Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Il y a eu un certain nombre de progrès dans le domaine de l'apprentissage en profondeur et de la vision par ordinateur. Surtout avec l'introduction de réseaux de neurones convolutifs très profonds, ces modèles ont permis d'obtenir des résultats de pointe sur des problèmes tels que la reconnaissance d'images et la classification d'images.
Ensuite, au fil des ans, les architectures d'apprentissage en profondeur sont devenues de plus en plus profondes (ajouter plus de couches) pour résoudre des tâches de plus en plus complexes, ce qui a également permis d'améliorer la performance des tâches de classification et de reconnaissance et aussi de les rendre robustes.
Mais quand nous continuons à ajouter plus de couches au réseau de neurones, il devient beaucoup plus difficile à entraîner et la précision du modèle commence à saturer puis se dégrade également. Voici le ResNet pour nous sauver de ce scénario et aider à résoudre ce problème.
Qu'est-ce que ResNet?
Réseau résiduel (ResNet) est l'un des célèbres modèles d'apprentissage en profondeur introduits par Shaoqing Ren, Kaiming il, Jian Sun et Xiangyu Zhang dans leur article. Le document a été nommé “Apprentissage résiduel profond pour la reconnaissance d'images”. [1] dans 2015. Le modèle ResNet est l'un des modèles d'apprentissage en profondeur les plus populaires et les plus réussis à ce jour.
Blocs résiduels
Le problème de la formation de réseaux très profonds a été atténué avec l'introduction de ces blocs résiduels et le modèle ResNet est constitué de ces blocs.
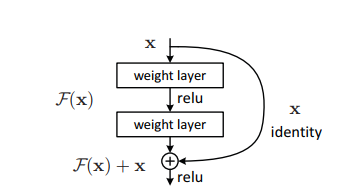
Le problème de la formation de réseaux très profonds a été atténué avec l'introduction de ces blocs résiduels et le modèle ResNet est constitué de ces blocs.
Dans la figure ci-dessus, la première chose que nous pouvons remarquer est qu'il existe une connexion directe qui omet certaines couches du modèle. Cette connexion s'appelle “connexion de saut” et c'est le coeur des blocs résiduels. La sortie n'est pas la même en raison de cette connexion de saut. Sans la connexion de saut, l'entrée 'X est multipliée par les pondérations des couches suivies de l'ajout d'un terme asymétrique.
Vient ensuite la fonction d'activation, F () et nous obtenons la sortie comme H (X).
H (X) = f (wx + b) Oh (X) = f (X)
À présent, avec l'introduction d'une nouvelle technique de connexion par saut, la sortie est H (X) ça change en
H (X) = f (X) + X
Mais la dimension de l'entrée peut varier de celle de la sortie, ce qui pourrait arriver à une couche convolutive ou à des couches groupées. Donc, ce problème peut être traité avec ces deux approches:
· Zero est rembourré avec la connexion de saut pour augmenter ses dimensions.
· Des couches convolutives sont ajoutées 1 × 1 à l'entrée pour correspondre aux dimensions. Dans ce cas, la sortie est:
H (X) = f (X) + w1.x
Ici, un paramètre supplémentaire w1 est ajouté alors qu'aucun paramètre supplémentaire n'est ajouté lors de l'utilisation de la première approche.
Cette technique de contournement dans ResNet résout le problème de la disparition du gradient dans les CNN profonds en permettant un chemin de raccourci alternatif pour que le gradient s'écoule.. En outre, la connexion de contournement aide si une couche nuit aux performances de l'architecture, alors il sera ignoré par régularisation.
Architecture ResNet
Il existe un simple réseau de 34 des couches d'architecture inspirées de VGG-19 dans lesquelles des connexions d'accès direct ou des connexions de saut sont ajoutées. Ces connexions de saut ou blocs résiduels convertissent ensuite l'architecture en réseau résiduel comme illustré dans la figure ci-dessous.
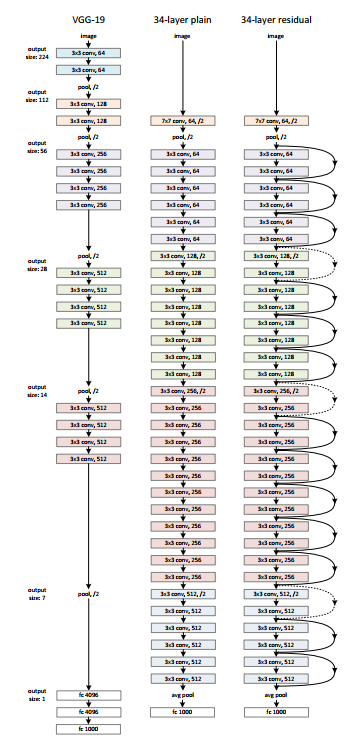
La source: ‘Apprentissage résiduel profond pour la reconnaissance d'images‘ papier
Utiliser ResNet avec Keras:
Keras est une bibliothèque d'apprentissage en profondeur open source capable de s'exécuter sur TensorFlow. Keras Applications fournit les versions suivantes de ResNet.
