Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
L'apprendimento automatico è un campo della tecnologia sviluppato con immense competenze e applicazioni nell'automazione delle attività, dove non è necessario alcun intervento umano o programmazione esplicita.
Il potere dell'apprendimento automatico è così grande che possiamo vedere che le sue applicazioni sono di tendenza quasi ovunque nella nostra vita quotidiana.. ML ha resuelto muchos problemas que existían antes y ha hecho que las empresas en el mundo progresen en gran misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.....
Oggi, analizzeremo uno di quei problemi pratici e creeremo una soluzione (modello) da soli usando ML.
Cosa c'è di così eccitante in questo??
Bene, implementeremo il nostro modello costruito utilizzando le applicazioni Flask e Heroku. Alla fine, avremo applicazioni web perfettamente funzionanti nelle nostre mani.
Perché è importante implementare il tuo modello?
I modelli di apprendimento automatico in genere mirano a essere una soluzione a uno o più problemi esistenti. E ad un certo punto della tua vita, devi aver pensato a come il tuo modello sarebbe una soluzione e come le persone lo userebbero?? Infatti, le persone non possono usare direttamente i loro taccuini e il codice, ed è qui che devi implementare il tuo modello.
Puoi implementare il tuo modello, come API o servizio web. Qui stiamo usando il micro-framework Flask. Flask definisce una serie di restrizioni per l'applicazione Web per inviare e ricevere dati.
Attenzione al sistema di previsione dei prezzi
Stiamo per implementare un modello ML per la previsione e l'analisi dei prezzi di vendita delle auto. Questo tipo di sistema è utile per molte persone.
Immagina una situazione in cui hai una vecchia macchina e vuoi venderla. Certo, puoi rivolgerti a un agente per questo e trovare il prezzo di mercato, ma in seguito dovrai pagare di tasca tua per il loro servizio quando vendi la tua auto. Ma, E se potessi conoscere il prezzo di vendita della tua auto senza l'intervento di un agente?? Oppure se sei un agente, questo renderà sicuramente il tuo lavoro più facile. sì, questo sistema ha già appreso da anni dei precedenti prezzi di vendita di varie auto.
Quindi, per essere chiari, Questa applicazione web implementata ti fornirà il prezzo di vendita approssimativo della tua auto in base al tipo di carburante, anni di servizio, il prezzo dello showroom, il numero dei precedenti proprietari, i chilometri percorsi, se sei un distributore / individuale e infine se il tipo di trasmissione è manuale / automatico. E questo è un punto debole.
Qualsiasi tipo di modifica può essere incorporata anche successivamente in questa applicazione. È possibile solo in seguito creare una struttura per incontrare gli acquirenti. Questa è una buona idea per un grande progetto che puoi provare. Puoi implementarlo come un'applicazione come OLA o qualsiasi applicazione di e-commerce. Le applicazioni di Machine Learning non finiscono qui. Nello stesso modo, ci sono infinite possibilità che puoi esplorare. Ma per il momento, lascia che ti aiuti a creare il modello per la previsione del prezzo dell'auto e il suo processo di implementazione.
Importa set di dati
Il set di dati è allegato nella cartella GitHub. Controlla qui
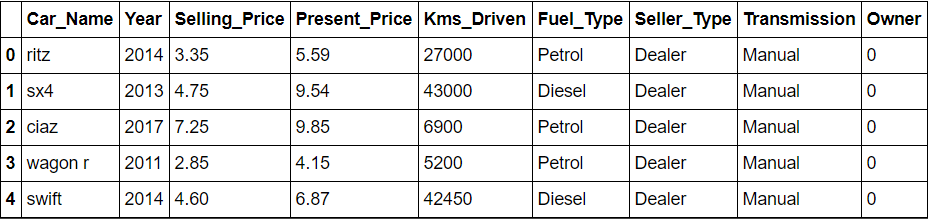
I dati sono costituiti da 300 righe e 9 colonne. Poiché il nostro obiettivo è trovare il prezzo di vendita, l'attributo target ed è anche il prezzo di vendita, le restanti caratteristiche sono prese per analisi e previsioni.
