Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.

Credito: https://gifer.com/en/GxlE
Il 2 preguntas principales que surgieron en mi mente mientras trabajaba en este artículo fueron “¿Por qué estoy escribiendo este artículo?” & “¿En qué se diferencia mi artículo de otros artículos?” Bene, la función de costo es un concepto importante de entender en los campos de la ciencia de datos, pero mientras seguía mi posgrado, me di cuenta de que los recursos disponibles en línea son demasiado generales y no cubren mis necesidades por completo.
Tuve que consultar muchos artículos y ver algunos videos en YouTube para tener una idea de las funciones de costos. Di conseguenza, quería reunir las funciones “Quella”, “Cuándo”, “Come” e “Come mai” de Cost que pueden ayudar a explicar este tema con mayor claridad. ¡Espero que mi artículo actúe como una ventanilla única para las funciones de costos!
Guía ficticia de la función de coste 🤷♀️
Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e...: se utiliza cuando nos referimos al error de un solo ejemplo de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.....
Funzione di costo: se utiliza para hacer referencia a un promedio de las funciones de pérdida en un conjunto de datos de entrenamiento completo.
Ma, ¿* por qué * usar una función de costo?
¿Por qué demonios necesitamos una función de costos? Considere un escenario en el que deseamos clasificar los datos. Supongamos que tenemos los detalles de altura y peso de algunos perros y gatos. Usemos estas 2 características para clasificarlas correctamente. Si trazamos estos registros, obtenemos el siguiente Diagramma di dispersioneIl grafico a dispersione è uno strumento grafico utilizzato in statistica per visualizzare la relazione tra due variabili. Consiste in un insieme di punti in un piano cartesiano, dove ogni punto rappresenta una coppia di valori corrispondenti alle variabili analizzate. Questo tipo di grafico consente di identificare i modelli, Tendenze e possibili correlazioni, facilitare l'interpretazione dei dati e il processo decisionale sulla base delle informazioni visive presentate....:
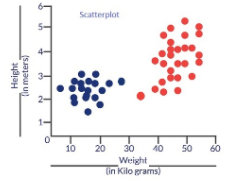
Fig 1: Diagrama de dispersión para la altura y el peso de varios perros y gatos
Los puntos azules son gatos y los puntos rojos son perros. A continuación se presentan algunas soluciones al problema de clasificación anterior.
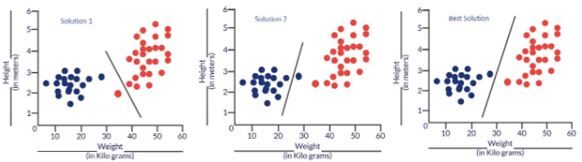
Fig: Soluciones probables a nuestro problema de clasificación
Essenzialmente, los tres clasificadores tienen una precisión muy alta, pero la tercera solución es la mejor porque no clasifica erróneamente ningún punto. La razón por la que clasifica todos los puntos a la perfección es que la línea está casi exactamente entre los dos grupos y no más cerca de ninguno de los grupos. Aquí es donde entra el concepto de función de costo. La función de costo nos ayuda a alcanzar la solución óptima. La función de costo es la técnica de evaluar “el desempeño de nuestro algoritmo / modello”.
Toma tanto los resultados previstos por el modelo como los resultados reales, y calcula cuánto se equivocó el modelo en su predicción. Produce un número más alto si nuestras predicciones difieren mucho de los valores reales. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que ajustamos nuestro modelo para mejorar las predicciones, la función de costo actúa como un indicador de cómo ha mejorado el modelo. Este es esencialmente un problema de optimización. Las estrategias de optimización siempre apuntan a “minimizar la función de costes”.
Tipos de función de costes
Hay muchas funciones de costos en el aprendizaje automático y cada una tiene sus casos de uso dependiendo de si se trata de un problema de regresión o de clasificación.
- Función de costo de regresión
- Funciones de costo de clasificación binaria
- Funciones de costos de clasificación de clases múltiples
1. Función de costo de regresión:
Los modelos de regresión tratan de predecir un valor continuo, ad esempio, lo stipendio di un dipendente, el precio de un automóvil, la predicción de un préstamo, eccetera. Una función de costo utilizada en el problema de regresión se llama “Función de costo de regresión”. Se calculan sobre el error basado en la distancia de la siguiente manera:
Error = y-y ‘
In cui si,
E – Entrada real
Y ‘- Salida prevista
Las funciones de costo de regresión más utilizadas se encuentran a continuación,
1.1 Error medio (ME)
- En esta función de costo, se calcula el error para cada dato de entrenamiento y luego se deriva el valor medio de todos estos errores.
- Calcular la media de los errores es la forma más sencilla e intuitiva posible.
- Los errores pueden ser tanto negativos como positivos. Perciò, pueden cancelarse entre sí durante la suma, lo que da un error medio cero para el modelo.
- Perciò, esta no es una función de costo recomendada, pero sienta las bases para otras funciones de costo de los modelos de regresión.
1.2 Root errore quadratico medio (MSE)
- Esto mejora el inconveniente que encontramos en el error medio anterior. Aquí se calcula un cuadrado de la diferencia entre el valor real y el predicho para evitar cualquier posibilidad de error negativo.
- Se mide como el promedio de la suma de las diferencias al cuadrado entre las predicciones y las observaciones reales.
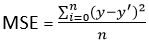
MSE = (suma de errores cuadrados) / n
- También se conoce como pérdida L2.
