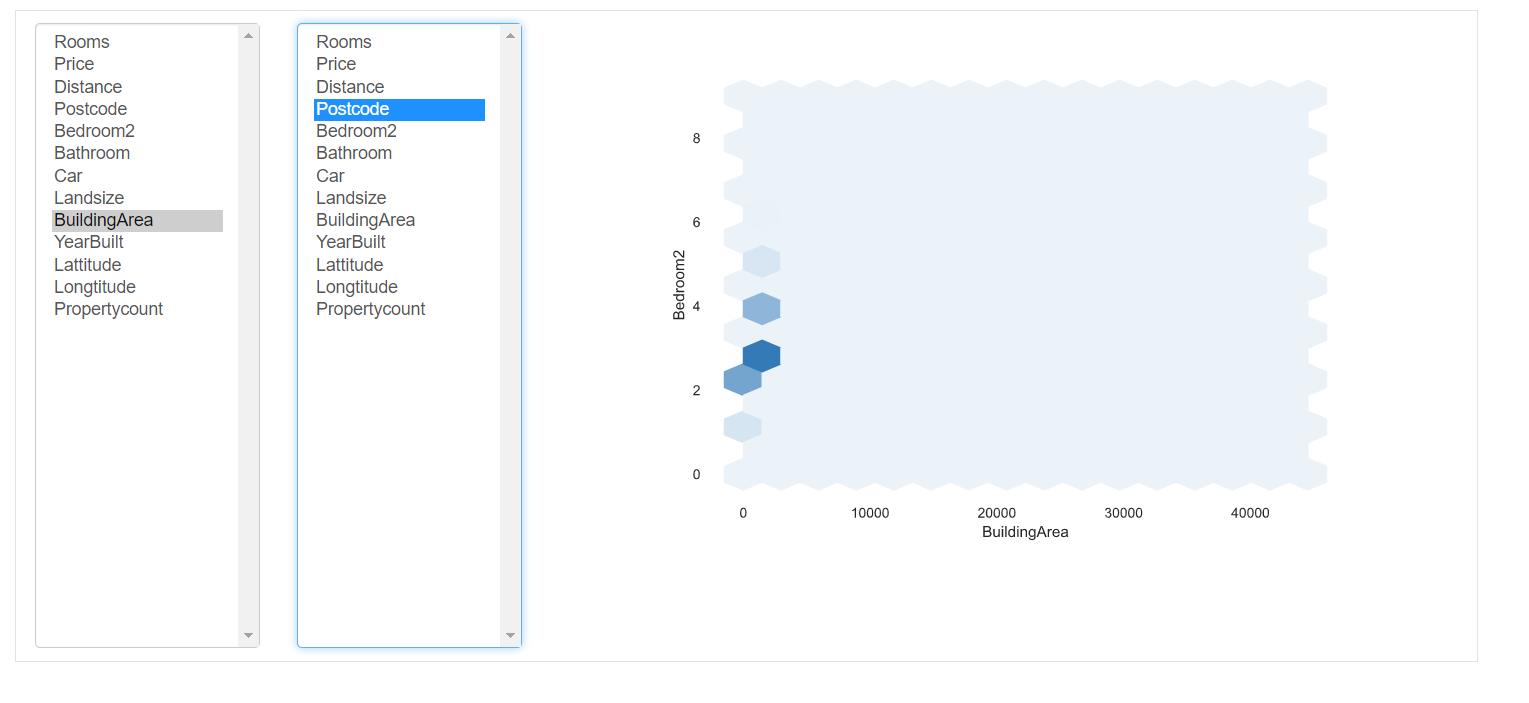
Interactions: cette partie du rapport montre les interactions des variables entre elles. Vous pouvez sélectionner n'importe quelle variable sur les axes respectifs.
