Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Immagina di entrare in una libreria per comprare un libro sull'economia mondiale e di non riuscire a trovare la sezione del negozio che ha questo libro., supponendo che la libreria abbia semplicemente impilato tutti i tipi di libri. Poi ti rendi conto di quanto sia importante dividere la libreria in diverse sezioni a seconda del tipo di libro.
La modellazione del tema è simile alla divisione di una libreria in base al contenuto dei libri, in quanto si riferisce al processo di scoperta di argomenti in un corpus testuale e annotazione dei documenti in base agli argomenti identificati.
Quando hai bisogno di segmentare, comprendere e riassumere una vasta raccolta di documenti, la modellazione dell'argomento può essere utile.
Modellazione di temi utilizzando LDA:
L'incarico latente di Dirichlet (LDA) è uno dei modi per implementare la modellazione del tema. È un modello probabilistico generativo in cui si presume che ogni documento sia costituito da una diversa proporzione di argomenti.
Come funziona l'algoritmo LDA??
I seguenti passaggi vengono eseguiti in LDA per assegnare argomenti a ciascuno dei documenti:
1) Per ogni documento, inizializza casualmente ogni parola su un argomento tra i K argomenti dove K è il numero di argomenti predefiniti.
2) Per ogni documento di:
Per ogni parola w nel documento, calcolare:
- P (tema t | documento d): Proporzione di parole nel documento d che sono assegnate all'argomento t
- P (palabra con | tema t): Proporzione di assegnazioni all'argomento t in tutti i documenti word che provengono da w
3) Riassegna l'argomento T' alla parola w con probabilità p (T’ | D) * P (w | T ') considerando tutte le altre parole e le loro assegnazioni di soggetto
L'ultimo passaggio viene ripetuto più volte fino a raggiungere uno stato stazionario in cui le assegnazioni degli argomenti non cambiano più. Il rapporto di argomento per ogni documento è determinato da queste assegnazioni di argomenti.
Esempio illustrativo di LDA:
Diciamo che abbiamo quanto segue 4 documenti come corpus e vogliamo eseguire una modellazione tematica su questi documenti.
Documento 1: Guardiamo molti video su YouTube.
Documento 2: I video di YouTube sono molto istruttivi.
Documento 3: Leggere un blog tecnico mi fa capire facilmente le cose.
Documento 4: Preferisco il blog ai video di YouTube.
La modellazione LDA ci aiuta a scoprire argomenti nel corpus precedente e ad assegnare combinazioni di argomenti per ciascuno dei documenti. Come esempio, il modello potrebbe produrre qualcosa come sotto:
Tema 1: 40% video, 60% Youtube
Tema 2: 95% blog, 5% Youtube
documenti 1 e 2 apparterrebbe allora a 100% all'argomento 1. Il documento 3 apparterrebbe a 100% all'argomento 2. Il documento 4 apparterrebbe a 80% all'argomento 2 e il 20% all'argomento 1.
Questa assegnazione di argomenti ai documenti viene eseguita tramite la modellazione LDA seguendo i passaggi discussi nella sezione precedente. Ora applichiamo LDA ad alcuni dati di testo e analizziamo i risultati effettivi in Python.
Modellazione di temi utilizzando LDA in Python:
Abbiamo preso i dati da "Amazon Fine Food Reviews"’ de Kaggle (https://www.kaggle.com/snap/amazon-fine-food-reviews) qui per illustrare come possiamo implementare la modellazione del tema usando LDA in Python.
Leggere i dati:
Iniziamo importando la libreria Pandas per leggere il CSV e salvarlo in un frame di dati.
importa panda come pd rev = pd.read_csv(R"Recensioni.csv") rev.testa()
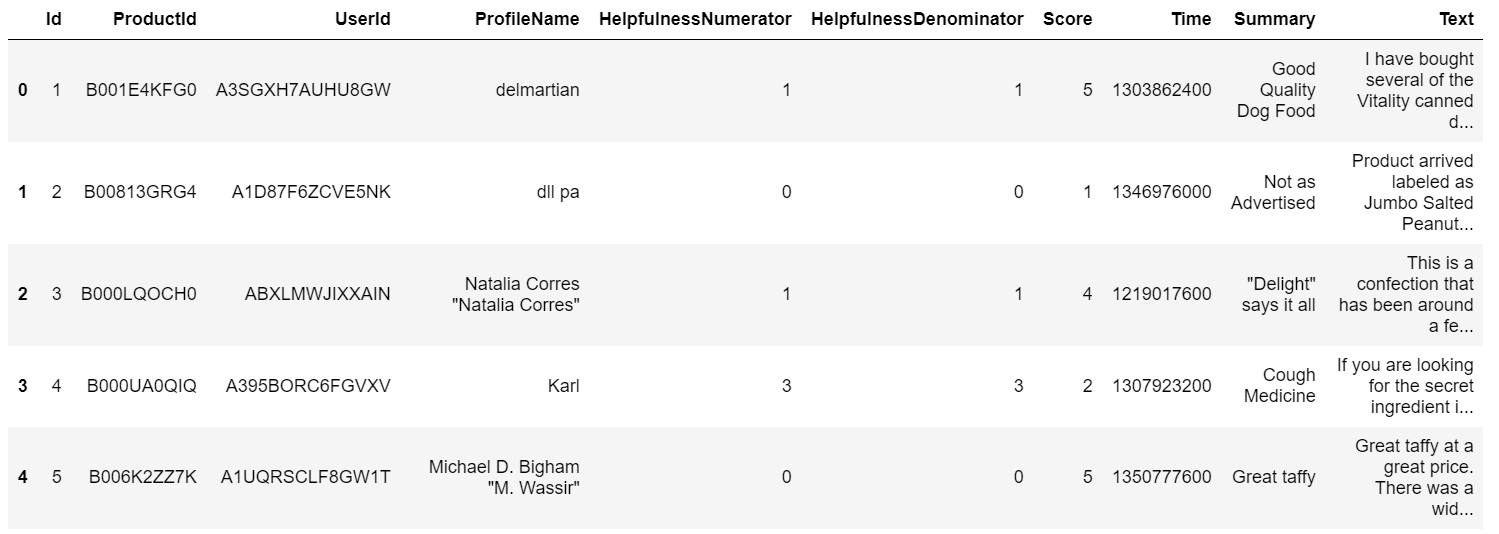
Siamo interessati ad argomenti di modellazione per la colonna "Testo"’ in questo set di dati.
