introduction
Traitement du langage naturel (PNL) est un domaine d'attention croissante en raison du nombre croissant d'applications telles que les chatbots, traduction automatique, etc. En quelque sorte, Toute la révolution des machines intelligentes repose sur la capacité de comprendre et d'interagir avec les humains.
J'explore la PNL depuis un certain temps. Mon parcours a commencé avec la bibliothèque NLTK en Python, qui était la bibliothèque recommandée pour démarrer à ce moment-là. NLTK est une bibliothèque parfaite pour l'éducation et la recherche, devient très lourd et fastidieux pour accomplir même les tâches les plus simples.
Plus tard, J'ai été présenté à TextBlob, qui est basé sur NLTK et Pattern. Un grand avantage de ceci est qu'il est facile à apprendre et offre de nombreuses fonctionnalités telles que l'analyse des sentiments., étiquetage de position, extraction de syntagmes nominaux, etc. C'est maintenant devenu ma bibliothèque de référence pour effectuer des tâches de PNL.
Sur une note latérale, Il y a de l'espace, qui est largement reconnue comme l'une des bibliothèques puissantes et avancées utilisées pour implémenter des tâches NLP. Mais ayant trouvé à la fois Spacy et TextBlob, Je suggérerais toujours TextBlob à un débutant en raison de son interface simple.
Si c'est votre premier pas en PNL, TextBlob est la bibliothèque parfaite pour vous entraîner. La meilleure façon de lire cet article est de suivre le code et de faire les tâches vous-même. Alors commençons!
Noter : Cet article ne décrit pas les tâches de la PNL en profondeur. Si vous voulez revoir les bases et revenir ici, vous pouvez toujours lire cet article.
Table des matières
- À propos de TextBlob?
- Configurer le système
- Essayez les tâches de PNL avec TextBlob
- Tokenisation
- Extraction d'expressions nominales
- Étiquetage POS
- Inflexion et radical des mots
- N-grammes
- Analyse des sentiments
- Autres choses sympas à faire avec TextBlob
- Correction orthographique
- Créer un court résumé d'un texte
- Traduction et détection de langue
- Classer du texte à l'aide de TextBlob
- Avantages et les inconvénients
- Remarques finales
1. À propos de TextBlob?
TextBlob est une bibliothèque Python et propose une API simple pour accéder à ses méthodes et effectuer des tâches de base en PNL.
La bonne chose à propos de TextBlob est qu'ils sont comme des chaînes de python. Ensuite, vous pouvez le transformer et jouer avec de la même manière que nous l'avons fait en python. Ensuite, Je vous ai montré ci-dessous quelques tâches de base. Ne vous inquiétez pas de la syntaxe, c'est juste pour vous donner une idée de la relation entre le TextBlob et les chaînes Python.
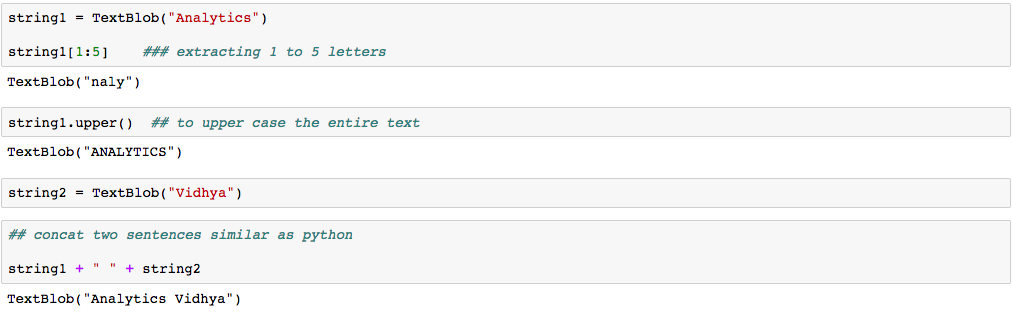 Ensuite, faire ces choses par vous-même, installons rapidement et commençons à coder.
Ensuite, faire ces choses par vous-même, installons rapidement et commençons à coder.
