Vue d'ensemble
- Comprendre Spark Streaming et son fonctionnement.
- En savoir plus sur Windows dans Spark Streaming avec un exemple.
introduction
Selon IBM, les 60% de toutes les informations sensorielles perdent de la valeur en quelques millisecondes si elles ne sont pas utilisées. Compte tenu du fait que le marché du Big Data et de l’analytique a atteint le $ 125 milliards et une grande partie de cela sera attribuée à l’IoT à l’avenir, l’incapacité de tirer parti de l’information en temps réel entraînera une perte de milliards de dollars.
Des exemples de certaines de ces applications incluent une entreprise de télécommunications, qui calcule combien de ses utilisateurs ont utilisé Whatsapp au cours des dernières années 30 minutes, un détaillant qui garde une trace du nombre de personnes qui ont dit des choses positives sur leurs produits aujourd’hui sur les médias sociaux, ou un organisme d’application de la loi à la recherche d’un suspect à l’aide de données de vidéosurveillance routière.
Esta es la razón principal por la que los sistemas de procesamiento de flujos como Spark Streaming definirán el futuro de la analytiqueL’analytique fait référence au processus de collecte, Mesurer et analyser les données pour obtenir des informations précieuses qui facilitent la prise de décision. Dans divers domaines, Comme les affaires, Santé et sport, L’analytique peut identifier des modèles et des tendances, Optimiser les processus et améliorer les résultats. L’utilisation d’outils et de techniques statistiques de pointe est essentielle pour transformer les données en connaissances applicables et stratégiques.... temps réel. Il existe également un besoin croissant d’analyser à la fois les données au repos et les données en mouvement pour alimenter les applications., ce qui fait des systèmes comme Spark, qui peut faire les deux, sont encore plus attrayants et puissants. C’est un système pour toutes les saisons de Big Data.
Vous apprendrez comment Spark Streaming ne se contente pas de garder intacte l’API Spark familière, mais aussi, sous le capot, utilise RDD pour le stockage et la tolérance aux pannes. Cela permet aux professionnels de Spark de se lancer dans le monde du streaming dès le début.. Dans cet esprit, allons-y directement.
Introduction à Spark Streaming | par Harshit Agarwal | Moitié
Table des matières
- Apache SparkApache Spark es un motor de procesamiento de datos de código abierto que permite el análisis de grandes volúmenes de información de manera rápida y eficiente. Su diseño se basa en la memoria, lo que optimiza el rendimiento en comparación con otras herramientas de procesamiento por lotes. Spark es ampliamente utilizado en aplicaciones de big data, machine learning y análisis en tiempo real, gracias a su facilidad de uso y...
- Écosystème Apache Spark
- Diffusion Spark: DStreams
- Diffusion Spark: contexte de transmission
- Exemple: nombre de mots
- Diffusion Spark: Fenêtre
- Une fenêtre basée sur: nombre de mots
- Un (plus efficace) basé sur des fenêtres: nombre de mots
- Diffusion Spark: opérations de sortie
Apache Spark
Apache Spark est un moteur informatique unifié et un ensemble de bibliothèques pour le traitement parallèle des données sur des clusters d'ordinateurs. Au moment de la rédaction de cet article, Spark est le moteur open source le plus développé pour cette tâche, ce qui en fait un outil standard pour tout développeur ou data scientist intéressé par le big data.
Spark prend en charge plusieurs langages de programmation largement utilisés (Python, Java, Échelle y R), inclut des bibliothèques pour diverses tâches allant de SQL au streaming en passant par l'apprentissage automatique, et fonctionne n’importe où, desde una computadora portátil hasta un grappeUn cluster est un ensemble d’entreprises et d’organisations interconnectées qui opèrent dans le même secteur ou la même zone géographique, et qui collaborent pour améliorer leur compétitivité. Ces regroupements permettent le partage des ressources, Connaissances et technologies, favoriser l’innovation et la croissance économique. Les grappes peuvent couvrir une variété d’industries, De la technologie à l’agriculture, et sont fondamentaux pour le développement régional et la création d’emplois.... de miles de servidores. Cela en fait un système facile à démarrer et à étendre au traitement de données volumineuses ou à une échelle incroyablement grande.. Voici quelques-unes des fonctionnalités de Spark:
-
Moteur rapide et polyvalent pour le traitement de données à grande échelle
-
Spark peut prendre en charge efficacement plus de types de Calculi
-
Vous pouvez lire / écrire sur n’importe quel système compatible Hadoop (par exemple, HDFSHDFS, o Système de fichiers distribués Hadoop, Il s’agit d’une infrastructure clé pour stocker de gros volumes de données. Conçu pour fonctionner sur du matériel commun, HDFS permet la distribution des données sur plusieurs nœuds, Garantir une disponibilité élevée et une tolérance aux pannes. Son architecture est basée sur un modèle maître-esclave, où un nœud maître gère le système et les nœuds esclaves stockent les données, faciliter le traitement efficace de l’information..)
