introduzione
"Se parli a un uomo in una lingua che capisce, gli va alla testa. Se gli parli nella sua lingua, raggiungerà il tuo cuore “. – Nelson Mandela
La bellezza della lingua trascende i confini e le culture. Imparare una lingua diversa dalla nostra lingua madre è un grande vantaggio. Ma la strada per il bilinguismo, o multilinguismo, spesso può essere lungo e infinito.
Ci sono così tante piccole sfumature che ci perdiamo nel mare delle parole. tuttavia, le cose sono diventate molto più semplici con i servizi di traduzione online (Ti sto guardando Google Translate!).
Ho sempre voluto imparare una lingua diversa dall'inglese. Ho provato a imparare il tedesco (o tedesco) Su 2014. È stato divertente e stimolante. Alla fine ho dovuto rinunciare, ma nutrivo la voglia di ricominciare.

Avanti veloce a 2019, Sono fortunato ad essere in grado di costruire un traduttore di lingue per ogni possibile coppia linguistica. Che grande vantaggio è stata l'elaborazione del linguaggio naturale!!
In questo articolo, Discuteremo i passaggi per creare un modello di traduzione dal tedesco all'inglese utilizzando Keras. Daremo anche una rapida occhiata alla storia dei sistemi di traduzione automatica con il senno di poi..
Questo articolo presuppone familiarità con RNN, LSTM e Keras. Di seguito sono riportati un paio di articoli per saperne di più su di loro:
Sommario
- Traduzione automatica: una breve storia
- Comprendere l'affermazione del problema
- Introduzione alla previsione sequenza per sequenza
- Implementazione in Python usando Keras
Traduzione automatica: una breve storia
La maggior parte di noi è stata introdotta alla traduzione automatica quando Google ha introdotto il servizio. Ma il concetto esiste dalla metà del secolo scorso.
Lavoro di ricerca nella traduzione automatica (MT) iniziato già nel decennio di 1950, principalmente negli Stati Uniti. Questi primi sistemi erano basati su enormi dizionari bilingue, regole codificate a mano e principi universali alla base del linguaggio naturale.
Sopra 1954, IBM ha fatto una prima dimostrazione pubblica di una traduzione automatica. Il sistema aveva un vocabolario abbastanza piccolo di soli 250 parole e potrebbe tradurre solo 49 frasi russe selezionate in inglese. Il numero sembra piccolo ora, ma il sistema è ampiamente considerato come un'importante pietra miliare nel progresso della traduzione automatica.

Questa immagine è stata presa da lavoro di ricerca descrivendo il sistema IBM
Presto sono emerse due scuole di pensiero:
- Approcci empirici per prove ed errori, utilizzando metodi statistici, e
- Approcci teorici che coinvolgono la ricerca linguistica fondamentale
Sopra 1964, il governo degli Stati Uniti ha istituito il comitato consultivo per l'elaborazione automatica del linguaggio (ALPAC) per valutare lo stato di avanzamento della traduzione automatica. L'ALPAC ha insistito un po' e ha pubblicato un rapporto a novembre 1966 sullo stato MT. Di seguito sono riportati i punti salienti di quel rapporto:
- Ha sollevato seri dubbi sulla fattibilità della traduzione automatica, definendola disperata.
- I finanziamenti per la ricerca sulla MT sono stati scoraggiati
- È stato un rapporto piuttosto deprimente per i ricercatori che lavorano in questo campo..
- La maggior parte di loro ha lasciato il campo e ha iniziato nuove carriere.
Non esattamente una raccomandazione brillante!!
Un lungo periodo di siccità ha seguito questo deplorevole rapporto. Finalmente, Su 1981, un nuovo sistema chiamato Sistema METEO schierato in Canada per la traduzione delle previsioni del tempo pubblicate in francese in inglese. È stato un progetto abbastanza riuscito che è rimasto in funzione fino al 2001.
Il primo strumento di traduzione web al mondo, Babele di pesce, è stato lanciato dal motore di ricerca AltaVista at 1997.
