Questo post è stato reso pubblico come parte del Blogathon sulla scienza dei dati
introduzione
Python è un linguaggio di programmazione facile da imparare, rendendolo la scelta preferita per i principianti della scienza dei dati, analisi dei dati e apprendimento automatico. Ha anche una grande comunità di studenti online ed eccellenti librerie incentrate sui dati..
Con così tanti dati che vengono generati, è essenziale che i dati che utilizziamo per le applicazioni di data science come l'apprendimento automatico e la modellazione predittiva siano puliti. Ma, Cosa intendiamo per dati puliti? E cosa incasina i dati in primo luogo??
Dati sporchi significa solo dati errati. Duplicazione dei record, Dati incompleti o obsoleti e analisi errate possono rovinare i dati. Questi dati devono essere puliti. Pulizia dei dati (o pulizia dei dati) si riferisce alla procedura di “ripulire” questi dati sporchi, identificare gli errori nei dati e poi correggerli.
La pulizia dei dati è un passo importante in un progetto di machine learning, e tratteremo alcune tecniche di base per la pulizia dei dati (e Python) in questo post.
Pulizia dei dati in Python
Impareremo di più sulla pulizia dei dati in Python con l'aiuto di un set di dati di esempio. Useremo il Set di dati sulle abitazioni russe a Kaggle.
Inizieremo importando le librerie indispensabili.
# import libraries
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
Scaricare i dati e quindi leggerli in un DataFrame Pandas utilizzando il read_csv () e specificando il percorso del file. Successivamente, Utilizzare l'attributo Shape per verificare il numero di righe e colonne nel dataset. Il codice per questo è il seguente:
df = pd.read_csv('housing_data.csv')
forma df
Il set di dati ha 30 471 righe e 292 colonne.
Ora separeremo le colonne numeriche dalle colonne categoriche.
# select numerical columns df_numeric = df.select_dtypes(includi=[np.numero]) numeric_cols = df_numeric.columns.values # select non-numeric columns df_non_numeric = df.select_dtypes(escludi=[np.numero]) non_numeric_cols = df_non_numeric.columns.values
Ora abbiamo finito con i passaggi preliminari. Ora possiamo passare alla pulizia dei dati. Inizieremo identificando le colonne che contengono valori mancanti e cercheremo di correggerle.
Valori mancanti
Inizieremo calcolando la percentuale di valori mancanti in ogni colonna e quindi memorizzando queste informazioni in un DataFrame..
# % of values missing in each column values_list = list() cols_list = elenco() per col in df.columns: pct_missing = np.mean(df[col].è zero())*100 cols_list.append(col) values_list.append(pct_missing) pct_missing_df = pd. DataFrame() pct_missing_df['cavolo'] = cols_list pct_missing_df['pct_missing'] = lista_valori
Il DataFrame pct_missing_df ora contiene la percentuale di valori mancanti in ogni colonna insieme ai nomi delle colonne.
Possiamo anche creare un'immagine da queste informazioni per una migliore comprensione usando il seguente codice:
pct_missing_df.loc[pct_missing_df.pct_missing > 0].complotto(tipo='bar', figsize=(12,8)) plt.mostra()
Il risultato dopo aver eseguito la riga di codice sopra dovrebbe essere simile a questo:
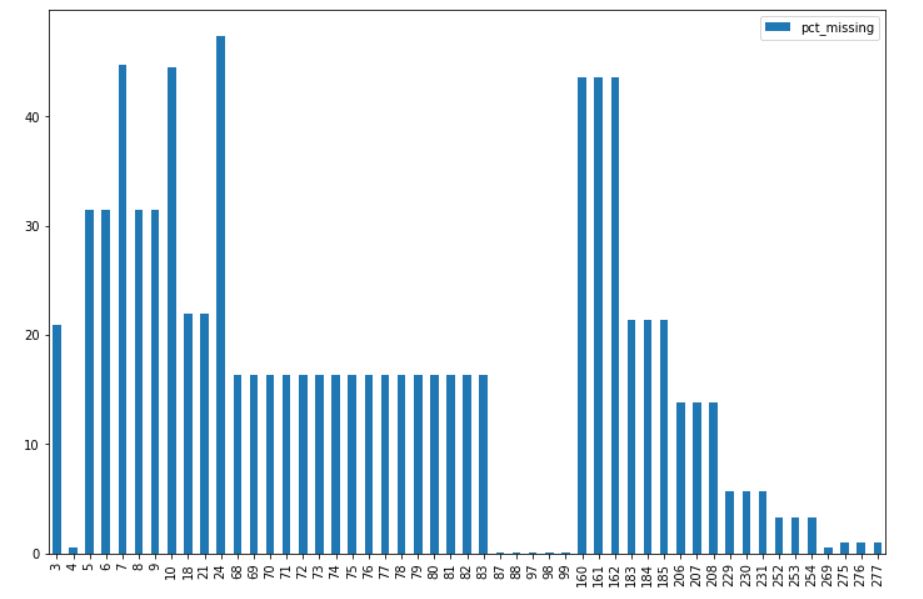
È chiaro che in alcune colonne mancano pochissimi valori, mentre in altre colonne manca una consistente percentuale di valori. Ora sistemeremo questi valori mancanti.
