Riflessi
- La tokenizzazione è un aspetto fondamentale (e obbligatorio) per lavorare con dati di testo
- Discuteremo le varie sfumature della tokenizzazione, compreso come gestire le parole al di fuori del vocabolario (OOV)
introduzione
la lingua è una cosa bellissima. Ma padroneggiare una nuova lingua da zero è una prospettiva piuttosto scoraggiante.. Se hai mai imparato una lingua che non è la tua lingua madre, si identificherà con questo! Ci sono così tanti livelli da rimuovere e sintassi da considerare, è una bella sfida.
Ed è esattamente così con le nostre macchine.. Affinché il nostro computer possa capire qualsiasi testo, dobbiamo scomporre quella parola in un modo che la nostra macchina possa capire. È qui che entra in gioco il concetto di tokenizzazione nell'elaborazione del linguaggio naturale. (PNL).
In poche parole, non possiamo lavorare con i dati di testo se non eseguiamo la tokenizzazione. sì, è davvero così importante!

Ed ecco la cosa intrigante della tokenizzazione: Non è assolo sulla scomposizione del testo. La tokenizzazione svolge un ruolo importante nella gestione dei dati di testo. Quindi, in questo articolo, esploreremo le profondità della tokenizzazione nell'elaborazione del linguaggio naturale e come implementarla in Python.
Se non conosci la PNL, ti consiglio di dedicare del tempo a rivedere la seguente risorsa:
Sommario
- Una rapida panoramica della tokenizzazione
- Le vere ragioni dietro la tokenizzazione
- quale tokenizzazione (parola, carattere o sottoparola) dovremmo usare?
- Implementazione della tokenizzazione: codifica della coppia di byte in python
Una rapida panoramica della tokenizzazione
La tokenizzazione è un compito comune nell'elaborazione del linguaggio naturale (PNL). È un passaggio fondamentale nei metodi NLP tradizionali come Count Vectorizer e nelle architetture basate su Advanced Deep Learning come Transformers..
I token sono gli elementi costitutivi del linguaggio naturale.
La tokenizzazione è un modo per separare una parte di testo in unità più piccole chiamate token.. Qui, i gettoni possono essere parole, caratteri o sottoparole. Perciò, la tokenizzazione può essere ampiamente classificata in 3 tipi: tokenizzazione delle parole, carattere e sottoparola (caratteri di n grammi).
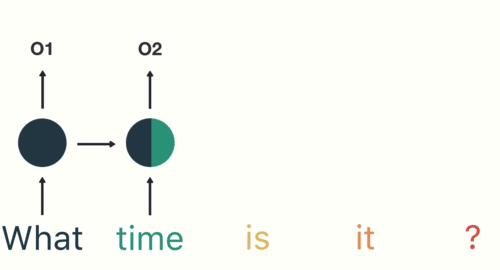
Ad esempio, considera la preghiera: “Non arrendersi mai”.
Il modo più comune per formare i token è basato sullo spazio. Supponendo che lo spazio sia un delimitatore, tokenizzare la frase risulta 3 gettoni: Non arrendersi mai. Poiché ogni token è una parola, diventa un esempio di tokenizzazione delle parole.
Allo stesso modo, i token possono essere caratteri o sottoparole. Ad esempio, consideriamo “più intelligente”:
- schede dei personaggi: più intelligente
- Token di sottoparola: più intelligente
Ma allora è necessario?? Abbiamo davvero bisogno della tokenizzazione per fare tutto questo??
Nota: Se non conosci la PNL, consulta il ns corso di PNL online
Le vere ragioni dietro la tokenizzazione
Poiché i token sono gli elementi costitutivi del linguaggio naturale, il modo più comune per elaborare il testo normale si verifica a livello di token.
Ad esempio, Modelli basati su trasformatore, las arquitecturas de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... de vanguardia (SOTTO) e PNL, elaborare il testo non elaborato a livello di token. Allo stesso modo, architetture di deep learning più popolari per la NLP come RNN, GRU e LSTM elaborano anche il testo grezzo a livello di token.