E poi è arrivata la svolta che ormai tutti conosciamo: Google Traduttore. Da allora, ha cambiato il nostro modo di lavorare (e abbiamo anche imparato) con lingue diverse.
Fonte: translate.google.com
Comprendere l'affermazione del problema
Torniamo da dove eravamo rimasti nella sezione introduttiva, vale a dire, Per imparare il tedesco. tuttavia, questa volta farò questo compito alla mia macchina. L'obiettivo è convertire una frase tedesca nella sua controparte inglese utilizzando un sistema di traduzione automatica neurale. (NMT).

Utilizzeremo i dati delle coppie di frasi tedesco-inglese di http://www.manythings.org/anki/. Puoi scaricarlo da qui.
Introduzione alla modellazione sequenza per sequenza (Seq2Seq)
Modelli da sequenza a sequenza (seq2seq) sono utilizzati per una varietà di attività di PNL, come riassunto del testo, riconoscimento vocale, Modellazione della sequenza del DNA, tra l'altro. Il nostro obiettivo è tradurre determinate frasi da una lingua all'altra.
Qui, sia l'input che l'output sono frasi. In altre parole, queste frasi sono una sequenza di parole che entrano ed escono da uno schema. Questa è l'idea di base della modellazione sequenza per sequenza.. Quanto segue figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... intenta explicar este método.
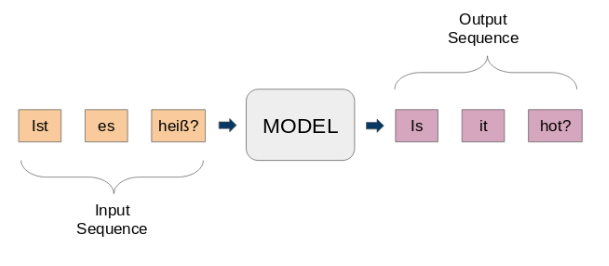
Un tipico modello seq2seq ha 2 componenti principali:
un) un codificatore
B) un decodificatore
Entrambe le parti sono essenzialmente due diversi modelli di reti neurali ricorrenti (RNN) combinati in una rete gigante:
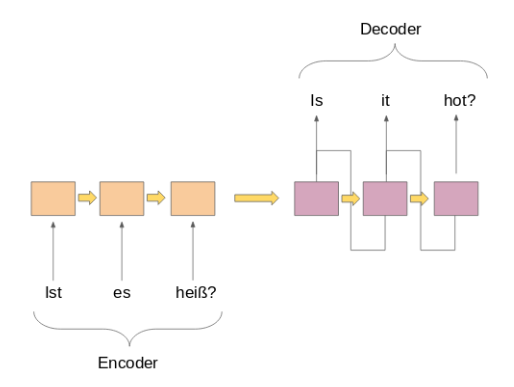
Di seguito ho elencato alcuni importanti casi d'uso della modellazione sequenza per sequenza (a parte la traduzione automatica, Certo):
- Riconoscimento vocale
- Estrazione di entità / soggetto del nome per identificare l'argomento principale di un corpo di testo
- Classificazione delle relazioni per etichettare le relazioni tra più entità etichettate nel passaggio precedente
- Capacità di chatbot per avere capacità di conversazione e interagire con i clienti
- Riepilogo del testo per generare un riassunto conciso di una grande quantità di testo
- Sistemas de respuesta a preguntas
Implementazione in Python usando Keras
¡Es hora de ensuciarnos las manos! No hay mejor sensación que aprender un tema viendo los resultados de primera mano. Arrancaremos nuestro entorno Python favorito (Jupyter Notebook para mí) y nos pondremos manos a la obra.
Importa le librerie richieste
import string import re from numpy import array, argmax, a caso, take import pandas as pd from keras.models import Sequential from keras.layers import Dense, LSTM, Incorporamento, RepeatVector from keras.preprocessing.text import Tokenizer from keras.callbacks import ModelCheckpoint from keras.preprocessing.sequence import pad_sequences from keras.models import load_model from keras import optimizers import matplotlib.pyplot as plt %matplotlib inline pd.set_option('display.max_colwidth', 200)
Lea los datos en nuestro IDE
Nuestros datos son un archivo de texto (.Il Predictive Power Score è un'alternativa alla matrice di correlazione) de pares de oraciones inglés-alemán. Primo, leeremos el archivo usando la función definida a continuación.
