Nell'era dei Big Data, Python è diventato il linguaggio più cercato. In questo articolo, Concentriamoci su un aspetto particolare di Python che lo rende uno dei linguaggi di programmazione più potenti: multiprocesso.
Ora, prima di immergerci nell'essenziale del multiprocessing, Ti suggerisco di leggere il mio precedente articolo su Threading in Python, in quanto può fornire un contesto migliore per l'articolo corrente.
Supponiamo che tu sia uno studente di scuola elementare a cui è stato affidato l'arduo compito di moltiplicare 1200 coppie di numeri come compiti a casa. Supponiamo di essere in grado di moltiplicare una coppia di numeri in 3 secondi. Dopo, totale, sono necessari 1200 * 3 = 3600 secondi, Che cos'è 1 è ora di risolvere tutti i compiti. Ma devi recuperare il ritardo sul tuo programma TV preferito su 20 minuti.
Cosa faresti? Uno studente intelligente, anche se disonesto, chiama altri tre amici che hanno un'abilità simile e dividi il compito. Allora avrai 250 compiti di moltiplicazione sul tuo piatto, che completerai in 250 * 3 = 750 secondi, vale a dire, 15 minuti. Perciò, tu, insieme al suo altro 3 gli amici, finirà il compito in 15 minuti, dando 5 minuti di tempo per fare uno spuntino e sedersi a guardare il tuo programma TV. Il compito ha preso solo 15 minuti quando 4 di voi avete lavorato insieme, cosa altrimenti ci sarebbe voluto 1 ora.
Questa è l'ideologia di base del multiprocessing. Se hai un algoritmo che può essere suddiviso in diversi lavoratori (processori), allora puoi velocizzare il programma. Oggi, le macchine vengono con 4,8 e 16 nuclei, che può poi essere implementato in parallelo.
Elaborazione multipla nella scienza dei dati
Il multiprocessing ha due applicazioni cruciali nella scienza dei dati.
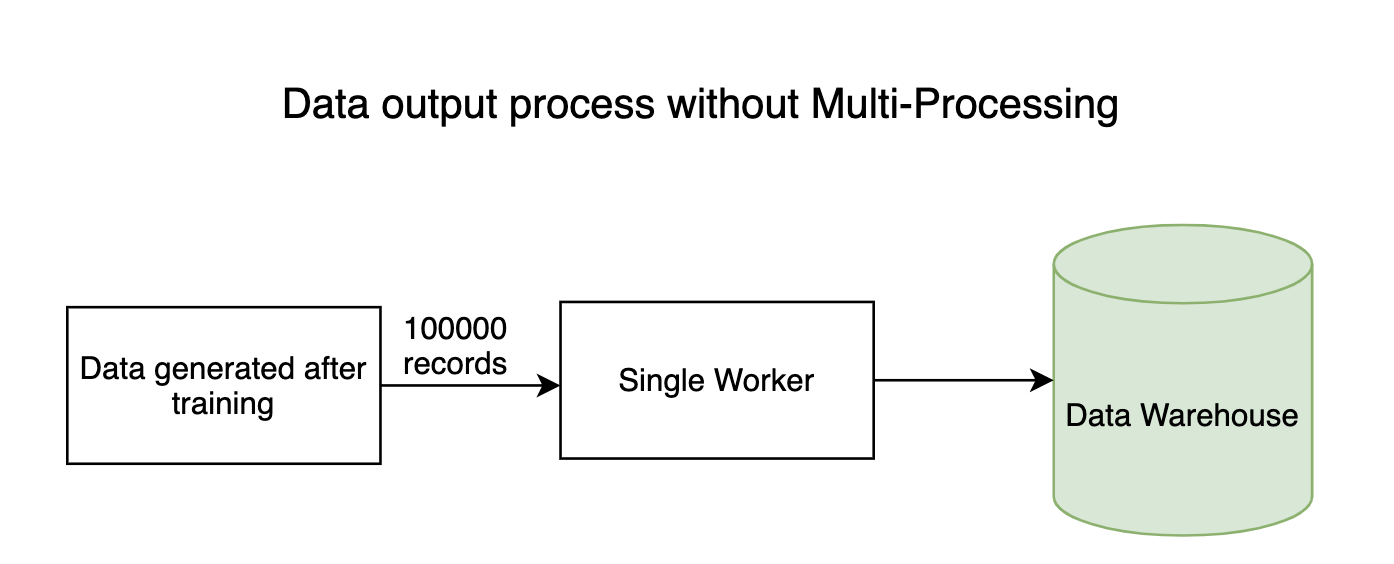
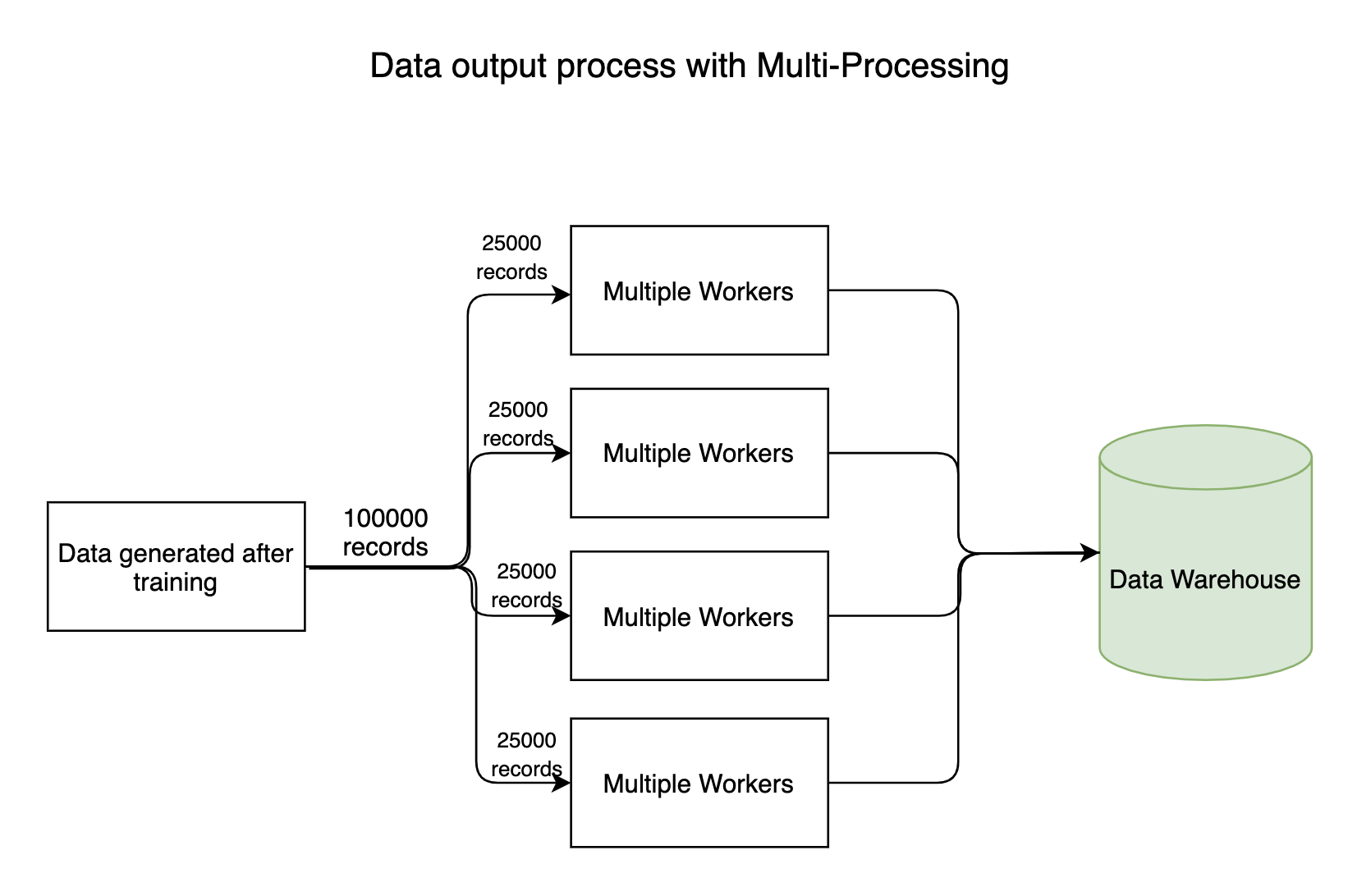
1. Processi di I/O
Qualsiasi pipeline ad alta intensità di dati ha processi di input e output in cui milioni di byte di dati fluiscono in tutto il sistema. Generalmente, il processo di lettura (iscrizione) di dati non ci vorrà molto, ma il processo di scrittura dei dati nei datastore richiede molto tempo. Il processo di scrittura può essere eseguito in parallelo, risparmiando molto tempo.