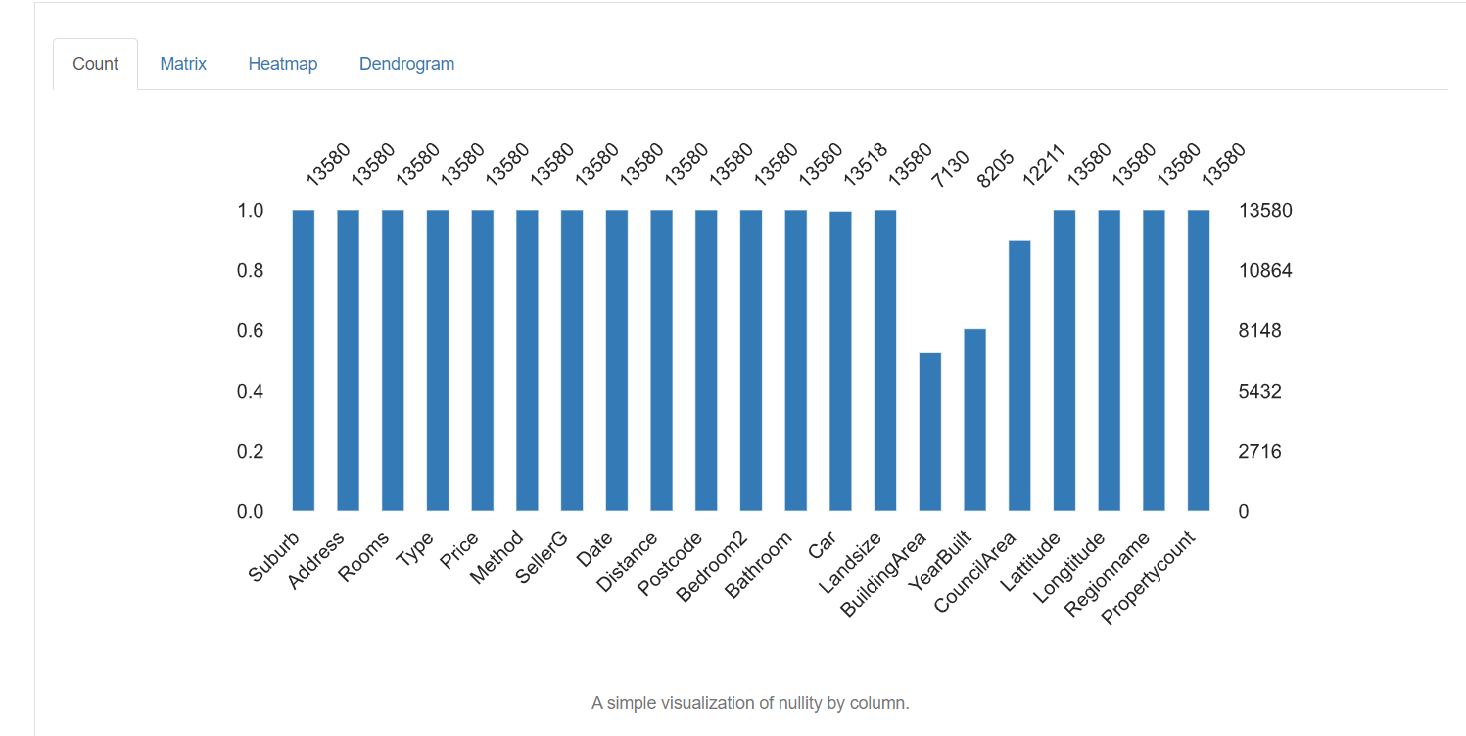
5. Valeurs manquantes: représente le nombre de valeurs manquantes dans chaque colonne.
Techniques de nettoyage des données
Nous avons maintenant une connaissance détaillée des données manquantes, valeurs incorrectes et catégories mal étiquetées dans l'ensemble de données. Nous allons maintenant voir certaines des techniques utilisées pour nettoyer les données. Cela dépend totalement de la qualité de l'ensemble de données, les résultats à obtenir de la façon dont vous traitez vos données. Certaines des techniques sont les suivantes:
Gestion des valeurs manquantes:
La gestion des valeurs manquantes est l'étape la plus importante du nettoyage des données. La première question à se poser est pourquoi les données manquent-elles ?? Manquant simplement parce que l'opérateur de saisie de données ne l'a pas enregistré ou a été intentionnellement laissé vide? Vous pouvez également consulter la documentation pour trouver la raison du même.
