introduzione
Una sfida comune in cui mi sono imbattuto nel frattempo imparare l'elaborazione del linguaggio naturale (PNL) – Possiamo costruire modelli per lingue diverse dall'inglese?? La risposta è stata no per un po' di tempo. Ogni lingua ha i suoi schemi grammaticali e sfumature linguistiche. E non ci sono molti set di dati disponibili in altre lingue.
È qui che entra in gioco l'ultima libreria di PNL di Stanford.: StanfordNLP.
Sono riuscito a malapena a contenere la mia eccitazione quando ho letto la notizia la scorsa settimana. Gli autori hanno affermato che StanfordNLP potrebbe supportare più di 53 lingue umane. sì, Ho dovuto ricontrollare quel numero.
Ho deciso di verificarlo di persona. Non esiste ancora un tutorial ufficiale per la libreria, così ho avuto la possibilità di sperimentarlo e giocarci. E ho scoperto che apre un mondo di infinite possibilità. StanfordNLP contiene modelli pre-addestrati per lingue asiatiche rare come l'hindi, Cinese e giapponese nelle loro scritture originali.

La capacità di lavorare con più lingue è una meraviglia che tutti gli appassionati di PNL bramano. In questo articolo, analizzeremo cos'è StanfordNLP, Perché è così importante, e poi attiveremo Python per vederlo dal vivo in azione. Prenderemo anche un caso di studio hindi per mostrare come funziona StanfordNLP, Non vorrai perderlo!
Sommario
- Che cos'è StanfordNLP e perché dovresti usarlo?
- Configurazione StanfordNLP in Python
- Utilizzo di StanfordNLP per eseguire attività di base in PNL
- Implementazione di StanfordNLP in hindi
- Utilizzo dell'API CoreNLP per l'analisi del testo
Che cos'è StanfordNLP e perché dovresti usarlo?
Ecco la descrizione di StanfordNLP dagli stessi autori:
StanfordNLP è la combinazione del pacchetto software utilizzato dal team di Stanford nell'attività condivisa CoNLL 2018 sull'analisi delle dipendenze universali e l'interfaccia Python ufficiale del gruppo per il Software Stanford CoreNLP.
Sono troppe informazioni in una volta!! Rompiamolo:
- CoNLL è una conferenza annuale sull'apprendimento del linguaggio naturale. I team che rappresentano gli istituti di ricerca di tutto il mondo stanno cercando di risolvere un problema. PNL basato sul compito
- Uno dei compiti dell'anno scorso era “Analisi multilingue del testo normale alle dipendenze universali”. In parole povere, significa analizzare dati di testo non strutturati da più lingue in utili annotazioni di dipendenze universali.
- Le dipendenze universali sono un framework che mantiene la coerenza nelle annotazioni. Queste annotazioni vengono generate per il testo indipendentemente dalla lingua analizzata.
- La presentazione di Stanford si è classificata prima in 2017. Hanno perso la prima posizione in 2018 a causa di un bug del software (finito al quarto posto)
StanfordNLP è una raccolta di modelli all'avanguardia pre-addestrati. Questi modelli sono stati utilizzati dai ricercatori nelle competizioni CoNLL. 2017 e 2018. Tutti i modelli sono basati su PyTorch e possono essere addestrati e valutati con i propri dati annotati. Degno di nota!
 ulteriore, StanfordNLP contiene anche un contenitore ufficiale per la popolare libreria NLP gigante: CoreNLP. Questo era stato in qualche modo limitato all'ecosistema Java fino ad ora. Dovresti dare un'occhiata a questo tutorial per saperne di più su CoreNLP e su come funziona in Python.
ulteriore, StanfordNLP contiene anche un contenitore ufficiale per la popolare libreria NLP gigante: CoreNLP. Questo era stato in qualche modo limitato all'ecosistema Java fino ad ora. Dovresti dare un'occhiata a questo tutorial per saperne di più su CoreNLP e su come funziona in Python.
Ecco alcuni altri motivi per cui dovresti dare un'occhiata a questa libreria:
- Implementazione Python nativa che richiede uno sforzo minimo per la configurazione
- Canalización de neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. completa para un análisis de texto sólido, cosa include?:
- Tokenizzazione
- Espansione token multi-parola (MWT)
- Lematizzazione
- Etichettare le parti del discorso (POS) e caratteristiche morfologiche
- Analisi delle dipendenze
- Modelli neurali pre-addestrati che supportano 53 modi di dire (umani) presentato in 73 panchine sugli alberi
- Un'interfaccia Python stabile e ufficialmente mantenuta per CoreNLP
Cosa potrebbe chiedere di più un appassionato di PNL?? Ora che abbiamo un'idea di cosa fa questa libreria, Facciamo un giro in Python!