2. Modelli di allenamento
Sebbene non tutti i modelli possano essere addestrati in parallelo, Pocos modelos tienen características inherentes que les permitan entrenarse mediante el Elaborazione parallelaL'elaborazione parallela è una tecnica che consente di eseguire più operazioni contemporaneamente, Suddivisione di attività complesse in sottoattività più piccole. Questa metodologia ottimizza l'uso delle risorse computazionali e riduce i tempi di elaborazione, particolarmente utile in applicazioni come l'analisi di grandi volumi di dati, Simulazioni e rendering grafici. La sua implementazione è diventata essenziale nei sistemi ad alte prestazioni e nell'informatica moderna..... Ad esempio, L'algoritmo di foresta casuale implementa diversi alberi decisionali per prendere una decisione cumulativa. Questi alberi possono essere costruiti in parallelo. Infatti, L'API SkLeArn viene fornita con un parametro denominato n_jobs, che offre la possibilità di utilizzare più lavoratori.
Elaborazione multipla in Python usando Processi classe-
Ora mettiamo le mani sul multielaborazione Libreria Python.
Dai un'occhiata al seguente codice
import time
def sleepy_man():
Stampa('Iniziare a dormire')
tempo.dormire(1)
Stampa('Finito di dormire')
tic = tempo.tempo()
sleepy_man()
sleepy_man()
toc = time.time()
Stampa(«Fatto in {:.4F} seconds'.format(toc-tic))
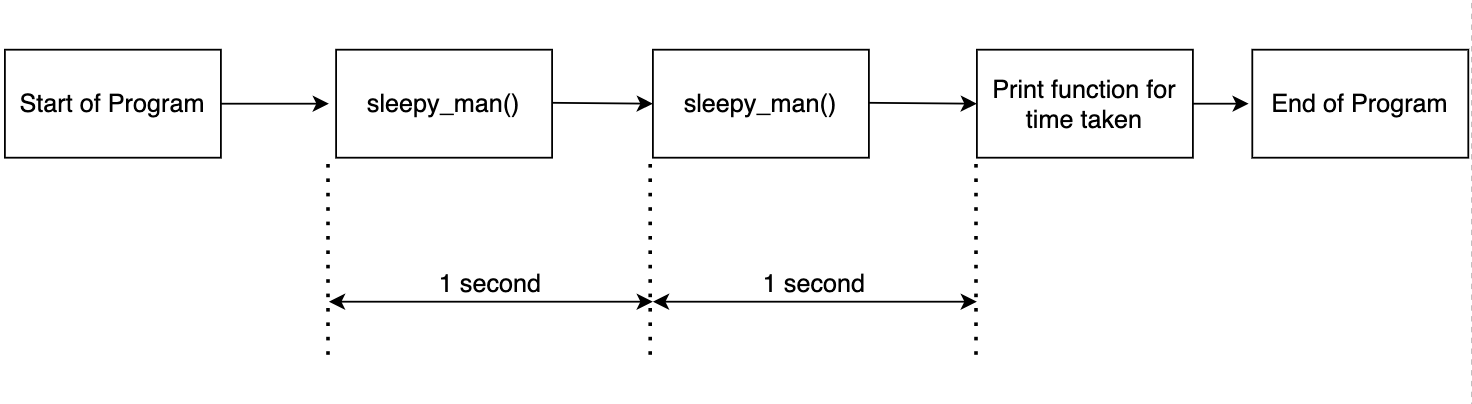
Il codice di cui sopra è semplice. La funzione hombre_soñoliento Sospendere per un secondo e chiamare la funzione due volte. Registriamo il tempo necessario per le due chiamate di funzione e stampiamo i risultati. L'output è come mostrato di seguito.