Importazione delle librerie necessarie:
Avremo bisogno di importare la libreria NLTK poiché utilizzeremo lo stemming per la preelaborazione. Cosa c'è di più, rimuoveremmo anche le stopword prima di eseguire l'LDA. Per eseguire la modellazione del tema, dobbiamo convertire la nostra colonna di testo in una forma vettorializzata e quindi importiamo il TfidfVectorizer.
import nltk
da nltk.corpus importa stopword #stopwords
da nltk.stem import WordNetLemmatizer
da sklearn.feature_extraction.text import TfidfVectorizer
stop_words=set(nltk.corpus.stopwords.words('inglese'))
Pre-elaborazione del testo:
Applicheremo la radice alle parole in modo che vengano usate le parole radice di tutte le parole derivate. Cosa c'è di più, le parole di stop vengono eliminate e le parole con lunghezze maggiori di 3.
def clean_text(titolo):
le=WordNetLemmatizer()
word_tokens=word_tokenize(titolo)
token=[the.lemmatize(w) for w in word_tokens se w non in stop_words e len(w)>3]
cleaned_text=" ".aderire(gettoni)
return cleaned_text
rev['testo_pulito']= giro['Testo'].applicare(testo_pulito)
Vettorizzazione TFIDF nella colonna di testo:
L'esecuzione di una vettorizzazione TFIDF nella colonna di testo ci fornisce una matrice di termini del documento su cui possiamo modellare il tema.. TFIDF si riferisce a Frequenza del termine Frequenza inversa dei documenti, poiché questa vettorizzazione confronta il numero di volte che una parola appare in un documento con il numero di documenti che la contengono.
vect =TfidfVectorizer(stop_words=stop_words,max_features=1000) vect_text=vect.fit_transform(rev['testo_pulito'])
LDA in testo vettorializzato:
Il parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... que le hemos dado al modelo LDA, come mostrato di seguito, includi il numero di argomenti, il metodo di apprendimento (che è il modo in cui l'algoritmo aggiorna le assegnazioni di argomenti ai documenti), il numero massimo di iterazioni da eseguire. fuori e lo stato casuale. I parametri che abbiamo dato al modello LDA, come mostrato di seguito, includi il numero di argomenti, il metodo di apprendimento (che è il modo in cui l'algoritmo aggiorna le assegnazioni di argomenti ai documenti), il numero massimo di iterazioni da eseguire. fuori e lo stato casuale.
da sklearn.decomposition import LatentDirichletAllocation lda_model=LatentDirichletAllocation(n_components=10, learning_method='online',random_state=42,max_iter=1) lda_top=lda_model.fit_transform(testo_vect)
Controllo dei risultati:
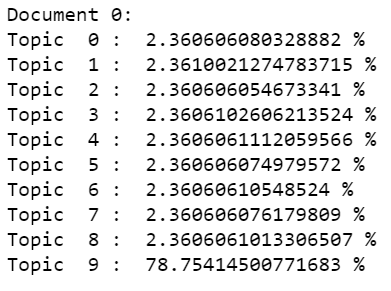
Possiamo verificare la proporzione di argomenti che sono stati assegnati al primo documento utilizzando le righe di codice indicate di seguito.
Stampa("Documento 0: ")
per me,argomento in enumerare(lda_top[0]):
Stampa("Argomento ",io,": ",argomento*100,"%")
Analizzare i problemi:
Vediamo quali sono le parole principali che compongono gli argomenti. Questo ci darebbe una visione di ciò che definisce ciascuno di questi temi..
vocab = vect.get_feature_names()
per me, comp in enumerare(lda_model.components_):
vocab_comp = zip(vocabolario, comp)
sorted_words = ordinato(vocab_comp, chiave= lambda x:X[1], inverso=Vero)[:10]
Stampa("Argomento "+str(io)+": ")
per t in sorted_words:
Stampa(T[0],fine=" ")
Stampa("n")

Oltre a LDA, altri algoritmi possono essere utilizzati per eseguire la modellazione del tema. Indicizzazione semantica latente (LSI), fattorizzazione di matrici non negative sono alcuni degli altri algoritmi che possono essere provati per eseguire la modellazione del tema. Tutti questi algoritmi, come LDA, implicano l'estrazione di caratteristiche dagli array di termini del documento e la generazione di un gruppo di termini che differiscono l'uno dall'altro, che alla fine portano alla creazione di temi. Questi temi possono aiutare a valutare i temi principali di un corpus e, così, organizzare grandi raccolte di dati testuali.
Circa l'autore
Nibedita
ha completato il suo master in ingegneria chimica presso l'IIT Kharagpur in 2014 e
attualmente lavora come consulente senior presso AbsolutData Analytics. Nel suo
capacità attuale, lavora alla creazione di soluzioni basate sull'intelligenza artificiale / ML per i clienti di
una varietà di settori.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





