Cet article a été publié dans le cadre du Blogathon sur la science des données
Prétraitement des données
C'est aussi une étape importante dans l'exploration de données, car nous ne pouvons pas travailler avec des données brutes. La qualité des données doit être vérifiée avant d'appliquer des algorithmes d'apprentissage automatique ou d'exploration de données.
Pourquoi le prétraitement des données est-il important?
Le pré-traitement des données sert principalement à vérifier la qualité des données. La qualité peut être vérifiée par les éléments suivants
- Précision: Pour vérifier si les données saisies sont correctes ou non.
- je le complète: Pour vérifier si les données sont disponibles ou non enregistrées.
- Cohérence: Pour vérifier si les mêmes données sont enregistrées dans tous les endroits correspondants ou non.
- Chance: Les données doivent être mises à jour correctement.
- Crédibilité: Les données doivent être fiables.
- Interprétabilité: L'intelligibilité des données.
- Nettoyage des données
- Intégration de données
- Réduction de donnée
- Transformation de données
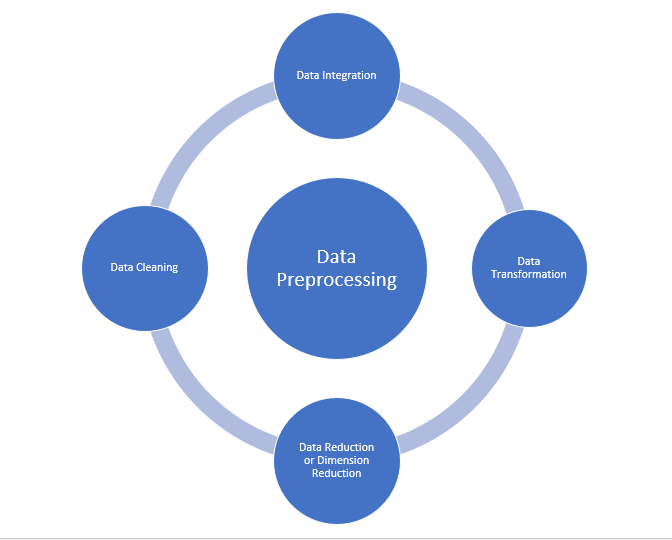
La source: medium.com
Nettoyage des données:
Le nettoyage des données est le processus de suppression des mauvaises données, données incomplètes et données inexactes des ensembles de données, et aussi remplacer les valeurs manquantes. Il existe des techniques de nettoyage des données
Gestion des valeurs manquantes:
- Vous pouvez utiliser des valeurs standard comme “Non disponible” O “N / A” remplacer les valeurs manquantes.
- Les valeurs manquantes peuvent également être renseignées manuellement, mais non recommandé lorsque l'ensemble de données est volumineux.
- La valeur médiane de l'attribut peut être utilisée pour remplacer la valeur manquante lorsque les données sont normalement distribuées.
dans lequel, dans le cas d'une distribution non normale, vous pouvez utiliser la valeur médiane de l'attribut. - Lors de l'utilisation d'algorithmes de régression ou d'arbre de décision, la valeur manquante peut être remplacée par la valeur la plus probable.
valeur.
Ruidoso:
Bruyant signifie généralement une erreur aléatoire ou contenant des points de données inutiles. Voici quelques-unes des méthodes de traitement des données bruitées.
- Binning: Cette méthode sert à lisser ou à gérer les données bruitées. Premier, les données sont triées puis les valeurs ordonnées sont séparées et stockées sous forme de conteneurs. Il existe trois méthodes pour lisser les données du conteneur. Lissage par la méthode de la moyenne bin: Dans cette méthode, les valeurs du conteneur sont remplacées par la valeur moyenne du conteneur; Lissage médian des bacs: Dans cette méthode, les valeurs du conteneur sont remplacées par la valeur médiane; Lissage des limites du conteneur: Dans cette méthode, les valeurs d'utilisation minimale et maximale sont extraites des valeurs de localisation et les valeurs sont remplacées par la valeur limite la plus proche.
- Régression: Il est utilisé pour lisser les données et aidera à gérer les données lorsqu'il y a des données inutiles. Pour analyse, objectif la régression aide à décider de la variable qui convient à notre analyse.
- Regroupement: Utilisé pour trouver les valeurs aberrantes et également pour regrouper les données. Le clustering est généralement utilisé dans l'apprentissage non supervisé.
Intégration de données:
Le processus de combinaison de plusieurs sources dans un seul ensemble de données. Le processus d'intégration des données est l'un des principaux composants de la gestion des données. Il y a quelques problèmes à prendre en compte lors de l'intégration des données.
- Intégration de schéma: Intégrer les métadonnées (un ensemble de données qui décrit d'autres données) de différentes sources.
- Problème d'identification d'entité: Identification d'entités à partir de plusieurs bases de données. Par exemple, le système ou l'application doit connaître l'étudiant _id d'une base de données et le nom de l'étudiant d'une autre base de données appartient à la même entité.
- Détecter et résoudre les concepts de valeur des données: Les données extraites de différentes bases de données lors de la fusion peuvent différer. Comment les valeurs d'attribut dans une base de données peuvent différer d'une autre base de données. Par exemple, le format de la date peut différer car “MM / JJ / AAAA” O “JJ / MM / AAAA”.
Réduction de donnée:
Ce processus permet de réduire le volume de données, qui facilite l'analyse et produit le même ou presque le même résultat. Cette réduction permet également de réduire l'espace de stockage.. Certaines des techniques de réduction des données sont la réduction de la dimensionnalité, Réduction de la numéralité, Compression de données.
