Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Este artículo tiene como objetivo comparar cuatro algoritmos diferentes de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... y aprendizaje automático para construir un detector de spam y evaluar su rendimiento. Il set di dati che abbiamo utilizzato proveniva da un campione casuale di soggetti e corpi di e-mail che contenevano sia spam che e-mail dannose in numerose proporzioni, che trasformiamo in slogan. Il rilevamento dello spam è uno dei progetti di deep learning più efficaci, ma spesso è anche un progetto in cui le persone perdono la fiducia nella ricerca del modello più semplice per scopi di precisione. In questo articolo, rileveremo lo spam nella posta utilizzando quattro diverse tecniche e le confronteremo per ottenere il modello più accurato.
PERCHÉ RILEVARE SPAM?
Un'e-mail è diventata uno dei più importanti tipi di comunicazione. Sopra 2014, si stima che ci sia 4,1 1 miliardo di account di posta elettronica in tutto il mondo, e intorno 196 1 miliardo di email vengono inviate giorno dopo giorno in tutto il mondo. Lo spam è una delle principali minacce presentate agli utenti di posta elettronica. Tutti i flussi di posta elettronica che erano spam in 2013 sono i 69,6%. Perciò, un'efficace tecnologia di filtraggio dello spam è un contributo significativo alla sostenibilità del cyberspazio e della nostra società. Poiché l'importanza dell'e-mail non è inferiore a quella del tuo conto bancario contenente 1Cr., Anche proteggerlo da spam o frodi è obbligatorio.
Preparazione dei dati
Per preparare i dati, seguiamo i passaggi seguenti:
1. Scarica e-mail di spam e ham tramite Google da asporto come file box.
2. Leggi i file mbox negli elenchi usando il pacchetto 'mailbox'. Ogni elemento dell'elenco conteneva un'e-mail individuale. Nella prima iterazione, includiamo 1000 E-mail radioamatoriali e 400 email di spam (testiamo proporzioni diverse dopo la prima iterazione).
3. Decomprimere ogni email e concatenarne l'oggetto e il corpo. Abbiamo deciso di includere anche l'oggetto dell'e-mail nella nostra analisi perché è anche un ottimo indicatore del fatto che un'e-mail sia spam o ham..
4. Elenchi convertiti in frame di dati, frame di dati di spam e ham uniti, e mescolato il frame di dati risultante.
5. Dividi il frame di dati in frame di dati di test e streaming. I dati del test erano i 33% dal set di dati originale.
6. Dividi il testo della posta in slogan e applica la trasformazione TF-IDF utilizzando CountVectorizer seguito dal trasformatore TF-IDF.
7. Se entrenaron cuatro modelos usando los datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina....:
- Bayes ingenuo
- Alberi decisionali
- Supporta la macchina vettoriale (SVM)
- foresta casuale
8. Utilizzo dei modelli addestrati, etichetta e-mail prevista per il set di dati di prova. Sono state calcolate quattro metriche per misurare le prestazioni dei modelli come Precisione, Precisione, Recupero, Punteggio F, AUC.