- In MSE, dado que cada error se eleva al cuadrado, ayuda a penalizar incluso pequeñas desviaciones en la predicción en comparación con MAE. Pero si nuestro conjunto de datos tiene valores atípicos que contribuyen a errores de predicción más grandes, entonces cuadrar este error aún más magnificará el error muchas veces más y también conducirá a un error de MSE más alto.
- Perciò, podemos decir que es menos robusto a los valores atípicos.
1.3 Errore assoluto medio (Amico)
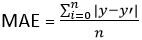
MAE = (suma de errores absolutos) / n
2. Funciones de costo para problemas de clasificación
Las funciones de costo que se usan en los problemas de clasificación son diferentes de las que usamos en el problema de regresión. Una función de pérdida comúnmente utilizada para la clasificación es la pérdida de entropía cruzada. Entendamos la entropía cruzada con un pequeño ejemplo. Considere que tenemos un problema de clasificación de 3 clases como sigue.
Classe (arancia, Mela, tomate)
El modelo de aprendizaje automático dará una distribución de probabilidad de estas 3 clases como salida para un dato de entrada dado. La clase con mayor probabilidad se considera una clase ganadora para la predicción.
Salida = [P(arancia),P(Mela),P(Tomato)]
La distribución de probabilidad real para cada clase se muestra a continuación.
Naranja = [1,0,0]
Manzana = [0,1,0]
Tomate = [0,0,1]
Si durante la fase de entrenamiento, la clase de entrada es Tomate, la distribución de probabilidad predicha debería tender hacia la distribución de probabilidad real de Tomate. Si la distribución de probabilidad predicha no se acerca más a la real, el modelo debe ajustar su peso. Aquí es donde la entropía cruzada se convierte en una herramienta para calcular qué tan lejos está la distribución de probabilidad predicha de la real. In altre parole, la entropía cruzada se puede considerar como una forma de medir la distancia entre dos distribuciones de probabilidad. La siguiente imagen ilustra la intuición detrás de la entropía cruzada:
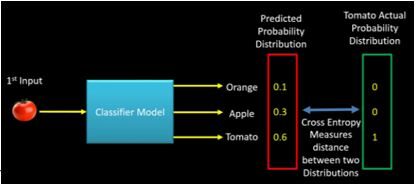
FIGURA"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... 3: Intuición detrás de croos-entropía (credito – machinelearningknowledge.ai)
Esto fue solo una intuición detrás de la entropía cruzada. Tiene su origen en la teoría de la información. Ora, con esta comprensión de la entropía cruzada, veamos ahora las funciones de costo de clasificación.
2.1 Funciones de costos de clasificación de clases múltiples
Esta función de costo se usa en los problemas de clasificación donde hay múltiples clases y los datos de entrada pertenecen a una sola clase. Entendamos ahora cómo se calcula la entropía cruzada. Supongamos que el modelo da la distribución de probabilidad como se muestra a continuación para ‘n’ clases y para un dato de entrada particular D.
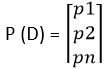
Y la distribución de probabilidad real o objetivo de los datos D es
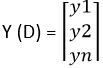
Dopo, la entropía cruzada para ese dato particular D se calcula como
Pérdida de entropía cruzada (e, P) = – eT Registrazione (P)
= – (e1 tronco d'albero (P1) + e2 tronco d'albero (P2) + …… yNord tronco d'albero (PNord))
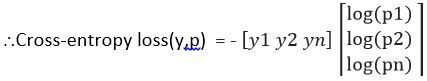
Definamos ahora la función de costo usando el ejemplo anterior (Consulte la imagen de entropía cruzada -Fig3),
P (tomate) = [0.1, 0.3, 0.6]
e (tomate) = [0, 0, 1]
Entropia incrociata (e, P) = – (0 * Log (0.1) + 0 * Log (0.3) + 1 * Log (0.6)) = 0.51
La fórmula anterior solo mide la entropía cruzada para una sola observación o datos de entrada. El error en la clasificación del modelo completo viene dado por la entropía cruzada categórica, que no es más que la media de la entropía cruzada para todos los N datos de entrenamiento.
Entropía cruzada categórica = (Suma de entropía cruzada para N datos) / n
2.2 Función de costo de entropía cruzada binaria
La entropía cruzada binaria es un caso especial de entropía cruzada categórica cuando solo hay una salida que simplemente asume un valor binario de 0 oh 1 para denotar la clase negativa y positiva respectivamente. Ad esempio, clasificación entre gato y perro.
Supongamos que la salida real se denota por una sola variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... e, luego la entropía cruzada para un dato particular D se puede simplificar de la siguiente manera:
Entropia incrociata (D) = – e * tronco d'albero (P) cuando y = 1
Entropia incrociata (D) = – (1-e) * tronco d'albero (1-P) cuando y = 0
El error en la clasificación binaria para el modelo completo viene dado por la entropía cruzada binaria, que no es más que la media de la entropía cruzada para todos los N datos de entrenamiento.
Entropía cruzada binaria = (Suma de entropía cruzada para N datos) / n
conclusione
¡Espero que este artículo le haya resultado útil! Déjeme saber lo que piensa, especialmente si hay sugerencias para mejorar. Puoi connetterti con me su LinkedIn: https://www.linkedin.com/in/saily-shah/ y aquí está mi perfil de GitHub: https://github.com/sailyshah
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





