Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Assumi il lavoro di un ingegnere dei dati, estrazione di dati da più fonti di formati di file, trasformandoli in particolari tipi di dati e caricandoli in un'unica fonte per l'analisi. Poco dopo aver letto questo articolo, con l'aiuto di vari esempi pratici, potrai mettere alla prova le tue abilità implementando web scraping ed estrazione di dati con API. Con Python e l'ingegneria dei dati, puoi iniziare a raccogliere enormi set di dati da molte fonti e trasformarli in un'unica fonte primaria o iniziare a eseguire la scansione del Web per utili approfondimenti aziendali.
Sinossi:
- Perché l'ingegneria dei dati è più affidabile??
- Processo del ciclo ETL
- Estratto passo dopo passo, trasformare, funzione di ricarica
- Informazioni sull'ingegneria dei dati
- A proposito di me
- conclusione
Perché l'ingegneria dei dati è più affidabile??
È un'occupazione tecnologica più affidabile e in più rapida crescita nella generazione attuale, poiché si concentra maggiormente sul web scraping e sul monitoraggio dei set di dati.
Processi (Ciclo ETL):
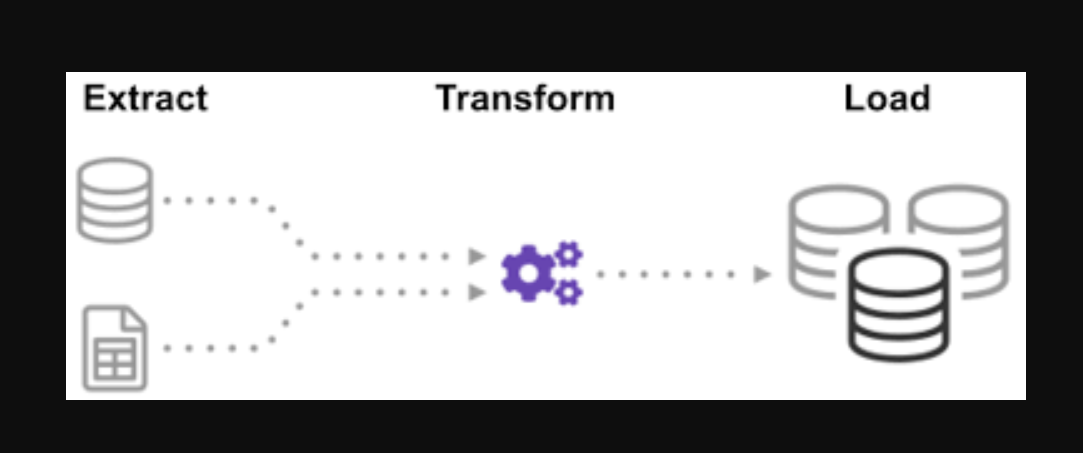
Vi siete mai chiesti come i dati provenienti da molte fonti siano stati integrati per creare un'unica fonte di informazioni? Il batch è un modo per raccogliere dati e imparare di più su "come esplorare un tipo di batch" chiamato Extract, Trasforma e carica.
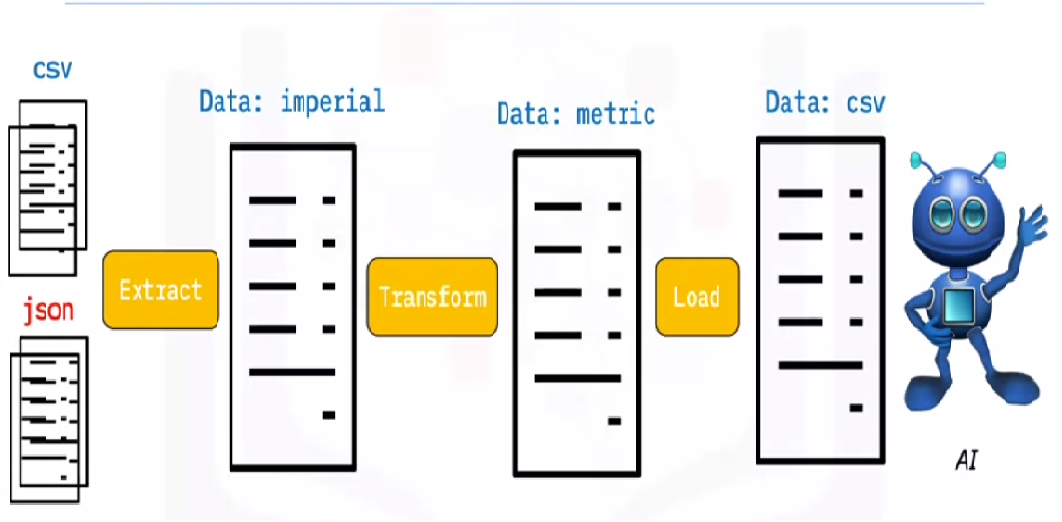
L'ETL è il processo di estrazione di grandi volumi di dati da una varietà di fonti e formati e la loro conversione in un unico formato prima di inserirli in un Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... o in un file di destinazione.
