Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
La sélection des fonctionnalités est le processus de sélection des fonctionnalités pertinentes pour un modèle d'apprentissage automatique. Cela signifie qu'il sélectionne uniquement les attributs qui ont un effet significatif sur la sortie du modèle.
Considérez le cas lorsque vous allez au grand magasin pour acheter des articles d'épicerie. Un produit contient beaucoup d'informations, c'est-à-dire, produit, Catégorie, date d'échéance, MRP, ingrédients et détails de fabrication. Toutes ces informations sont les caractéristiques du produit. Normalement, vérifier la marque, MRP et date d'expiration avant d'acheter un produit. Cependant, la section ingrédients et fabrication ne vous concerne pas. Donc, la marque, el mrp, la date de péremption sont des caractéristiques pertinentes et l'ingrédient, les détails de fabrication ne sont pas pertinents. Voici comment se fait la sélection des fonctionnalités.
Dans le monde réel, un jeu de données peut avoir des milliers de fonctionnalités et il peut y avoir des chances que certaines fonctionnalités soient redondantes, certains peuvent être corrélés et certains peuvent ne pas être pertinents pour le modèle. À ce stade, si vous utilisez toutes les fonctions, il faudra beaucoup de temps pour former le modèle et la précision du modèle sera réduite. Donc, la sélection des caractéristiques devient importante dans la construction de modèles. Il existe de nombreuses autres façons de sélectionner des fonctionnalités, comme élimination des caractéristiques récursives, algorithmes génétiques, arbres de décision. Cependant, Je vais vous dire la méthode de filtrage la plus basique et manuelle à l'aide de tests statistiques.
Maintenant que vous avez une compréhension de base de la sélection de fonctionnalités, nous verrons comment mettre en œuvre divers tests statistiques sur les données pour sélectionner des caractéristiques importantes.
Cibler
L'objectif principal de ce blog est de comprendre les tests statistiques et leur implémentation en données réelles en Python, qui aidera dans la sélection des fonctionnalités.
Terminologies
Avant d'aborder les types de tests statistiques et leur mise en œuvre, il est nécessaire de comprendre le sens de certaines terminologies.
Tests d'hypothèses
Le test d'hypothèse dans les statistiques est une méthode de test des résultats d'expériences ou d'enquêtes pour voir s'il a des résultats significatifs.. Utile lorsque vous souhaitez déduire une population sur la base d'un échantillon ou d'une corrélation entre deux échantillons ou plus.
Hypothèse nulle
Cette hypothèse établit qu'il n'y a pas de différence significative entre l'échantillon et la population ou entre les différentes populations.. Il est noté H0.
Pas. On suppose que la moyenne de 2 les échantillons sont les mêmes.
Hypothèse alternative
L'énoncé contraire à l'hypothèse nulle est inclus dans l'hypothèse alternative. Il est noté H1.
Pas. On suppose que la moyenne des 2 les échantillons sont inégaux.
valeur critique
C'est un point sur l'échelle de la statistique de test au-delà duquel l'hypothèse nulle est rejetée.. Plus la valeur critique est élevée, plus la probabilité que 2 les échantillons appartiennent à la même distribution. La valeur critique pour tout test peut
valeur p
p-valeur signifie 'valeur de probabilité'; indique la probabilité qu'un résultat se produise par hasard. Essentiellement, la valeur p est utilisée dans les tests d'hypothèse pour vous aider à soutenir ou à rejeter l'hypothèse nulle. Plus la valeur p est petite, plus les preuves sont solides pour rejeter l'hypothèse nulle.
Degré de liberté
Le degré de liberté est le nombre de variables indépendantes. Ce concept est utilisé pour calculer la statistique t et la statistique du chi carré.
Vous pouvez vous référer à statistiqueswho.com pour plus d'informations sur ces terminologies.
Tests statistiques
Un test statistique est un moyen de déterminer si la variable aléatoire suit l'hypothèse nulle ou l'hypothèse alternative. Essentiellement, indique si l'échantillon et la population ou deux échantillons ou plus présentent des différences significatives. Vous pouvez utiliser diverses statistiques descriptives comme moyenne, médian, manière, plage ou écart type à cet effet. Cependant, on utilise généralement la moyenne. Le test statistique vous donne un nombre qui est ensuite comparé à la valeur p. Si sa valeur est supérieure à la valeur p, accepter l'hypothèse nulle, au contraire, elle rejette.
