Panoramica
- Impara il web scraping in Python usando la libreria BeautifulSoup
- Il Web Scraping è una tecnica utile per convertire i dati non strutturati sul Web in dati strutturati
- BeautifulSoup è un'efficiente libreria disponibile in Python per eseguire scratch web diversi da urllib
- È necessaria una conoscenza di base dei tag HTML e HTML per eseguire il web scraping in Python
introduzione
La necessità e l'importanza di estrarre dati dal web sta diventando sempre più forte e chiara. Ogni poche settimane, Sono in una situazione in cui abbiamo bisogno di estrarre dati dal web per costruire un modello di apprendimento automatico.
Ad esempio, La scorsa settimana stavamo pensando di creare un indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... prurito e sensazione per diversi corsi di data science disponibile su internet. Ciò non richiederebbe solo la ricerca di nuovi corsi!, ma cerca anche sul web le tue recensioni e poi riassumile in alcune metriche!
Questo è uno dei problemi / prodotti la cui efficacia dipende maggiormente dal web scraping e dall'estrazione di informazioni (raccolta dati) quale delle tecniche utilizzate per riassumere i dati.
Nota: Abbiamo anche creato un corso gratuito per questo articolo: Introduzione al web scraping con Python. Questo formato strutturato ti aiuterà a imparare meglio.
Modi per estrarre informazioni dal web
Esistono diversi modi per estrarre informazioni dal web. Uso di APIè probabilmente il modo migliore per estrarre dati da un sito web. Quasi tutti i grandi siti web come Twitter, Facebook, Google, Twitter, StackOverflow fornisce API per accedere ai tuoi dati in modo più strutturato. Se riesci a ottenere ciò di cui hai bisogno tramite un'API, è quasi sempre l'approccio preferito rispetto al web scraping. Questo perché se accedi ai dati strutturati dal provider, Perché vorresti creare un motore per estrarre le stesse informazioni??
purtroppo, non tutti i siti web forniscono un'API. Alcuni lo fanno perché non vogliono che i lettori estraggano molte informazioni in modo strutturato, mentre altri non forniscono API a causa della mancanza di conoscenze tecniche. Cosa fai in questi casi? Bene, dobbiamo raschiare il sito Web per ottenere le informazioni.
Potrebbero esserci altri modi come i feed RSS, ma il suo uso è limitato e, così, Non li includerò nella discussione qui.

Cos'è il web scraping??
Il web scraping è una tecnica software per l'estrazione di informazioni dai siti Web. Questa tecnica è principalmente focalizzata sulla trasformazione di dati non strutturati (formato HTML) sul web in dati strutturati (Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... o foglio di calcolo).
Puoi eseguire il web scraping in vari modi, compreso l'uso di Google Docs in quasi tutti i linguaggi di programmazione. Mi rivolgerei a Python per la sua semplicità e il suo ricco ecosistema. Ha una biblioteca conosciuta come "BeautifulSoup"’ cosa aiuta in questo compito. In questo articolo, ti mostrerò il modo più semplice per imparare il web scraping usando la programmazione Python.
Per quelli di voi che hanno bisogno di un modo non di programmazione per estrarre informazioni dalle pagine web, possono anche guardare import.io . Fornisce un'interfaccia guidata dalla GUI per eseguire tutte le operazioni di scraping web di base. Gli hacker possono continuare a leggere questo articolo!!
Librerie necessarie per il web scraping
Come sappiamo, Chiodo è un linguaggio di programmazione open source. Puoi trovare molte librerie per eseguire una funzione. Perciò, devi trovare la migliore libreria da usare. preferisco Bella zuppa (Libreria Python), in quanto è facile ed intuitivo lavorarci sopra. Precisamente, userò due moduli Python per raschiare i dati:
- Urllib2: È un modulo Python che può essere utilizzato per cercare URL. Definisci funzioni e classi per aiutare con le azioni URL (autenticazione di base e sommaria, reindirizzamenti, biscotti, eccetera.). Per ulteriori dettagli, vedere il pagina della documentazione. Nota: urllib2 è il nome della libreria inclusa in Python 2. Anziché, puoi usare la libreria urllib.request inclusa con python 3. La libreria urllib.request funziona nello stesso modo in cui funziona urllib.request in Python 2. Perchè è già incluso non c'è bisogno di installare.