Alcuni dei tuoi dati sono archiviati in file CSV, mentre altri sono conservati in archivi JSONJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software... È necessario raccogliere tutte queste informazioni in un unico file affinché l'IA le possa leggere. Perché i tuoi dati sono in unità imperiali, ma l'intelligenza artificiale ha bisogno di unità metriche, deve convertirli. Perché l'intelligenza artificiale può leggere solo i dati CSV in un unico file di grandi dimensioni, devi prima caricarlo. Se i dati sono in formato CSV, mettiamo il seguente ETL con python e diamo un'occhiata alla fase di estrazione con alcuni semplici esempi.
Guardando l'elenco dei file .json e .csv. L'estensione del file glob è preceduta da una stella e un punto nella voce. Viene restituito un elenco di file .csv. Per i file .json, possiamo fare lo stesso. Possiamo creare un file che estrae i nomi, altezze e pesi in formato CSV. Il nome file del file .csv è l'input e l'output è un frame di dati. Per i formati JSON, possiamo fare lo stesso.
passo 1:
Aprire il notebook e importare le funzioni e i moduli necessari
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
Dati utilizzati:
Gli archivi dealership_data contengono file CSV, JSON e XML per i dati delle auto usate che contengono funzionalità denominate car_model, year_of_manufacture, price, e fuel. Quindi estraiamo il file dai dati grezzi e trasformiamolo in un file di destinazione e carichiamolo nell'output.
Scaricare il file di origine dal cloud:
!wget https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0221EN-SkillsNetwork/labs/module 6/Lab - Extract Transform Load/data/datasource.zip
Estrarre il file zip:
nzip datasource.zip -d dealership_data
Impostare il percorso dei file di destinazione:
tmpfile = "dealership_temp.tmp" # store all extracted data logfile = "dealership_logfile.txt" # all event logs will be stored targetfile = "dealership_transformed_data.csv" # vengono archiviati i dati trasformati
passo 2 (ESTRARREL'estratto è una sostanza ottenuta concentrando composti di origine vegetale, animale o minerale. Utilizzato in una varietà di applicazioni, come l'industria alimentare, Farmaceutico e cosmetico. Gli estratti possono essere presentati in forma liquida, in polvere o sotto forma di tinture, e la sua produzione prevede tecniche come la macerazione, distillazione o estrazione con solvente. Il suo utilizzo permette di sfruttare in modo più ampio le proprietà benefiche degli ingredienti originali..):
L'estrazione della funzione estrarrà grandi quantità di dati da più origini in batch. Quando si aggiunge questa funzione, ora scoprirà e caricherà tutti i nomi di file CSV, e i file CSV verranno aggiunti alla cornice della data con ogni iterazione del ciclo, con la prima iterazione che si attacca per prima, seguito dalla seconda iterazione, risultante in un elenco di dati estratti. Una volta raccolti i dati, passeremo al passo “Trasformare” di processo.
Nota: Se lui “indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... Di ignorare” è impostato su vero, l'ordine di ogni riga sarà lo stesso dell'ordine in cui le righe sono state aggiunte al frame di dati.
Funzione di estrazione CSV
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
restituire il dataframe
Funzione di estrazione JSON
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,righe=Vero)
restituire il dataframe
Funzione di estrazione XML
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(colonne=['modello d'auto','anno di fabbricazione','prezzo', 'carburante'])
albero = ET.parse(file_to_process)
root = tree.getroot()
per persona in root:
car_model = person.find("car_model").text
year_of_manufacture = int(persona.trova("year_of_manufacture").testo)
prezzo = flottante(persona.trova("prezzo").testo)
carburante = person.find("combustibile").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "prezzo":prezzo, "combustibile":combustibile}, ignore_index=Vero)
restituire il dataframe
Función de extracción ():
Ahora llame a la función de extracción usando su llamada de función para CSV, JSON, XML.
estratto def():
extracted_data = pd. DataFrame(colonne=['modello d'auto','anno di fabbricazione','prezzo', 'carburante'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=Vero)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=Vero)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=Vero)
extracted_data di ritorno
passo 3 (Trasformare):
Una volta raccolti i dati, pasaremos a la fase “Trasformare” di processo. Questa funzione convertirà l'altezza della colonna, che è in pollici, in millimetri e la colonna della libbra, che è in libbre, al chilogrammo, e restituirà i risultati nella variabile data. Nel riquadro dei dati di input, l'altezza della colonna è in piedi. Converti la colonna in metri e arrotonda a due cifre decimali.
def trasformare(dati):
dati['prezzo'] = rotondo(dati.prezzo, 2)
restituire i dati
passo 4 (caricamento e registrazione):
È ora di caricare i dati nel file di destinazione ora che li abbiamo raccolti e specificati. Salviamo il frame di dati dei panda come CSV in questo scenario. Ora siamo passati attraverso i passaggi di estrazione, trasformare e caricare dati da più fonti in un unico file di destinazione. Dobbiamo impostare una voce di registro prima di poter terminare il nostro lavoro. Raggiungeremo questo obiettivo digitando una funzione di registrazione.
