Classificazione dell'albero decisionale | Guida alla classificazione dell'albero decisionale
Contenuti
Panoramica
Che cos'è l'algoritmo dell'albero di classificazione delle decisioni??
Come costruire un albero decisionale da zero
Terminologie dell'albero decisionale
Differenza tra foresta casuale e albero decisionale
Implementazione del codice Python degli alberi decisionali
Esistono diversi algoritmi nell'apprendimento automatico per problemi di regressione e classificazione, ma optando per L'algoritmo migliore e più efficiente per il dato set di dati è il punto principale da fare durante lo sviluppo di un buon modello di apprendimento automatico..
Uno di questi algoritmi buono per problemi di classificazione / categorico e di regressione è l'albero decisionale
Gli alberi decisionali generalmente implementano esattamente la capacità di pensiero umano quando si prende una decisione, quindi è facile da capire.
La logica dietro l'albero decisionale può essere facilmente compresa perché mostra una struttura di tipo diagramma di flusso / struttura ad albero che semplifica la visualizzazione e l'estrazione di informazioni dal processo in background.
Sommario
Che cos'è un albero decisionale?
Elementi dell'albero decisionale
Come prendere una decisione da zero
Come funziona l'algoritmo dell'albero decisionale??
Conoscenza dell'EDA (analisi esplorativa dei dati)
Alberi decisionali e foreste casuali
Vantaggi della foresta decisionale
Svantaggi della foresta decisionale
Implementazione del codice Python
1. Che cos'è un albero decisionale?
Un albero decisionale è un algoritmo di apprendimento automatico supervisionato. Utilizzato sia negli algoritmi di classificazione che di regressione.. L'albero decisionale è come un albero con nodi. I rami dipendono da diversi fattori. Divide i dati in rami come questi fino a raggiungere un valore di soglia. Un albero decisionale è costituito dai nodi radice, nodi figli e nodi foglia.
Comprendiamo i metodi dell'albero decisionale prendendo uno scenario di vita reale
Immagina di giocare a calcio ogni domenica e di invitare sempre il tuo amico a giocare con te. Qualche volta, il tuo amico viene e gli altri no.
Il fattore di venire o meno dipende da numerose cose, come il tempo, la temperatura, vento e stanchezza. Abbiamo iniziato a prendere in considerazione tutte queste funzionalità e abbiamo iniziato a seguirle insieme alla decisione del tuo amico di venire a giocare o meno..
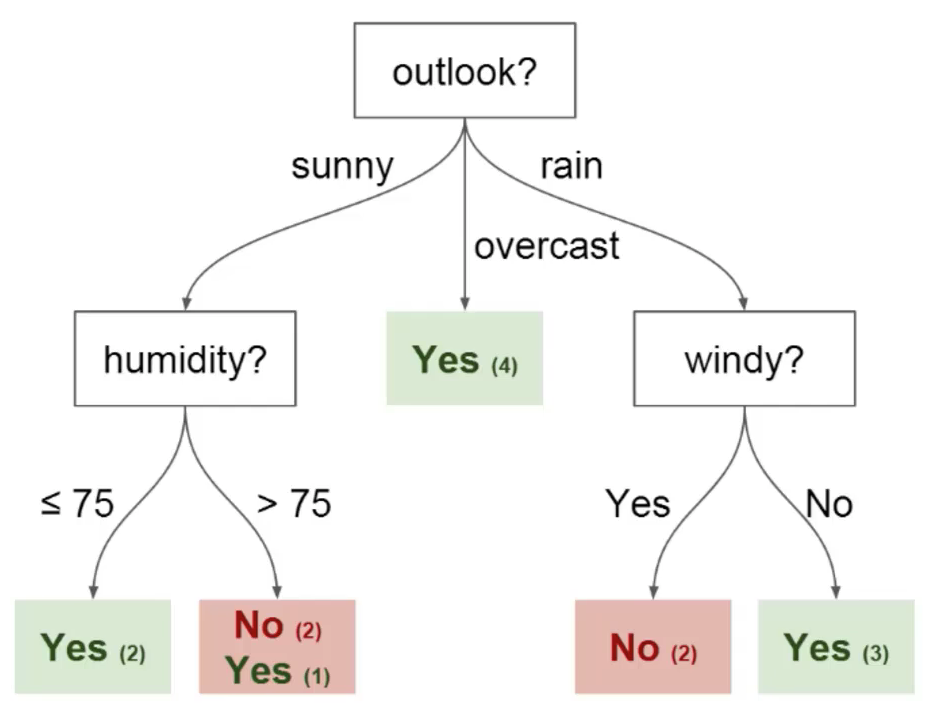
Puoi utilizzare questi dati per pronosticare se il tuo amico verrà a giocare a calcio o meno. La tecnica che potresti usare è un albero decisionale. Ecco come sarebbe l'albero decisionale dopo la distribuzione:
2. Elementi di un albero decisionale
Ogni albero decisionale è costituito dal seguente elenco di elementi:
un nodo
b bordi
c Radice
d Foglie
un) nodi: È il punto in cui l'albero viene diviso in base al valore di qualche attributo / caratteristica del set di dati.