- Réduction de la dimensionnalité: Ce processus est nécessaire pour les applications du monde réel, car la taille des données est grande. Dans ce processus, la réduction des attributs ou des variables aléatoires est effectuée de manière à réduire la dimensionnalité de l'ensemble de données. Combinez et fusionnez les attributs des données sans perdre leurs caractéristiques d'origine. Cela permet également de réduire l'espace de stockage et le temps de calcul.. Quand les données sont très dimensionnelles, le problème appelé “La malédiction de la dimensionnalité”.
- Réduction de la Nombreuse: Dans cette méthode, la représentation des données devient plus petite à mesure que le volume est réduit. Il n'y aura pas de perte de données dans cette réduction.
- Compression de données: La forme compressée des données est appelée compression de données. Cette compression peut être sans perte ou avec perte. Lorsqu'il n'y a pas de perte d'informations lors de la compression, est appelée compression sans perte. Alors que la compression avec perte réduit les informations, mais cela ne supprime que les informations inutiles.
Transformation de données:
La modification apportée au format ou à la structure des données est appelée transformation de données. Cette étape peut être simple ou complexe selon les besoins. Il existe des méthodes de transformation de données.
- Lissage: A l'aide d'algorithmes, nous pouvons supprimer le bruit de l'ensemble de données et aider à connaître les caractéristiques importantes de l'ensemble de données. En lissant, nous pouvons trouver même un simple changement qui aide à la prédiction.
- Agrégation: Dans cette méthode, les données sont stockées et présentées sous forme de résumé. L'ensemble de données provenant de plusieurs sources est intégré à la description de l'analyse des données. Il s'agit d'une étape importante car l'exactitude des données dépend de la quantité et de la qualité des données.. Lorsque la qualité et la quantité des données sont bonnes, les résultats sont plus pertinents.
- Discrétisation: Les données continues ici sont divisées en intervalles. La discrétisation réduit la taille des données. Par exemple, au lieu de spécifier l'heure du cours, nous pouvons définir un intervalle comme (3 pm-17 pm, 6 pm-20 pm).
- Normalisation: C'est la méthode de mise à l'échelle des données afin qu'elles puissent être représentées dans une plage plus petite. Exemple qui va de -1.0 une 1.0.
Étapes de prétraitement des données dans l'apprentissage automatique
Importer les bibliothèques et l'ensemble de données
import pandas as pd
import numpy as np
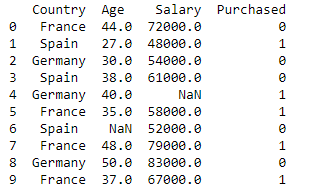
dataset = pd.read_csv('Datasets.csv')
imprimer (base de données)
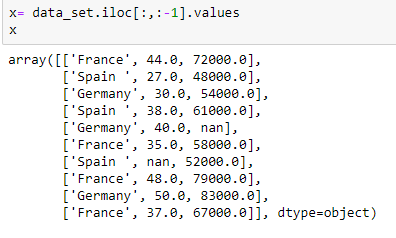
Extraction de variable indépendante:
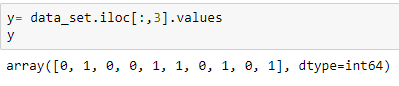
Extraction de la variable dépendante:
Remplir l'ensemble de données avec la valeur moyenne de l'attribut
from sklearn.preprocessing import Imputer imputer= Imputer(valeurs_manquantes="NaN", stratégie='moyen', axe = 0) imputerimputer = imputer.fit(X[:, 1:3]) X[:, 1:3]= imputer.transformer(X[:, 1:3]) X
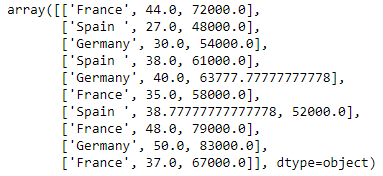
Codage de la variable pays
Les modèles d'apprentissage automatique utilisent des équations mathématiques. Ensuite, les données catégorielles ne sont pas acceptées, nous les convertissons donc sous forme numérique.
de sklearn.preprocessing importer LabelEncoder label_encoder_x= LabelEncoder() X[:, 0]= label_encoder_x.fit_transform(X[:, 0])
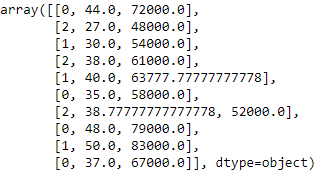
Codage factice
Ces variables muettes remplacent les données catégorielles comme 0 Oui 1 en l'absence ou en présence de données catégorielles spécifiques.
Codage de la variable achetée
labelencoder_y=Encodeur d'étiquette() y= labelencoder_y.fit_transform(Oui)
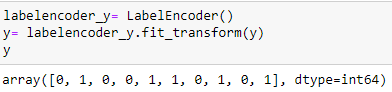
Divisez l'ensemble de données en ensemble d'entraînement et de test:
de sklearn.model_selection importer train_test_split x_train, x_test, y_train, y_test= train_test_split(X, Oui, taille_test= 0.2, état_aléatoire=0)
Échelle de fonctionnalité
de sklearn.preprocessing importer StandardScaler
st_x= StandardScaler() x_train= st_x.fit_transform(x_train)

x_test= st_x.transform(x_test)
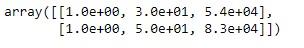
conclusion:
Dans cet article, J'ai expliqué que l'étape la plus cruciale de l'apprentissage automatique est le prétraitement des données. J'espère que cet article vous aidera à mieux comprendre le concept.
Référence:
https://www.javatpoint.com/data-preprocessing-machine-learning
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





