introduzione
Oggi, le organizzazioni gestiscono una grande quantità e un'ampia varietà di dati: chiamate dei clienti, le tue email, tweet, dati dell'app mobile e altro. Ci vuole molto tempo e impegno perché questi dati siano utili. Una delle abilità di base per estrarre informazioni dai dati di testo è l'elaborazione del linguaggio naturale (PNL).
Elaborazione del linguaggio naturale (PNL) è l'arte e la scienza che ci aiutano a estrarre informazioni dal testo e ad usarle nei nostri calcoli e algoritmi. Visto l'aumento dei contenuti su Internet e sui social network, è uno dei must-have per tutti i data scientist.
Che tu conosca o meno la PNL, questa guida dovrebbe aiutarti come riferimento pronto per te. Attraverso questa guida, Ti ho fornito risorse e codici per eseguire le attività più comuni in PNL.
Dopo aver letto questa guida, sentiti libero di dare un'occhiata al nostro video corso sull'elaborazione del linguaggio naturale (PNL).

Perché ho creato questa guida?
Dopo aver lavorato per un po' di tempo sui problemi di PNL, Mi sono imbattuto in varie situazioni in cui avevo bisogno di consultare centinaia di fonti diverse per studiare gli ultimi sviluppi sotto forma di articoli di ricerca, blog e concorsi per alcune delle attività comuni di PNL. .
Quindi, Ho deciso di raccogliere tutte queste risorse in un unico posto e renderlo una soluzione completa per le risorse più recenti e più importanti per queste attività comuni di PNL.. Di seguito è riportato l'elenco delle attività trattate in questo articolo insieme alle relative risorse.. Cominciamo.
Sommario
- Derivato
- Lematizzazione
- Incorporamenti di parole
- Etichettare una parte del discorso
- Disambiguazione dell'entità denominata
- Riconoscimento entità nominative
- Analisi del sentimento
- Somiglianza semantica del testo
- Identificazione della lingua
- Riepilogo del testo
1. Derivato
Cos'è Stemming? ?: La derivazione è il processo di riduzione delle parole (generalmente modificato o derivato) alla sua radice o radice della parola. Lo scopo della radice è ridurre le parole legate alla stessa radice, anche se la radice non è una parola del dizionario. Ad esempio, in lingua inglese-
- bella e splendidamente sono derivati da bella
- meglio e meglio sono derivati da meglio e meglio rispettivamente
Carta: il articolo originale di Martin Porter nell'algoritmo di Porter per derivare.
Algoritmo: Ecco l'implementazione Python dell'algoritmo di derivazione Porter2.
Implementazione: Ecco come puoi derivare una parola usando l'algoritmo Porter2 dal alla deriva Biblioteca.
2. Lematizzazione
Che cosa sta derivando? ?: Lo stemming è il processo di riduzione di un gruppo di parole al suo motto o alla forma del dizionario. Tiene conto di cose come POS (Parti del discorso), il significato della parola nella frase, il significato della parola in frasi chiuse, eccetera. prima di ridurre la parola al tuo motto. Ad esempio, in lingua inglese-
- bella e splendidamente sono slogan per bella e splendidamente rispettivamente.
- Buona, meglio e meglio sono slogan per Buona, Buona e Buona rispettivamente.
Documento 1: Questo articolo discute i diversi metodi di lemmatizzazione in grande dettaglio. Da leggere se vuoi sapere come funzionano gli stemmer tradizionali.
Documento 2: Questo è un ottimo lavoro che affronta il problema della derivazione per lingue ricche di variazioni utilizzando il Deep Learning.
Set di dati: Questo è il collegamento per il set di dati Treebank-3 che puoi usare se vuoi creare il tuo Lemmatiser.
Implementazione: Di seguito è riportata un'implementazione di un Lemmatizer inglese che utilizza spacy.
#!pip install spacy#python -m spacy download enimport spacynlp=spacy.load("en")doc="good better best"
for token in nlp(doc): print(token,token.lemma_)
3. Incorporamenti di parole
Cosa sono gli incorporamenti di parole? ?: Word Embeddings è il nome delle tecniche utilizzate per rappresentare il linguaggio naturale in forma vettoriale di numeri reali. Sono utili a causa dell'incapacità dei computer di elaborare il linguaggio naturale. Quindi, questi intarsi di parole catturano l'essenza e la relazione tra le parole nel linguaggio naturale usando numeri reali. E incorporamento di parole, una palabra o frase se representa en un vector de dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e... fija de longitud, Diciamo 100.