Ci sono diversi modi in cui possiamo correggere questi valori mancanti. Alcuni di loro sono”
Osservazioni autunnali
Un modo potrebbe essere quello di scartare quelle osservazioni che contengono un valore nullo per una qualsiasi delle colonne. Funzionerà quando la percentuale di valori mancanti in ciascuna colonna è molto più bassa. Elimineremo le osservazioni che contengono null in quelle colonne che hanno meno di 0,5% nullo. Queste colonne sarebbero metro_min_walk, metro_km_walk, railroad_station_walk_km, railroad_station_walk_min e ID_railroad_station_walk.
less_missing_values_cols_list = lista(pct_missing_df.loc[(pct_missing_df.pct_missing < 0.5) & (pct_missing_df.pct_missing > 0), 'cavolo'].valori) df.dropna(subset=less_missing_values_cols_list, inplace=Vero)
Ciò ridurrà il numero di record nel nostro set di dati a 30,446 record.
Elimina colonne (funzioni)
Un altro modo per affrontare i valori mancanti in un set di dati sarebbe eliminare quelle colonne o caratteristiche che hanno una percentuale significativa di valori mancanti.. Queste colonne non contengono molte informazioni e possono essere completamente eliminate dal set di dati. Nel nostro caso, eliminiamo tutte quelle colonne che mancano più del 40% di valori. Queste colonne sarebbero build_year, stato, hospital_beds_raion, cafe_sum_500_min_price_avg, cafe_sum_500_max_price_avg e cafe_avg_price_500.
# eliminazione delle colonne con più di 40% null values
_40_pct_missing_cols_list = list(pct_missing_df.loc[pct_missing_df.pct_missing > 40, 'cavolo'].valori)
df.drop(columns=_40_pct_missing_cols_list, inplace=Vero)
Il numero di funzionalità nel nostro set di dati è ora 286.
Imputare i valori persi
I dati mancano ancora dal nostro set di dati. Ora imputeremo i valori mancanti in ogni colonna numerica con il valore mediano di quella colonna.
df_numeric = df.select_dtypes(includi=[np.numero]) numeric_cols = df_numeric.columns.values for col in numeric_cols: mancante = df[col].è zero() num_missing = np.sum(mancante) se num_missing > 0: # impute values only for columns that have missing values med = df[col].Mediare() #impute with the median df[col] = df[col].riempire(Med)
I valori mancanti nelle colonne numeriche sono stati corretti. Nel caso di colonne categoriche, Sostituiremo i valori persi con i valori alla moda di quella colonna.
df_non_numeric = df.select_dtypes(escludi=[np.numero]) non_numeric_cols = df_non_numeric.columns.values for col in non_numeric_cols: mancante = df[col].è zero() num_missing = np.sum(mancante) se num_missing > 0: # impute values only for columns that have missing values mod = df[col].descrivere()['in alto'] # impute with the most frequently occuring value df[col] = df[col].riempire(Mod)
Tutti i valori mancanti nel nostro set di dati sono già stati risolti. Possiamo verificarlo eseguendo il seguente codice:
df.isnull().somma().somma()
Se l'output è zero, significa che ora non ci sono valori mancanti nel nostro set di dati.
Inoltre possiamo sostituire i valori mancanti con un valore particolare (Che cosa -9999 lo scomparso') che indicherà il fatto che i dati mancavano in questo luogo. Questo può essere un sostituto per l'imputazione del valore perso.
Valori atipici
Un outlier è un'osservazione insolita che si discosta dalla maggior parte dei dati. I valori anomali possono influenzare in modo significativo le prestazioni di un modello di apprendimento automatico. Perché, identificare i valori anomali e affrontarli è essenziale.
Prendiamo la colonna "life_sq"’ come esempio. Useremo prima il metodo di descrizione () per guardare le statistiche descrittive e vedere se possiamo raccogliere informazioni da esso.
df.life_sq.describe()
L'output sarà simile a questo:
contare 30446.000000 Significare 33.482658 standard 46.538609 min 0.000000 25% 22.000000 50% 30.000000 75% 38.000000 max 7478.000000 Nome: vita_sq, dtype: float64
di partenza, è chiaro che qualcosa non quadra. Il valore massimo sembra essere anormalmente grande rispetto ai valori medi e mediani. Facciamo un box plot di questi dati per avere un'idea migliore.