importa numpy come np importa panda come pd data = pd.read_csv(r'C:UtentiSURABHIOneDriveDocumentiprogettidatasetscar.csv') data.head()
Ingegneria delle funzioni
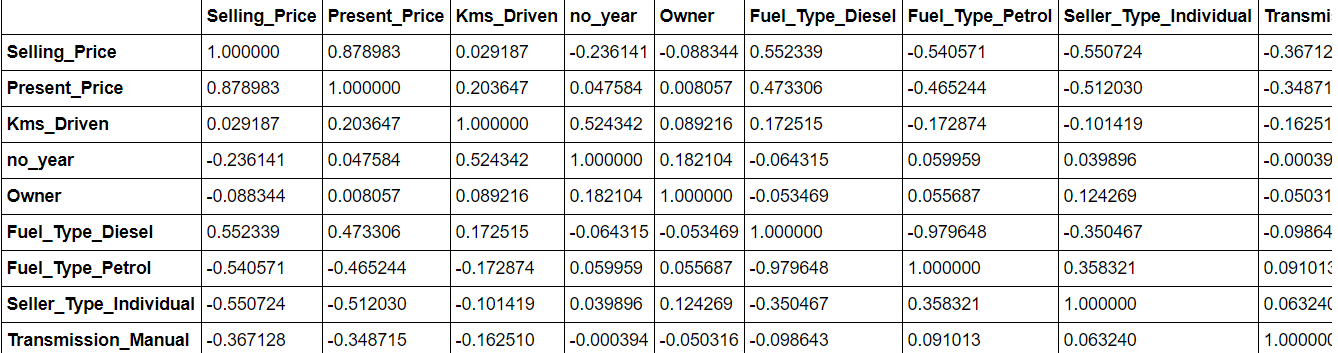
I dati. corretto () ti darà un'idea della correlazione tra tutti gli attributi nel set di dati. È possibile rimuovere più funzioni correlate, in quanto possono causare un adattamento eccessivo del modello.
data = data.drop(['Nome_auto'], asse=1) dati['anno corrente'] = 2020 dati['no_anno'] = dati['anno corrente'] - dati['Anno'] data = data.drop(['Anno','anno corrente'],asse = 1) data = pd.get_dummies(dati,drop_first=Vero) dati = dati[['Prezzo di vendita','Prezzo_Presente','Kms_Driven','no_anno','Proprietario','Tipo_carburante_Diesel','Tipo_carburante_Benzina', 'Seller_Type_Individual','Manuale_Trasmissione']] dati
data.corr()
Prossimo, dividimos los datos en conjuntos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... e test.
x = data.iloc[:,1:] y = data.iloc[:,0]
Scopri l'importanza delle funzioni per eliminare le funzioni indesiderate
La libreria extratressregressor ti permette di vedere l'importanza delle caratteristiche e, così, rimuovere le caratteristiche meno importanti dei dati. Si consiglia sempre di rimuovere la funzione non necessaria perché possono sicuramente produrre punteggi di precisione migliori.
da sklearn.ensemble import ExtreesRegressor modello = ExtraTreesRegressor() model.fit(X,e)

model.feature_importances_
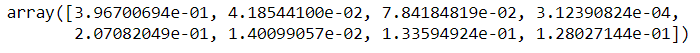
Ottimizzazione degli iperparametri
Questo viene fatto per ottenere i valori ottimali per l'uso nel nostro modello, questo può anche in una certa misura
aiuta a ottenere buoni risultati nella previsione
n_estimatori = [int(X) per x in np.linspace(inizio = 100, stop = 1200,num = 12)] max_features = ['auto','quadrato'] profondità_max = [int(X) per x in np.linspace(5,30,numero = 6)] min_samples_split = [2,5,10,15,100] min_samples_leaf = [1,2,5,10]
griglia = {'n_estimatori': n_estimatori,
'max_caratteristiche': max_features,
'profondità massima': profondità massima,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf}
Stampa(griglia)
# Produzione
{'n_estimatori': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200],
'max_caratteristiche': ['auto', 'quadrato'],
'profondità massima': [5, 10, 15, 20, 25, 30],
'min_samples_split': [2, 5, 10, 15, 100],
'min_samples_leaf': [1, 2, 5, 10]}
Test del treno diviso
da sklearn.model_selection import train_test_split #importing modulo split test treno x_treno, x_test,y_train,y_test = train_test_split(X,e,random_state=0,test_size=0.2)
Addestrare il modello
Abbiamo utilizzato il regressore della foresta casuale per prevedere i prezzi di vendita in quanto si tratta di un problema di regressione e che la foresta casuale utilizza più alberi decisionali e ha mostrato buoni risultati per il mio modello.