La procédure pour mettre en œuvre chaque test statistique sera la suivante:
- Nous calculons la valeur statistique en utilisant la formule mathématique
- Ensuite, nous calculons la valeur critique à l'aide de tableaux statistiques.
- Avec l'aide de la valeur critique, nous calculons la p-valeur
- Si la valeur p> 0.05 on accepte l'hypothèse nulle, sinon on le rejette
Maintenant que vous comprenez la sélection de fonctionnalités et les tests statistiques, on peut s'orienter vers la mise en place de différents tests statistiques ainsi que leur signification. Avant que, je vais vous montrer l'ensemble de données et cet ensemble de données sera utilisé pour tous les tests.
Base de données
L'ensemble de données que j'utiliserai est un ensemble de données de prédiction de prêt qui a été tiré du concours d'analyse Vidhya. Vous pouvez également participer au concours et télécharger le jeu de données. ici.
J'ai d'abord importé tous les modules python nécessaires et l'ensemble de données.
importer numpy en tant que np
importer des pandas au format pd
importer seaborn en tant que qn
de numpy import sqrt, abdos, tour
importer scipy.stats en tant que statistiques
à partir de la norme d'importation scipy.stats
df=pd.read_csv('prêt.csv')
df.head()

Il y a de nombreuses caractéristiques dans l'ensemble de données, comme genre, personnes à charge, éducation, revenu du demandeur, montant du prêt, histoire de credit. Nous utiliserons ces fonctionnalités et vérifierons si un effet de fonctionnalité affecte d'autres fonctionnalités à l'aide de divers tests., c'est-à-dire, essai Z, test de corrélation, Test ANOVA et test du Chi carré.
essai Z
Un test Z est utilisé pour comparer la moyenne de deux échantillons donnés et déduire s'ils appartiennent ou non à la même distribution.. Nous n'implémentons pas le test Z lorsque la taille de l'échantillon est inférieure à 30.
Un test Z peut être un test Z à un échantillon ou un test Z à deux échantillons.
L'échantillon unique tester t détermine si la moyenne de l'échantillon est statistiquement différente d'une moyenne de population connue ou hypothétique. Le test Z à deux échantillons compare 2 variables indépendantes.
Nous allons implémenter un test Z à deux échantillons.
La statistique Z est notée
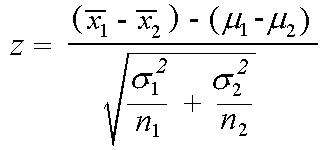
Mise en œuvre
Veuillez noter que nous mettrons en œuvre 2 échantillons de tests z où une variable sera catégorique avec deux catégories et l'autre variable sera continue pour appliquer le test z.
Ici, nous utiliserons le Genre variable catégorielle et Revenu du demandeur Variable continue. Le genre a 2 groupes: masculin et féminin. L'hypothèse sera donc:
Hypothèse nulle: Il n'y a pas de différence significative entre le revenu moyen des hommes et des femmes.
Hypothèse alternative: il y a une différence significative entre le revenu moyen des hommes et des femmes.
Code
M_mean=df.loc[df['Genre']=='Homme',« Revenu du demandeur »].moyenne() F_mean=df.loc[df['Genre']=='Femme',« Revenu du demandeur »].moyenne() M_std=df.loc[df['Genre']=='Homme',« Revenu du demandeur »].std() F_std=df.loc[df['Genre']=='Femme',« Revenu du demandeur »].std() no_of_M=df.loc[df['Genre']=='Homme',« Revenu du demandeur »].compter() no_of_F=df.loc[df['Genre']=='Femme',« Revenu du demandeur »].compter()
Le code ci-dessus calcule le revenu moyen des candidats masculins, le revenu moyen des candidates, son écart type et le nombre d'échantillons d'hommes et de femmes.
deuxSampZ La fonction calculera la statistique z et la valeur p sans passer par les paramètres d'entrée précédemment calculés.
def deuxSampZ(X1, X2, mudiff, sd1, sd2, n1, n2):
pooledSE = sqrt(sd1**2/n1 + sd2**2/n2)
z = ((X1 - X2) - mudiff)/SE mutualisé
pval = 2*(1 - norme.cdf(abdos(Avec)))
retour en rond(Avec,3), pval
z,p= deuxSampZ(M_moyenne,F_moyenne,0,M_std,F_std,no_of_M,no_of_F)
imprimer('Z'=z,'p'=p)
Z = 1.828
p = 0.06759726635832197
si p<0.05:
imprimer("nous rejetons l'hypothèse nulle")
autre:
imprimer("on accepte l'hypothèse nulle")
on accepte l'hypothèse nulle
Étant donné que la valeur p est supérieure à 0.5 on accepte l'hypothèse nulle. Pourtant, nous concluons qu'il n'y a pas de différence significative entre les revenus des hommes et des femmes.