– ResNet50
– ResNet50V2
– ResNet101
– ResNet101V2
– ResNet152
– ResNet152V2
Construisons ResNet à partir de zéro:
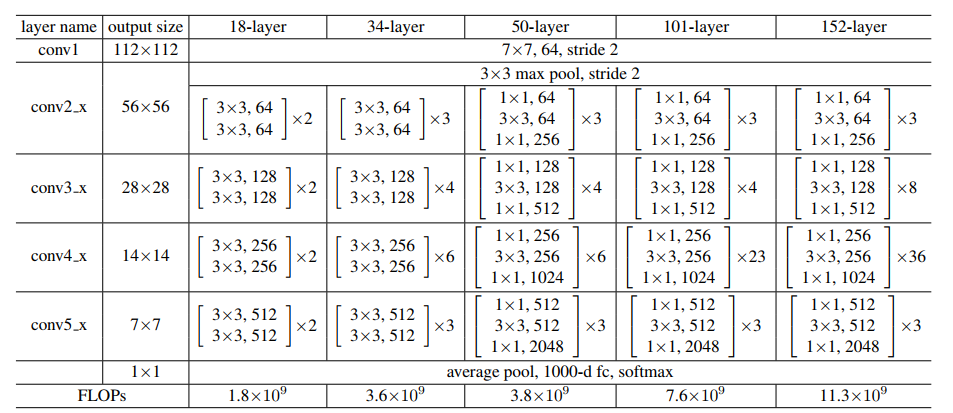
La source: ‘Apprentissage résiduel profond pour la reconnaissance d'images‘ papier
Gardons l'image ci-dessus pour référence et commençons à construire le réseau..
L'architecture ResNet utilise plusieurs fois les blocs CNN, créons donc une classe pour le bloc CNN, qui prend les canaux d'entrée et les canaux de sortie. Il y a un batchnorm2d après chaque couche de conv.
torche d'importation importer torch.nn en tant que nn
bloc de classe(nn.Module):
def __init__(
soi, in_channels, canaux_intermédiaires, identity_downsample=Aucun, foulée=1
):
super(bloquer, soi).__init__()
self.expansion = 4
self.conv1 = nn.Conv2d(
in_channels, canaux_intermédiaires, kernel_size=1, foulée=1, remplissage=0, biais=Faux
)
self.bn1 = nn.BatchNorm2d(canaux_intermédiaires)
self.conv2 = nn.Conv2d(
canaux_intermédiaires,
canaux_intermédiaires,
taille_noyau=3,
foulée= foulée,
remplissage=1,
biais=Faux
)
self.bn2 = nn.BatchNorm2d(canaux_intermédiaires)
self.conv3 = nn.Conv2d(
canaux_intermédiaires,
canaux_intermédiaires * auto-expansion,
kernel_size=1,
foulée=1,
remplissage=0,
biais=Faux
)
self.bn3 = nn.BatchNorm2d(canaux_intermédiaires * auto-expansion)
self.relu = nn.ReLU()
self.identity_downsample = identity_downsample
self.stride = foulée
def vers l'avant(soi, X):
identité = x.clone()
x = self.conv1(X)
x = soi.bn1(X)
x = self.relu(X)
x = self.conv2(X)
x = soi.bn2(X)
x = self.relu(X)
x = self.conv3(X)
x = soi.bn3(X)
si self.identity_downsample n'est pas None:
identité = self.identity_downsample(identité)
x += identité
x = self.relu(X)
retourner x
Alors, créer une classe ResNet qui prend l'entrée de plusieurs blocs, couvre, canaux d'image et le nombre de classes.