- La vitesse: stockage de données en mémoire pour des requêtes itératives très rapides
-
el sistema también es más eficiente que CarteRéduireMapReduce est un modèle de programmation conçu pour traiter et générer efficacement de grands ensembles de données. Propulsé par Google, Cette approche décompose le travail en tâches plus petites, qui sont répartis entre plusieurs nœuds d’un cluster. Chaque nœud traite sa partie, puis les résultats sont combinés. Cette méthode vous permet de faire évoluer les applications et de gérer d’énormes volumes d’informations, fondamental dans le monde du Big Data.... para aplicaciones complejas que se ejecutan en el disco
-
jusqu'à 40 fois plus rapide que Hadoop
-
Ingérer des données provenant de nombreuses sources: Kafka, Twitter, HDFS, sockets TCP
-
Les résultats peuvent être envoyés aux systèmes de fichiers, base de données, panneaux en direct, mais pas seulement
-

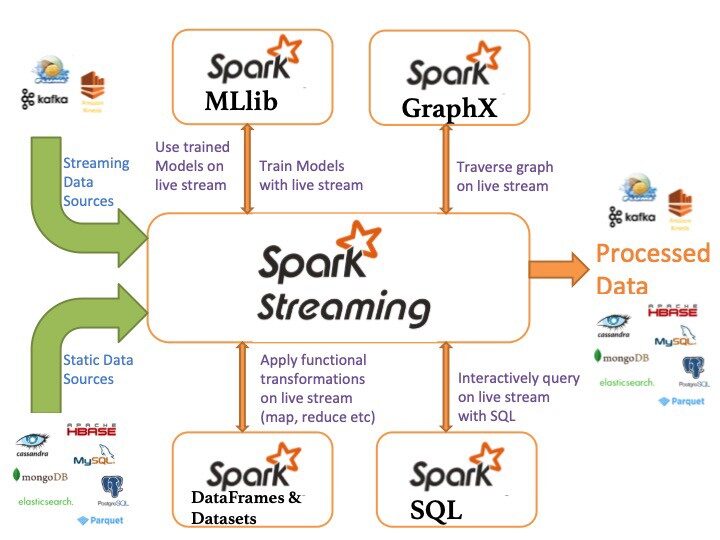
Écosystème Apache Spark
Voici les composants de l’écosystème Apache Spark:
- Noyau d'étincelle: fonctionnalité spark de base (planification des tâches, gestion de la mémoire, échec de la récupération, interaction avec le système de stockage).
-
Spark SQL: package pour l’utilisation de données structurées interrogées via SQL et HiveQL
-
Diffusion Spark: un composant qui permet le traitement des flux de données en direct (par exemple, fichiers journaux, messages de mise à jour d’état)
- MLLib: MLLib est une bibliothèque d’apprentissage automatique comme Mahout. Il est construit sur Spark et a la capacité de prendre en charge de nombreux algorithmes d’apprentissage automatique.
- GraphX: Pour les graphiques et les calculs graphiques, Spark dispose de son propre moteur de calcul graphique, appelé GraphX. Il est similaire à d’autres outils de traitement graphique ou bases de données largement utilisés, comme Neo4j, Giraffe et de nombreuses autres bases de données graphiques distribuées.