2. Configuration du système
Installation de TextBlob sur votre système en une seule tâche, tout ce que vous avez à faire est d'ouvrir l'indicateur anaconda (le terminal lui-même utilise Mac OS ou Ubuntu) et entrez les commandes suivantes:
pip install -U textblob
Cela installera TextBlob. Pour les non-initiés: les travaux pratiques en traitement automatique du langage naturel utilisent généralement de grandes quantités de données linguistiques, O corpus. Pour télécharger le corpus nécessaire, vous pouvez exécuter la commande suivante
python -m textblob.download_corpora
3. Tâches de PNL avec TextBlob
3.1 Tokenisation
La tokenisation fait référence à la division d'un texte ou d'une phrase en une séquence de jetons, qui correspondent approximativement à “mots”. C'est l'une des tâches de base de la PNL. Pour ce faire en utilisant TextBlob, suivre les deux étapes:
- Créer un texte objet et passer une corde avec.
- Lama les fonctions de textblob pour effectuer une tâche spécifique.
Ensuite, créons rapidement un objet textblob à jouer.
à partir de textblob importer TextBlob
blob = TextBlob("DataPeaker est une excellente plateforme pour apprendre la science des données. n Il aide la communauté à travers les blogs, hackathons, discussions,etc.")
À présent, ce bloc de texte peut être converti en phrase puis en mots. Voyons le code ci-dessous.
3.2 Extraction d'expressions nominales
Comment nous avons extrait les mots de la section précédente, au lieu, nous pouvons simplement extraire les phrases nominales du bloc de texte. L'extraction de syntagmes nominaux est particulièrement importante lorsque l'on veut analyser le “qui” dans une phrase. Voyons un exemple ci-dessous.
blob = TextBlob("DataPeaker est une excellente plate-forme pour apprendre la science des données.")
pour np dans blob.noun_phrases:
imprimer (par exemple)
>> vidhya analytique
super plateforme
science des données
Comme on le voit, les résultats ne sont pas tout à fait corrects, mais nous devons être conscients que nous travaillons avec des machines.
3.3 Étiqueter une partie de la voix
Le balisage des parties du discours ou le balisage grammatical est une méthode de marquage des mots présents dans un texte en fonction de leur définition et de leur contexte. En mots simples, dit si un mot est un nom, un adjectif, un verbe, etc. Ceci est juste une version complète de l'extraction de phrases nominales, où nous voulons trouver toutes les parties du discours dans une phrase.
Vérifions les étiquettes de notre bloc de texte.
pour les mots, balise dans blob.tags:
imprimer (mots, étiqueter)
>> Analytique NNS
Vidhya NNP
est VBZ
un DT
super JJ
plate-forme NN
à A
apprendre VB
données NNS
sciences NN
Ici, NN représente un nom, DT représente un déterminant, etc. Vous pouvez consulter la liste complète des étiquettes sur ici savoir mais.
3.4 Inflexion et radical des mots
Inflexion est un processus de mot formation dans laquelle des caractères sont ajoutés à la forme de base d'un mot exprimer des significations grammaticales. L'inflexion des mots dans TextBlob est très simple, c'est-à-dire, les mots que nous avons symbolisés à partir d'un textblob peuvent être facilement changés au singulier ou au pluriel.
blob = TextBlob("DataPeaker est une excellente plateforme pour apprendre la science des données. n Il aide la communauté à travers les blogs, hackathons, discussions,etc.")
imprimer (blob.phrases[1].mots[1])
imprimer (blob.phrases[1].mots[1].singulariser())
>> aide
aider
La bibliothèque TextBlob propose également un objet intégré appelé Mot. Nous avons juste besoin de créer un objet mot, puis de lui appliquer une fonction directement comme indiqué ci-dessous.
à partir de textblob importer Word
w = mot('Plate-forme')
w.pluraliser()
>>« Plateformes »
Nous pouvons également utiliser les balises pour infléchir un type particulier de mots comme indiqué ci-dessous.
## utiliser des balises pour mot,pos dans blob.tags: si pos == 'NN': imprimer (word.pluralize()) >> plates-formes les sciences
Les mots peuvent être radicalisés en utilisant le lématiser une fonction.
