Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
La première étape d'un projet de science des données est de résumer, décrire et visualiser les données. Essayez de connaître les différents aspects des données et leurs attributs. Les meilleurs modèles sont créés par ceux qui comprennent leurs données.
Explorer les caractéristiques et les attributs des données à l'aide de statistiques descriptives. Les informations et le résumé numérique que vous obtenez des statistiques descriptives vous aident à mieux comprendre ou à être en mesure de gérer les données plus efficacement pour les tâches d'apprentissage automatique..
Les statistiques descriptives sont le processus par défaut dans l'analyse des données. L'analyse exploratoire des données (AED) pas complet sans analyse statistique descriptive.
Ensuite, dans cet article, Je vais expliquer les attributs de l'ensemble de données à l'aide de statistiques descriptives. Il est divisé en deux parties: MesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... de puntos de datos centrales y Medida de dispersión. Avant de commencer notre analyse, nous devons terminer le processus de collecte et de nettoyage des données.
Collecte et nettoyage des données
Nous collecterons des données de ici. Je n'utiliserai que les données de test pour l'analyse. Puede combinar datos de prueba y de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... para su análisis. Voici du code pour le processus de nettoyage des données des données du train.
Supprimer du code
- Les colonnes Item_Weight et Outlet_Size ont des valeurs nulles. Ce sont les options:
-
- supprimer les lignes contenant des valeurs nulles
- supprimer les colonnes contenant des valeurs nulles
- ou remplacer les valeurs nulles.
- Les premières 2 les options sont réalisables lorsque les données ont des lignes en millions ou que le nombre de valeurs est petit. Ensuite, Je vais choisir la troisième option pour résoudre le problème de la valeur nulle.
- Premier, trouver le Item_Identifier et son Item_Weight correspondant. Puis remplacez ce qui manque / null dans Item_Weight avec le Item_weight connu de l'item_identifier respectif.
- Comme nous savons, la visibilité des articles dans un magasin peut être proche de zéro mais pas nulle. Ensuite, Nous considérons 0 comme valeur nulle et nous suivons l'étape précédente pour Item_Visibility.
- Outlet_Size n'est pas très important dans notre analyse et prédiction des modèles. Ensuite, je laisse tomber cette colonne.
- Remplacez LF et reg dans la colonne Item_fat_content par Low Fat et Regular Fat.
- Calculez l'âge des magasins et enregistrez ces valeurs dans la colonne Outlet_years et déposez la colonne Outlet_Establishment_year.
Commençons par l'analyse des données des statistiques descriptives.
La mesure du point de données central
Trouver le centre de données numérique et catégoriel en utilisant la moyenne, la médianLa médiane est une mesure statistique qui représente la valeur centrale d’un ensemble de données ordonnées. Pour le calculer, Les données sont organisées de la plus basse à la plus élevée et le numéro au milieu est identifié. S’il y a un nombre pair d’observations, La moyenne des deux valeurs fondamentales est calculée. Cet indicateur est particulièrement utile dans les distributions asymétriques, puisqu’il n’est pas affecté par les valeurs extrêmes.... y la moda se conoce como Medida del punto de datos central. Calcul des valeurs centrales des données de la colonne au moyen, la médiane et le mode sont différents l'un de l'autre.
Bien, ensuite, calculons la moyenne, la médiane, le nombre et le mode des attributs de l'ensemble de données à l'aide de python.
- Raconter
Le comptage n'aide pas directement à trouver le centre des attributs de l'ensemble de données. Mais il est utilisé dans le calcul de la moyenne, médiane et mode. Nous calculons le nombre total dans chaque catégorie des variables catégorielles. Calcule également le nombre total de données de colonnes numériques.
Supprimer du code.