CODICE
1.Importa le librerie
#importa tutte le librerie necessarie importare la casella di posta %matplotlib in linea importa matplotlib.pyplot come plt importa csv da textblob import TextBlob importare panda importare sklearn #import cPickle importa numpy come np da sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer da sklearn.naive_bayes import MultinomialNB da sklearn.svm import SVC, LinearSVC da sklearn.metrics import classificazione_report, f1_score, precision_score, confusione_matrice da sklearn.pipeline import Pipeline da sklearn.grid_search import GridSearchCV da sklearn.cross_validation import StratifiedKFold, cross_val_score, train_test_split da sklearn.tree import DecisionTreeClassifier da sklearn.learning_curve import learning_curve #import librerie di metriche da sklearn.metrics import confusion_matrix da sklearn.metrics import precision_score da sklearn.metrics import recall_score da sklearn.metrics import f1_score da sklearn.metrics import roc_auc_score
2.Funzione per ottenere il testo dell'e-mail dal corpo dell'e-mail
def getmailtext(Messaggio): #ottenere il testo normale "corpo dell'email"
corpo = Nessuno
#controlla se il messaggio di posta elettronica di mbox ha più parti
if message.is_multipart():
per parte in message.walk():
if part.is_multipart():
per la sottoparte in part.walk():
if subpart.get_content_type() == 'testo/semplice':
body = subpart.get_payload(decodifica=Vero)
elif part.get_content_type() == 'testo/semplice':
body = part.get_payload(decodifica=Vero)
#se il messaggio ha solo una parte
elif message.get_content_type() == 'testo/semplice':
body = message.get_payload(decodifica=Vero)
#restituisce il testo della posta che concatena sia l'oggetto che il corpo della posta
mailtext=str(Messaggio['soggetto'])+" "+str(corpo)
messaggio di ritorno
3. Leggi il file di posta indesiderata m-box
mbox = casella di posta.mbox('Spam.mbox')
mlist_spam = []
#crea un elenco che contiene il testo della posta per ogni messaggio di posta elettronica di spam
per messaggio in mbox:
mlist_spam.append(getmailtext(Messaggio))
#rottura
#leggi file email mbox ham
mbox_ham = casella di posta.mbox('ham.mbox')
mlist_ham = []
conteggio=0
#crea un elenco che contiene il testo della posta per ogni messaggio di posta elettronica amatoriale
per messaggio in mbox_ham:
mlist_ham.append(getmailtext(Messaggio))
se conta>601:
rottura
conteggio+=1
4. Crea due set di dati dalle e-mail di spam / prosciutto che contengono informazioni come il testo dell'e-mail, l'etichetta postale e la lunghezza della spedizione.
#creare 2 frame di dati per le e-mail di spam ham che contengono le seguenti informazioni- #Testo della posta, lunghezza della posta, la posta è etichetta prosciutto/spam importa panda come pd spam_df = pd.DataFrame(mlist_spam, colonne=["Messaggio"]) spam_df["etichetta"] = "spam" spam_df['lunghezza'] = spam_df['Messaggio'].carta geografica(testo lambda: len(testo)) Stampa(spam_df.head()) ham_df = pd.DataFrame(mlist_ham, colonne=["Messaggio"]) ham_df["etichetta"] = "prosciutto" ham_df['lunghezza'] = prosciutto_df['Messaggio'].carta geografica(testo lambda: len(testo)) Stampa(ham_df.head())

5.Funzione per applicare le trasformazioni BOW e TF-IDF
def features_transform(posta):
#prendi la borsa delle parole per il testo della posta
bow_transformer = ContaVectorizer(analizzatore=split_into_lemmas).in forma(mail_treno)
#Stampa(len(bow_transformer.vocabolario_))
message_bow = bow_transformer.transform(posta)
#stampa il valore di scarsità
Stampa('forma matrice sparsa:', messaggi_arco.forma)
Stampa('numero di diversi da zero':', message_bow.nnz)
Stampa("sparsità": %.2F%%' % (100.0 * message_bow.nnz / (messaggi_arco.forma[0] * messaggi_arco.forma[1])))
#applicare la trasformata TF-IDF all'output di BOW
tfidf_transformer = TfidfTransformer().in forma(messaggi_arco)
message_tfidf = tfidf_transformer.transform(messaggi_arco)
#Stampa(message_tfidf.shape)
#restituisce il risultato delle trasformazioni
return message_tfidf
6. Funzione per stampare le metriche di performance del modello associato
#funzione che accetta y valore di test e y valore previsto e stampa le metriche delle prestazioni del modello associate
def model_assessment(y_test,classe_predetta):
Stampa('matrice di confusione')
Stampa(confusione_matrice(y_test,classe_predetta))
Stampa('precisione')
Stampa(precision_score(y_test,classe_predetta))
Stampa('precisione')
Stampa(precision_score(y_test,classe_predetta,pos_label="spam"))
Stampa('richiamare')
Stampa(punteggio_richiamo(y_test,classe_predetta,pos_label="spam"))
Stampa('F-Score')
Stampa(f1_score(y_test,classe_predetta,pos_label="spam"))
Stampa('AUC')
Stampa(roc_auc_score(np.dove(y_test == 'spam',1,0),np.dove(forecast_class=='spam',1,0)))
plt.matshow(confusione_matrice(y_test, classe_predetta), cmap=plt.cm.binary, interpolazione='più vicino')
plt.titolo('matrice di confusione')
plt.colorbar()
plt.ylabel('etichetta prevista')
plt.xlabel('etichetta prevista')
Iniziamo l'analisi comparativa di quattro diversi modelli per ottenere l'algoritmo più performante.