Dans le code suivant, la fonction '_make_layer’
créer les couches ResNet, qui prend l'entrée des blocs, le nombre de résidus
blocs, canal de sortie et foulées.
classe ResNet(nn.Module):
def __init__(soi, bloquer, couches, image_channels, nombre_classes):
super(ResNet, soi).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(image_channels, 64, kernel_size=7, foulée=2, remplissage=3, biais=Faux)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(taille_noyau=3, foulée=2, remplissage=1)
# Essentiellement, l'ensemble de l'architecture ResNet se trouve dans ces 4 lignes ci-dessous self.layer1 = self._make_layer( bloquer, couches[0], intermédiaires_canaux=64, foulée=1 ) self.layer2 = self._make_layer( bloquer, couches[1], intermédiaires_canaux=128, foulée=2 ) self.layer3 = self._make_layer( bloquer, couches[2], intermédiaires_canaux=256, foulée=2 ) self.layer4 = self._make_layer( bloquer, couches[3], intermédiaires_canaux=512, foulée=2 ) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.fc = nn.Linéaire(512 * 4, nombre_classes) def vers l'avant(soi, X): x = self.conv1(X) x = soi.bn1(X) x = self.relu(X) x = self.maxpool(X) x = self.layer1(X) x = self.layer2(X) x = self.layer3(X) x = self.layer4(X) x = self.avgpool(X) x = x.remodeler(x.forme[0], -1) x = soi.fc(X) retourner x def _make_layer(soi, bloquer, nombre_blocs_résiduels, canaux_intermédiaires, foulée): identity_downsample = Aucun couches = [] # Soit si nous la moitié de l'espace d'entrée pour ex, 56x56 -> 28x28 (foulée=2), ou des changements de canaux # nous devons adapter l'Identité (ignorer la connexion) il pourra donc être ajouté # à la couche qui est devant si foulée != 1 ou self.in_channels != canaux_intermédiaires * 4: identity_downsample = nn.Sequential( nn.Conv2d( self.in_channels, canaux_intermédiaires * 4, kernel_size=1, foulée= foulée, biais=Faux ), nn.BatchNorm2d(canaux_intermédiaires * 4), ) calques.append( bloquer(self.in_channels, canaux_intermédiaires, identité_sous-échantillon, foulée) ) # La taille d'extension est toujours 4 pour ResNet 50,101,152 self.in_channels = intermédiaires_channels * 4 # Par exemple pour la première couche resnet: 256 sera mappé sur 64 comme couche intermédiaire, # puis enfin retour à 256. Par conséquent, aucun sous-échantillonnage d'identité n'est nécessaire, puisque foulée = 1, # et aussi le même nombre de canaux. pour moi à portée(nombre_blocs_résiduels - 1): calques.append(bloquer(self.in_channels, canaux_intermédiaires))
retour nn.Séquentielle (* couvre)
Définissez ensuite différentes versions de ResNet
– Pour ResNet50, la séquence de couches est [3, 4, 6, 3].
– Pour ResNet101, la séquence de couches est [3, 4, 23, 3].
– Pour ResNet152, la séquence de couches est [3, 8, 36, 3]. (Demande à ‘Apprentissage résiduel profond pour la reconnaissance d'images‘ papier)
def ResNet50(img_channel=3, nombre_classes=1000):
retour ResNet(bloquer, [3, 4, 6, 3], img_canal, nombre_classes)
def ResNet101(img_channel=3, nombre_classes=1000): retour ResNet(bloquer, [3, 4, 23, 3], img_canal, nombre_classes) def ResNet152(img_channel=3, nombre_classes=1000): retour ResNet(bloquer, [3, 8, 36, 3], img_canal, nombre_classes)
Alors, écrivez un petit code de test pour vérifier si le modèle fonctionne bien.
test de définition():
net = ResNet101(img_channel=3, nombre_classes=1000)
appareil = "miracle" si torch.cuda.is_available() autre "CPU"
y = net(torche.randn(4, 3, 224, 224)).à(dispositif)
imprimer(y.taille())
test()
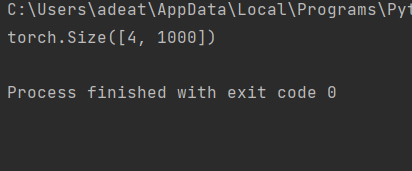
Pour le cas de test ci-dessus, la sortie doit être:
Le code complet est accessible ici:
https://github.com/BakingBrains/Deep_Learning_models_implementation_from-scratch_using_pytorch_/blob/main/ResNet_.py
[1]. Kaiming il, Xiangyu Zhang, Shaoqing Ren, Jian Soleil: Apprentissage profond résiduel pour la reconnaissance d'images, décembre de 2015, EST CE QUE JE: https://arxiv.org/abs/1512.03385
Merci.
Vos suggestions et doutes sont les bienvenus ici dans la section commentaires. Merci d'avoir lu mon article!