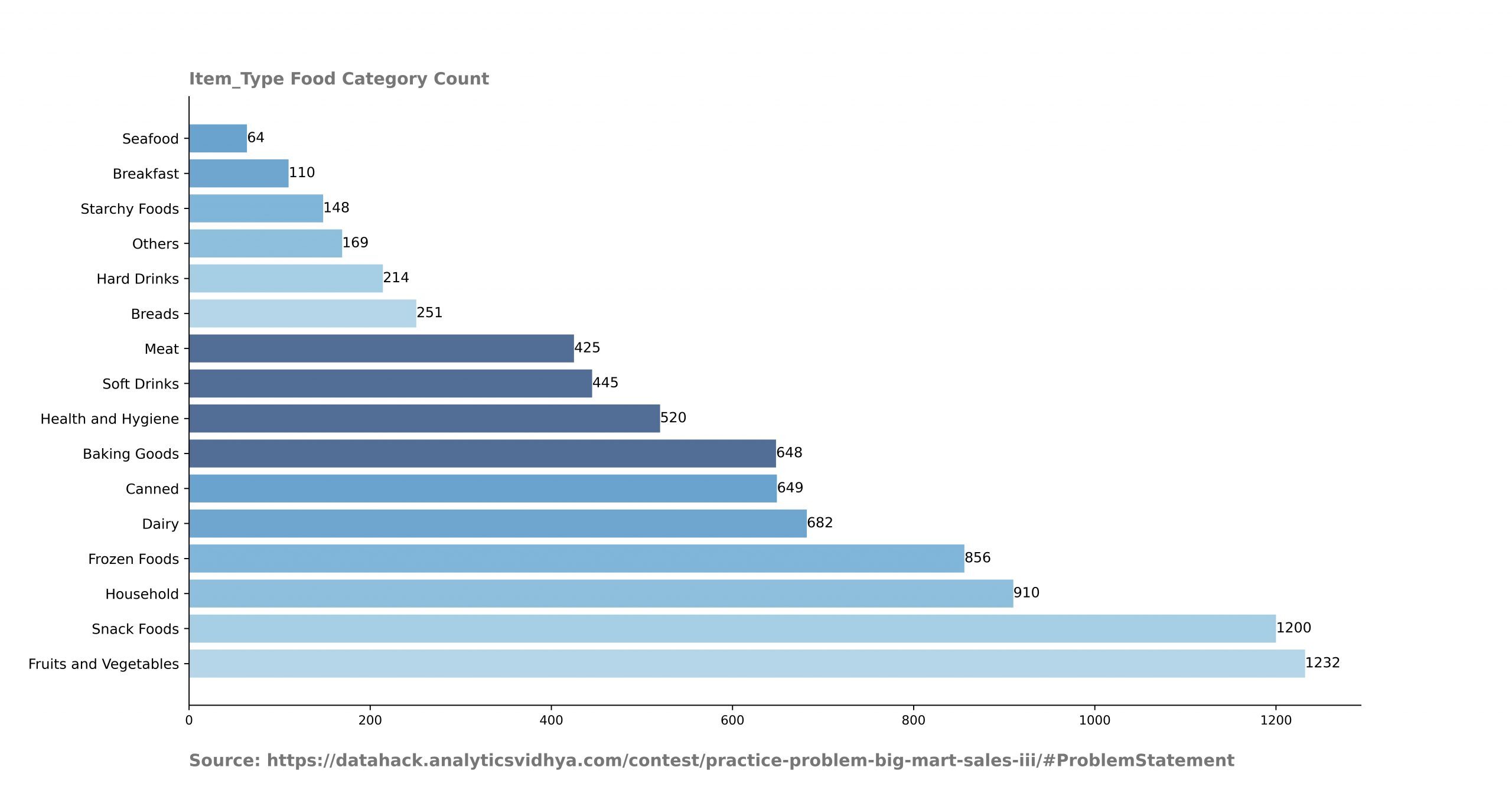
- Parcourez les colonnes catégorielles pour tracer la catégorie et son nombre.
Analyse de sortie.
- Ces décomptes vous aident à savoir si les données sont équilibrées ou non. De ce graphique, Je peux dire que les rangs de la catégorie des fruits et légumes sont bien plus que la catégorie des fruits de mer.
- On peut aussi supposer que les ventes dans la catégorie des fruits et légumes sont beaucoup plus importantes que dans la catégorie des fruits de mer..
-
Vouloir dire
La somme des valeurs présentes dans la colonne divisée par le total des lignes de cette colonne est appelée moyenne. Aussi connu sous le nom de moyenne.
Utilisation train.moyen () pour calculer la valeur moyenne des colonnes numériques de l'ensemble de données de train.
Voici du code pour les colonnes catégorielles de l'ensemble de données des trains.
imprimer(former[['Item_Outlet_Sales','Type_de_sortie']].par groupe(['Type_de_sortie']).agglutiné({'Item_Outlet_Sales':'moyenne'}))Analyse de sortie
- L'âge moyen de départ est 15 ans.
- Les ventes moyennes des points de vente sont 2100.
- La catégorie de type supermarché 3 Outlet_Type's a beaucoup plus de ventes que la catégorie épicerie.
- On peut aussi supposer que la catégorie supermarché est plus populaire que la catégorie épicerie..