Tester T
Un test t est également utilisé pour comparer la moyenne de deux échantillons donnés., comme le test Z. Cependant, est mis en œuvre lorsque la taille de l'échantillon est inférieure à 30. Une distribution normale de l'échantillon est supposée. Il peut également s'agir d'un ou deux échantillons. Le degré de liberté est calculé par n-1 où n est le nombre d'échantillons.
Il est désigné par

Mise en œuvre
Il sera implémenté de la même manière que le test Z. La seule condition est que la taille de l'échantillon soit inférieure à 30. Je vous ai montré la mise en œuvre du test Z. À présent, vous pouvez essayer le T-Test.
Test de corrélation
Un test de corrélation est une mesure permettant d'évaluer dans quelle mesure les variables sont associées les unes aux autres.
Notez que les variables doivent être continues pour appliquer le test de corrélation.
Il existe plusieurs méthodes de test de corrélation, c'est-à-dire, covariance, Coefficient de corrélation de Pearson, Coefficient de corrélation de rang de Spearman, etc.
Nous utiliserons le coefficient de corrélation des personnes puisqu'il est indépendant des valeurs des variables.
Coefficient de corrélation de Pearson
Il est utilisé pour mesurer la corrélation linéaire entre 2 variables. Il est désigné par

Google Image
Ses valeurs se situent entre -1 Oui 1.
Si la valeur de r est 0, signifie qu'il n'y a pas de relation entre les variables X et Y.
Si la valeur de r est comprise entre 0 Oui 1, signifie qu'il existe une relation positive entre X et Y, et sa force augmente de 0 une 1. Une relation positive signifie que si la valeur de X augmente, la valeur de Y augmente également.
Si la valeur de r est comprise entre -1 Oui 0, signifie qu'il existe une relation négative entre X et Y, et sa force diminue de -1 une 0. Une relation négative signifie que si la valeur de X augmente, la valeur de Y diminue.
Mise en œuvre
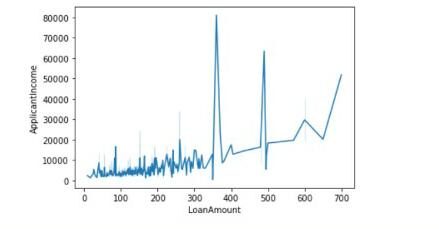
Ici, nous utiliserons deux variables ou caractéristiques continues: Montant du prêt Oui Revenu du demandeur. Nous conclurons s'il existe une relation linéaire entre le montant du prêt et les revenus du demandeur avec la valeur du coefficient de corrélation de Pearson et nous tracerons également le graphique entre eux.
Code
Il y a quelques valeurs manquantes dans la colonne LoanAmount, premier, nous le remplissons avec la valeur moyenne. Puis il calcula la valeur du coefficient de corrélation.
df['Montant du prêt']= df['Montant du prêt'].remplir (df['Montant du prêt'].vouloir dire())
pcc = par exemple corrcoef (df.Revenu du demandeur, df.MontantPrêt)
imprimer (pc)
[[1. 0.56562046] [0.56562046 1. ]]
Les valeurs des diagonales indiquent la corrélation des caractéristiques avec elles-mêmes. 0.56 signifie qu'il existe une certaine corrélation entre les deux caractéristiques.
On peut aussi tracer le graphique comme suit:
sns.lineplot(données=df,x='MontantPrêt',y = 'Revenu du demandeur')
test ANOVA
ANOVA signifie Analyse de la variance. Comme le nom le suggère, utilise la variance comme paramètre pour comparer plusieurs groupes indépendants. L'ANOVA peut être une ANOVA unidirectionnelle ou une ANOVA bidirectionnelle. L'ANOVA à sens unique est appliquée lorsqu'il existe au moins trois groupes indépendants d'une variable. Nous allons implémenter la même chose en Python.
La statistique F peut être calculée par

Mise en œuvre
Ici, nous utiliserons le Personnes à charge variable catégorielle et Revenu du demandeur Variable continue. Les personnes à charge ont 4 groupes: 0,1,2,3+. L'hypothèse sera donc:
Hypothèse nulle: Il n'y a pas de différence significative entre le revenu moyen entre les différents groupes de personnes à charge.