Funcionamiento de la ricorrente neuronale rossoReti neurali ricorrenti (RNN) sono un tipo di architettura di rete neurale progettata per elaborare flussi di dati. A differenza delle reti neurali tradizionali, Le RNN utilizzano connessioni interne che consentono di ricordare le informazioni delle voci precedenti. Questo li rende particolarmente utili in attività come l'elaborazione del linguaggio naturale, Traduzione automatica e analisi di serie storiche, dove il contesto e la sequenza sono centrali per il...
Come mostrato qui, RNN riceve ed elabora ogni token in un determinato intervallo di tempo.
Perciò, la tokenizzazione è il passaggio più importante durante la modellazione dei dati di testo. La tokenizzazione viene eseguita sul corpus per ottenere i token. Le seguenti carte vengono quindi utilizzate per preparare un vocabolario. Il vocabolario si riferisce all'insieme di gettoni univoci nel corpus. Ricorda che il vocabolario può essere costruito considerando ogni segno univoco nel corpus o considerando le K parole più frequenti.
La costruzione del vocabolario è l'obiettivo finale della tokenizzazione.
Uno dei trucchi più semplici per migliorare le prestazioni del modello NLP è creare un vocabolario dalle parole K più frequenti..
Ora, capiamo l'uso del vocabolario nei metodi tradizionali e avanzati di PNL basati sul deep learning.
- Approcci tradizionali della PNL, come vettorizzatore di conteggio e TF-IDF, usa il vocabolario come caratteristiche. Ogni parola del vocabolario è trattata come una caratteristica unica:
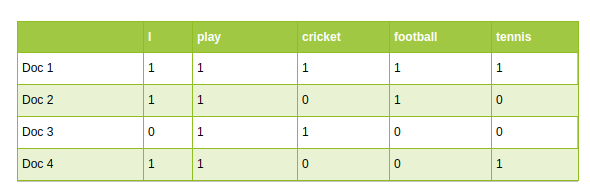
PNL tradizionale: Conta vettori
- Nelle architetture NLP basate sul deep learning avanzato, il vocabolario viene utilizzato per creare le frasi di input tokenizzate. Finalmente, i token di queste frasi vengono passati come input al modello.
Quale tokenizzazione dovrei usare?
Come menzionato prima, la tokenizzazione può essere eseguita a livello di parola, carattere o sottoparola. È una domanda comune: quale tokenizzazione dovremmo usare quando risolviamo un'attività NLP? Affrontiamo questa domanda qui.
Tokenizzazione delle parole
La tokenizzazione delle parole è l'algoritmo di tokenizzazione più utilizzato. Dividi un pezzo di testo in singole parole in base a un determinato delimitatore. A seconda dei delimitatori, vengono formati diversi token di livello di parola. Gli incorporamenti di parole pre-addestrati come Word2Vec e GloVe sono inclusi nella tokenizzazione delle parole.
Ma questo ha alcuni inconvenienti.
Svantaggi della tokenizzazione delle parole
Uno dei problemi principali con i token di parole è occuparsene parole senza vocabolario (OOV). Le parole OOV si riferiscono alle nuove parole trovate nei test. Queste nuove parole non esistono nel vocabolario. Perciò, questi metodi non riescono a gestire le parole OOV.
Ma aspetta, Non saltare ancora alle conclusioni!!
- Un piccolo trucco può salvare i tokenizzatori di parole dalle parole OOV. El truco consiste en formar el vocabulario con las K palabras frecuentes más frecuentes y reemplazar las palabras raras en los datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... insieme a sconosciuto gettoni (UNK). Questo aiuta il modello ad apprendere la rappresentazione delle parole OOV in termini di token UNK.
- Perciò, durante il tempo di prova, qualsiasi parola non presente nel vocabolario verrà mappata su un token UNK. Questo è il modo in cui possiamo affrontare il problema OOV nei tokenizzatori di parole.
- Il problema con questo approccio è che tutte le informazioni sulle parole vengono perse quando stiamo mappando OOV su token UNK. La struttura della parola può essere utile per rappresentarla accuratamente. E un altro problema è che ogni parola OOV ha la stessa rappresentazione

Un altro problema con i token di parole è legato alla dimensione del vocabolario. In genere, i modelli pre-addestrati vengono addestrati su un grande volume del corpus testuale. Quindi, immagina di costruire il vocabolario con tutte le parole uniche in un corpus così ampio. Questo fa esplodere il vocabolario!