Diffusion Spark: Abstractions
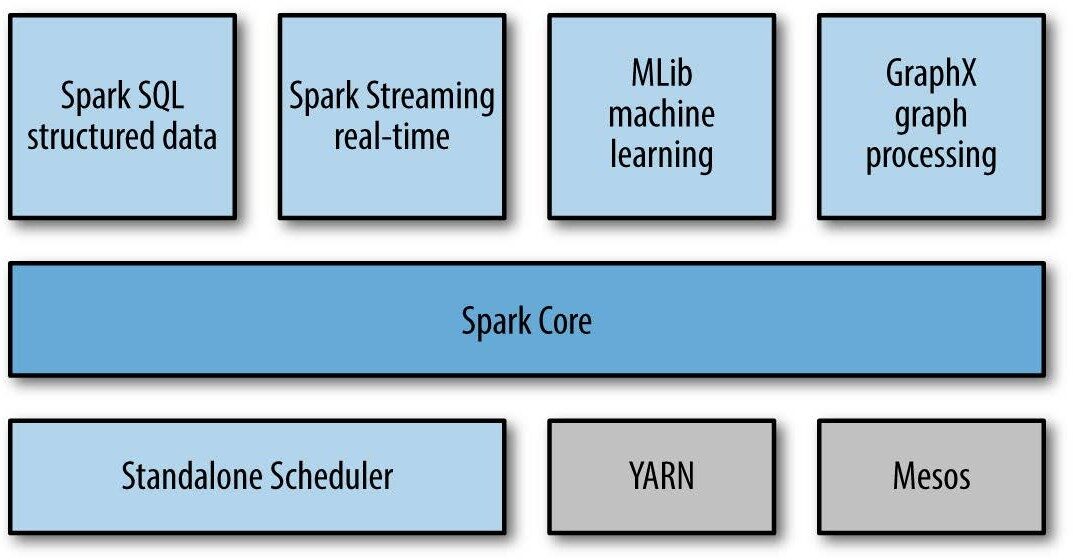
Spark Streaming a un architecture de micro-lots comme suit:
-
traite la transmission comme une série de lots de données
-
De nouveaux lots sont créés à intervalles réguliers.
-
la taille des intervalles de temps est appelée lot intervalle
-
l’intervalle de lot est généralement entre 500 ms et plusieurs secondes
la valeur de réduction de chaque fenêtre est calculée de manière incrémentielle.
Séquence discrétisée (DStream)
Courant discrétisé O DStream est l’abstraction de base fournie par Spark Streaming. Représente un flux continu de données, soit le flux de données d’entrée reçu de la source, soit le flux de données traitées généré par la transformation du flux d’entrée. Intérieurement, un DStream est représenté par une série continue de RDD, qui est l’abstraction de Spark d’un jeu de données distribué et immuable (regarder Guide de programmation Spark pour plus de détails). chaque rdd d’un dstream contient des données d’une certaine plage.
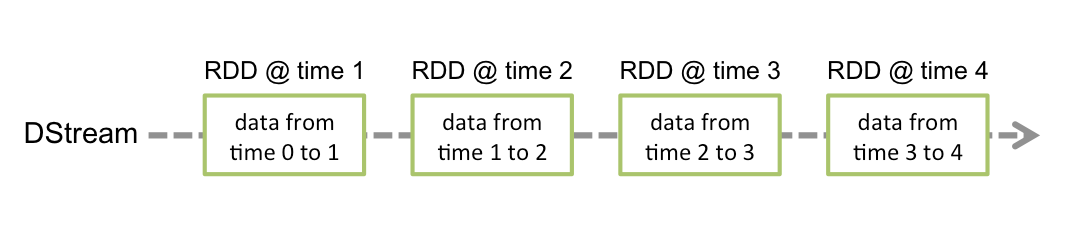
- Les transformations RDD sont calculées par le moteur Spark
-
Les opérations DStream masquent la plupart de ces détails
-
Toute opération appliquée dans un DStream entraîne des opérations sur les RDD sous-jacents.
-
la valeur de réduction de chaque fenêtre est calculée de manière incrémentielle.