da sklearn.ensemble import modello RandomForestRegressor = RandomForestRegressor()
hyp = RandomizedSearchCV(stimatore = modello,
param_distributions=grid,
n_iter=10,
punteggio= 'neg_mean_squared_error'
cv=5, verboso = 2,
random_state = 42,n_jobs = 1)
hyp.fit(x_treno,y_train)
hyp è un modello creato utilizzando gli iperparametri ottimali ottenuti tramite la convalida incrociata della ricerca casuale
Produzione
Ora usiamo finalmente il modello per prevedere il set di dati del test.
y_pred = hyp.predict(x_test) y_pred

Per utilizzare il framework Flask per la distribuzione, è necessario impacchettare tutto questo modello e importarlo in un file Python per creare applicazioni web. Perciò, scarichiamo il nostro modello nel file pickle usando il codice dato.
importare sottaceti
file = aperto("file.pkl", "wb") # apertura di un nuovo file in modalità di scrittura
sottaceto.discarica(hyp, file) # scaricare il modello creato in un file pickle
Codice completo
https://github.com/SurabhiSuresh22/Car-Price-Prediction/blob/master/car_project.ipynb
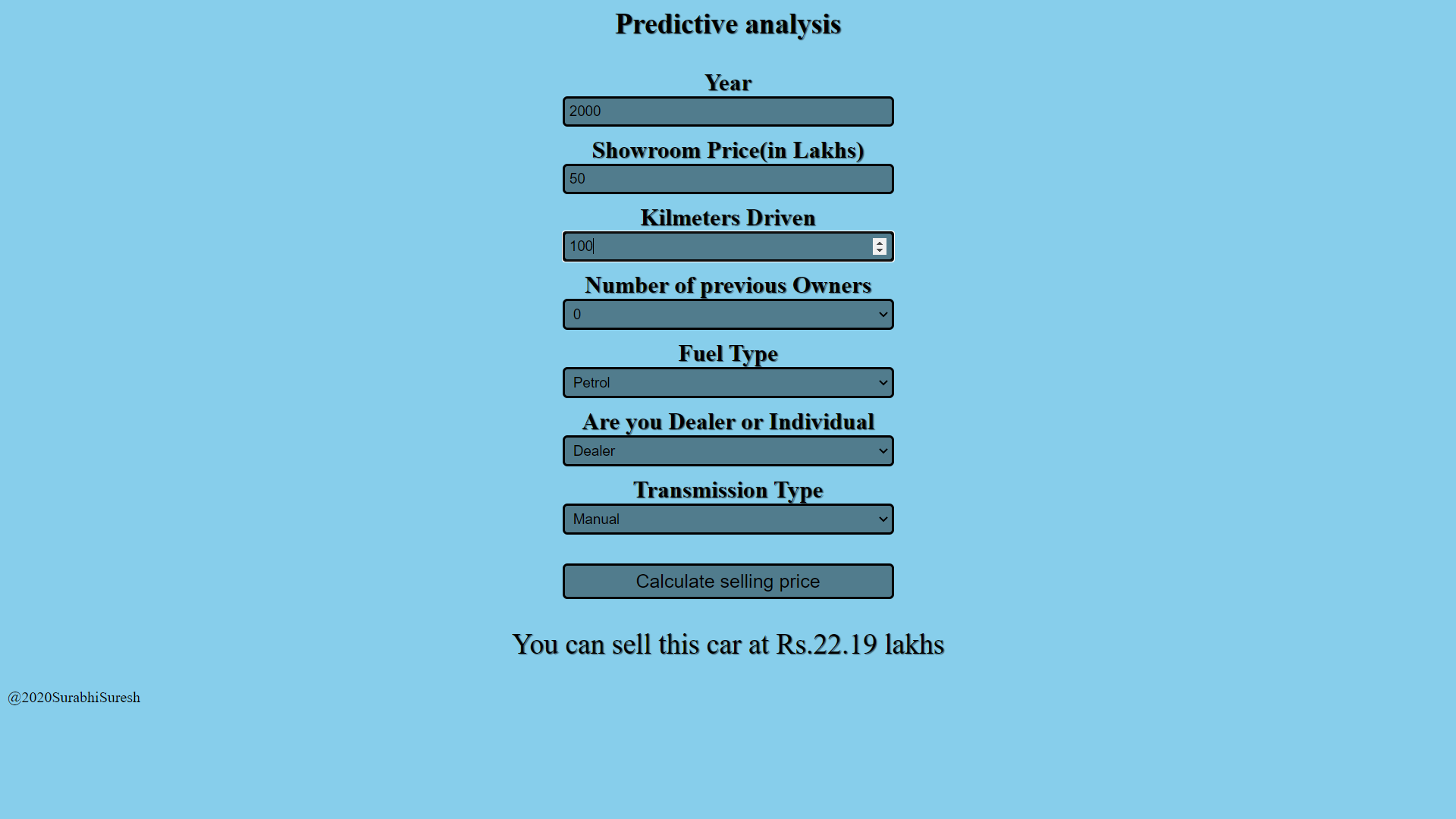
Cornice del pallone
Quello di cui abbiamo bisogno è un'applicazione web che contenga un modulo per prendere l'input dell'utente e restituire le previsioni del modello. Quindi, svilupperemo una semplice applicazione web per questo. L'interfaccia è realizzata utilizzando semplici HTML e CSS. Ti consiglio di rivedere le basi dello sviluppo web per capire il significato del codice scritto per l'interfaccia. Sarebbe anche bello se conoscessi il telaio della fiaschetta. Attraverso è il video se non conosci FLASK.