Starting to sleep
Done sleeping
Starting to sleep
Done sleeping
Done in 2.0037 Secondi
Questo è previsto in quanto chiamiamo la funzione due volte e registriamo l'ora. Il flusso è illustrato nel diagramma seguente.
Ora incorporiamo il multiprocessing nel codice.
import multiprocessing
import time
def sleepy_man():
Stampa('Iniziare a dormire')
tempo.dormire(1)
Stampa('Finito di dormire')
tic = tempo.tempo()
p1 = multiprocessing. Processo(target= sleepy_man)
p2 = multiprocessing. Processo(target= sleepy_man)
p1.start()
p2.start()
toc = time.time()
Stampa(«Fatto in {:.4F} seconds'.format(toc-tic))
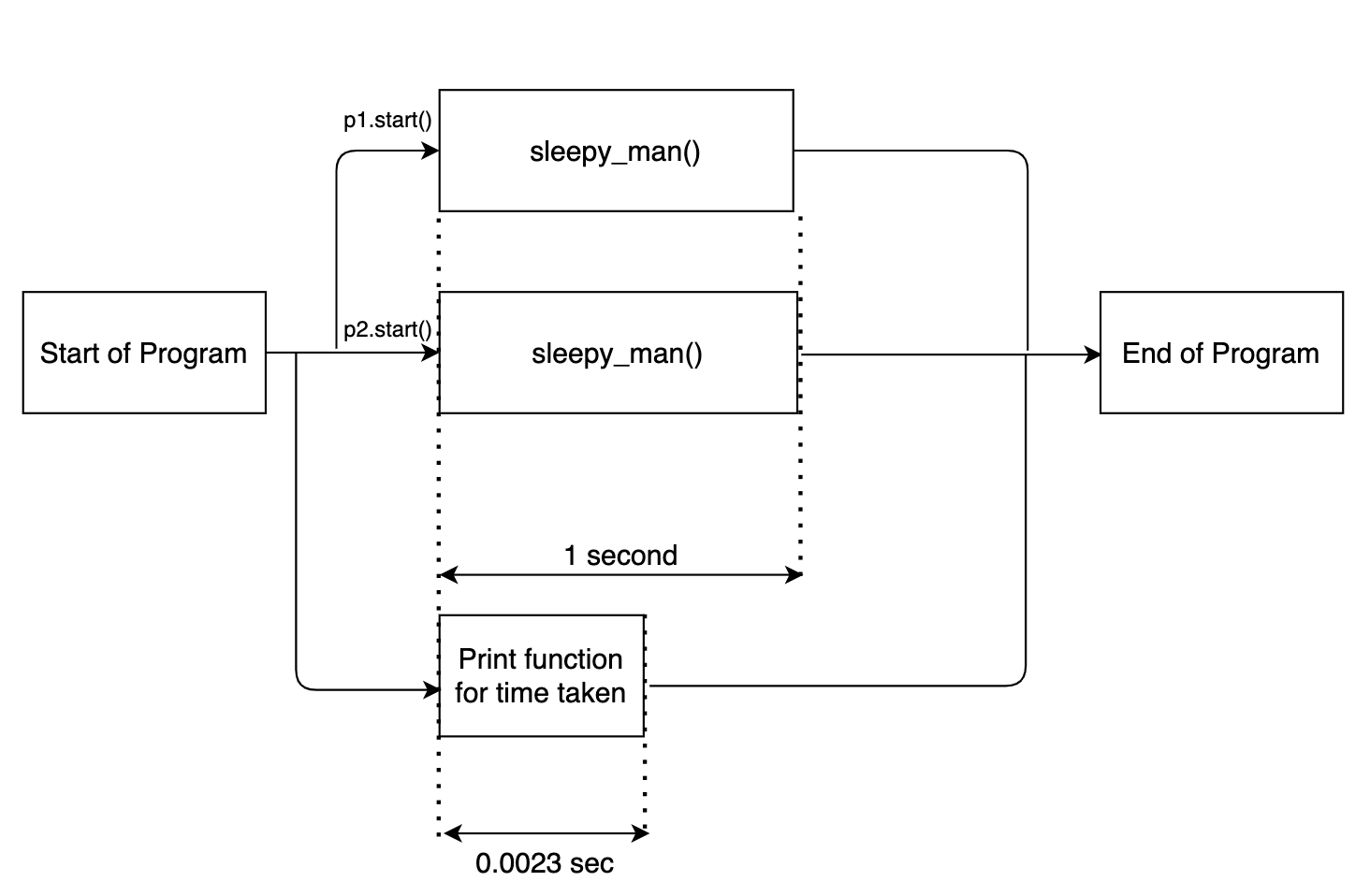
Qui multielaborazione. Processo (target = sleepy_man) definisce un'istanza multithread. Passiamo la funzione richiesta per essere eseguita, hombre_soñoliento, come argomento. Attiviamo le due istanze tramite p1.start ().