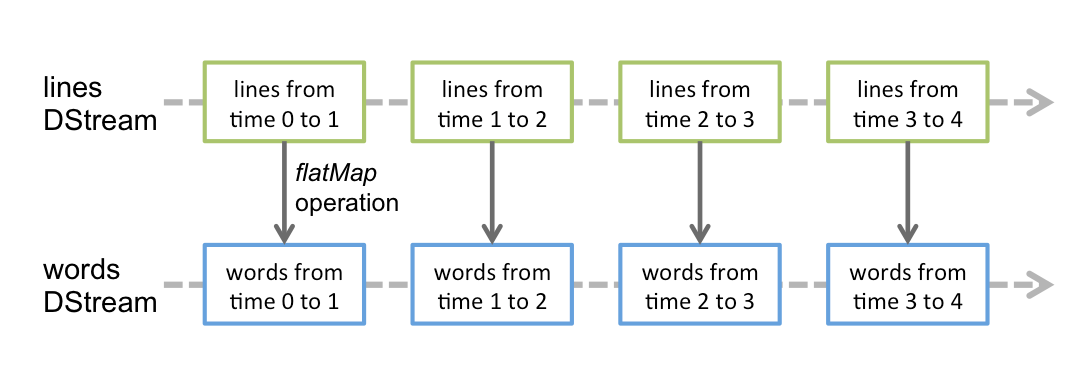
Diffusion Spark: contexte de transmission
C’est le principal point d’entrée de la fonctionnalité Spark Streaming. Fournit les méthodes utilisées pour créer DStreamà partir de plusieurs sources d’entrée. Streaming Spark peut être créé en fournissant une URL principale Spark et un nom d’application, ou à partir d’une configuration org.apache.spark.SparkConf, ou à partir d’un org.apache.spark.SparkContext existant. Le SparkContext associé est accessible à l’aide de context.sparkContext.
Après avoir créé et transformé DStreams, l’informatique de transmission peut être démarrée et arrêtée à l’aide de context.start() Oui, respectivement. context.awaitTermination() permet au thread actuel d’attendre la fin du contexte par stop() ou par une exception.
Pour exécuter une application SparkStreaming, nous devons définir StreamingContext. SparkContext est spécialisé dans les applications de streaming.
Le contexte de transmission en Java peut être défini comme suit:
JavaStreamingContext ssc = nouveau JavaStreamingContext(sparkConf, batchInterval);
où:
-
Maestro est une URL de cluster Spark, Mesos o FILYARN es un gestor de paquetes para JavaScript que permite la instalación y gestión eficiente de dependencias en proyectos de desarrollo. Desarrollado por Facebook, se caracteriza por su rapidez y seguridad en comparación con otros gestores. YARN utiliza un sistema de caché para optimizar las instalaciones y proporciona un archivo de bloqueo para garantizar la consistencia de las versiones de las dependencias en diferentes entornos de desarrollo....; pour exécuter votre code en mode local, utilisation « local[K]« Où K> = 2 représente le parallélisme
-
nom de l’application est le nom de votre application
-
gamme de lots intervalle de temps (en secondes) de chaque lot
Une fois construit, offrir deux types d’opérations:
Certains exemples sont: carte (), filtre () et reduceByKey ()
-
-
transformations avec état: utilise les données des lots précédents pour calculer les résultats du lot actuel. Inclure des fenêtres coulissantes, suivi de l’état au fil du temps, etc.
-
Notez qu’un contexte de streaming ne peut être démarré qu’une seule fois et doit être démarré après avoir configuré tous les DStreams et les opérations de sortie.
Sources de données de base
Les sources de données de base de diffusion en continu d’étincelles sont répertoriées ci-dessous:
- Flux de fichiers: Utilisé pour lire des données de fichier sur n’importe quel système de fichiers prenant en charge l’API HDFS (c'est-à-dire, HDFS, S3, NFS, etc.), vous pouvez créer un DStream en tant que:
... = streamingContext.fileStream<...>(annuaire);
- Flux basés sur des récepteurs personnalisés: Les DStreams peuvent être créés avec des flux de données reçus via des récepteurs personnalisés, extension de la classe Receiver
... = streamingContext.queueStream(file d’attenteOfRDDs)
- File d’attente RDD en tant que flux: Pour tester une application Spark Streaming avec des données de test, vous pouvez également créer un flux dstream basé sur une file d’attente rdd, à l'aide de
... = streamingContext.queueStream(file d’attenteOfRDDs)
la plupart des transformations ont la même syntaxe que celle appliquée aux rdds
-
Transformation
Sens
Carte (func)
Renvoie un nouveau DStream en passant chaque élément du DStream source via une fonction func.