1.Modello Naive Bayes
Bayes ingenuo con un approccio a sacco di parole usando TF-IDFNaive Bayes è l'algoritmo di ordinamento più semplice (veloce da formare, utilizzato regolarmente per il rilevamento dello spam). è un metodo popolare (linea di base) per la categorizzazione del testo, la questione di giudicare i documenti come appartenenti a una categoria o all'opposto (come spammare il legittimo, sport o politica, eccetera.) con frequenze di parola dovute alle caratteristiche.
Estrazione di feature utilizzando BOW:
Frequenza del termine TF-IDF: la frequenza inversa del documento utilizza tutti i token all'interno del set di dati come vocabolario. La frequenza del termine e il numero di documenti durante i quali viene prodotto il token sono responsabili della determinazione della frequenza inversa del documento.. Ciò che questo assicura è che, se un token si verifica frequentemente durante un documento, quel token avrà un alto TF ma se quel token si verifica frequentemente nella maggior parte dei documenti, quindi ridurre l'IDF. Entrambe queste matrici TF e IDF per un documento selezionato vengono moltiplicate e normalizzate per rendere il TF-IDF di un documento.
CODICE
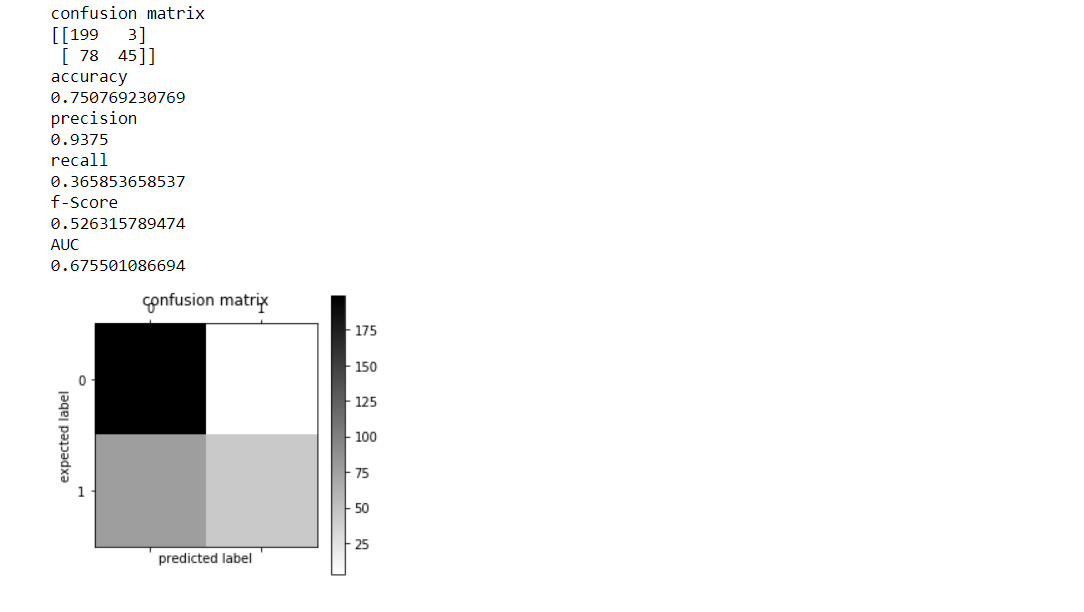
#creare e adattare il modello NB modelloNB = MultinomialeNB() modelloNB.fit(train_features,y_train) #trasformare le funzionalità di test per testare le prestazioni del modello test_features=features_transform(mail_test) #NB previsioni forecast_class_NB=modelNB.predict(test_features) #valutare NB modello_valutazione(y_test,forecast_class_NB)
2.Modello di albero decisionale
Gli alberi decisionali sono utilizzati per la classificazione e la regressione. La teoría podría ser una misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... para definir este grado de desorganización durante un sistema llamado Entropía. Il fattore di entropia varia da campione a campione. L'entropia è zero per il campione omogeneo, e per il campione di uguali dividendi, l'entropia è 1. Elige la división que tiene una entropía mínima en comparación con el nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... principal y otras divisiones. Più piccola è l'entropia, maggiore.