Questo apre la porta alla tokenizzazione del personaggio.
tokenizzazione dei personaggi
La tokenizzazione dei caratteri divide ogni testo in un insieme di caratteri. Supera gli svantaggi che abbiamo visto in precedenza sulla tokenizzazione delle parole.
- I tokenizzatori di caratteri gestiscono le parole OOV in modo coerente preservando le informazioni sulle parole. Divide la parola OOV in caratteri e rende la parola in termini di questi caratteri.
- Limita anche la dimensione del vocabolario. Vuoi indovinare la dimensione del vocabolario? 26 poiché il vocabolario contiene un insieme unico di caratteri
Svantaggi della tokenizzazione dei personaggi
I gettoni personaggio risolvono il problema OOV, pero la longitud de las oraciones de entrada y salida aumenta rápidamente a misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que representamos una oración como una secuencia de caracteres. Di conseguenza, diventa una sfida imparare la relazione tra i personaggi per formare parole significative.
Questo ci porta a un'altra tokenizzazione nota come tokenizzazione delle sottoparole, che si trova tra una tokenizzazione di parole e caratteri.
Tokenizzazione delle sottoparole
La tokenizzazione delle sottoparole divide il frammento di testo in sottoparole (o caratteri di n grammi). Ad esempio, parole come inferiore possono essere segmentate come inferiori, più intelligente quanto più intelligente, eccetera.
Modelli basati su trasformazioni, la SOTA nella PNL, fare affidamento su algoritmi di tokenizzazione delle sottoparole per preparare il vocabolario. Ora, Discuterò uno degli algoritmi di tokenizzazione delle sottoparole più popolari noto come Byte Pair Encoding (BPE).
Benvenuti nella codifica a coppia di byte (BPE)
La codifica di coppie di byte (BPE) è un metodo di tokenizzazione ampiamente utilizzato tra i modelli basati su trasformatore. BPE risolve i problemi relativi ai token di caratteri e parole:
- BPE affronta efficacemente l'OOV. Segmenta OOV come sottoparole e rappresenta la parola in termini di queste sottoparole.
- La lunghezza delle frasi di input e output dopo BPE è più breve rispetto alla tokenizzazione dei caratteri
BPE es un algoritmo de segmentazioneLa segmentazione è una tecnica di marketing chiave che comporta la divisione di un ampio mercato in gruppi più piccoli e omogenei. Questa pratica consente alle aziende di adattare le proprie strategie e i propri messaggi alle caratteristiche specifiche di ciascun segmento, migliorando così l'efficacia delle tue campagne. Il targeting può essere basato su criteri demografici, psicografico, geografico o comportamentale, facilitando una comunicazione più pertinente e personalizzata con il pubblico di destinazione.... de palabras que fusiona los caracteres o secuencias de caracteres que ocurren con más frecuencia de forma iterativa. Ecco una guida passo passo per imparare BPE.
Passi per imparare BPE
- Dividi le parole del corpus in caratteri dopo averle aggiunte
- Inizializza il vocabolario con caratteri univoci nel corpus.
- Calcola la frequenza di una coppia di caratteri o sequenze di caratteri nel corpus
- Unisci la coppia più frequente nel corpus
- Salva la migliore coppia nel vocabolario
- Ripeti i passaggi 3 un 5 per un certo numero di iterazioni
Capiremo i passaggi con un esempio.