Il existe différentes manières de gérer ces valeurs manquantes:
1. Éliminer les valeurs manquantes: La façon la plus simple de les gérer est de simplement supprimer toutes les lignes qui contiennent des valeurs manquantes. Si vous ne voulez pas savoir pourquoi les valeurs sont manquantes et que vous n'avez qu'un faible pourcentage de valeurs manquantes, vous pouvez les supprimer en utilisant la commande suivante:
Cependant, ce n'est pas conseillé car toutes les données sont importantes et ont une grande importance pour les résultats globaux. Comme d'habitude, le pourcentage d'entrées manquantes dans une colonne particulière est élevé. Donc arrêter n'est pas une bonne option.
2. Imputation: L'imputation est le processus de remplacement des valeurs nulles / perdu pour une certaine valeur. Pour les colonnes numériques, une option consiste à remplacer chaque entrée manquante dans la colonne par la valeur moyenne ou la valeur médiane. Une autre option pourrait être de générer des nombres aléatoires entre une plage de valeurs appropriées pour la colonne. La plage peut être comprise entre la moyenne et l'écart type de la colonne. Vous pouvez simplement importer un imputer du package scikit-learn et effectuer l'imputation comme suit:
from sklearn.impute import SimpleImputer
#Imputation
my_imputer = SimpleImputer()
imputed_df = pd.DataFrame(my_imputer.fit_transform(df))Gestion des doublons:
Les lignes en double se produisent généralement lorsque les données sont combinées à partir de plusieurs sources. Parfois ça se reproduit. Un problème courant est lorsque les utilisateurs ont le même numéro d'identification ou que le formulaire a été soumis deux fois.
La solution à ces tuples en double est de simplement les supprimer. Vous pouvez utiliser la fonction unique () pour connaître les valeurs uniques présentes dans la colonne puis décider quelles valeurs doivent être supprimées.
Codage:
Le codage de caractères est défini comme l'ensemble de règles définies pour le mappage un à un des chaînes d'octets binaires brutes en chaînes de texte lisibles par l'homme. Divers encodages sont disponibles: ASCII, utf-8, US-ASCII, utf-16, utf-32, etc.
Vous pouvez remarquer que certains des champs de caractères de texte ont des motifs irréguliers et méconnaissables. C'est parce que utf-8 est l'encodage Python par défaut. Tout le code est en utf-8. Donc, lorsque les données proviennent de plusieurs sources structurées et non structurées et sont conservées dans un endroit commun, des motifs irréguliers sont observés dans le texte.
La solution au problème ci-dessus est de trouver d'abord l'encodage des caractères du fichier à l'aide du module chardet en Python comme suit:
import chardetwith open("C:/Users/Desktop/Dataset/housing.csv",'rb') as rawdata:result = chardet.detect(rawdata.read(10000))# check what the character encoding might beprint(result)
Après avoir trouvé le type d'encodage, si différent de utf-8, enregistrer le fichier en utilisant l'encodage “utf-8” en utilisant la commande suivante.
df.to_csv("C:/Users/Desktop/Dataset/housing.csv")Mise à l'échelle et normalisation
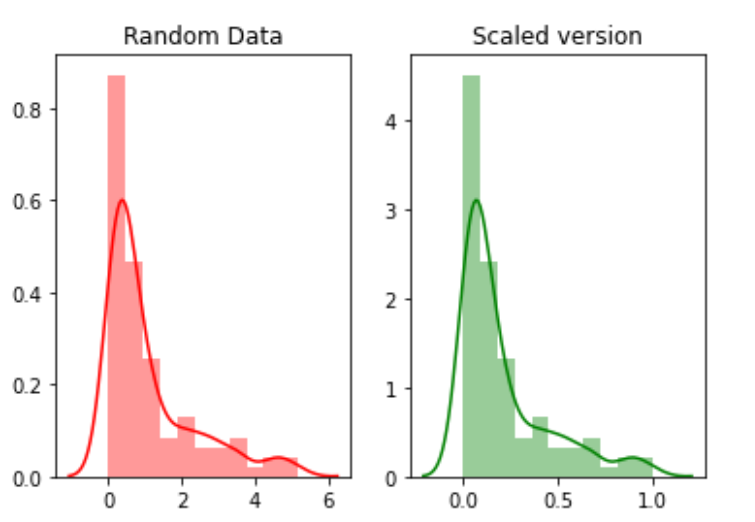
L'échelle fait référence à la transformation de la plage de données et à sa modification en une autre plage de valeurs. Ceci est avantageux lorsque nous voulons comparer différents attributs sur la même base.. Un exemple utile pourrait être la conversion de devises.