Configurazione StanfordNLP in Python
Ci sono alcune cose bizzarre della biblioteca che all'inizio mi hanno lasciato perplesso. Ad esempio, hai bisogno Pitone 3.6.8 / 3.7.2 o successivo per usare StanfordNLP. Per essere sicuro, Ho creato un ambiente separato in Anaconda per Pitone 3.7.1. Ecco come puoi farlo:
1. Apri il prompt di conda e digita questo:
conda create -n stanfordnlp python=3.7.1
2. Ora attiva l'ambiente:
sorgente attiva stanfordnlp
3. Installa la libreria StanfordNLP:
pip install stanfordnlp
4. Abbiamo bisogno di scaricare il modello specifico di una lingua per lavorare con esso. Avvia una shell Python e importa StanfordNLP:
import stanfordnlp
quindi scarica il modello linguistico per l'inglese (“Su”):
stanfordnlp.download('Su')
L'operazione potrebbe richiedere del tempo a seconda della tua connessione Internet.. Questi modelli linguistici sono piuttosto grandi (L'inglese è di 1,96 GB).
Un paio di note importanti
- StanfordNLP è basato su PyTorch 1.0.0. Potrebbe bloccarsi se hai una versione precedente. Prossimo, Ti mostriamo come puoi controllare la versione installata sulla tua macchina:
pip congelare | torcia grep
che dovrebbe dare un output come torch==1.0.0
- Ho provato a utilizzare la libreria senza GPU sul mio Lenovo Thinkpad E470 (8GB di RAM, Grafica Intel). Ho ricevuto un errore di memoria in Python abbastanza velocemente. Perciò, sono passato a una macchina abilitata per GPU e ti consiglierei di fare lo stesso anche tu. Puoi provare Google Colab che viene fornito con supporto GPU gratuito
Questo è tutto! Entriamo subito in alcuni processi di base della PNL..
Utilizzo di StanfordNLP per eseguire attività di base in PNL
StanfordNLP è dotato di processori integrati per eseguire cinque attività NLP di base:
- Tokenizzazione
- Espansione token multi-parola
- Lematizzazione
- Etichettatura di parti del discorso
- Analisi delle dipendenze
Iniziamo creando una pipeline di testo:
nlp = stanfordnlp.Pipeline(processori = "tokenizzare,mwt,lemma,posizione")
doc = nlp("""Le prospettive per il ritiro ordinato della Gran Bretagna dall'Unione Europea a marzo 29 si sono ritirati ulteriormente, anche se i parlamentari si sono radunati per fermare uno scenario senza accordo. Un emendamento al disegno di legge sulla cessazione dell'adesione di Londra al blocco obbliga il primo ministro Theresa May a rinegoziare il suo accordo di recesso con Bruxelles. La proposta di un backbencher Tory invita il governo a trovare alternative al backstop irlandese, un principio centrale dell'accordo che la Gran Bretagna ha concordato con il resto dell'UE.""")
il processori = “” L'argomento viene utilizzato per specificare l'attività. Tutti e cinque i processori vengono presi per impostazione predefinita se non vengono passati argomenti. Ecco una rapida panoramica dei processori e di cosa possono fare:

Vediamo ognuno di loro in azione.
Tokenizzazione
Questo processo si verifica implicitamente una volta che il processore token è in esecuzione. Infatti, è abbastanza veloce. Puoi dare un'occhiata ai token usando print_tokens ():
doc.frasi[0].print_tokens()
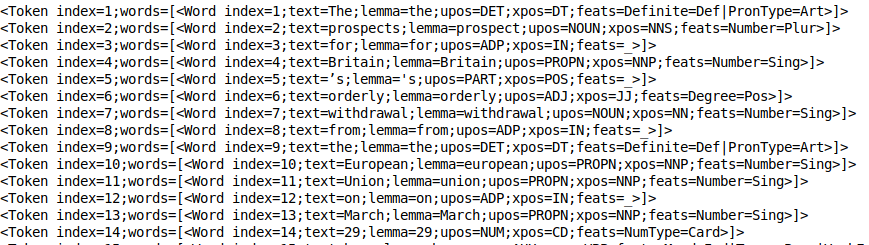
El objeto token contiene el indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... del token en la oración y una lista de objetos de palabra (nel caso di un token multi-parola). Ogni oggetto parola contiene informazioni utili, come indice della parola, il motto del testo, tag postale (parti del discorso) e il tag feat (caratteristiche morfologiche).