Per esempio-
Una parola “uomo” può essere rappresentato in un vettore di 5 dimensioni come
![]()
dove ciascuno di questi numeri è la grandezza della parola in una particolare direzione.
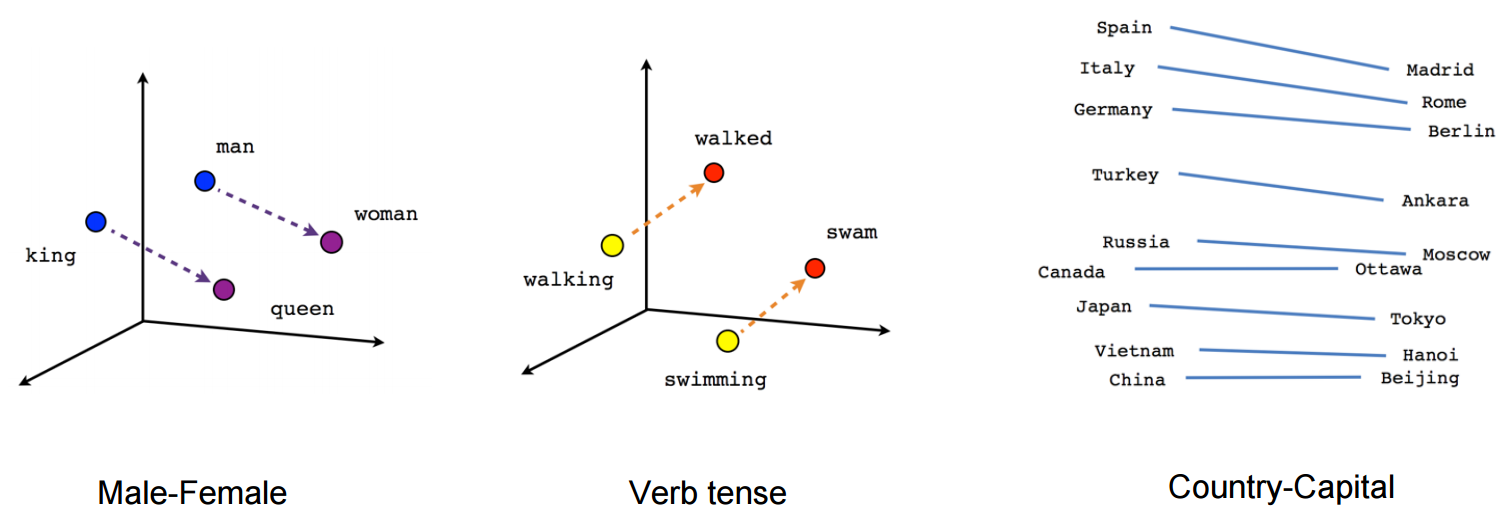
Blog: Ecco un articolo che spiega gli incorporamenti di Word in modo molto dettagliato.
Carta: Un ottimo ruolo che spiega in dettaglio i vettori di parole. Da leggere per una profonda comprensione dei vettori di parole.
Attrezzo: Un browser basato strumento per visualizzare i vettori di parole.
Vettori di parole pre-addestrati: Ecco un elenco completo di Vettori di parole pre-addestrati Su 294 lingue di facebook.
Implementazione: Ecco come puoi ottenere Word Vector pre-addestrato usando il pacchetto gensim.
Scarica il Vettori di parole precedentemente addestrati in Google News da qui.
#!pip install gensimfrom gensim.models.keyedvectors import KeyedVectorsword_vectors=KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin',binary=True)word_vectors['human']
Implementazione: Ecco come puoi addestrare i tuoi vettori di parole usando gensim
sentence=[['first','sentence'],['second','sentence']]model = gensim.models.Word2Vec(sentence, min_count=1,size=300,workers=4)
4. Etichettare una parte del discorso
Che cos'è il tagging del discorso parziale? ?: In termini semplicistici, L'etichettatura parziale del discorso è il processo di marcatura delle parole in una frase come nomi, verbi, aggettivi, avverbi, eccetera.. Ad esempio, nella frase-
“Ashok ha ucciso il serpente con un bastone”
Le parti del discorso sono identificate come:
Ashok PROPN
delicato VERBO
il IL
serpente SOSTANTIVO
insieme a ADP
un IL
palo SOSTANTIVO
. PUNTO
Test 1: Questo ruolo choi opportunamente intitolato L'ultima essenza dello stato dell'arte introduce un nuovo metodo chiamato Dynamic Feature Induction che raggiunge lo stato dell'arte nell'attività di tagging POS
Documento 2: Questo articolo Introduce l'etichettatura POS non presidiata utilizzando i modelli Markov nascosti con ancoraggio.