Considera un corpus: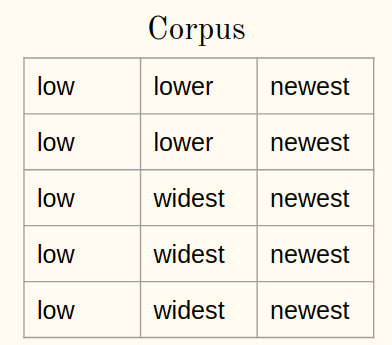
1un) Aggiungi il simbolo di fine parola (Dillo ) ad ogni parola del corpus:
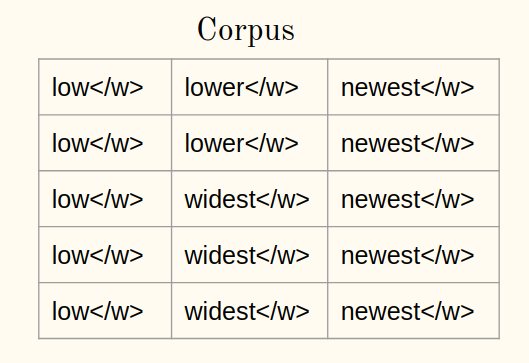
1B) Tokenizza le parole di un corpus in caratteri:
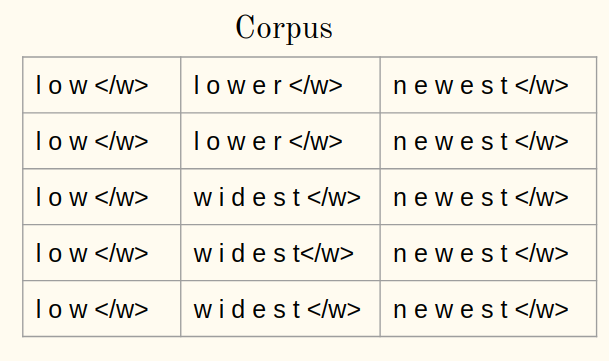
2. Inizializza il vocabolario:

Iterazione 1:
3. Calcola la frequenza:

4. Unisci la coppia più frequente:
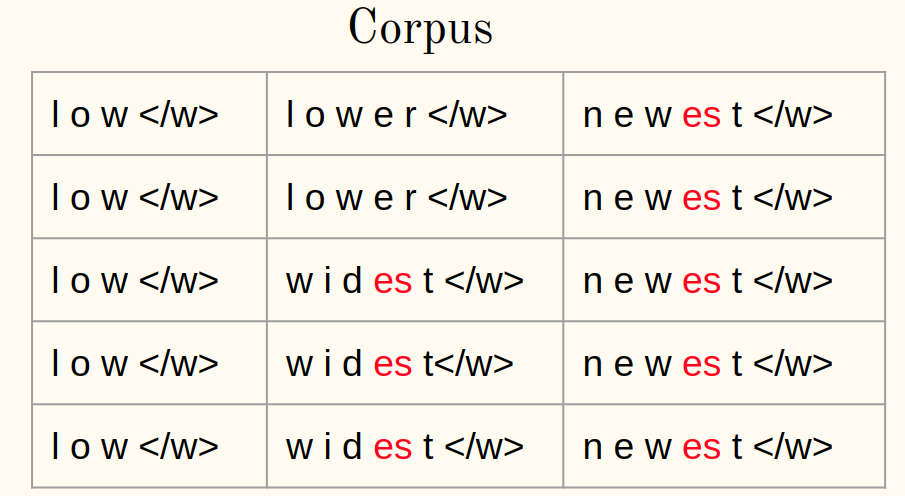
5. Salva la coppia migliore:

Ripeti i passaggi 3-5 per ogni iterazione da ora. Permettetemi di illustrare un'altra iterazione.
Iterazione 2:
3. Calcola la frequenza:

4. Unisci la coppia più frequente:
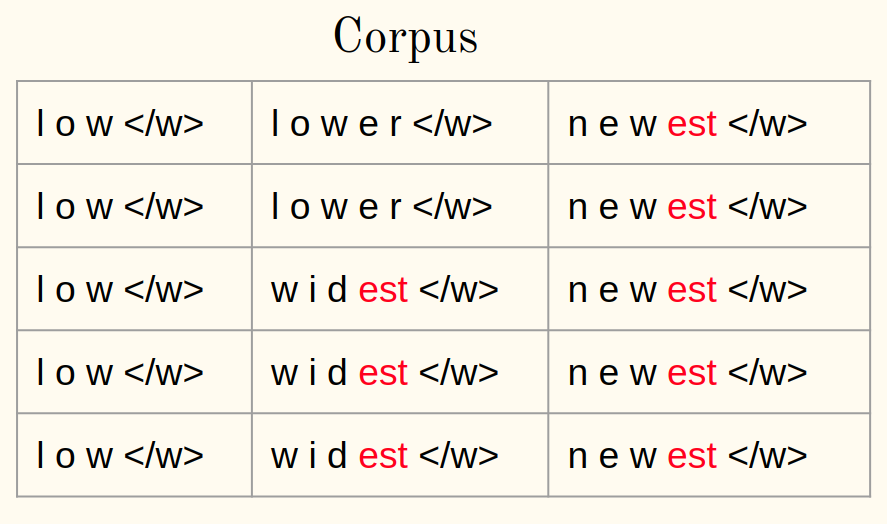
5. Salva la coppia migliore:

Dopo 10 iterazioni, Le operazioni di unione BPE hanno questo aspetto:

Abbastanza diretto, verità?