L'output è il seguente:
Dona in 0.0023 seconds
Starting to sleep
Starting to sleep
Done sleeping
Done sleeping
Ora nota una cosa. La dichiarazione di stampa del registro temporale è stata eseguita per prima. Questo è perché, insieme alle istanze multithread abilitate per il hombre_soñoliento funzione, Il codice principale della funzione è stato eseguito separatamente in parallelo. Il diagramma di flusso mostrato di seguito chiarirà le cose.
Per eseguire il resto del programma dopo l'esecuzione delle funzioni multithread, abbiamo bisogno di eseguire la funzione entrare().
import multiprocessing
import time
def sleepy_man():
Stampa('Iniziare a dormire')
tempo.dormire(1)
Stampa('Finito di dormire')
tic = tempo.tempo()
p1 = multiprocessing. Processo(target= sleepy_man)
p2 = multiprocessing. Processo(target= sleepy_man)
p1.start()
p2.start()
p1.join()
p2.join()
toc = time.time()
Stampa(«Fatto in {:.4F} seconds'.format(toc-tic))
Ora, Il resto del blocco di codice verrà eseguito solo dopo l'esecuzione delle attività multiprocessore. L'output è mostrato di seguito.
Starting to sleep
Starting to sleep
Done sleeping
Done sleeping
Done in 1.0090 Secondi
Il diagramma di flusso è mostrato di seguito.
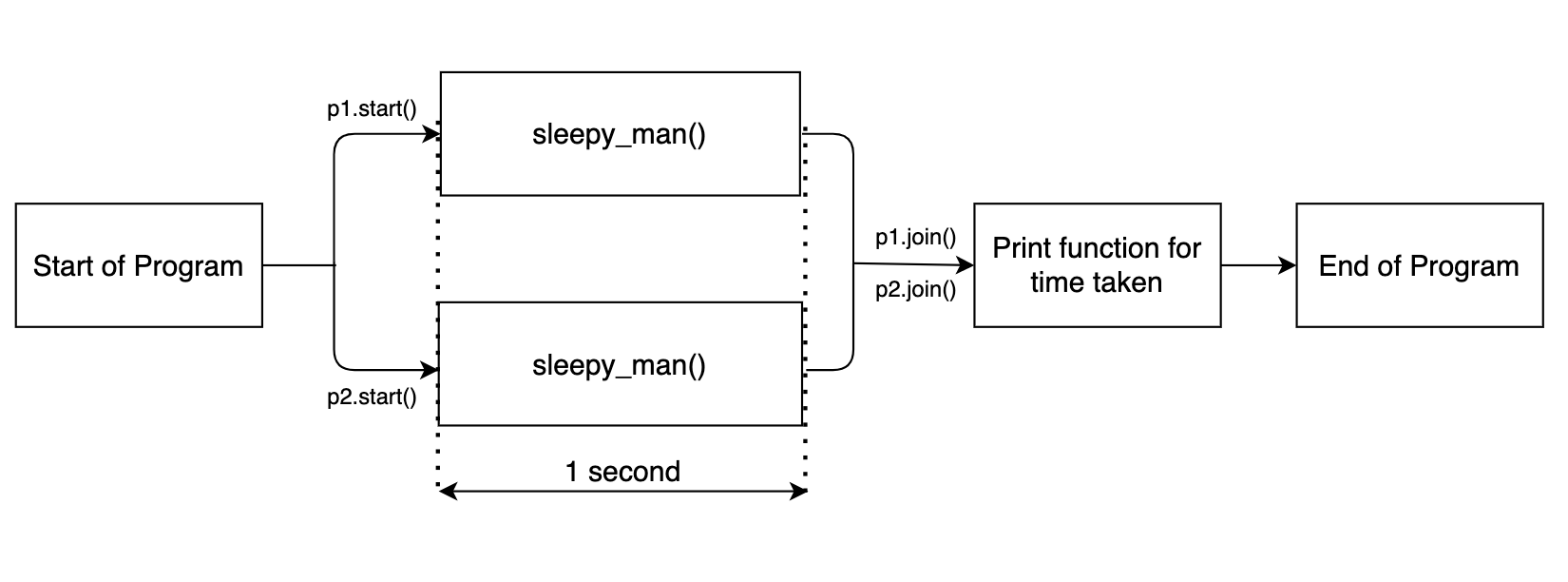
Poiché le due funzioni di sospensione funzionano in parallelo, la funzione nel suo insieme dura circa 1 secondo.
Possiamo definire qualsiasi numero di istanze multiprocessing. Guarda il codice qui sotto. Definire 10 diverse istanze di multiprocessing che utilizzano un ciclo for.
import multiprocessing
import time
def sleepy_man():
Stampa('Iniziare a dormire')
tempo.dormire(1)
Stampa('Finito di dormire')
tic = tempo.tempo()