# function to read raw text file def read_text(nome del file): # open the file file = open(nome del file, mode="rt", codifica='utf-8') # read all text text = file.read() file.chiudi() testo di ritorno
Definamos otra función para dividir el texto en pares inglés-alemán separados por ‘ n'. Dopo, dividiremos estos pares en oraciones en inglés y oraciones en alemán, rispettivamente.
# split a text into sentences def to_lines(testo): sents = text.strip().diviso('n') sents = [io.diviso('T') for i in sents] return sents
Ahora podemos usar estas funciones para leer el texto en una matriz en nuestro formato deseado.
data = read_text("deu.txt") deu_eng = to_lines(dati) deu_eng = array(deu_ita)
I dati effettivi contengono più di 150.000 coppie di frasi. tuttavia, useremo solo il primo 50,000 pares de oraciones para reducir el tiempo de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... del modello. Puoi modificare questo numero in base alla potenza di calcolo del tuo sistema (O se ti senti fortunato!).
deu_eng = deu_eng[:50000,:]
Pre-elaborazione del testo
Un passo molto importante in qualsiasi progetto, soprattutto in PNL. I dati con cui lavoriamo sono spesso non strutturati, quindi ci sono alcune cose di cui dobbiamo occuparci prima di passare alla parte di costruzione del modello.
(un) Pulizia del testo
Diamo prima un'occhiata ai nostri dati. Questo ci aiuterà a decidere quali passaggi di pre-elaborazione intraprendere.
deu_ita
Vettore([['Ciao.', 'Ciao!'],
['Ciao.', 'Buona giornata!'],
['Correre!', 'Correre!'],
...,
["Mary ha i capelli molto lunghi.", "Maria ha i capelli molto lunghi."],
["Mary è la segretaria di Tom.", "Maria è la segretaria di Tom."],
["Maria è una donna sposata.", "Maria è una donna sposata."]],
dtype="<U380")
Ci sbarazzeremo dei segni di punteggiatura e quindi convertiremo tutto il testo in minuscolo.
# Remove punctuation deu_eng[:,0] = [s.translate(str.maketrans('', '', stringa.punteggiatura)) for s in deu_eng[:,0]] deu_ita[:,1] = [s.translate(str.maketrans('', '', stringa.punteggiatura)) for s in deu_eng[:,1]] deu_ita
Vettore([['Ciao', 'Hallo'], ['Ciao', 'Grüß Gott'], ['Run', 'Lauf'], ..., ['Mary has very long hair', 'Maria hat sehr langes Haar'], ['Mary is Toms secretary', 'Maria ist Toms Sekretärin'], ['Mary is a married woman', 'Maria ist eine verheiratete Frau']], dtype="<U380")
# convert text to lowercase for i in range(len(deu_ita)): deu_ita[io,0] = deu_eng[io,0].inferiore() deu_ita[io,1] = deu_eng[io,1].inferiore() deu_ita
Vettore([['Ciao', 'hallo'], ['Ciao', 'grüß gott'], ['correre', 'lauf'], ..., ['mary has very long hair', 'maria hat sehr langes haar'], ['mary is toms secretary', 'maria ist toms sekretärin'], ['mary is a married woman', 'maria ist eine verheiratete frau']], dtype="<U380")
(B) Conversión de texto a secuencia
Un modelo Seq2Seq requiere que convertimos tanto las oraciones de entrada como las de salida en secuencias enteras de longitud fija.
Pero antes de hacer eso, visualicemos la longitud de las oraciones. Capturaremos la longitud de todas las oraciones en dos listas separadas para inglés y alemán, rispettivamente.