Funzione di ricarica:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
Funzione di registrazione:
Tutti i dati immessi verranno aggiunti alle informazioni correnti quando il “un”. Possiamo quindi allegare un timestamp a ciascuna fase del processo, indicando quando inizia e quando finisce, generazione di questo tipo di input. Una volta definito tutto il codice necessario per eseguire il processo ETL sui dati, L'ultimo passaggio consiste nel chiamare tutte le funzioni.
registro def(Messaggio):
timestamp_format="%h:%m:%S-%h-%d-%Y"
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
con aperto("dealership_logfile.txt","un") come f: f.scrivere(Timestamp + ',' + Messaggio + 'n')
passo 5 (Esecuzione del processo ETL):
Per prima cosa iniziamo chiamando la funzione extract_data. I dati ricevuti da questo passaggio verranno quindi trasferiti al secondo passaggio di trasformazione dei dati. Una volta che questo è completato, i dati vengono caricati nel file di destinazione. Cosa c'è di più, nota che prima e dopo ogni passaggio sono state aggiunte l'ora e la data di inizio e di fine.
La registrazione dell'avvio del processo ETL:
tronco d'albero("Lavoro ETL iniziato")
Il record che ha iniziato e completato il passaggio Estrai:
tronco d'albero("Fase di estrazione iniziata")
dati_estratti = estratto()
tronco d'albero("Fase di estrazione terminata")
Il record che ha iniziato e concluso la Fase di Trasformazione:
tronco d'albero (“Iniziata la fase di trasformazione”)
data_transformed = trasformare (dati_estratti)
tronco d'albero("Fase di trasformazione terminata")
Il record che ha iniziato e concluso la fase di caricamento:
tronco d'albero("Fase di carico avviata")
carico(targetfile,dati_trasformati)
tronco d'albero("Fase di carico terminata")
Il record di completamento del ciclo ETL:
tronco d'albero("Lavoro ETL terminato")
Attraverso questo processo, discutiamo alcune funzioni di estrazione di base, trasformazione e caricamento
- Come scrivere una semplice funzione di estrazione.
- Come scrivere una semplice funzione di trasformazione.
- Come scrivere una semplice funzione di caricamento.
- Come scrivere una semplice funzione di registro.
“Non grande dati, sei cieco e sordo e sei in mezzo a un'autostrada “. – Geoffrey Moore.
Al massimo, abbiamo discusso tutti i processi ETL. Cosa c'è di più, vediamo, “Quali sono i vantaggi del lavoro di ingegneria dei dati??”.
Informazioni sull'ingegneria dei dati:
L'ingegneria dei dati è un campo vasto con molti nomi. Potresti non avere nemmeno una laurea formale in molte istituzioni. Di conseguenza, generalmente è meglio iniziare definendo gli obiettivi del lavoro di ingegneria dei dati che portano ai risultati attesi. Gli utenti che si fidano dei data engineer sono diversi quanto i talenti e i risultati dei team di data engineering. I tuoi consumatori definiranno sempre quali problemi gestisci e come li risolvi, indipendentemente dal settore a cui è dedicato.
A proposito di me:
Ciao, mi chiamo Lavanya e vengo da Chennai. Sono uno scrittore appassionato e un creatore di contenuti entusiasta. I problemi più difficili mi eccitano sempre. Attualmente sto studiando il mio B. Tech in Chemical Engineering e ho un vivo interesse per i campi dell'ingegneria dei dati, apprendimento automatico, scienza dei dati e intelligenza artificiale, e sono costantemente alla ricerca di modi per integrare questi campi con altre discipline come la scienza. e chimica per promuovere i miei obiettivi di ricerca.
conclusione:
Spero che il mio articolo ti sia piaciuto e che tu abbia capito cos'è Python in poche parole, che ti fornirà alcune indicazioni mentre inizi il tuo viaggio verso l'apprendimento dell'ingegneria dei dati. Questa è solo la punta dell'iceberg in termini di possibilità.. Ci sono molti argomenti più sofisticati nell'ingegneria dei dati, ad esempio, imparare. tuttavia, prima di poter afferrare tali nozioni, Mi svilupperò nel prossimo articolo. Grazie!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