process_list = []
per io nel raggio d'azione(10):
p = multiprocessing.Processo(target= sleepy_man)
p.start()
process_list.append(P)
per il processo in process_list:
process.join()
toc = time.time()
Stampa(«Fatto in {:.4F} seconds'.format(toc-tic))
L'output del codice sopra è mostrato di seguito.
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done in 1.0117 Secondi
Qui, Le dieci esecuzioni di funzioni vengono elaborate in parallelo e, così, L'intero programma richiede solo un secondo. Ora la mia macchina non ha 10 processori. Quando definiamo più processi della nostra macchina, La libreria multiprocessore dispone di una logica per la pianificazione dei processi. Quindi non devi preoccuparti di questo..
Possiamo anche passare argomenti al Processi funzione utilizzando argomenti.
import multiprocessing
import time
def sleepy_man(secondo):
Stampa('Iniziare a dormire')
tempo.dormire(secondo)
Stampa('Finito di dormire')
tic = tempo.tempo()
process_list = []
per io nel raggio d'azione(10):
p = multiprocessing.Processo(target= sleepy_man, args = [2])
p.start()
process_list.append(P)
per il processo in process_list:
process.join()
toc = time.time()
Stampa(«Fatto in {:.4F} seconds'.format(toc-tic))
L'output del codice sopra è mostrato di seguito.
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done in 2.0161 Secondi
Dal momento che passiamo un argomento, il hombre_soñoliento funzione di sonno durante 2 secondi invece di 1 secondo.
Elaborazione multipla in Python usando Piscina classe-
Nell'ultimo frammento di codice, Correre 10 processi diversi che utilizzano un ciclo for a. Invece, possiamo usare il Piscina per eseguire lo stesso.
