introduction
Le format PDF ou fichier de document portable est l'un des formats de fichiers les plus courants aujourd'hui. Il est largement utilisé dans toutes les industries, comme dans les bureaux du gouvernement, soins médicaux et même travail personnel. Comme conséquence, Il existe une grande quantité de données non structurées au format PDF et l'extraction de ces données pour générer des informations significatives est un travail courant chez les data scientists.
Il existe plusieurs bibliothèques Python dédiées au travail avec des documents PDF comme PYPDF2, etc. Dans ce tutoriel, portera Camelot.

Pourquoi Camelot?
- Vous êtes en contrôle: contrairement à d'autres bibliothèques et outils qui donnent de bons résultats ou échouent lamentablement (sans intermédiaires), Camelot vous donne le pouvoir de modifier l'extraction de table. (Ceci est essentiel puisque tout dans le monde réel, y compris l'extraction de tableaux PDF, c'est confus).
- Un peu les tableaux peuvent être supprimés en fonction de métriques telles que la précision et les espaces, sans avoir à regarder manuellement chaque table.
- Chaque table est un DataFrame pandas, qui s'intègre parfaitement dans Analyse des données et workflows ETL.
- Exporter vers plusieurs formats, y compris JSON, Exceller, HTML et SQLite.
On va commencer
Avant d'installer les bibliothèques Camelot, nous devons installer script fantôme , une fois que nous avons installé le script fantôme, installons-nous camelot-py.
Exécutez les commandes ci-dessous :
pip installer "camelot-py[CV]"
Une fois que vous avez installé la bibliothèque camelot-py, nous serons prêts à commencer. Nous essayons d'extraire un tableau des recettes de la TPS à l'échelle de l'État à partir de ce document pdf.
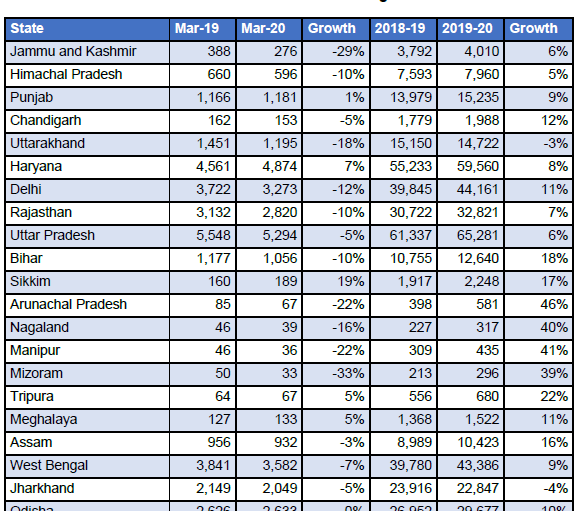
tableau pdf
importer camelot
Si vous avez du camelot, Python n'imprimera pas de message d'erreur, et sinon, vous verrez un ImportError.
# Syntaxe de la fonction camelot.read_pdf
camelot.lire_pdf(
chemin du fichier,
pages='1',
le mot de passe=Aucun,
saveur='treillis',
supprimer_stdout=Faux,
layout_kwargs={},
**kwargs,
)
Si vous devez extraire un tableau de différentes pages, vous devez donner le numéro de page.
tables2=camelot.read_pdf('tps-recettes-collecte-mars2020.pdf', saveur ="flux", pages="0-3")
tableaux2
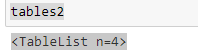
Cela vous donnera une liste totale du tableau qui est là dans un document pdf. on peut choisir une table passant l'index.
tableaux2[2] # 2 est l'indice
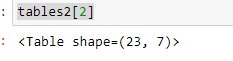
tableaux2[2].rapport_analyse

Le code ci-dessus vous fournira des détails tels que la précision et le numéro de page. Veuillez noter qu'il existe 2 pages.
Le code suivant extraira le tableau du document pdf.
df2=tables2[2].df
df2
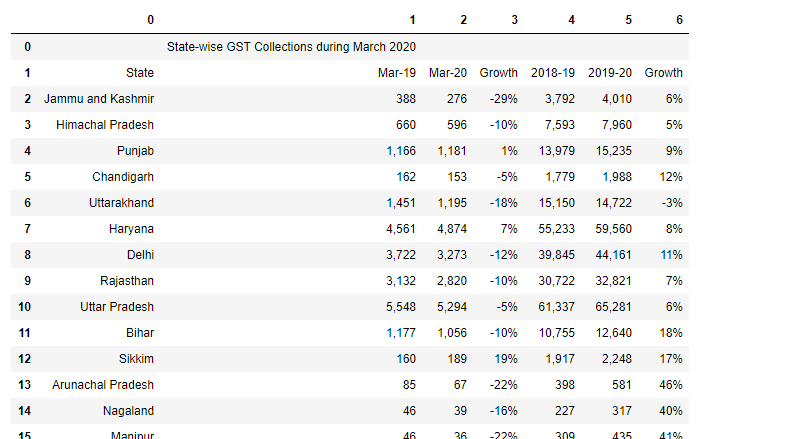
Dans cette circonstance, car le tableau est divisé en deux pages différentes. Ensuite, nous pouvons faire une solution.
tableaux2[3]
tableaux2[3].rapport_analyse