# empty lists eng_l = [] deu_l = [] # populate the lists with sentence lengths for i in deu_eng[:,0]: eng_l.append(len(io.diviso())) for i in deu_eng[:,1]: deu_l.append(len(io.diviso())) length_df = pd.DataFrame({'eng':eng_l, 'deu':deu_l}) length_df.hist(bidoni = 30) plt.mostra()
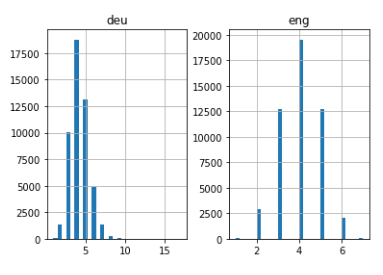
Bastante intuitivo: la longitud máxima de las oraciones en alemán es de 11 y la de las frases en inglés es de 8.
Prossimo, vectorice nuestros datos de texto mediante el uso de Keras Tokenizador () classe. Convertirá nuestras oraciones en secuencias de números enteros. Luego podemos rellenar esas secuencias con ceros para hacer todas las secuencias de la misma longitud.
Tenga en cuenta que prepararemos tokenizadores para las oraciones en alemán e inglés:
# function to build a tokenizer def tokenization(Linee): tokenizer = tokenizzatore() tokenizer.fit_on_texts(Linee) return tokenizer
# prepare english tokenizer eng_tokenizer = tokenization(deu_ita[:, 0]) eng_vocab_size = len(eng_tokenizer.word_index) + 1 eng_length = 8 Stampa('English Vocabulary Size: %D' % eng_vocab_size)
English Vocabulary Size: 6453
# prepare Deutch tokenizer deu_tokenizer = tokenization(deu_ita[:, 1]) deu_vocab_size = len(deu_tokenizer.word_index) + 1 deu_length = 8 Stampa('Deutch Vocabulary Size: %D' % deu_vocab_size)
Deutch Vocabulary Size: 10998
El siguiente bloque de código contiene una función para preparar las secuencias. También realizará el relleno de secuencia hasta una longitud máxima de oración como se mencionó anteriormente.
# encode and pad sequences def encode_sequences(tokenizzatore, lunghezza, Linee): # integer encode sequences seq = tokenizer.texts_to_sequences(Linee) # pad sequences with 0 values seq = pad_sequences(seguito, maxlen=length, padding='post') return seq
Costruzione del modello
Ahora dividiremos los datos en tren y conjunto de prueba para el entrenamiento y la evaluación del modelo, rispettivamente.
da sklearn.model_selection import train_test_split
# split data into train and test set
train, test = train_test_split(deu_ita, test_size=0.2, stato_casuale = 12)
Es hora de codificar las oraciones. Nosotros codificaremos Oraciones en alemán como secuencias de entrada e Oraciones en inglés como secuencias de destino. Esto debe hacerse tanto para el tren como para los conjuntos de datos de prueba.
# prepare training data trainX = encode_sequences(deu_tokenizer, deu_length, treno[:, 1]) trainY = encode_sequences(eng_tokenizer, eng_length, treno[:, 0]) # prepare validation data testX = encode_sequences(deu_tokenizer, deu_length, test[:, 1]) testY = encode_sequences(eng_tokenizer, eng_length, test[:, 0])
¡Ahora viene la parte emocionante!
Comenzaremos definiendo nuestra arquitectura de modelo Seq2Seq:
- Para el codificador, usaremos una capa de incrustación y una capa LSTM
- Para el decodificador, usaremos otra capa LSTM seguida de una strato densoLo strato denso è una formazione geologica che si caratterizza per la sua elevata compattezza e resistenza. Si trova comunemente sottoterra, dove funge da barriera al flusso dell'acqua e di altri fluidi. La sua composizione varia, ma di solito include minerali pesanti, che gli conferisce proprietà uniche. Questo strato è fondamentale nell'ingegneria geologica e negli studi sulle risorse idriche, poiché influenza la disponibilità e la qualità dell'acqua..