Implementazione: Ecco come possiamo eseguire la codifica POS utilizzando spacy.
#!pip install spacy#!python -m spacy download en nlp=spacy.load('en')sentence="Ashok killed the snake with a stick"for token in nlp(sentence): print(token,token.pos_)
5. Disambiguazione dell'entità denominata
Cos'è la disambiguazione delle entità denominate? ?: La disambiguazione dell'entità denominata è il processo di identificazione delle menzioni dell'entità in una frase. Ad esempio, nella frase-
“Apple ha guadagnato entrate di 200 miliardi di dollari nel 2016”
È compito della Designation of Named Entities dedurre che Apple nella frase è l'azienda Apple e non un frutto..
Entità denominata, generalmente, richiede una base di conoscenza dell'entità che è possibile utilizzare per collegare le entità nella frase alla base di conoscenza.
Documento 1: Questo articolo di Huang utilizza modelli di relazione semantica profonda basati su reti neurali profonde in combinazione con la base di conoscenza per ottenere risultati all'avanguardia nella disambiguazione delle entità nominate.
Documento 2: Questo articolo di Ganea e Hofmann utilizzare l'attenzione neurale locale insieme agli incorporamenti di Word e senza funzioni create manualmente.
6. Riconoscimento entità nominative
Che cos'è il riconoscimento dell'entità denominata? ?: Il riconoscimento delle entità denominate è il compito di identificare le entità in una frase e classificarle in categorie come una persona, organizzazione, Data, Posizione, ora, eccetera. Ad esempio, una NER prenderebbe una frase come:
“Ram di Apple Inc. viaggiato a Sydney su 5 ottobre 2017”
e restituisce qualcosa come
RAM
a partire dal
Mela ORG
C. ORG
viaggiato
per
Sydney GPE
su
Quinto DATA
ottobre DATA
2017 DATA
Qui, ORG sta per Organizzazione e GPE sta per Posizione.
Il problema con i NER attuali è che anche i NER di nuova generazione tendono a sottoperformare se utilizzati in un dominio di dati diverso dai dati su cui è stato addestrato il NER..

Carta: Questo eccellente documento utilizza LSTM bidirezionali e combina metodi di apprendimento supervisionati e non supervisionati per ottenere un risultato all'avanguardia nel riconoscimento di entità nominate in 4 Le lingue.
Implementazione: Prossimo, spiega come eseguire il riconoscimento di entità denominate utilizzando spacy.
import spacynlp=spacy.load('en')sentence="Ram of Apple Inc. travelled to Sydney on 5th October 2017"for token in nlp(sentence): print(token, token.ent_type_)
7. Analisi del sentimento
Cos'è l'analisi del sentimento? ?: L'analisi del sentiment è un'ampia gamma di analisi soggettive che utilizza tecniche di elaborazione del linguaggio naturale per eseguire attività come identificare il sentiment di una recensione del cliente., sensazione positiva o negativa in una frase, giudicare l'umore usando l'analisi del parlato o l'analisi del testo scritto, eccetera. Ad esempio:
"Non mi è piaciuto il gelato al cioccolato" – è un'esperienza negativa con il gelato.
“Non odiavo il gelato al cioccolato”: può essere considerata un'esperienza neutra
Esiste un'ampia gamma di metodi utilizzati per eseguire l'analisi del sentiment, dal conteggio delle parole negative e positive in una frase all'uso di LSTM con intarsi di parole.
Blog 1: Questo articolo si concentra sulla conduzione di analisi del sentimento sui tweet dei film
Blog 2: Questo articolo si concentra sulla conduzione di analisi del sentimento dei tweet durante l'alluvione di Chennai.
Documento 1: Questo articolo adopta el enfoque del método de apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... con el método Naive Bayes para clasificar las revisiones de IMDB.
Documento 2: Questo articolo utiliza el método de Apprendimento non supervisionatoL'apprendimento non supervisionato è una tecnica di apprendimento automatico che consente ai modelli di identificare modelli e strutture nei dati senza etichette predefinite. Attraverso algoritmi come k-means e analisi delle componenti principali, Questo approccio viene utilizzato in una varietà di applicazioni, come la segmentazione dei clienti, Rilevamento delle anomalie e compressione dei dati. La sua capacità di rivelare informazioni nascoste lo rende uno strumento prezioso... con LDA para identificar aspectos y sentimientos de las opiniones generadas por los usuarios. Questo documento è eccezionale in quanto affronta il problema della carenza di recensioni commentate..