## lemmatisation
w = mot('fonctionnement')
w.lemmatiser("v") ## v ici représente le verbe
>> 'Cours'
3,5 N-grammes
Une combinaison de plusieurs mots ensemble s'appelle N-Grams. Les N grammes (N> 1) sont généralement plus informatifs que les mots et peuvent être utilisés comme fonctionnalités pour la modélisation du langage. Les N-grammes sont facilement accessibles dans TextBlob en utilisant le ngramas une fonction, qui renvoie un tuple de n mots successifs.
pour ngram dans blob.ngrams(2):
imprimer (ngramme)
>> ['Analytique', 'Vidhya']
['Vidhya', 'est']
['est', 'une']
['une', 'super']
['super', 'Plate-forme']
['Plate-forme', 'à']
['à', 'apprendre']
['apprendre', 'Les données']
['Les données', 'science']
3.6 Analyse des sentiments
L'analyse des sentiments est essentiellement le processus de détermination de l'attitude ou de l'émotion de l'écrivain, c'est-à-dire, oui c'est positif, négatif ou neutre.
Les sentiment la fonction textblob renvoie deux propriétés, polarité, Oui subjectivité.
La polarité est flottante qui est dans la gamme de [-1,1] où 1 signifie une déclaration positive et -1 signifie déclaration négative. Les phrases subjectives renvoient généralement à des opinions, émotions ou jugements personnels, tandis que les objectifs se réfèrent à des informations factuelles. La subjectivité est aussi un flotteur qui est de l'ordre de [0,1].
Passons en revue le sentiment de notre blob.
imprimer (goutte) blob.sentiment >> DataPeaker est une excellente plateforme pour apprendre la science des données. Sentiment(polarité=0.8, subjectivité=0,75)
On voit que la polarité est 0,8, ce qui signifie que l'énoncé est positif et 0,75 la subjectivité fait référence au fait qu'il s'agit principalement d'une opinion publique et non d'une information factuelle.
4. D'autres choses sympas à faire
4.1 Correction orthographique
La vérification orthographique est une fonctionnalité intéressante proposée par TextBlob, vous pouvez nous accéder en utilisant le C'est Correct travailler comme indiqué ci-dessous.
blob = TextBlob(« DataPeaker est une excellente plate-forme pour apprendre la science des données »)
blob.correct()
>> TextBlob("DataPeaker est une excellente plateforme pour apprendre la science des données")
Nous pouvons également vérifier la liste de mots suggérés et votre confiance en utilisant le vérificateur d'orthographe une fonction.
blob.mots[4].correcteur orthographique()
>> [('super', 0.5351351351351351),
('avoir', 0.3162162162162162),
('a grandi', 0.11216216216216217),
('gris', 0.026351351351351353),
('saluer', 0.006081081081081081),
('frette', 0.002702702702702703),
('grincer', 0.0006756756756756757),
('frisé', 0.0006756756756756757)]
4.2 Créer un court résumé d'un texte
C'est une astuce simple que nous utiliserons les choses que nous avons apprises plus tôt. Premier, jetez un oeil au code ci-dessous et comprenez-vous.
importer au hasard
blob = TextBlob('DataPeaker est une communauté florissante pour l'industrie axée sur les données. Cette plateforme permet
les gens à en savoir plus sur l'analyse de ses articles, Q&Un forum, et parcours d'apprentissage. Aussi, nous aidons
professionnels & amateurs d'affiner leurs compétences en fournissant une plate-forme pour participer à des Hackathons.')
noms = liste()
pour mot, balise dans blob.tags:
si balise == 'NN':
noms.append(mot.lemmatiser())
imprimer ("Ce texte concerne...")
pour l'élément dans random.sample(noms, 5):
mot = mot(Objet)
imprimer (word.pluralize())
>> Ce texte concerne...
communautés
plates-formes
forum
plates-formes
les industries
Simple, ce n'est pas comme ça? Ce que nous avons fait précédemment, c'est que nous avons extrait une liste de noms du texte pour donner au lecteur une idée générale des choses auxquelles le texte se rapporte..
4.3 Traduction et détection de langue
Pouvez-vous deviner ce qui est écrit sur la ligne suivante?
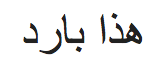
Et et! Pouvez-vous deviner de quelle langue il s'agit? Ne t'inquiète pas, nous le détectons en utilisant textblob…
blob.detect_language() >> 'Avec'
Ensuite, c'est de l'arabe. À présent, essayons de le traduire en anglais afin que nous puissions savoir ce qui est écrit en utilisant TextBlob.
blob.translate(from_lang='ar', à = 'fr')
>> TextBlob("c'est super")
Même si vous ne définissez pas explicitement la langue source, TextBlob détectera automatiquement la langue et la traduira dans la langue souhaitée.
blob.translate(à = 'fr') ## ou tu peux faire directement comme ça
>> TextBlob("c'est super")
C'est vraiment cool !!! ??
