introduzione
A lungo, Stavo facendo il modello predittivo usando la regressione lineare e ho trovato una variabile il cui coefficiente di regressione non standardizzato (beta o stima) vicino allo zero, ma dopo un po' di analisi, Trovo che sia statisticamente significativo (significa valore p <0.05 ). Sabemos que si una variable es significativa para un modelo en particular, significa que el valor de su coeficiente es significativo y distinto de cero. Entonces, la pregunta que ocurre es "¿Por qué el valor del coeficiente es cercano a cero pero esa variable es significativa para nuestro modelo predictivo?".
La soluzione a questa domanda risiede nella differenza tra i coefficienti di regressione standardizzati e non standardizzati.. Quindi, in questo post, vedremo i concetti di base alla base di questi coefficienti e come differiscono l'uno dall'altro con i loro vantaggi e svantaggi.
Il concetto di standardizzazione o coefficienti standard entra in scena quando le variabili indipendenti o il predittore di un particolare modello sono espressi in unità diverse.. Come esempio, diciamo che abbiamo tre caratteristiche indipendenti, vale a dire, altezza, età e peso. La tua altezza è in pollici, il tuo peso in chilogrammi e la tua età in anni. Se vogliamo classificare questi predittori in base al coefficiente non standardizzato (che arriva direttamente quando addestriamo un modello di regressione), non sarebbe un confronto equo poiché le unità per tutti i predittori sono diverse.
Coefficienti di regressione non standardizzati
1. Cosa sono i coefficienti di regressione non standardizzati?
I coefficienti non standardizzati sono quelli prodotti dal modello di regressione lineare dopo il suo addestramento utilizzando le variabili indipendenti misurate sulle loro scale originali., In altre parole, nelle stesse unità in cui il set di dati viene prelevato dalla sorgente per addestrare il modello.
– Il coefficiente non standardizzato non deve essere utilizzato per escludere o classificare i predittori (note anche come variabili indipendenti), poiché non elimina l'unità di misura.
Come esempio, Facciamo un esempio ipotetico in cui vogliamo prevedere le entrate (in rupie) di una persona in base alla sua età (in anni), altezza (e cmq) e peso (in kg). Quindi, qui gli input per il nostro modello di regressione sono l'età, altezza e peso, e la produzione è reddito. Successivamente,
Reddito (rupie) = A0 + a1 * età (anni) + a2 * altezza (cm) + a3 * il peso (kg) + e (eqn-1)
2. Come interpretare i coefficienti di regressione non standardizzati?
Sono usati per interpretare l'effetto di ogni variabile indipendente sul risultato. (Rispondere / Uscita). La sua interpretazione è semplice ed intuitiva.
– Tutte le altre variabili sono mantenute costanti, un cambio di 1 unità a Xi (predittori) implica che c'è una variazione media delle unità ai in Y (Risultato).
Nell'esempio sopra, e a1 = 0.3, a2 = 0.2 y a3 = 0.4 (e assumiamo che siano tutti statisticamente significativi), allora interpretiamo questi coefficienti come:
Avere 1 anno è associato ad un aumento di 0,3 di reddito, assumendo che le altre variabili siano costanti (significa che non vi è alcun cambiamento in altezza e peso).
Equivalentemente, possiamo anche interpretare il coefficiente per altre variabili indipendenti.
Rappresenta la quantità di cui cambia la variabile dipendente se cambiamo la variabile indipendente di una unità, mantenendo costanti le altre variabili indipendenti..
3. Limitazioni dei coefficienti di regressione non standardizzati
– I coefficienti non standardizzati sono ottimi per interpretare il legame tra una variabile indipendente X e un risultato Y. Nonostante questo, non sono utili per confrontare l'effetto di una variabile indipendente con un'altra nel modello.
– Come esempio, Quale variabile ha il maggiore impatto sul reddito, età, altezza o peso?
Possiamo provare a rispondere a questa domanda guardando l'equazione-1 e supponiamo di nuovo che a1 = 0.3, a2 = 0.2 y a3 = 0.4, concludiamo che:
“Un aumento di 20 cm di altezza ha lo stesso effetto sull'aumento di peso 10 volte”
Comunque, Questo non risponde alla domanda su quale variabile influisca maggiormente sul reddito.
In particolare, l'affermazione che "l'effetto dell'aumento di peso su 10 volte = l'effetto dell'aumento dell'altezza di 20 cm ”non ha senso senza specificare quanto sia difficile aumentare l'altezza di 20 cm, specificamente per qualcuno che non ha familiarità con questa scala.
Quindi, finalmente, concludiamo che un confronto diretto dei coefficienti di regressione per una delle due variabili indipendenti non ha senso o non è utile poiché queste variabili indipendenti sono su scale diverse (Età in anni, peso in kg e altezza in cm).