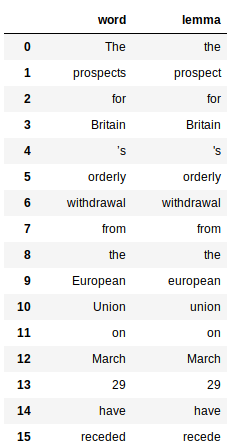
Lematizzazione
Ciò comporta l'uso della proprietà “motto” delle parole generate dal processore di slogan. Ecco il codice per ottenere il motto di tutte le parole:
Questo restituisce un panda data frame per ogni parola e il suo rispettivo motto:
Etichettare le parti del discorso (PoS)
Il tagger PoS è abbastanza veloce e funziona benissimo in tutte le lingue. Come gli slogan, Anche i tag PoS sono facili da rimuovere:
Nota il grande dizionario nel codice sopra? È solo una mappatura tra i tag PoS e il loro significato. Questo aiuta a comprendere meglio la struttura sintattica del nostro documento.
L'output sarebbe un frame di dati con tre colonne: parola, pos ed exp (Spiegazione). La colonna di spiegazione ci fornisce la maggior parte delle informazioni sul testo (e, così, è abbastanza utile).
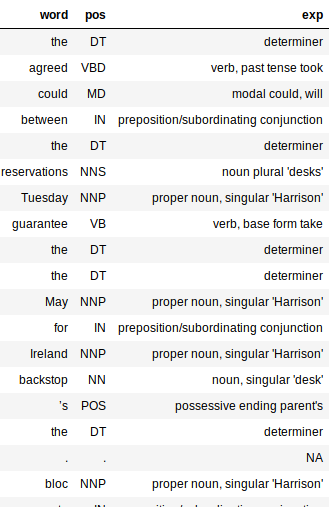
L'aggiunta della colonna di spiegazione rende molto più semplice valutare l'accuratezza del nostro processore. Mi piace il fatto che il tagger sia preciso per la maggior parte delle parole. Cattura anche il tempo di una parola e se è in forma base o plurale.
Estrazione delle dipendenze
L'estrazione delle dipendenze è un'altra funzionalità predefinita di StanfordNLP. Puoi semplicemente chiamare print_dipendenze () in una frase per ottenere i rapporti di dipendenza per tutte le tue parole:
doc.frasi[0].print_dipendenze()

La libreria calcola tutto quanto sopra durante una singola esecuzione della pipeline. Questo richiederà solo pochi minuti su una macchina abilitata per GPU.
Ora abbiamo scoperto un modo per eseguire l'elaborazione di testi di base con StanfordNLP. È tempo di approfittare del fatto che possiamo fare lo stesso per gli altri! 51 Le lingue!
Implementazione di StanfordNLP in hindi
StanfordNLP si distingue davvero per le sue prestazioni e il supporto per l'analisi del testo multilingue. Approfondiamo quest'ultimo aspetto.
Elaborazione testi hindi (sceneggiatura devanagari)
Primo, dobbiamo scaricare il modello di lingua hindi (Comparativamente più piccolo!):
stanfordnlp.download('Ciao')
Ora, prendi un frammento di testo hindi come nostro documento di testo:
hindi_doc = nlp("""Il governo Modi al Centro ha presentato venerdì il suo bilancio provvisorio. Il ministro delle Finanze facente funzione Piyush Goyal nel suo bilancio, Lavoro, contribuente, Annunciati i paraurti per tutti, donne comprese. Sebbene, Anche dopo il bilancio c'è stata molta confusione sulla tassa.. Cosa c'era di speciale in questo bilancio provvisorio del governo centrale e chi ha ottenuto cosa?, capire qui in un linguaggio semplice""")
Questo dovrebbe essere sufficiente per generare tutte le etichette. Controlliamo i tag per l'hindi:
extract_pos(hindi_doc)
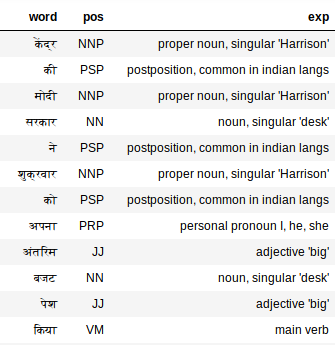
Il tagger PoS funziona sorprendentemente bene anche sul testo hindi. Vista “Mio”, ad esempio. Il tagger PoS lo etichetta come un pronome, me, lui, lei, cos'è esatto?.