- bellazuppa: È uno strumento incredibile per estrarre informazioni da una pagina web. Puoi usarlo per estrarre tabelle, liste, paragrafo e puoi anche mettere filtri per estrarre informazioni dalle pagine web. In questo articolo, useremo l'ultima versione di BeautifulSoup 4. Puoi fare riferimento alle istruzioni di installazione nel tuo pagina della documentazione.
BeautifulSoup non cerca nel sito per noi. Perché, Uso urllib2 in combinazione con la libreria BeautifulSoup.
Chiodo ha molte altre opzioni per lo scraping HTML oltre a BeatifulSoup. Eccone altri:
Concetti basilari: familiarizzare con l'HTML (etichette)
Mentre facciamo il robusto web, ci occupiamo dei tag html. Perciò, dobbiamo capirli bene. Se conosci già le basi dell'HTML, puoi saltare questa sezione. Di seguito è riportata la sintassi di base dell'HTML: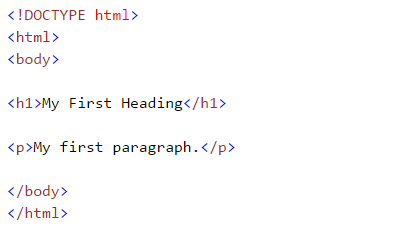 Questa sintassi ha diversi tag che sono dettagliati di seguito:
Questa sintassi ha diversi tag che sono dettagliati di seguito:
- : I documenti HTML devono iniziare con una dichiarazione di tipo
- Il documento HTML è contenuto tra e
- La parte visibile del documento HTML è tra e
- Le intestazioni HTML sono definite con il
per etichette - I paragrafi HTML sono definiti con il etichetta
Altri tag HTML utili sono:
- I collegamenti HTML sono definiti con il etichetta, “<un href =“Http://www.test.com”>Questo è un link per test.com</un> "
- Le tabelle HTML sono definite con
, fila come
e le righe sono suddivise in dati come 
- L'elenco HTML inizia con
- (disordinato) e
- Importa le librerie richieste:
- (pulito). Ogni elemento nell'elenco inizia con
Se non conosci questi tag HTML, Ti consiglierei anche di controllare Tutorial HTML di W3schools. Questo ti darà una chiara comprensione dei tag HTML.
Raschiare una pagina web usando BeautifulSoup
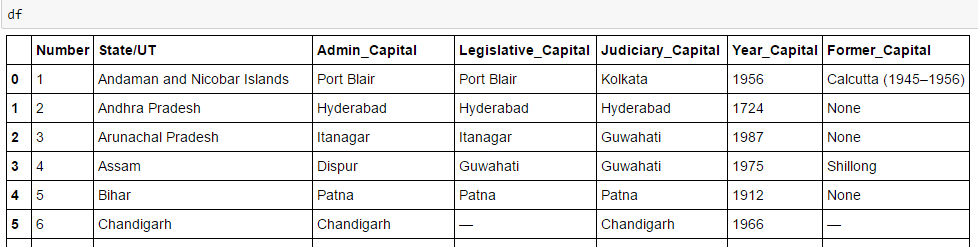
Qui, Sto estraendo dati da a Pagina di Wikipedia. Il nostro obiettivo finale è estrarre un elenco di capitali statali e territoriali dell'Unione in India. E alcuni dettagli di base come la struttura, la vecchia capitale e altri formano questo pagina wikipedia. Impariamo facendo questo progetto passo dopo passo:
#importare la libreria utilizzata per interrogare un sito web import urllib2 #se stai usando la versione python3+, import urllib.request
#specificare l'url wiki = "https://en.wikipedia.org/wiki/List_of_state_and_union_territory_capitals_in_India"
#Interroga il sito web e riporta l'html alla variabile 'page' pagina = urllib2.urlopen(wiki) #Per pitone 3 usa urllib.request.urlopen(wiki)
#importare le funzioni di Beautiful Soup per analizzare i dati restituiti dal sito web da bs4 import BeautifulSoup
#Analizza l'html nella variabile 'page', e conservalo nel formato Beautiful Soup zuppa = zuppa bella(pagina)
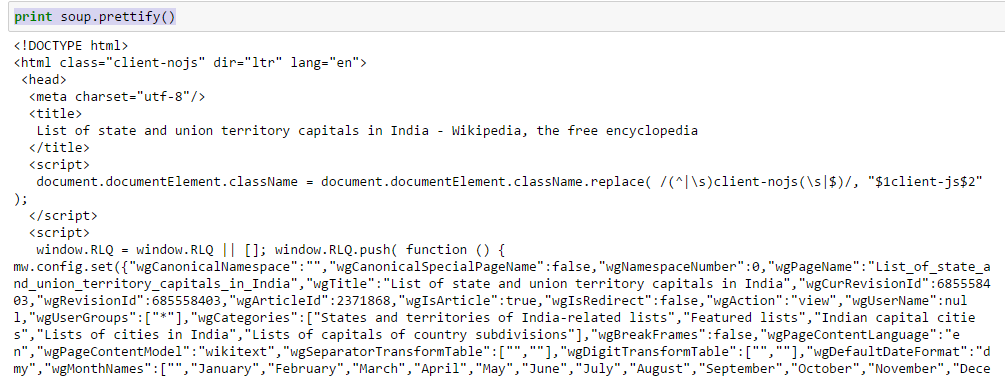
- Usa la funzione “abbellire” per vedere la struttura annidata della pagina HTML
 Al di sopra, puoi vedere quella struttura dei tag HTML. Questo ti aiuterà a conoscere i diversi tag disponibili e come puoi giocare con loro per estrarre informazioni.
Al di sopra, puoi vedere quella struttura dei tag HTML. Questo ti aiuterà a conoscere i diversi tag disponibili e come puoi giocare con loro per estrarre informazioni.
- Lavora con i tag HTML
- la minestra. : Restituisce il contenuto tra il tag di apertura e chiusura, compresa l'etichetta.
In[30]:zuppa.titolo Fuori[30]:<titolo>Elenco delle capitali dello stato e del territorio dell'Unione in India - Wikipedia, l'enciclopedia libera</titolo>
- la minestra. .corda: Stringa di ritorno all'interno del tag dato
In [38]:la minestra.titolo.corda Fuori[38]:u'Elenco delle capitali di stato e territorio dell'Unione in India - Wikipedia, l'enciclopedia libera'
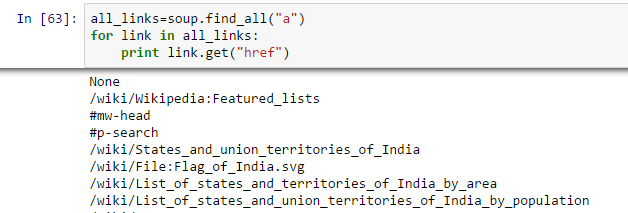
- Trova tutti i link all'interno dei tag della pagina :: Lo sappiamo, possiamo taggare un collegamento usando il tag ““. Quindi, dovremmo andare con l'opzione la minestra. un e deve restituire i link disponibili sul sito web. Facciamolo.
In [40]:la minestra.un Fuori[40]:<un id="superiore"></un>
Al di sopra, puoi vedere che abbiamo solo una via d'uscita. Ora, per estrarre tutti i collegamenti all'interno , noi useremo “trova tutto().

Al di sopra, mostra tutti i link, compresi i titoli, link e altre informazioni. Ora, per mostrare solo i link, dobbiamo iterare su ogni tag a e quindi restituire il collegamento utilizzando l'attributo “href” insieme a ottenere.