flatMap (func)
Semblable à une carte, mais chaque élément d’entrée peut être affecté à 0 ou plusieurs éléments de sortie.
filtre (func)
Renvoyer un nouveau DStream en sélectionnant uniquement les enregistrements du DStream source dans lequel func renvoie true.
syndicat (autreStream)
Renvoie un nouveau DStream qui contient la jointure des éléments source DStream et otherDStream.
unir (un autre flux)
Lorsque deux paires de DStreams sont appelées (K, V) Oui (K, W), renvoie un nouveau DStream de (K, (V, W)) paires avec toutes les paires d’éléments pour chaque clé.
Exemple: nombre de mots
SparkConf sparkConf = nouveau SparkConf()
.setMaster("local[2]").setAppName("WordCount (Compte Word)");
JavaStreamingContext ssc = ...
JavaReceiverInputDStream<Chaîne de caractères> lignes = ssc.socketTextStream( ... );
JavaDStream<Chaîne de caractères> mots = lignes.flatMap(...);
JavaPairdStream<Chaîne de caractères, Entier> wordCounts = words
.mapToPair(s -> nouveau Tuple2<>(s, 1))
.reduceByKey((i1, i2) -> i1 + i2);
wordCounts.print();
Diffusion Spark: Fenêtre
La fonction de fenêtre la plus simple est une fenêtre, qui vous permet de créer un nouveau DStream, calculado aplicando los paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... de ventana al antiguo DStream. vous pouvez utiliser n’importe laquelle des opérations dstream dans le nouveau flux, pour que vous obteniez toute la flexibilité que vous voulez.
Les calculs dans les fenêtres vous permettent d’appliquer des transformations sur une fenêtre de données coulissante. Toute opération de fenêtre doit spécifier deux paramètres:
- fenêtre long
- La durée de la fenêtre en secondes.
- coulissant intervalle
- Intervalle auquel l’opération de fenêtre est effectuée en secondes.
- ces paramètres doivent être des multiples de l’intervalle de lot.
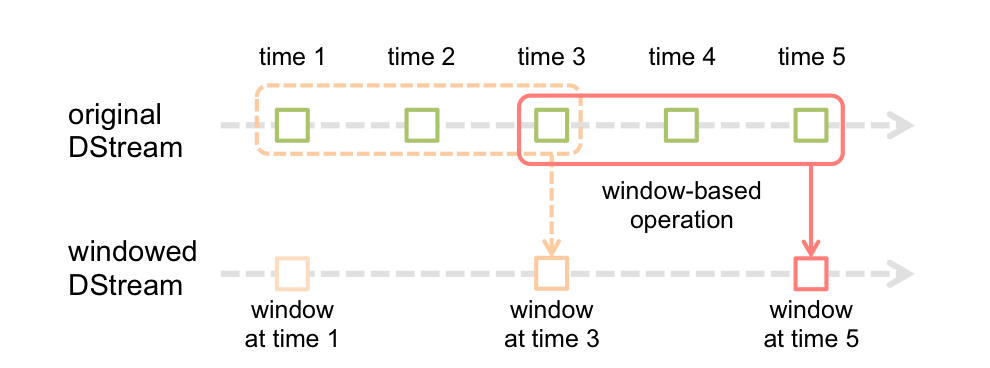
la fenêtre(fenêtreLongueur, slideInterval)
Renvoie un nouveau DStream calculé en fonction des lots dans la fenêtre.
...
JavaStreamingContext ssc = ...
JavaReceiverInputDStream<Chaîne de caractères> lignes = ...
JavaDStream<Chaîne de caractères> linesInWindow =
lines.window(WINDOW_SIZE, SLIDING_INTERVAL);
JavaPairdStream<Chaîne de caractères, Entier> wordCounts = lignesInWindow.flatMap(SPLIT_LINE)
.mapToPair(s -> nouveau Tuple2<>(s, 1))
.reduceByKey((i1, i2) -> i1 + i2);
- reduceByWindow (func, InvFunc, fenêtreLongueur, slideInterval)
- Renvoie une nouvelle séquence d’un seul élément, créé en ajoutant des éléments dans la séquence au cours d’un intervalle de glissement à l’aide de func (qui doit être associatif).