5. Classer du texte à l'aide de TextBlob
Construisons un modèle de classification de texte simple à l'aide de TextBlob. Pour ca, premier, nous devons préparer une formation et tester les données.
formation = [
('Tom Holland est un terrible spiderman.','pos'),
('un terrible Javert (Russel Crowe) ruiné Les Misérables pour moi...','pos'),
("The Dark Knight Rises est le plus grand film de super-héros de tous les temps!','nég'),
("Les Quatre Fantastiques n'auraient jamais dû être créés.",'pos'),
('Wes Anderson est mon réalisateur préféré!','nég'),
('Capitaine Amérique 2 est assez génial.','nég'),
('Faisons comme si "Batman et Robin" n'est jamais arrivé..','pos'),
]
test = [
("Superman n'a jamais été un personnage intéressant.",'pos'),
('Fantastic Mr Fox est un film génial!','nég'),
('Dragonball Evolution est tout simplement terrible!!','pos')
]
Textblob fournit un module de classificateurs intégré pour créer un classificateur personnalisé. Ensuite, importons-le rapidement et créons un classificateur de base.
à partir des classificateurs d'importation textblob classificateur = classificateurs.NaiveBayesClassifier(entraînement)
Comme vous pouvez le voir ci-dessus, nous avons transmis les données d'apprentissage au classificateur.
Notez qu'ici nous avons utilisé le classificateur Naive Bayes, mais TextBlob propose également le classificateur d'arbre de décision illustré ci-dessous.
## classificateur d'arbre de décision dt_classifier = classificateurs.DecisionTreeClassifier(entraînement)
À présent, vérifions l'exactitude de ce classificateur sur l'ensemble de données de test et TextBlob nous permet également de vérifier les fonctionnalités les plus informatives.
imprimer (classificateur.précision(essai))
classifier.show_informative_features(3)
>> 1.0
Fonctionnalités les plus informatives
contient(est) = Vrai nég : position = 2.9 : 1.0
contient(terrible) = Faux négatif : position = 1.8 : 1.0
contient(jamais) = Faux négatif : position = 1.8 : 1.0
Quoi, on peut voir que si le texte contient “il est”, alors il y a une forte probabilité que l'énoncé soit négatif.
pour donner un peu plus d'idée, vérifions notre classificateur sur un texte aléatoire.
blob = TextBlob('le temps est horrible!', classificateur=classificateur)
imprimer (blob.classify())
>> négatif
Ensuite, basé sur la formation dans l'ensemble de données ci-dessus, notre classificateur nous a donné le bon résultat.
Notez qu'ici nous aurions pu faire un prétraitement et un nettoyage des données, mais ici, mon objectif était de vous donner une idée de la façon dont nous pouvons effectuer une classification de texte à l'aide de TextBlob.
6. Avantages et les inconvénients
Avantages:
- Étant donné que, est construit sur les épaules de NLTK et Pattern, donc, simplifie les choses pour les débutants en fournissant une interface intuitive pour NLTK.
- Fournit une traduction et une détection de langue qui fonctionnent avec Google Translate (non fourni avec Spacy).
Les inconvénients:
- C'est un peu plus lent par rapport à l'espace, mais plus rapide que NLTK. (Espacer> TextBlob> NLTK)
- Ne fournit pas de fonctionnalités telles que l'analyse des dépendances, vecteurs de mots, etc. qui offre de l'espace.
7. Remarques finales
J'espère que vous vous amuserez à découvrir cette bibliothèque. TextBlob, en réalité, fourni une interface très simple pour les débutants pour apprendre les tâches de base de la PNL.
Je recommanderais à tous les débutants de commencer par cette bibliothèque, puis, faire un travail avancé, ils peuvent aussi apprendre à être espacés. Nous continuerons à utiliser TextBlob pour le prototypage initial dans presque tous les projets NLP.
Vous pouvez trouver le code complet de cet article dans mon github dépôt.
En outre, Avez-vous trouvé cet article utile? Partagez vos opinions / pensées dans la section des commentaires ci-dessous.





