
Organiser 1: Toute banque mondiale a aujourd'hui plus de 100 des millions de clients effectuant des milliards de transactions chaque mois.
Organiser 2: Les sites Web de médias sociaux ou les sites Web de commerce électronique suivent le comportement des clients sur le site Web, puis fournissent des informations / produit pertinent.
Les systèmes traditionnels ont du mal à faire face à cette échelle au taux requis de manière rentable.
C'est là que les plateformes Big Data viennent en aide.. Dans cet article, nous vous présentons le monde fascinant de Hadoop. Hadoop est utile lorsqu'il s'agit de traiter d'énormes données. Cela peut ne pas accélérer le processus, mais cela nous donne la possibilité d'utiliser la puissance de traitement parallèle pour gérer le Big Data. En résumé, Hadoop nous permet de gérer les complexités de volume élevé, vitesse et variété des données (populairement connu sous le nom de 3V).
Notez que, en plus de Hadoop, il existe d'autres plateformes de big data, par exemple, NoSQL (MongoDB est le plus populaire), on les verra plus tard.
Introduction à Hadoop
Hadoop est un écosystème complet de projets open source qui nous fournit le cadre pour traiter le big data.. Commençons par réfléchir aux défis potentiels liés au traitement des mégadonnées (dans les systèmes traditionnels) et voyons ensuite la capacité de la solution Hadoop.
Voici les défis auxquels je peux penser lorsque je traite des mégadonnées:
1. Investissement en capital élevé dans l'acquisition d'un serveur avec une capacité de traitement élevée.
2. Beaucoup de temps investi
3. En cas de requête longue, imaginez qu'une erreur se produise dans la dernière étape. Vous perdrez beaucoup de temps à faire ces itérations.
4. Difficulté à générer des requêtes sur le programme
Voici comment Hadoop résout tous ces problèmes:
1. Investissement important dans l'acquisition d'un serveur à haut débit: Les clusters Hadoop s'exécutent sur du matériel de base normal et conservent plusieurs copies pour garantir la fiabilité des données. Un maximum de 4500 machines ensemble à l'aide d'Hadoop.
2. Beaucoup de temps investi : Le processus est divisé en plusieurs parties et se déroule en parallèle, gagner du temps. Un maximum de 25 Pétaoctets (1 PB = 1000 TB) données avec Hadoop.
3. En cas de requête longue, imaginez qu'une erreur se produise dans la dernière étape. Vous perdrez beaucoup de temps à faire ces itérations : Hadoop sauvegarde les ensembles de données à tous les niveaux. Exécute également des requêtes sur des ensembles de données en double pour éviter la perte de processus en cas d'échec individuel. Ces étapes rendent le traitement Hadoop plus précis et précis.
4. Difficulté à générer des requêtes sur le programme : Les requêtes dans Hadoop sont aussi simples que de coder dans n'importe quelle langue. Vous avez juste besoin de changer votre façon de penser à la création d'une requête pour permettre le traitement parallèle.
Fond d'écran Hadoop
Avec une augmentation de la pénétration d'Internet et de l'utilisation d'Internet, les données capturées par Google ont augmenté de façon exponentielle d'année en année. Juste pour vous donner une estimation de ce nombre, dans 2007 Google a collecté en moyenne 270 PB de données chaque mois. Le même nombre est passé à 20000 PB tous les jours dans 2009. Évidemment, Google avait besoin d'une meilleure plate-forme pour traiter des données aussi volumineuses. Google a implémenté un modèle de programmation appelé MapReduce, qui pourrait traiter ces 20000 Po par jour. Google a exécuté ces opérations MapReduce sur un système de fichiers spécial appelé Google File System (GFS). Malheureusement, GFS n'est pas open source.
Doug Cutting et Yahoo! rétroconçu le modèle GFS et construit un système de fichiers distribué Hadoop (HDFS) parallèle. Le logiciel ou le framework qui prend en charge HDFS et MapReduce est connu sous le nom de Hadoop. Hadoop est open source et distribué par Apache.
Peut-être êtes-vous intéressé: Introduction à MapReduce
Cadre de traitement Hadoop
Tirons une analogie de notre quotidien pour comprendre comment fonctionne Hadoop. La base de la pyramide de toute entreprise, ce sont les personnes qui sont des contribuables individuels. Ils peuvent être des analystes, programmeurs, travail manuel, cuisiniers, etc. La gestion de votre travail est le chef de projet. Le chef de projet est responsable de la bonne exécution de la tâche. Besoin de répartir le travail, fluidifier la coordination entre eux, etc. En outre, la plupart de ces entreprises ont un responsable du personnel, qui est plus soucieux de conserver l'équipe.