Utilizzo dell'API CoreNLP per l'analisi del testo
CoreNLP è un toolkit NLP di livello industriale testato nel tempo, noto per le sue prestazioni e accuratezza. StanfordNLP è stato dichiarato come interfaccia ufficiale Python per CoreNLP. È una GRANDE vittoria per questa libreria.
Ci sono stati sforzi prima di creare pacchetti wrapper Python per CoreNLP, ma niente batte un'implementazione ufficiale degli stessi autori. Ciò significa che la libreria vedrà aggiornamenti e miglioramenti regolari..
StanfordNLP richiede tre righe di codice per iniziare a utilizzare la sofisticata API CoreNLP. Letteralmente, Solo tre righe di codice per configurarlo!!
1. Scarica il pacchetto CoreNLP. Apri il tuo terminale Linux e digita il seguente comando:
wget http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
2. Decomprimi il pacchetto scaricato:
decomprimere stanford-corenlp-full-2018-10-05.zip
3. Avvia il server CoreNLP:
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -tempo scaduto 15000
Nota: CoreNLP richiede Java8 per l'esecuzione. Assicurati di aver installato JDK e JRE 1.8.x.
Ora, assicurati che StanfordNLP sappia dove è presente CoreNLP. Per quello, deve esportare $ CORENLP_HOME come posizione della cartella. Nel mio caso, questa cartella era dentro casa in sé in modo che il mio percorso sia come
esporta CORENLP_HOME=stanford-corenlp-full-2018-10-05/
Una volta eseguiti i passaggi precedenti, puoi avviare il server e fare richieste in codice python. Di seguito è riportato un esempio completo di come avviare un server, effettuare richieste e accedere ai dati dell'oggetto restituito.
un. Configurazione del client CoreNLPC
B. Analisi delle dipendenze e POS
C. Riconoscimento di entità nominate e stringhe di co-riferimento
Gli esempi di cui sopra graffiano a malapena la superficie di ciò che CoreNLP può fare e, tuttavia, è molto interessante, siamo stati in grado di realizzare qualsiasi cosa, dalle attività di base della PNL come l'etichettatura di parti del discorso a cose come il riconoscimento di entità nominate, estrarre stringhe di co-riferimento e trovare chi ha scritto cosa. in una frase in poche righe di codice Python.
Quello che mi piace di più qui è la facilità d'uso e la maggiore accessibilità che ciò comporta quando si tratta di utilizzare CoreNLP in Python.
I miei pensieri sull'utilizzo di StanfordNLP – Pro e contro
Esplorare una libreria appena rilasciata è stata sicuramente una sfida. Non c'è quasi nessuna documentazione su StanfordNLP! tuttavia, è stata un'esperienza di apprendimento piuttosto piacevole.
Alcune cose che mi entusiasmano riguardo al futuro di StanfordNLP:
- Il tuo supporto immediato per più lingue
- Il fatto che sarà un'interfaccia Python ufficiale per CoreNLP. Ciò significa che in futuro migliorerà solo la funzionalità e la facilità d'uso..
- È abbastanza veloce (tranne l'enorme ingombro di memoria)
- Configurazione semplice in Python
tuttavia, ci sono alcune crepe da risolvere. Di seguito sono riportati i miei pensieri sulle aree in cui StanfordNLP potrebbe migliorare:
- La dimensione dei modelli linguistici è troppo grande (L'inglese è di 1,9 GB, cinese ~ 1,8 GB)
- La libreria richiede molto codice per produrre funzioni. Confrontalo con NLTK, dove puoi scrivere velocemente un prototipo; questo potrebbe non essere possibile per StanfordNLP
- Funzionalità di visualizzazione attualmente mancanti. È utile averlo per funzioni come l'analisi delle dipendenze. StanfordNLP non è all'altezza rispetto a librerie come SpaCy
Assicurati di controllare Documentazione ufficiale StanfordNLP.
Note finali
C'è ancora una funzione che non ho ancora provato. StanfordNLP ti consente di addestrare i modelli sui tuoi dati annotati utilizzando gli incorporamenti di Word2Vec / FastText. Mi piacerebbe esplorarlo in futuro e vedere quanto sia efficace questa funzionalità.. Aggiornerò l'articolo quando la libreria matura un po'.
Chiaramente, StanfordNLP è in fase beta. Andrà solo meglio da qui, quindi questo è un buon momento per iniziare a usarlo: avere un vantaggio su tutti gli altri.
Per adesso, il fatto che questi fantastici toolkit (CoreNLP) stanno raggiungendo l'ecosistema Python e giganti della ricerca come Stanford stanno facendo uno sforzo per aprire il loro software open source, Sono ottimista per il futuro.