- la valeur de réduction de chaque fenêtre est calculée de manière incrémentielle.
- reduceByKeyAndWindow (func, InvFunc, fenêtreLongueur, slideInterval)
- Lors de l’appel d’un DStream de (K, V) Paires, renvoie un nouveau DStream de (K, V) paires où les valeurs de chaque touche sont ajoutées à l’aide de la fonction de réduction donnée func sur des lots dans une fenêtre coulissante.
Pour effectuer ces transformations, nous devons définir un répertoire de points de contrôle
Basé sur une fenêtre: nombre de mots
...
JavaPairdStream<Chaîne de caractères, Entier> wordCountPairs = ssc.socketTextStream(...)
.flatMap(x -> Arrays.asList(ESPACE.split(X)).itérateur())
.mapToPair(s -> nouveau Tuple2<>(s, 1));
JavaPairdStream<Chaîne de caractères, Entier> wordCounts = wordCountPairs
.reduceByKeyAndWindow((i1, i2) -> i1 + i2, WINDOW_SIZE, SLIDING_INTERVAL);
wordCounts.print();
wordCounts.foreachRDD(nouveau SaveAsLocalFile());
Un (plus efficace) basé sur des fenêtres: nombre de mots
Dans une version plus efficace, la valeur de réduction de chaque fenêtre est calculée de manière incrémentielle.
Notez que les points de contrôle doivent être activés pour utiliser cette opération.
... ssc.checkpoint(LOCAL_CHECKPOINT_DIR); ... JavaPairdStream<Chaîne de caractères, Entier> wordCounts = wordCountPairs.reduceByKeyAndWindow( (i1, i2) -> i1 + i2, (i1, i2) -> i1 - i2, WINDOW_SIZE, SLIDING_INTERVAL);
Diffusion Spark: opérations de sortie
Las operaciones de salida permiten que los datos de DStream se envíen a sistemas externos como una base de donnéesUne base de données est un ensemble organisé d’informations qui vous permet de stocker, Gérez et récupérez efficacement les données. Utilisé dans diverses applications, Des systèmes d’entreprise aux plateformes en ligne, Les bases de données peuvent être relationnelles ou non relationnelles. Une bonne conception est essentielle pour optimiser les performances et garantir l’intégrité de l’information, facilitant ainsi la prise de décision éclairée dans différents contextes.... o un sistema de archivos
-
Opération de sortie
Sens
impression()
Imprime los primeros diez elementos de cada lote de datos en un DStream en el nœudNodo est une plateforme digitale qui facilite la mise en relation entre les professionnels et les entreprises à la recherche de talents. Grâce à un système intuitif, Permet aux utilisateurs de créer des profils, Partager des expériences et accéder à des opportunités d’emploi. L’accent mis sur la collaboration et le réseautage fait de Nodo un outil précieux pour ceux qui souhaitent élargir leur réseau professionnel et trouver des projets qui correspondent à leurs compétences et à leurs objectifs.... del controlador que ejecuta la aplicación.
saveAsTextFiles (préfixe, [suffixe])
enregistrer le contenu de ce flux sous forme de fichiers texte. Le nom de fichier dans chaque plage de lots est généré en fonction du préfixe.
saveAsHadoopFiles (préfixe, [suffixe])
enregistrer le contenu de ce dstream en tant que fichiers hadoop.
saveAsObjectFiles (préfixe, [suffixe])
enregistrer le contenu de ce dstream en tant que séquencesfichiers d’objets Java sérialisés.
foreachRDD (func)
Opérateur de sortie générique qui applique une fonction, func, à chaque RDD généré à partir de la séquence.
Références en ligne
• Spark Documentation
• Spark Documentation
conclusion
Il devrait être clair que Spark Streaming présente un moyen puissant d’écrire des applications de streaming.. Prendre un travail par lots que vous exécutez déjà et le transformer en un travail de transmission presque inchangé est simple et extrêmement utile du point de vue de l’ingénierie si vous avez besoin que ce travail interagisse étroitement avec le reste de votre application de traitement de données..
Je vous recommande de consulter les ressources d'ingénierie de données suivantes pour améliorer vos connaissances:
Si vous avez aimé l’article, laisser un commentaire dans la section commentaires ci-dessous.