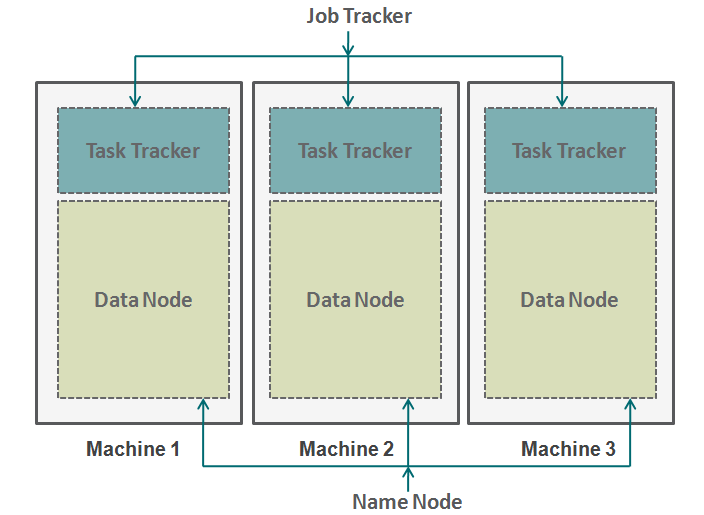
Hadoop fonctionne dans un format similaire. En bas nous avons les machines disposées en parallèle. Ces machines sont analogues au contribuable individuel dans notre analogie. Chaque machine dispose d'un nœud de données et d'un suivi des travaux. Le nœud de données est également connu sous le nom de HDFS (Système de fichiers distribué Hadoop) et le suivi des tâches est également connu sous le nom de réducteurs de carte.
Le nœud de données contient l'intégralité de l'ensemble de données et le suivi des tâches effectue toutes les opérations. Vous pouvez imaginer le tracker de tâches comme vos bras et vos jambes, vous permettant d'effectuer une tâche et un nœud de données en tant que cerveau, contenant toutes les informations que vous souhaitez traiter. Ces machines fonctionnent en silos et il est très important de les coordonner. Suivi des tâches (chef de projet dans notre analogie) sur différentes machines sont coordonnés par un job tracker. Job Tracker s'assure que chaque opération est terminée et s'il y a un échec de processus sur un nœud, vous devez attribuer une tâche en double à un suivi de tâches. Le suivi des travaux distribue également l'ensemble de la tâche à toutes les machines.
D'un autre côté, un nœud nommé coordonne tous les nœuds de données. Il régit la distribution des données qui vont à chaque machine. Il vérifie également tout type de purge qui s'est produit dans une machine. Si un tel débogage se produit, trouve les données en double qui ont été envoyées à un autre nœud de données et les duplique à nouveau. Vous pouvez considérer ce nœud de nom comme le gestionnaire de personnes dans notre analogie, qui se soucie davantage de la conservation de l'ensemble de données.
Quand ne pas utiliser Hadoop?
Jusqu'à maintenant, nous avons vu comment Hadoop a rendu possible le traitement des mégadonnées. Mais dans certains scénarios, la mise en œuvre d'Hadoop n'est pas recommandée. Voici quelques-uns de ces scénarios:
- Accès aux données à faible latence: accès rapide à de petites données
- Modification de plusieurs données: Hadoop n'est mieux adapté que si nous sommes principalement concernés par la lecture de données et non par l'écriture de données.
- Beaucoup de petits fichiers: Hadoop s'intègre mieux dans les scénarios, où nous avons peu mais gros fichiers.
Remarques finales
Cet article vous donne un aperçu de la façon dont Hadoop vient à la rescousse lorsqu'il s'agit de traiter d'énormes données. Comprendre comment fonctionne Hadoop est essentiel avant de commencer à le coder. C'est parce que vous devez changer votre façon de penser à un code. Vous devez maintenant commencer à penser à activer le traitement parallèle. Vous pouvez effectuer de nombreux types de processus différents dans Hadoop, mais vous devez convertir tous ces codes en une fonction de réduction de carte. Dans les prochains articles, nous expliquerons comment vous pouvez convertir votre logique simple en logique Map-Reduce basée sur Hadoop. Nous effectuerons également des études de cas spécifiques au langage R pour développer une solide compréhension de l'application Hadoop..
L'article vous a-t-il été utile? Partagez avec nous toutes les applications pratiques Hadoop que vous avez rencontrées au travail. Faites-nous part de vos impressions sur cet article dans la case ci-dessous..