B) bordi: Dirige il risultato di una divisione al nodo successivo che possiamo vedere nella figura precedente che ci sono nodi per caratteristiche come la prospettiva, umidità e vento. C'è un vantaggio per ogni potenziale valore di ciascuno di questi attributi / caratteristiche.
C) Radice: Questo è il nodo dove avviene la prima divisione.
D) Fogliame: Questi sono i nodi terminali che predicono l'esito dell'albero decisionale.
3. Come costruire alberi decisionali da zero?
Quando si crea un albero decisionale, la cosa principale è selezionare l'attributo migliore dall'elenco delle caratteristiche totali del set di dati per il nodo radice e per i sottonodi. La selezione degli attributi migliori viene eseguita con l'aiuto di una tecnica nota come misura di selezione degli attributi. (ASM).
Con l'aiuto di ASM, possiamo facilmente selezionare le migliori caratteristiche per i rispettivi nodi dell'albero decisionale.
Ci sono due tecniche per ASM:
un) Guadagno di informazioni
B) Indice di Gini
un) Guadagno di informazioni:
1Il guadagno di informazioni è la misurazione dei cambiamenti nel valore dell'entropia dopo la divisione / segmentazione del set di dati basata su un attributo.
2 Indica quante informazioni ci fornisce una funzione / attributo.
3 Seguendo il valore del guadagno di informazioni, la divisione dei nodi e la costruzione dell'albero decisionale sono in corso.
L'albero delle decisioni 4 cerca sempre di massimizzare il valore del guadagno di informazioni, e un nodo / l'attributo che ha il valore più alto del guadagno di informazioni viene diviso per primo. Il guadagno di informazioni può essere calcolato utilizzando la seguente formula:
Guadagno di informazioni = Entropia (S) – [(Media ponderata) *entropia(ogni caratteristica)
entropia: Entropia indica la casualità nel set di dati. Viene definito come una metrica per misurare l'impurità. L'entropia può essere calcolata come:
entropia(S)= -P(sì)log2 P(sì)- P(no) log2 P(no)
In cui si,
S= Numero totale di campioni
P(sì)= probabilità di sì
P(no)= probabilità di no.
B) Indice Gini:
L'indice di Gini viene anche definito come una misura di impurezza/purezza utilizzata durante la creazione di un albero decisionale nel CART(noto come albero di classificazione e regressione) algoritmo.
Un attributo con un valore dell'indice Gini basso dovrebbe essere preferito rispetto al valore dell'indice Gini alto.
Crea solo divisioni binarie, e l'algoritmo CART utilizza l'indice di Gini per creare divisioni binarie.
L'indice di Gini può essere calcolato utilizzando la formula seguente:
Indice Gini= 1- ?JPJ2
Dove pj sta per la probabilità
4. Come funziona l'algoritmo dell'albero decisionale??
L'idea alla base di qualsiasi algoritmo dell'albero decisionale è la seguente:
1. Seleziona la caratteristica migliore utilizzando le misure di selezione degli attributi(ASM) per dividere i record.
2. Rendi quell'attributo/caratteristica un nodo decisionale e suddividi il set di dati in sottoinsiemi più piccoli.
3 Inizia il processo di costruzione dell'albero ripetendo questo processo in modo ricorsivo per ogni bambino fino a quando non viene raggiunta una delle seguenti condizioni :
un) Tutte le tuple appartenenti allo stesso valore di attributo.
B) Non ci sono più attributi rimanenti.
C ) Non ci sono più istanze rimanenti.