import multiprocessing
import time
def sleepy_man(secondo):
Stampa("Iniziare a dormire per {} seconds'.format(secondo))
tempo.dormire(secondo)
Stampa('Fatto dormire per {} seconds'.format(secondo))
tic = tempo.tempo()
pool = multiprocessing. Pozza(5)
pool.map(sleepy_man, gamma(1,11))
pool.chiudi()
toc = time.time()
Stampa(«Fatto in {:.4F} seconds'.format(toc-tic))
Pool Multiprocessing (5) definisce il numero di lavoratori. Qui definiamo il numero come 5. pool.map () è il metodo che attiva l'esecuzione della funzione. Chiamare pool.map (hombre_soñoliento, classifica (1,11)). Qui, hombre_soñoliento es la función que se llamará con los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... Para las ejecuciones de funciones definidas por classifica (1,11) (Di solito viene passato un elenco). L'output è il seguente:
Iniziare a dormire per 1 seconds Starting to sleep for 2 seconds Starting to sleep for 3 seconds Starting to sleep for 4 seconds Starting to sleep for 5 seconds Done sleeping for 1 seconds Starting to sleep for 6 seconds Done sleeping for 2 seconds Starting to sleep for 7 seconds Done sleeping for 3 seconds Starting to sleep for 8 seconds Done sleeping for 4 seconds Starting to sleep for 9 seconds Done sleeping for 5 seconds Starting to sleep for 10 seconds Done sleeping for 6 seconds Done sleeping for 7 seconds Done sleeping for 8 seconds Done sleeping for 9 seconds Done sleeping for 10 seconds Done in 15.0210 Secondi
Piscina è un modo migliore per implementare il multiprocessing perché distribuisce le attività ai processori disponibili utilizzando il programma First Enter, primo fuori. È quasi simile all'architettura di riduzione della mappa, in sostanza, assegna l'input a diversi processori e raccoglie l'output da tutti i processori come un elenco. I processi in esecuzione sono archiviati in memoria e altri processi non in esecuzione sono archiviati in memoria.
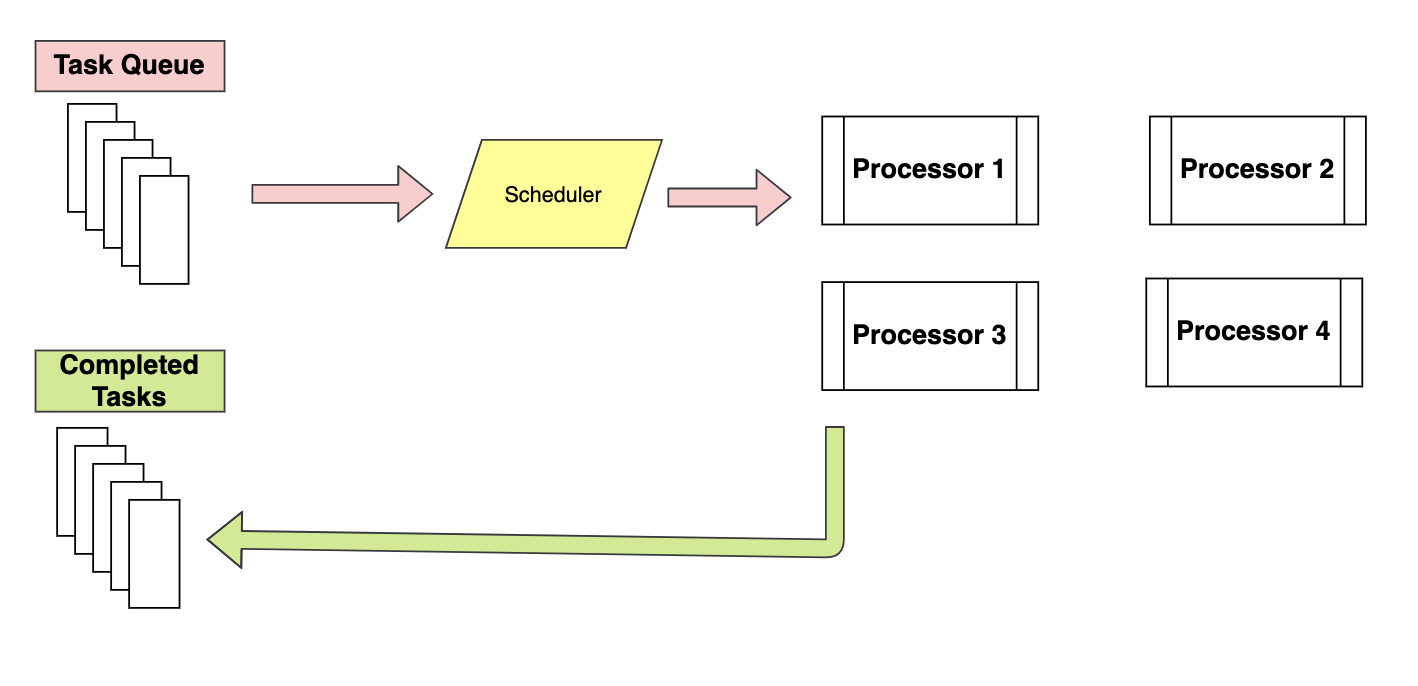
Nel frattempo Processi classe, tutti i processi vengono eseguiti in memoria e la loro esecuzione è pianificata utilizzando la politica FIFO.