Hypothèse alternative: il existe une différence significative entre le revenu moyen entre les différents groupes de personnes à charge.
Code
Premier, nous gérons les valeurs manquantes dans la fonction Dépendants.
df[« personnes à charge »].est nul().somme()
df[« personnes à charge »]=df[« personnes à charge »].remplir('0')
Après cela, nous créons une base de données avec les caractéristiques Dépendants et Revenu Candidat. Alors, avec l'aide de la bibliothèque scipy.stats, nous calculons la statistique F et la valeur p.
df_anova = df[['Facture totale','journée']]
grps = pd.unique(df.day.values)
d_données = {grp:df_anova['Facture totale'][df_anova.day == grp] pour grp en grps}
F, p = stats.f_oneway(d_données['Soleil'], d_données['Sam'], d_données['Jeu'],d_données['Ven'])
imprimer('F ={},p={}'.format(F,p))
F =5.955112389949444,p=0.0005260114222572804
et P <0,05:
imprimer (“rejeter l'hypothèse nulle”)
le reste:
imprimer (“accepter l'hypothèse nulle”)
Rejeter l'hypothèse nulle.
Étant donné que la valeur p est inférieure à 0.5 nous rejetons l'hypothèse nulle. Pourtant, nous concluons qu'il existe une différence significative entre les revenus des divers groupes de personnes à charge.
Test du chi carré
Ce test est appliqué lorsque vous avez deux variables catégorielles d'une population. Il est utilisé pour déterminer s'il existe une association ou une relation significative entre les deux variables.
Il y a 2 types de tests du chi carré: Test d'adéquation du chi carré et test du chi carré d'indépendance, nous allons mettre en œuvre ce dernier.
Le degré de liberté dans le test du chi carré est calculé par (n-1) * (m-1) où n et m sont respectivement les nombres de lignes et de colonnes.
Il est désigné par:

Mise en œuvre
Nous utiliserons des caractéristiques catégorielles Genre Oui Statut du prêt et découvrir s'il existe une association entre eux en utilisant le test du chi carré.
Hypothèse nulle: il n'y a pas d'association significative entre les caractéristiques de genre et le statut de prêt.
Hypothèse alternative: il existe une association significative entre les caractéristiques de genre et le statut de prêt.
Code
Premier, on récupère la colonne Gender et LoanStatus et on forme un tableau.
dataset_table=pd.crosstab(base de données['sexe'],base de données['fumeur']) dataset_table
Loan_Status N Y
Gender
Female 37 75
Homme 33 339
Alors, nous calculons les valeurs observées et attendues à l'aide du tableau ci-dessus.
observé=dataset_table.values val2=stats.chi2_contingency(dataset_table) attendu=val2[3]
Ensuite, nous calculons la statistique du chi carré et la valeur p à l'aide du code suivant:
de scipy.stats importer chi2 chi_carré=somme([(o-et)**2./e pour o,e en zip(observé,attendu)]) chi_square_statistic=chi_square[0]+chi_carré[1] p_value=1-chi2.cdf(x=chi_square_statistic,df = dddf)
imprimer("statistique du chi carré:-",chi_square_statistic)
imprimer('Niveau de signification: ',alpha)
imprimer('Degré de liberté: ',je vais venir)
imprimer('valeur p:',p_valeur)
statistique du chi carré:- 0.23697508750826923 Niveau de signification: 0.05 Degré de liberté: 1 valeur p: 0.6263994534115932
si p_valeur<=alpha:
imprimer("Rejeter l'hypothèse nulle")
autre:
imprimer("Accepter l'hypothèse nulle")
Accepter l'hypothèse nulle
Étant donné que la valeur p est supérieure à 0.05, on accepte l'hypothèse nulle. Nous concluons qu'il n'y a pas d'association significative entre les deux caractéristiques.
résumé
Premier, nous avons discuté de la sélection des fonctionnalités. Ensuite, nous passons aux tests statistiques et aux diverses terminologies qui s'y rapportent.. Finalement, nous avons vu l'application de tests statistiques, c'est-à-dire, essai Z, Test T, test de corrélation, ANOVA et test Chi-deux ainsi que leur implémentation en Python.
Les références
Image exceptionnelle – Google Image
Statistiques – statistiqueswho.com
Sur moi
Salut! Soja Ashish Choudhary. J'étudie le B.Tech de l'Université des sciences et technologies JC Bose. La science des données est ma passion et je suis fier d'écrire des blogs intéressants à ce sujet. N'hésitez pas à me contacter sur LinkedIn.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