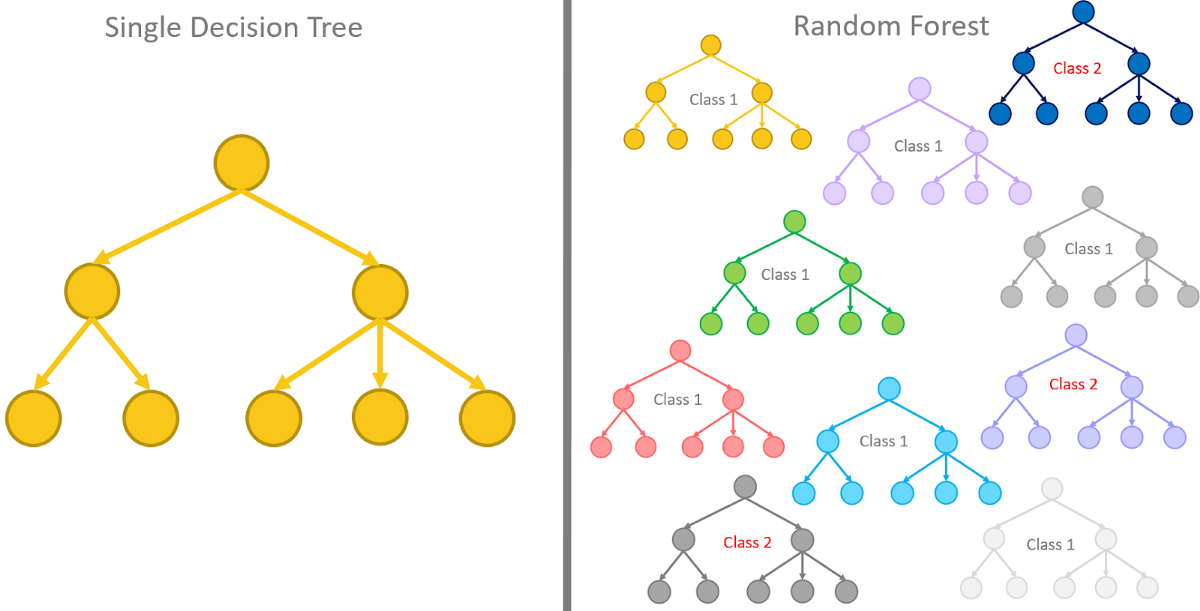
5. Alberi decisionali e foreste casuali
Gli alberi decisionali e la foresta casuale sono entrambi i metodi ad albero utilizzati in Machine Learning.
Gli alberi decisionali sono i modelli di Machine Learning utilizzati per fare previsioni esaminando ogni singola caratteristica nel set di dati, uno per uno.
Le foreste casuali d'altra parte sono una raccolta di alberi decisionali raggruppati e addestrati insieme che utilizzano ordini casuali delle caratteristiche nei set di dati forniti.
Invece di fare affidamento su un solo albero decisionale, la foresta casuale prende la previsione da ogni albero e si basa sulla maggioranza dei voti delle previsioni, e dà l'output finale. In altre parole, la foresta casuale può essere definita come una raccolta di più alberi decisionali.
6. Vantaggi dell'albero decisionale
1 È semplice da implementare e segue una struttura di tipo diagramma di flusso che ricorda il processo decisionale umano.
2 Si rivela molto utile per problemi legati alle decisioni.
3 Aiuta a trovare tutti i possibili risultati per un dato problema.
4 La pulizia dei dati negli alberi decisionali è minima rispetto ad altri algoritmi di Machine Learning.
5 Gestisce sia valori numerici che categoriali
7. Svantaggi dell'albero decisionale
1 Troppi livelli di albero decisionale lo rendono a volte estremamente complesso.
2 Potrebbe causare un sovradattamento ( che può essere risolto usando il Algoritmo della foresta casuale)
3 Per il maggior numero di etichette di classe, la complessità computazionale dell'albero decisionale aumenta.
8. Implementazione del codice Python
#Librerie di calcolo numerico
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Suddividi il set di dati in dati di addestramento e dati di test
from sklearn.model_selection import train_test_split
x = raw_data.drop('Cifosi', asse = 1)
y = raw_data['Cifosi']
x_dati_di_allenamento, x_test_data, y_training_data, y_test_data = train_test_split(X, e, test_size = 0.3)
#Entrenar el modelo de árbol de decisiones
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(x_dati_di_allenamento, y_training_data)
forecasts = model.predict(x_test_data)
# Medir el rendimiento del modelo de árbol de decisiones
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
print(classificazione_report(y_test_data, predizioni))
Stampa(confusione_matrice(y_test_data, predizioni))
Con questo chiudo questo blog.. Ciao a tutti, Namaste Il mio nome è Pranshu Sharma e sono un appassionato di data science
Grazie mille per aver dedicato del tuo tempo prezioso a leggere questo blog.. Sentiti libero di segnalare eventuali errori (Dopotutto, sono un apprendista) e fornire i commenti corrispondenti o lasciare un commento.
Dhanyvaad !! Feedback: E-mail: [e-mail protetta]
Il supporto mostrato in questo articolo di DataPeaker non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.