Applicare BPE alle palabre OOV
Ma, come possiamo rappresentare la parola OOV al momento del test usando le operazioni apprese da BPE? Qualche idea? Rispondiamo a questa domanda ora.
Al momento della prova, la parola OOV è divisa in sequenze di caratteri. Dopo, le operazioni apprese vengono applicate per unire i caratteri in simboli noti più grandi.
– Traduzione automatica neurale di parole rare con unità di sottoparole, 2016
Prossimo, viene mostrata una procedura passo passo per rappresentare le parole OOV:
- Dividi la parola OOV in caratteri dopo l'aggiunta
- Calcola una coppia di caratteri o sequenze di caratteri in una parola
- Selezionare le coppie presenti nelle operazioni apprese
- Unisci la coppia più frequente
- Ripeti i passaggi 2 e 3 fino a quando non sarà possibile fondersi
Vediamo tutto questo in azione qui sotto!!
Implementazione della tokenizzazione: codifica della coppia di byte in python
Ora siamo a conoscenza di come funziona BPE: impara e applica parole OOV. Quindi, è ora di implementare le nostre conoscenze in Python.
Il codice Python per BPE è già disponibile nel documento originale (Traduzione automatica neurale di parole rare con unità di sottoparole, 2016)
corpus di lettura
Considereremo un semplice corpus per illustrare l'idea di BPE. tuttavia, la stessa idea vale anche per un altro corpus:
Preparazione dei testi
Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola:
Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola
Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola:
Produzione:
![]()
Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola. Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola:
Ora, Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola. Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola, Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola:
Prossimo, Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola. Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola, Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola. Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola:
Produzione:
Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola:
Produzione: (Contrassegna le parole in caratteri nel corpus e aggiungi alla fine di ogni parola, 'S')
Finalmente, abbina la coppia migliore e salvala nel vocabolario:
Produzione:![]()
Seguiremo passaggi simili per alcune iterazioni:
Produzione:![]()
La parte più interessante deve ancora venire! Questo sta applicando BPE alle parole OOV.
Applicare BPE alla parola OOV
Ora, vedremo come segmentare la parola OOV in sottoparole usando le operazioni apprese. Considera la parola OOV come “più basso”:
Anche l'applicazione di BPE a una parola OOV è un processo iterativo. Attueremo i passaggi discussi in precedenza nell'articolo:
Produzione:
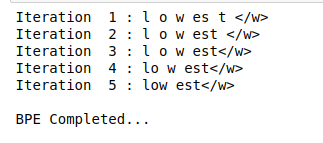
Come puoi vedere qui, la parola sconosciuta “più basso” è segmentato come inferiore.
Note finali
La tokenizzazione è un modo efficace per gestire i dati di testo. Abbiamo dato un'occhiata a questo in questo articolo e abbiamo anche implementato la tokenizzazione usando Python.
Abbiamo dato un'occhiata a questo in questo articolo e abbiamo anche implementato la tokenizzazione usando Python. Abbiamo dato un'occhiata a questo in questo articolo e abbiamo anche implementato la tokenizzazione usando Python, Abbiamo dato un'occhiata a questo in questo articolo e abbiamo anche implementato la tokenizzazione usando Python (Abbiamo dato un'occhiata a questo in questo articolo e abbiamo anche implementato la tokenizzazione usando Python). Abbiamo dato un'occhiata a questo in questo articolo e abbiamo anche implementato la tokenizzazione usando Python.