Repository: Questo è un repository fantastico di lavoro di ricerca e implementazione di analisi del sentimento in varie lingue.
Set di dati 1: Set di dati di opinione da più domini, versione 2.0
Set di dati 2: Set di dati di analisi del sentiment di Twitter
Fai tu stesso l'analisi del sentiment di Twitter.
8. Somiglianza semantica del testo
Cos'è la somiglianza semantica del testo? ?: La somiglianza semantica del testo è il processo di analisi della somiglianza tra due parti di testo rispetto al significato e alla sostanza del testo invece di analizzare la sintassi delle due parti di testo. Cosa c'è di più, la somiglianza è diversa dalla relazione.
Ad esempio –
L'auto e l'autobus sono simili, ma l'auto e il carburante sono correlati.
Documento 1: Questo articolo presenta i diversi approcci per misurare la somiglianza del testo in dettaglio. Un articolo da leggere per conoscere gli approcci esistenti in un unico posto.
Documento 2: Questo articolo presenta la CNN per classificare una coppia di due brevi testi
Documento 3: Questo articolo si avvale di Tree-LSTM che raggiungono un risultato all'avanguardia nella relazione semantica dei testi e nella classificazione semantica.
9. Identificazione della lingua
Che cos'è l'identificazione della lingua? ?: L'identificazione della lingua è il compito di identificare la lingua in cui si trova il contenuto. Si avvale delle proprietà statistiche e sintattiche della lingua per svolgere questo compito. Può anche essere considerato un caso speciale di classificazione del testo.
Blog: In questo post sul blog fastText, introdurre un nuovo strumento in grado di identificare 170 lingue con 1 MB di memoria utilizzata.
Documento 1: Questo articolo analizzare 7 metodi di identificazione della lingua di 285 Le lingue.
Documento 2: Questo articolo descrive come le reti neurali profonde possono essere utilizzate per ottenere risultati all'avanguardia nell'identificazione automatica del linguaggio.
10. Riepilogo del testo
Che cos'è il riepilogo del testo? ?: Il riassunto del testo è il processo di accorciamento di un testo identificando i punti importanti del testo e creando un riassunto usando questi punti. L'obiettivo del riassunto del testo è di conservare la massima informazione insieme alla massima abbreviazione del testo senza alterare il significato del testo.
Documento 1: Questo articolo descrive un approccio basato su un modello di attenzione neurale per il riassunto astratto della frase.
Documento 2: Questo articolo descrive come gli RNN sequenza per sequenza possono essere utilizzati per ottenere risultati all'avanguardia nella sintesi del testo.
Repository: Questo repository di Google Brain Il team ha i codici per utilizzare un modello sequenza per sequenza personalizzato per il riepilogo del testo. Il modello è addestrato su un set di dati Gigaword.
Applicazione: Il robot autotldr su Reddit usa il riepilogo del testo per riassumere gli articoli nei commenti di un post. Questa funzionalità si è rivelata molto famosa tra gli utenti di Reddit..
Implementazione: ecco come puoi riassumere rapidamente il tuo testo usando il pacchetto gensim.
from gensim.summarization import summarizesentence="Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document. Technologies that can make a coherent summary take into account variables such as length, writing style and syntax.Automatic data summarization is part of machine learning and data mining. The main idea of summarization is to find a subset of data which contains the information of the entire set. Such techniques are widely used in industry today. Search engines are an example; others include summarization of documents, image collections and videos. Document summarization tries to create a representative summary or abstract of the entire document, by finding the most informative sentences, while in image summarization the system finds the most representative and important (i.e. salient) images. For surveillance videos, one might want to extract the important events from the uneventful context.There are two general approaches to automatic summarization: extraction and abstraction. Extractive methods work by selecting a subset of existing words, phrases, or sentences in the original text to form the summary. In contrast, abstractive methods build an internal semantic representation and then use natural language generation techniques to create a summary that is closer to what a human might express. Such a summary might include verbal innovations. Research to date has focused primarily on extractive methods, which are appropriate for image collection summarization and video summarization."summarize(sentence)
Note finali
Quindi si trattava delle attività di PNL più comuni insieme alle relative risorse sotto forma di blog., articoli di ricerca, repository e applicazioni, eccetera. Se ci credi, c'è una grande risorsa su ognuno di questi 10 attività che ho perso o vuoi suggerire di aggiungere un'altra attività, quindi sentiti libero di commentare i tuoi suggerimenti e commenti.
Abbiamo anche un ottimo corso, PNL usando Python, per te se vuoi diventare un praticante di PNL.
Buon apprendimento!