df.life_sq.plot(tipo='scatola', figsize=(12, 8)) plt.mostra()
L'output sarà simile a questo:
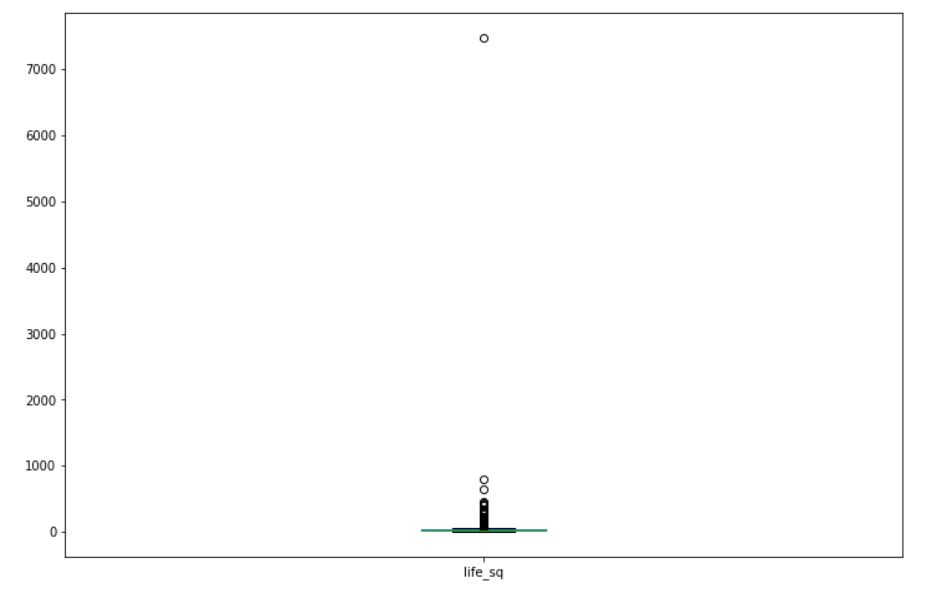
Dal box plot è chiaro che l'osservazione per il valore massimo (7478) è un outlier in questi dati. Statistiche descrittive, il box plotDiagrammi a scatola, Conosciuto anche come diagrammi a scatola e baffi, sono strumenti statistici che rappresentano la distribuzione di un dataset. Questi diagrammi mostrano la mediana, quartili e valori anomali, Consentire la visualizzazione della variabilità e della simmetria dei dati. Sono utili nel confronto tra diversi gruppi e nell'analisi esplorativa, Rendendo più facile identificare tendenze e modelli nei dati.... y los diagramas de dispersión nos ayudan a identificar valores atípicos en los datos.
Possiamo gestire i valori anomali come abbiamo fatto con i valori mancanti. Possiamo eliminare le osservazioni che pensiamo siano valori anomali, oppure possiamo sostituire i valori anomali con valori adeguati, oppure possiamo fare una sorta di trasformazione nei dati (come logaritmo o esponenziale). Nel nostro caso, eliminiamo il record in cui il valore di 'life_sq’ è 7478.
# removing the outlier value in life_sq column
df = df.loc[df.life_sq < 7478]
Record duplicati
Qualche volta, I dati possono contenere valori duplicati. È essenziale cancellare i record duplicati dal set di dati prima di procedere con qualsiasi progetto di apprendimento automatico. Nei nostri dati, Poiché la colonna ID è un identificatore univoco, Verranno rimossi i record duplicati considerando tutti tranne la colonna ID.
# dropping duplicates by considering all columns other than ID
cols_other_than_id = list(df.colonne)[1:]
df.drop_duplicates(subset=cols_other_than_id, inplace=Vero)
Questo ci aiuterà a cancellare i record duplicati. Quando si utilizza il metodo shape, È possibile verificare che i record duplicati siano stati effettivamente eliminati. Il numero di osservazioni è ora 30,434.
Correzione del tipo di dati
Spesso, nel set di dati, I valori non vengono memorizzati nel tipo di dati corretto. Ciò può creare un ostacolo nelle fasi successive e potremmo non ottenere il risultato desiderato o ottenere errori durante l'esecuzione.. Un errore comune nel tipo di dati sono le date. Le date vengono spesso analizzate come oggetti in Python. Esiste un tipo di dati separato per le date in Pandas, chiamato DateTime.
Controlleremo prima il tipo di dati della colonna timestamp nei nostri dati.
df.timestamp.dtype
Questo restituisce il tipo di dati 'oggetto'. Ora sappiamo che il timestamp non è memorizzato correttamente. Per risolvere questo problema, Convertire la colonna Timestamp in formato DateTime.
# converting timestamp to datetime format
df['timestamp'] = pd.to_datetime(DF.TIMESTAMP, formato="%Y-%m-%d")
Ora abbiamo il timestamp nel formato giusto. Allo stesso modo, È possibile che siano presenti colonne in cui i numeri interi vengono memorizzati come oggetti. È essenziale identificare tali caratteristiche e correggere il tipo di dati prima di procedere con l'apprendimento automatico.. fortunati per noi, non abbiamo problemi di questo tipo nel nostro set di dati.
Nota finale
In questo post, Abbiamo discusso alcuni modi di base per pulire i dati in Python prima di iniziare il nostro progetto di machine learning. Dobbiamo identificare e cancellare i valori mancanti, identificare e affrontare gli outlier, cancellare i record duplicati e correggere il tipo di dati di tutte le colonne nel nostro set di dati prima di continuare con il nostro compito AA.
L'autore di questo post è Vishesh Arora. Puoi connetterti con me su LinkedIn.
I media mostrati in questo post sull'accreditamento della lingua dei segni non sono di proprietà di DataPeaker e vengono utilizzati a discrezione dell'autore.