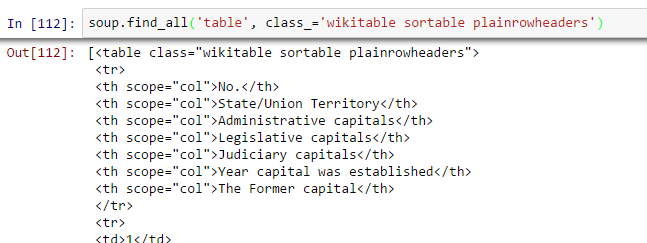
- Trova il tavolo giusto: Come cerchiamo una tabella per estrarre informazioni sulle capitali degli stati, dobbiamo prima identificare la tabella corretta. Scriviamo il comando per estrarre informazioni all'interno di tutto mesa etichette.
all_tables=soup.find_all('tavolo')Ora, per identificare la tabella corretta, useremo l'attributo “classe” dalla tabella e la useremo per filtrare la tabella corretta. In Chrome, puoi controllare il nome della classe facendo clic con il pulsante destro del mouse sulla tabella richiesta della pagina web -> Ispeziona elemento -> Copia il nome della classe O vai all'output del comando sopra e trova il nome della classe dalla tabella giusta.
right_table=zuppa.trova('tavolo', class_='wikitable ordinabili plainrowheaders') tavola_destra Al di sopra, siamo in grado di identificare la tabella giusta.
Al di sopra, siamo in grado di identificare la tabella giusta. - Estrai le informazioni in DataFrame: Qui, dobbiamo scorrere ogni riga (vero) e poi assegna ogni elemento di tr (td) a uno variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... e aggiungerlo a un elenco. Diamo prima un'occhiata alla struttura HTML della tabella (Non estrarrò informazioni per l'intestazione della tabella
)  Al di sopra, potresti notare che il secondo elemento di
Al di sopra, potresti notare che il secondo elemento di
è dentro l'etichetta , no , quindi dobbiamo occuparci di questo. Ora, per accedere al valore di ogni elemento, useremo l'opzione “Cercare (testo = vero)” con ogni elemento. Vediamo il codice: #Genera liste A=[] B=[] C=[] D=[] E=[] F=[] G=[] per riga in right_table.findAll("vero"): celle = riga.trovaTutto('td') stati=riga.trovaTutto('ns') #Per memorizzare i dati della seconda colonna se len(cellule)==6: #Estrai solo il corpo della tabella senza intestazione A.append(cellule[0].trova(testo=Vero)) B.append(stati[0].trova(testo=Vero)) C.append(cellule[1].trova(testo=Vero)) D.append(cellule[2].trova(testo=Vero)) E.append(cellule[3].trova(testo=Vero)) F.append(cellule[4].trova(testo=Vero)) G.append(cellule[5].trova(testo=Vero))#importa panda per convertire l'elenco in frame di dati importa panda come pd df=pd.DataFrame(UN,colonne=['Numero']) df['Stato/UT']=B df['Capitale_Ammin']=C df['Legislative_Capital']=D df["Capitale_giudiziario"]= E df['Anno_Capitale']=F df['Ex_Capitale']=G df
Finalmente, abbiamo dati nel frame di dati:

Nello stesso modo, puoi eseguire altri tipi di web scraping usando “Bella zuppa“. Ciò ridurrà i tuoi sforzi manuali per raccogliere i dati della pagina web.. Puoi anche guardare gli altri attributi come .parent, .Contenuti, .discendenti y .next_sibling, .prev_sibling e vari attributi per navigare usando il nome del tag. Questi ti aiuteranno a rimuovere le pagine web in modo efficace.Ma, Perché non posso usare l'espressione regolare??
Ora, se conosci le espressioni regolari, potresti pensare di poter scrivere codice usando regex che può fare lo stesso per te. Avevo sicuramente questa domanda. Nella mia esperienza con BeautifulSoup e regex per fare lo stesso, ho scoperto:
- Il codice scritto in BeautifulSoup è solitamente più robusto del codice scritto con espressioni regolari. I codici scritti con espressioni regolari dovrebbero essere modificati con qualsiasi modifica alle pagine. Anche BeautifulSoup ne ha bisogno in alcuni casi, è solo che BeautifulSoup è relativamente migliore.
- Le espressioni regolari sono molto più veloci di BeautifulSoup, generalmente di un fattore 100 per dare lo stesso risultato.