Confronto delle prestazioni temporali per calcolare numeri perfetti-
Fino ad ora, giochiamo con multielaborazione funzioni in dormire funzioni. Ora prendiamo una funzione che controlla se un numero è un numero perfetto o no. Per chi non lo sapesse, un numero è perfetto se la somma dei suoi divisori positivi è uguale al numero stesso. Elencheremo i numeri perfetti minori o uguali a 100000. Lo implementeremo da 3 forme: Utilizzo di un ciclo per regolari, utilizzando multiprocesso. Processo () e multiprocesso. Pozza ().
Utilizzo di un normale per un ciclo
import time def is_perfect(n): sum_factors = 0 per io nel raggio d'azione(1, n): Se (n % i == 0): sum_factors = sum_factors + i if (sum_factors == n): Stampa('{} è un numero perfetto'.format(n)) tic = tempo.tempo() per n nell'intervallo(1,100000): is_perfect(n) toc = time.time() Stampa(«Fatto in {:.4F} seconds'.format(toc-tic))
Il risultato del programma di cui sopra è mostrato di seguito.
6 è un numero perfetto
28 è un numero perfetto
496 è un numero perfetto
8128 is a Perfect number
Done in 258.8744 Secondi
Utilizzo di una classe process
import time import multiprocessing def is_perfect(n): sum_factors = 0 per io nel raggio d'azione(1, n): Se(n % i == 0): sum_factors = sum_factors + i if (sum_factors == n): Stampa('{} è un numero perfetto'.format(n)) tic = tempo.tempo() processi = [] per io nel raggio d'azione(1,100000): p = multiprocessing. Processo(target=is_perfect, args=(io,)) processes.append(P) p.start() per il processo nei processi: process.join() toc = time.time() Stampa(«Fatto in {:.4F} seconds'.format(toc-tic))
Il risultato del programma di cui sopra è mostrato di seguito.
6 è un numero perfetto
28 è un numero perfetto
496 è un numero perfetto
8128 is a Perfect number
Done in 143.5928 Secondi
Come hai potuto vedere, abbiamo ottenuto una riduzione del 44,4% nel tempo in cui implementiamo il multiprocessing utilizzando Processi classe, invece di un ciclo per regolare.
Utilizzo di una classe Pool
import time import multiprocessing def is_perfect(n): sum_factors = 0 per io nel raggio d'azione(1, n): Se(n % i == 0): sum_factors = sum_factors + i if (sum_factors == n): Stampa('{} è un numero perfetto'.format(n)) tic = tempo.tempo() pool = multiprocessing. Pozza() pool.map(is_perfect, gamma(1,100000)) pool.chiudi() toc = time.time() Stampa(«Fatto in {:.4F} seconds'.format(toc-tic))
Il risultato del programma di cui sopra è mostrato di seguito.
6 è un numero perfetto
28 è un numero perfetto
496 è un numero perfetto
8128 is a Perfect number
Done in 74.2217 Secondi
Come potete vedere, rispetto a un normale ciclo for, abbiamo ottenuto una riduzione del 71,3% in tempo di calcolo, e rispetto al Processi classe, abbiamo ottenuto una riduzione del 48,4% in tempo di calcolo.
Perciò, È molto evidente che implementando un metodo adatto dal multielaborazione biblioteca, possiamo ottenere una significativa riduzione dei tempi di calcolo.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