Ici vous pouvez remarquer, nous extrayons le tableau de la page no 3.
df3=tables2[3].df
df3
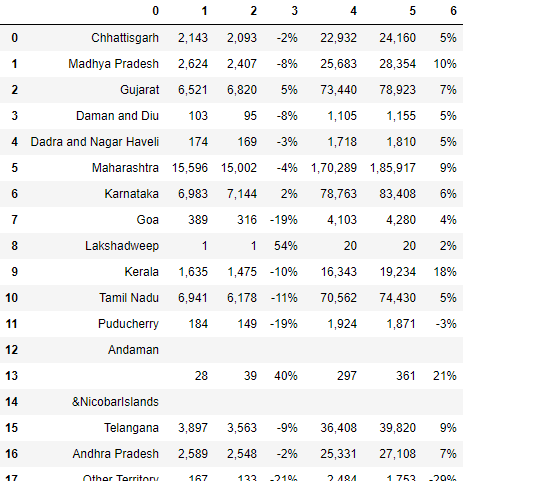
Ce qui suit est le code pour ajouter df2 et df3.
df4=df2.append(df3)
df4
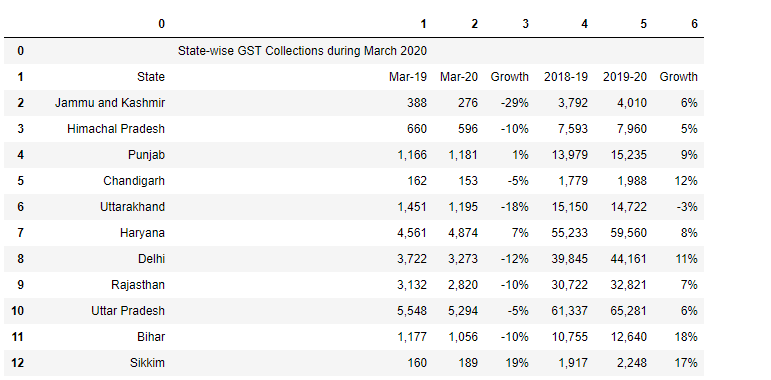
df5 = df4[1:] df5.head() new_header = df5.iloc[0]df5 = df5[1:]df5.columns = new_header
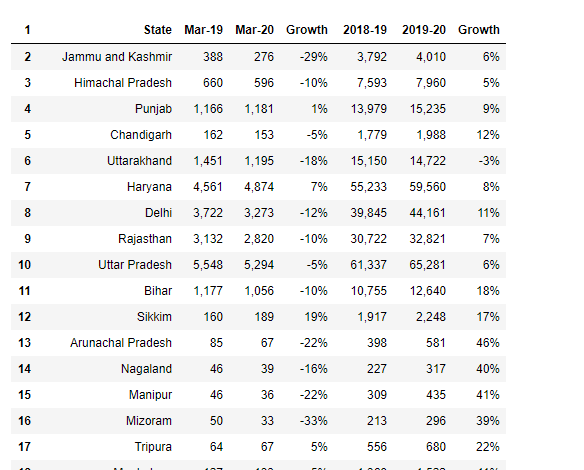
Ici tu as, nous avons extrait un tableau du pdf, maintenant nous pouvons exporter ces données dans n'importe quel format vers le système local.
conclusion
L'extraction de données tabulaires à partir de pdf à l'aide de la bibliothèque camelot est vraiment facile. En même temps, nous savons qu'il y a beaucoup de données non structurées au format pdf et, après avoir extrait les tableaux, nous pouvons faire beaucoup d'analyses et de visualisations en fonction des besoins de votre entreprise.
J'espère que cet article vous aidera et vous fera gagner du temps. Laissez-moi savoir si vous avez des suggestions.
CODAGE HEUREUX.
A propos de l'auteur

Prabhat Kumar – Analyste associé
Je suis un ingénieur qui travaille aujourd'hui dans les principales entreprises multinationales en tant qu'analyste associé et passionné d'innovation, j'aime apprendre de nouvelles choses, Je crois que chaque information a une histoire et j'aime lire les histoires.
Prabhat Pathak (Profil LinkedIn) est analyste associé.