Perciò, si riduce alla velocità rispetto alla robustezza del codice e non esiste un vincitore universale qui. Se le informazioni che stai cercando possono essere estratte con semplici dichiarazioni regex, devi andare avanti e usarli. Per quasi tutti i lavori complessi, In genere consiglio BeautifulSoup più delle espressioni regolari.
Nota finale
In questo articolo, analizziamo i metodi di web scraping che usano “bellazuppa” e “urllib2” e Python. Abbiamo anche esaminato le basi dell'HTML ed eseguito il web scraping passo dopo passo mentre risolvevamo una sfida.. Ti consiglio di esercitarti e di usarlo per raccogliere dati dalle pagine web.
Trovi utile questo articolo? Condividi le tue opinioni / pensieri nella sezione commenti qui sotto.
Nota: Abbiamo anche creato un corso gratuito per questo articolo: Introduzione al web scraping con Python. Questo formato strutturato ti aiuterà a imparare meglio.
Se ti piace quello che hai appena letto e vuoi continuare a imparare l'analisi, iscriviti alle nostre email, Seguici su Twitter o come il nostro pagina Facebook.
Imparentato




- L'elenco HTML inizia con

 Al di sopra, puoi vedere quella struttura dei tag HTML. Questo ti aiuterà a conoscere i diversi tag disponibili e come puoi giocare con loro per estrarre informazioni.
Al di sopra, puoi vedere quella struttura dei tag HTML. Questo ti aiuterà a conoscere i diversi tag disponibili e come puoi giocare con loro per estrarre informazioni.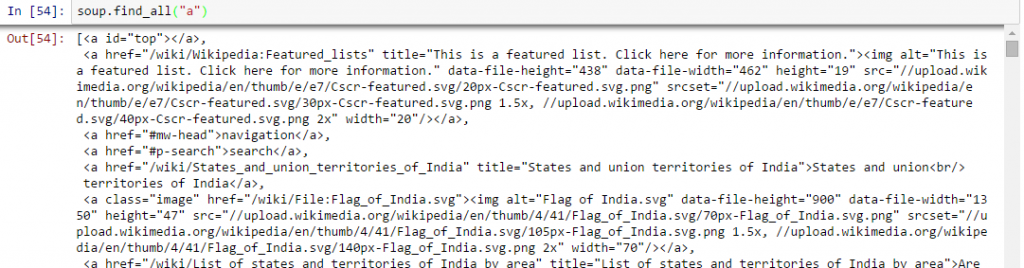
 Al di sopra, siamo in grado di identificare la tabella giusta.
Al di sopra, siamo in grado di identificare la tabella giusta.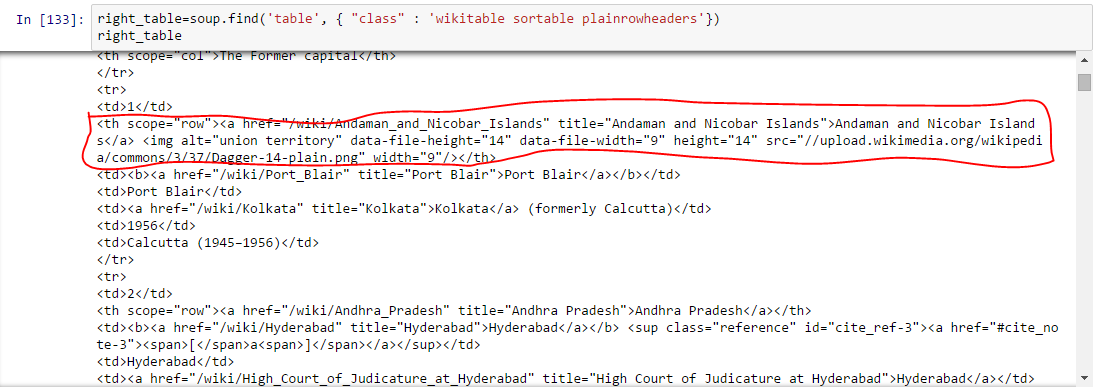 Al di sopra, potresti notare che il secondo elemento di
Al di sopra, potresti notare che il secondo elemento di