CODICE
#creare e adattare il modello dell'albero model_tree=DecisionTreeClassifier() model_tree.fit(train_features,y_train) #esegui il modello su test e stampa metriche forecast_class_tree=model_tree.predict(test_features) modello_valutazione(y_test,albero_classe_predetto)

3. Supporta la macchina vettoriale
Entrambe le sfide di classificazione e regressione funzionano perfettamente per questo popolare algoritmo di apprendimento automatico supervisionato. (SVM). tuttavia, è usato principalmente nei problemi di classificazione. Quando lavoriamo con questo algoritmo, nello spazio n-dimensionale, stiamo andando a tracciare ogni elemento di dati in una certa misura, in modo che il valore di ciascuna caratteristica sia il valore di una coordinata selezionata. Support Vector Machine potrebbe anche essere un confine che segrega meglio il 2 Lezioni (iperpiano / linea).
CODICE
#creare e adattare il modello SVM model_svm=SVC() model_svm.in forma(train_features,y_train) #esegui il modello su test e stampa metriche forecast_class_svm=model_svm.prevedere(test_features) modello_valutazione(y_test,forecast_class_svm)


4. foresta casuale
La foresta casuale è come un algoritmo bootstrap con un modello ad albero di chiamate (CARRELLO). L'ultima parola di previsione potrebbe essere una funzione di ogni previsione. Questa previsione finale può essere semplicemente la media di tutte le previsioni. La foresta casuale fornisce previsioni significativamente più accurate se posizionata accanto a semplici modelli CART / CHAID o regressione in molti scenari. Questi casi hanno generalmente un gran numero di variabili predittive e un'enorme dimensione del campione.. Ciò è spesso dovuto al fatto che cattura la varianza di diverse variabili di input in un tempo uniforme e consente a un gran numero di osservazioni di partecipare alla previsione..