-
Médian
La valeur centrale d'un attribut est appelée la médiane. Comment calculons-nous la valeur médiane? Premier, trier les données des colonnes par ordre croissant ou décroissant. Trouvez ensuite le nombre total de lignes, puis divisez-le par 2.
Cette valeur de sortie est la médiane de cette colonne.
La valeur médiane divise les points de données en deux parties. Cela signifie que le 50% des points de données sont présents au-dessus de la médiane et de la 50% sous.
Généralement, les valeurs médianes et moyennes sont différentes pour les mêmes données.
La médiane n'est pas affectée par les valeurs aberrantes. En raison de valeurs aberrantes, la différence entre les valeurs moyennes et médianes augmente.
Utilisation train.médian () pour calculer la valeur moyenne des colonnes numériques de l'ensemble de données de train.
Voici du code pour les colonnes catégorielles de l'ensemble de données des trains.
imprimer(former[['Item_Outlet_Sales','Type_de_sortie']].par groupe(['Type_de_sortie']).agglutiné({'Item_Outlet_Sales':'médian'}))Analyse de sortie
- La plupart des observations sont les mêmes que la valeur moyenne.
- La différence entre la valeur moyenne et la valeur médiane est due aux valeurs aberrantes. Vous pouvez également observer cette différence dans les variables catégorielles.
- Façon
Le mode est ce point de données dont le nombre est le maximum dans une colonne. Il n'y a qu'une seule valeur moyenne et médiane pour chaque colonne. Mais les attributs peuvent avoir plusieurs valeurs de mode. Utilisation train.mode () pour calculer la valeur moyenne des colonnes numériques de l'ensemble de données de train. Voici du code pour les colonnes catégorielles de l'ensemble de données de train.imprimer(former[['Item_Outlet_Sales', 'Type_de_sortie', 'Outlet_Identifier', 'Identifiant_Élément']].par groupe(['Type_de_sortie']).agglutiné(lambda x:x.value_counts().indice[0]))
Analyse de sortie