Par exemple, nous allons créer 100 points aléatoires d'une distribution exponentielle puis nous les tracerons. Finalement, nous les convertirons en une version mise à l'échelle à l'aide du package python mlxtend.
# for min_max scalingfrom mlxtend.preprocessing import minmax_scaling# plotting packagesimport seaborn as snsimport matplotlib.pyplot as plt
Maintenant, mettre à l'échelle les valeurs:
random_data = np.random.exponential(size=100)# mix-max scale the data between 0 and 1scaled_version = minmax_scaling(random_data, columns=[0])
Finalement, tracer les deux versions.
La normalisation fait référence à la modification de la distribution des données afin qu'elle puisse représenter une courbe en cloche où les valeurs des attributs sont également réparties sur la moyenne. La valeur de la moyenne et de la médiane est la même. Ce type de distribution est également appelé distribution gaussienne.. Il est nécessaire pour les algorithmes d'apprentissage automatique qui supposent que les données sont normalement distribuées.
À présent, nous allons normaliser les données en utilisant la fonction boxcox:
from scipy import statsnormalized_data = stats.boxcox(random_data)# plot both together to comparefig,ax=plt.subplots(1,2)sns.distplot(random_data, ax=ax[0],color="pink")ax[0].set_title("Random Data")sns.distplot(normalized_data[0], ax=ax[1],color="purple")ax[1].set_title("Normalized data")
Gestion des dates
Le champ de date est un attribut important qui doit être géré lors du nettoyage des données. Il existe plusieurs formats différents dans lesquels les données peuvent être saisies dans l'ensemble de données. Donc, la standardisation de la colonne de date est une tâche critique. Certaines personnes peuvent avoir traité la date comme une colonne de chaîne, d'autres en tant que colonne DateTime. Lorsque l'ensemble de données est combiné à partir de différentes sources, cela peut créer un problème pour l'analyse.
La solution consiste à trouver d'abord le type de colonne de date à l'aide de la commande suivante.
df['Date'].dtype
Si le type de colonne est différent de DateTime, convertissez-le en DateTime en utilisant la commande suivante:
import datetimedf['Date_parsed'] = pd.to_datetime(df['Date'], format="%m/%d/%y")
Gestion des problèmes de saisie de données incohérentes
Il existe un grand nombre d'entrées incohérentes qui ne peuvent pas être trouvées manuellement ou par des calculs directs. Par exemple, si la même entrée est écrite en majuscules ou en minuscules ou un mélange de majuscules et de minuscules. Ensuite, cette entrée doit être standardisée sur toute la colonne.
Une solution consiste à convertir toutes les entrées d'une colonne en minuscules et à réduire l'espace supplémentaire de chaque entrée. Cela peut être inversé plus tard une fois l'analyse terminée.
# convert to lower casedf['ReginonName'] = df['ReginonName'].str.lower()# remove trailing white spacesdf['ReginonName'] = df['ReginonName'].str.strip()
Une autre solution consiste à utiliser la correspondance approximative pour trouver les chaînes de la colonne les plus proches les unes des autres, puis à remplacer toutes ces entrées par un seuil particulier par l'entrée principale..
En premier lieu, nous découvrirons les noms uniques des régions:
region = df['Regionname'].unique()Ensuite, nous calculons les scores en utilisant une correspondance approximative:
import fuzzywuzzyfromfuzzywuzzy import processregions=fuzzywuzzy.process.extract("WesternVictoria",region,limit=10,scorer=fuzzywuzy.fuzz.token_sort_ratio)

Valider le processus.
Une fois le processus de nettoyage des données terminé, il est important de vérifier et de valider que les modifications que vous avez apportées n'ont pas entravé les restrictions imposées au jeu de données.
Et finalement, … Pas besoin de dire,
Merci pour la lecture!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