Lascia che ti spieghi, brevemente, cosa ho codificato usando FLASK.
Quindi, iniziamo il codice importando tutte le librerie richieste usate qui.
from flask import Flask, render_template, richiesta importare sottaceti richieste di importazione importa numpy come np
Come lo sai, dobbiamo importare il modello salvato qui per fare previsioni dai dati forniti dall'utente. Quindi stiamo importando il modello salvato
modello = pickle.load(aprire("modello.pkl", "rb"))
Ora andiamo al codice per creare l'applicazione flask vera e propria.
app = Flask(_nome_)
@app.route("/") # questo ci indirizzerà alla home page quando facciamo clic sul collegamento dell'app Web
def home():
return render_template("home.html") # home page
@app.route("/prevedere", metodi = ["INVIARE"]) # funziona quando l'utente fa clic sul pulsante di previsione
def predire():
anno = int(modulo di richiesta["anno"]) # prendendo l'input dell'anno dall'utente
tot_year = 2020 - anno
prezzo_presente = flottante(modulo di richiesta["presente_prezzo"]) #prendendo il presente premio
fuel_type = request.form["tipo di carburante"] # tipo di carburante dell'auto
# if ciclo per l'assegnazione di valori numerici
se tipo_carburante == "Benzina":
carburante_P = 1
carburante_D = 0
altro:
carburante_P = 0
carburante_D = 1
kms_driven = int(modulo di richiesta["kms_driven"]) # chilometri totali percorsi dall'auto
trasmissione = request.form["trasmissione"] # tipo di trasmissione
# assegnazione di valori numerici
se trasmissione == "Manuel":
trasmissione_manuale = 1
altro:
trasmissione_manuale = 0
seller_type = request.form["tipo_venditore"] # tipo di venditore
se tipo_venditore == "Individuale":
venditore_individuo = 1
altro:
venditore_individuo = 0
proprietario = int(modulo di richiesta["proprietario"]) # numero di proprietari
valori = [[
presente_prezzo,
kms_driven,
proprietario,
tot_year,
carburante_D,
carburante_P,
venditore_individuo,
trasmissione_manuale
]]
# ha creato un elenco di tutti i valori immessi dall'utente, quindi usandolo per la previsione
predizione = modello.predizione(valori)
pronostico = round(predizione[0],2)
# restituendo il valore previsto per visualizzarlo nell'applicazione Web front-end
return render_template("home.html", pred = "Il prezzo dell'auto è {} Lakh".formato(galleggiante(predizione)))
se _nome_ == "_principale_":
app.run(debug = True)
Implementazione con Heroku
Tutto quello che devi fare è connettere il tuo repository GitHub contenente tutti i file necessari per il progetto con Heroku. Per tutti coloro che non sanno cosa sia Heroku, Heroku è una piattaforma che consente agli sviluppatori di creare, eseguire e gestire applicazioni cloud.
Questo è il link all'applicazione web che ho creato utilizzando la piattaforma Heroku. Quindi, abbiamo visto il processo di costruzione e implementazione di un modello di machine learning. Puoi farlo anche tu, impara di più e sentiti libero di provare cose nuove e svilupparle.
https://car-price-analysis-app.herokuapp.com/
conclusione
Quindi, abbiamo visto il processo di costruzione e implementazione di un modello di machine learning. Puoi farlo anche tu, impara di più e sentiti libero di provare cose nuove e svilupparle. Sentiti libero di connetterti con me su collegato in.
Grazie
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