- Outlet_Type a une valeur de mode. Type de supermarché 1. La catégorie de type supermarché 1 La valeur de l'article ou du mode le plus vendu est FDZ15.
- Item_Identifier FDH50 est l'article le plus vendu dans la catégorie Outlet_Type.
Mesures de dispersion
Une mesure de la dispersion explique la diversité des valeurs d'attribut dans l'ensemble de données. Aussi connu comme une mesure de propagation. De cette statistique, savoir comment et pourquoi les données se propagent d'un point à un autre.
Ce sont les statistiques qui entrent dans la mesure de la dispersion.
- Distance
- Centiles ou quartiles
- Écart-type
- Différence
- Obliquité
-
Distance
La différence entre la valeur maximale et la valeur minimale dans une colonne est appelée plage.
Voici un code pour calculer la plage.
pour i dans num_col: imprimer(F"Colonne: {je} Valeur max: {max(former[je])} Min_Value: {min(former[je])} Varier: {tour(max(former[je]) - min(former[je]),2)}")Vous pouvez également calculer le rang des colonnes catégorielles. Voici un code pour connaître les valeurs minimales et maximales dans chaque catégorie de sortie.
Analyse de sortie
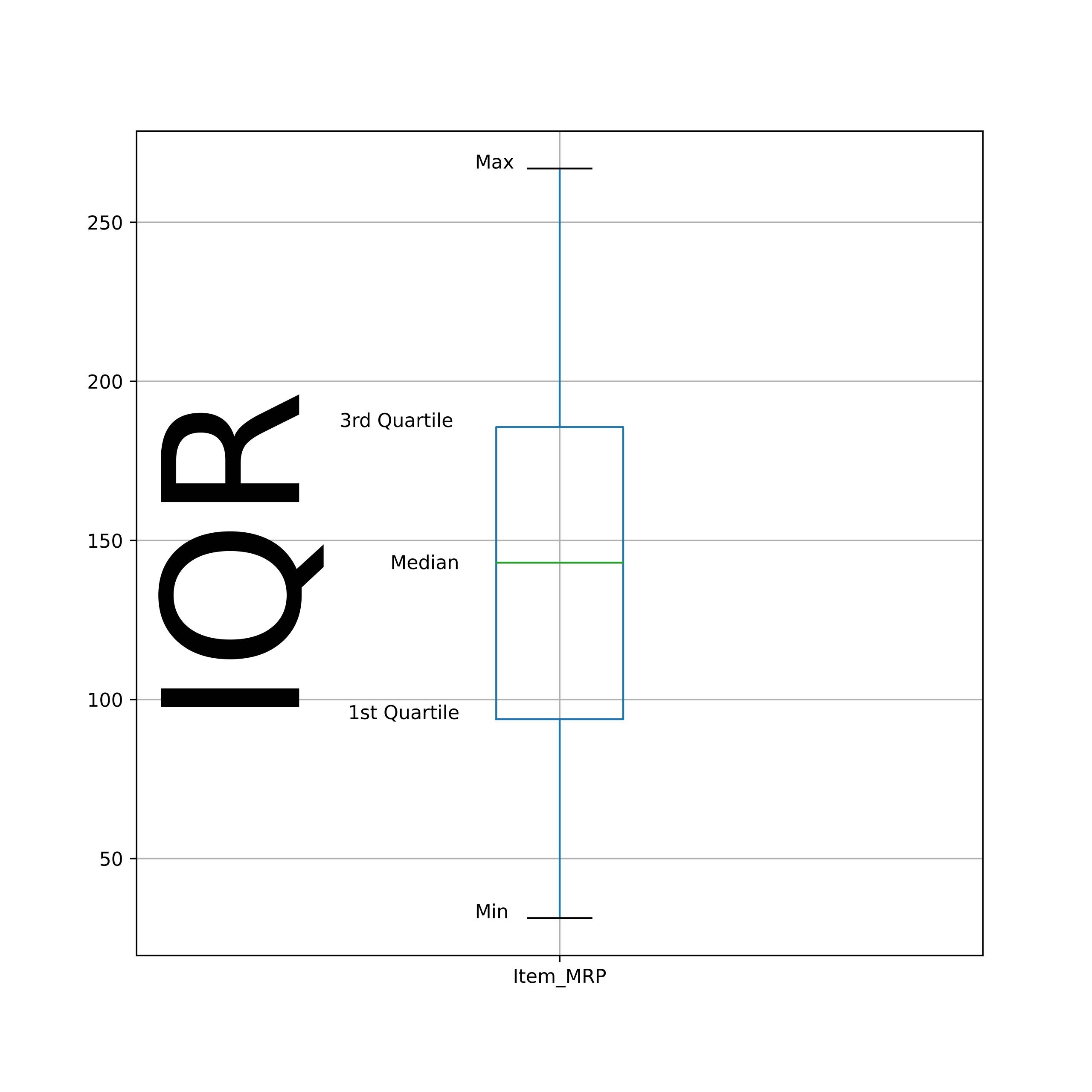
- La plage de Item_MRP et Item_Outlet_sales est élevée et peut nécessiter une transformation.
- Il existe une grande variation dans Item_MRP dans la catégorie de type supermarché 3.
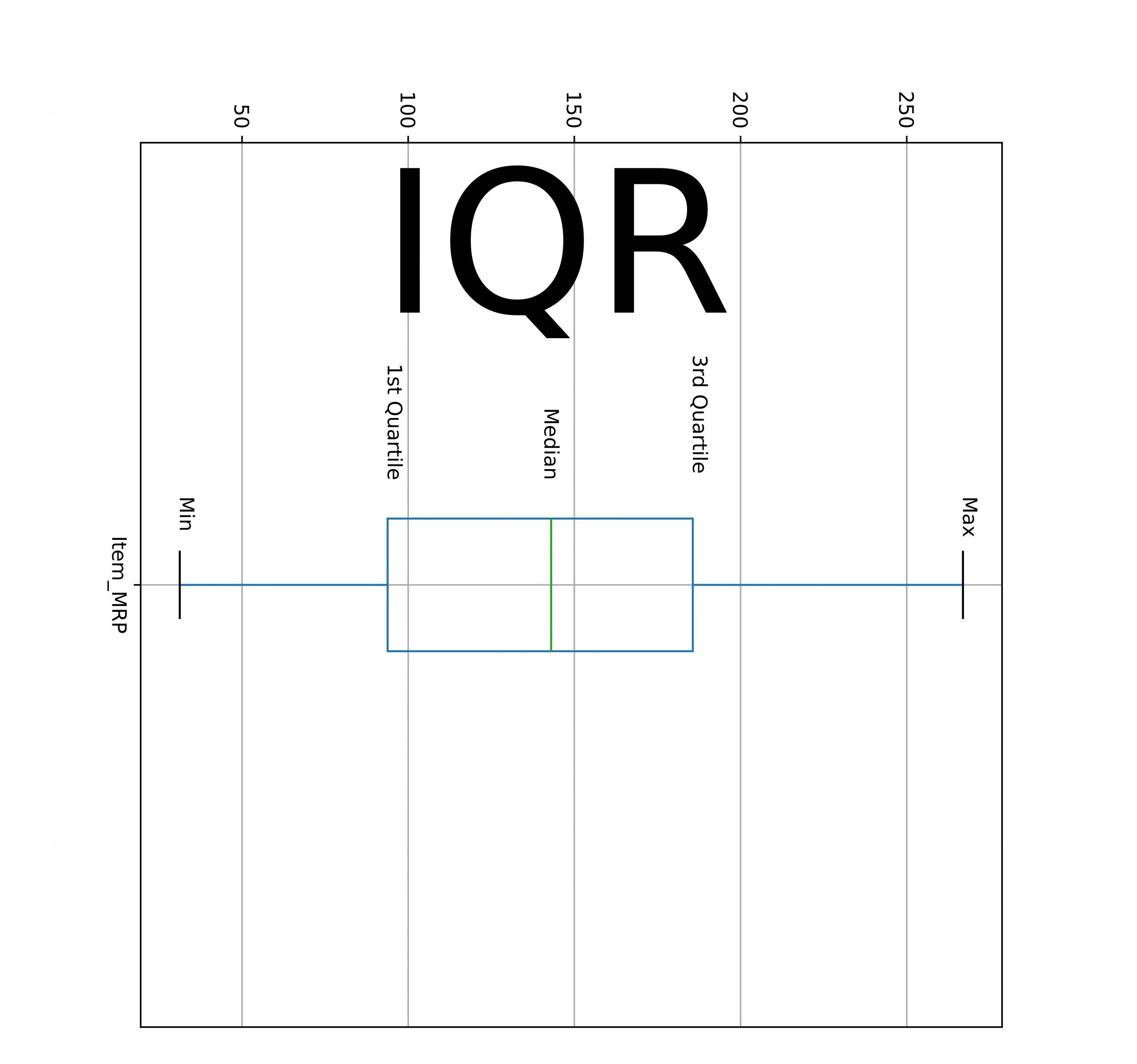
- Centiles ou quartilesOn peut décrire la distribution des valeurs des colonnes en calculant le résumé de plusieurs centiles. La médiane est également connue sous le nom de percentile 50 des données. Voici un autre centile.
- La valeur minimale est égale au centile 0.
- La valeur maximale est égale au centile 100.
- Le premier quartile est égal au centile 25.
- Le troisième quartile est égal au centile 75.
Voici un code pour calculer les quartiles.