Risulta che gli effetti di queste variabili possono essere confrontati utilizzando la versione standardizzata dei loro coefficienti. Ed è di questo che parleremo in seguito.
Coefficienti di regressione standardizzati
1. Cosa sono i coefficienti di regressione standardizzati??
I coefficienti di regressione standardizzati sono ottenuti mediante addestramento (o correndo) un modello di regressione lineare nella forma standardizzata delle variabili.
Le variabili standardizzate vengono calcolate sottraendo la media e dividendo per la deviazione standard di ciascuna osservazione., In altre parole, calcolo del punteggio Z. vorrei dire 0 e deviazione standard 1. Quindi, non rappresentano le loro scale originali poiché non hanno un'unità.
Per ogni osservazione “J” della variabile X, calcoliamo lo z-score usando la formula:
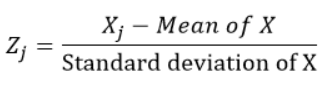
2. Quali variabili dobbiamo standardizzare per trovare i coefficienti di regressione standardizzati, In altre parole, sia il predittore che la soluzione o uno di essi?
sì, standardizziamo entrambe le variabili dipendenti (Rispondere) come gli indipendenti (predittori) prima di eseguire il modello di regressione lineare (poiché questa è la pratica ampiamente accettata quando si vuole trovare la forma standardizzata delle variabili).
3. Come interpretare i coefficienti di regressione standardizzati?
L'interpretazione dei coefficienti di regressione standardizzata non è intuitiva rispetto alle loro versioni non standardizzate:
Un cambio di 1 la deviazione standard in X è associata a una variazione delle deviazioni standard β di Y.
Nota:
– Se c'è una variabile categoriale invece di una variabile numerica nella nostra analisi, allora il suo coefficiente standardizzato non può essere interpretato poiché non ha senso cambiare X in 1 deviazione standard. Generalmente, questo non è un ostacolo per il nostro modello, poiché questi coefficienti non sono destinati ad essere interpretati individualmente, ma da confrontare tra loro per avere un'idea della rilevanza di ciascuna variabile nel modello di regressione lineare.
Il coefficiente standardizzato è misurato in unità di deviazione standard. Un valore beta di 2.25 indica che un cambiamento di una deviazione standard nella variabile indipendente si traduce in un aumento di 2.25 deviazioni standard nella variabile dipendente.
4. Qual è l'uso effettivo dei coefficienti standardizzati??
Sono principalmente utilizzati per classificare i predittori (o variabili indipendenti o esplicative) poiché eliminano le unità di misura delle variabili indipendenti e dipendenti). Possiamo classificare le variabili indipendenti con un valore assoluto di coefficienti standardizzati. La variabile più importante avrà il massimo valore assoluto del coefficiente standardizzato.
Come esempio:
Y = β0 + B1 X1 + B2 X2 + e
Se i coefficienti standardizzati β1 = 0.5 y2 = 1, possiamo concludere che:
X2 è due volte più importante di X1 nella previsione di Y, supponendo che sia X1 e X2 seguono all'incirca la stessa distribuzione e le loro deviazioni standard non sono così diverse.
5. Limitazioni dei coefficienti di regressione standardizzati
I coefficienti standardizzati sono fuorvianti se le variabili nel modello hanno deviazioni standard diverse, significa che tutte le variabili hanno distribuzioni diverse.
Dai un'occhiata alla prossima equazione di regressione lineare:
Reddito ($) =0 + B1 Età (anni) + B2 Esperienza (anni) + e
Perché le nostre variabili indipendenti Età ed Esperienza sono sulla stessa scala (anni) e se è ragionevole presumere che le loro deviazioni standard differiscano notevolmente, allora per questo caso:
– I suoi coefficienti non standardizzati dovrebbero essere usati per confrontare la sua rilevanza / influenza sul modello.
– Standardizzare queste variabili andrebbe bene, in realtà, che erano su una scala diversa (deviazioni standard diverse o segue una distribuzione diversa)
Calcolo dei coefficienti standardizzati
1. Per regressione lineare (un altro approccio, visto che vediamo un focus nella parte precedente del post)
Il coefficiente standardizzato si ottiene moltiplicando il coefficiente non standardizzato per il rapporto delle deviazioni standard della variabile indipendente e della variabile dipendente..

2. Per regressione logistica

Note finali
Questo post ha trattato alcuni concetti di base ma necessari quando si lavora su un progetto di vita reale nell'apprendimento automatico e nell'intelligenza artificiale.. Spero che tu abbia capito molto bene i concetti spiegati in questo post. In questo post nell'ultima parte, Vediamo solo la formulazione relativa ai concetti ma non approfondiamo molto la matematica dietro di essi, Discuteremo quella parte in qualche altro post.
Se hai qualche domanda, Fatemi sapere nella sezione commenti!
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