CODICE
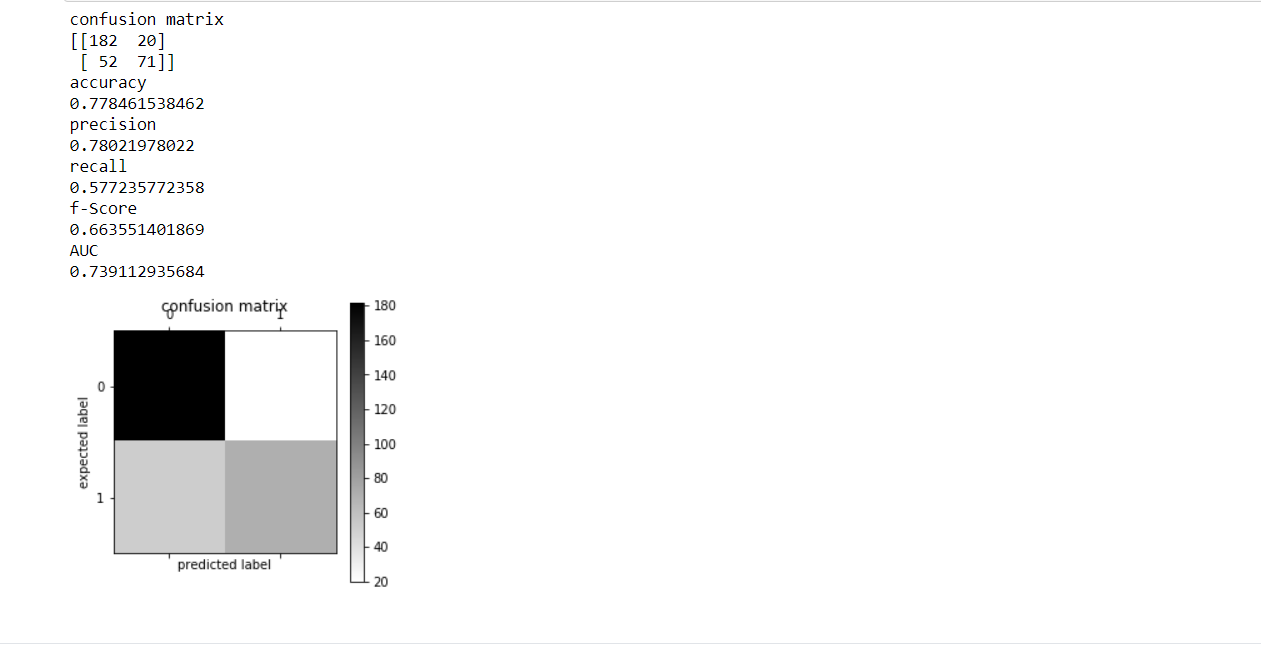
a partire dal sklearn.set importare Classificatore foresta casuale #creare e adattare il modello model_rf=Classificatore foresta casuale(n_estimatori=20,criterio='entropia') model_rf.in forma(train_features,y_train) #esegui il modello su test e stampa metriche forecast_class_rf=model_rf.prevedere(test_features) modello_valutazione(y_test,forecast_class_rf)
CONFRONTO:-
Vedendo l'uscita del 4 Modelli, puoi facilmente confrontare e trovare la sua precisione. Secondo la spiegazione sopra, l'ordine di precisione decrescente è rappresentato come:
PRECISIONE DEL MODELLO
FORESTA CASUALE 0.77846
NAIVE BAYS 0,75076
MODELLO DI ALBERO DECISIONALE 0.65538
SUPPORTO MACCHINA VETTORIALE 0.62153
RISULTATI
I risultati sono molto chiari sul fatto che Random Forest è il metodo più accurato per rilevare le e-mail di spam.. La ragione per lo stesso è la sua ampia capacità di deviazione per trovare la caratteristica migliore usando la sua casualità. Il modello che non può essere utilizzato per tale rilevamento dello spam è SVM. La ragione per lo stesso è la sua piccola espansione. SVM potrebbe non essere in grado di gestire grandi quantità di dati.
CONCLUSIONE
Questo articolo ti aiuterà a implementare un progetto di rilevamento dello spam con l'aiuto del deep learning. Questo si basa in gran parte su un'analisi comparativa di quattro diversi modelli. Resta sintonizzato su Analytics Vidya per i prossimi articoli. Puoi usarlo come riferimento. Sentiti libero di inserire i tuoi contributi nella chat qui sotto. Puoi anche inviarmi un ping su LinkedIn all'indirizzo https://www.linkedin.com/in/shivani-sharma-aba6141b6/
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