La différence entre 3rd et le 1S t Le quartile est aussi appelé interquartile (IQR). En outre, les points de données maximum sont inclus dans l'IQR.

-
Écart-type
La valeur de l'écart type nous indique de combien tous les points de données s'écartent de la valeur moyenne. L'écart type est affecté par les valeurs aberrantes car il utilise la moyenne pour son calcul.
Voici un code pour calculer l'écart type.
pour i dans num_col: imprimer(je , tour(former[je].std(),2))Les pandas ont également un raccourci pour calculer toutes les valeurs statistiques ci-dessus.
Former.décrire()
- DifférenceLa variance est le carré de l'écart type. En cas de valeurs aberrantes, la valeur de la variance devient grande et perceptible. Donc, est également affecté par les valeurs aberrantes. Voici un code pour calculer la variance
pour i dans num_col: imprimer(je , tour(former[je].où(),2))Analyse de sortie.
- Les colonnes Item_MRP et Item_Outlet_sales présentent un écart important en raison des valeurs aberrantes.
-
Obliquité
Idéalement, la distribution des données doit être sous forme gaussienne (courbe en cloche). Mais pratiquement, les formes de données sont asymétriques ou asymétriques. C'est ce qu'on appelle l'asymétrie dans les données..
Vous pouvez calculer l'asymétrie des données du train en utilisant train.skew (). La valeur de biais peut être négative (gauche) le positif (droite). Sa valeur doit être proche de zéro.
Remarques finales
Ce sont les statistiques vers lesquelles nous nous tournons lorsque nous effectuons une analyse exploratoire des données sur l'ensemble de données. Vous devez faire attention aux valeurs générées par ces statistiques et demander pourquoi ce nombre. Ces statistiques nous aident à déterminer les attributs pour la transformation des données et la suppression des variables du post-traitement..
La bibliothèque Pandas a de très bonnes fonctions qui vous aident à obtenir des valeurs statistiques descriptives en une seule ligne de code.