Arquitectura del modelo
# build NMT model def define_model(in_vocab,out_vocab, in_timesteps,out_timesteps,units): modello = Sequenziale() modello.aggiungi(Incorporamento(in_vocab, units, input_length=in_timesteps, mask_zero=True)) modello.aggiungi(LSTM(units)) modello.aggiungi(RepeatVector(out_timesteps)) modello.aggiungi(LSTM(units, return_sequences=Vero)) modello.aggiungi(Denso(out_vocab, attivazione='softmax')) modello di ritorno
Estamos utilizando el optimizador RMSprop en este modelo, ya que suele ser una buena opción cuando se trabaja con redes neuronales recurrentes.
# model compilation model = define_model(deu_vocab_size, eng_vocab_size, deu_length, eng_length, 512)
rms = optimizers.RMSprop(lr=0,001) modello.compila(optimizer=rms, perdita="sparse_categorical_crossentropy")
Tenga en cuenta que hemos utilizado ‘sparse_categorical_crossentropy‘como la Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e.... Esto se debe a que la función nos permite usar la secuencia de destino tal como está, en lugar del formato codificado en caliente. La codifica a caldo delle sequenze target utilizzando un vocabolario così ampio potrebbe consumare tutta la memoria del nostro sistema.
Siamo pronti per iniziare ad addestrare il nostro modello!
Ti alleneremo durante 30 volte e con un lotto di 512 con una divisione di convalida del 20%. Il 80% dei dati verrà utilizzato per addestrare il modello e il resto per valutarlo. Puoi cambiare e giocare con questi iperparametri.
Useremo anche il Modello Checkpoint () funzione per salvare il modello con la minima perdita di convalida. Personalmente prefiero este método a la parada anticipada.
nome file="model.h1.24_jan_19" checkpoint = ModelCheckpoint(nome del file, monitor="val_loss", verboso=1, save_best_only=Vero, mode="min") # train model history = model.fit(trenoX, trainY.reshape(trainY.shape[0], trainY.shape[1], 1), epoche=30, batch_size=512, validation_split = 0.2,callbacks=[posto di blocco], verboso=1)
Comparemos la pérdida de entrenamiento y la pérdida de validación.
plt.trama(history.history['perdita']) plt.trama(history.history['val_loss']) plt.legend(['treno','validation']) plt.mostra()
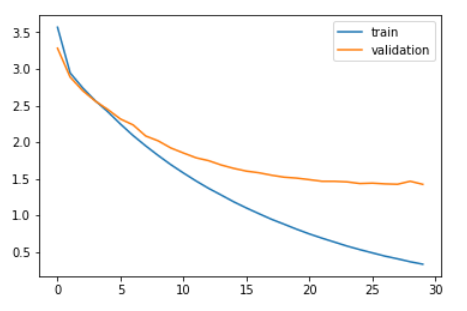
Como puede ver en el gráfico anterior, la pérdida de validación dejó de disminuir después de 20 epoche.
Finalmente, podemos cargar el modelo guardado y hacer predicciones sobre los datos invisibles: testX.
modello = load_model('model.h1.24_jan_19') preds = model.predict_classes(testX.reshape((testX.shape[0],testX.shape[1])))
Estas predicciones son secuencias de números enteros. Necesitamos convertir estos números enteros en sus palabras correspondientes. Definamos una función para hacer esto:
def get_word(n, tokenizzatore): per parola, index in tokenizer.word_index.items(): if index == n: return word return None
Convertir predicciones en texto (inglese):
preds_text = [] for i in preds: temperatura = [] per j nell'intervallo(len(io)): t = get_word(io[J], eng_tokenizer) se j > 0: Se (t == get_word(io[j-1], eng_tokenizer)) o (t == None): temp.append('') altro: temp.append else: Se(t == None): temp.append('') altro: temp.append preds_text.append(' '.aderire(temperatura))
Pongamos las oraciones originales en inglés en el conjunto de datos de prueba y las oraciones predichas en un marco de datos:
pred_df = pd.DataFrame({'actual' : test[:,0], 'predicted' : preds_text})
Podemos imprimir aleatoriamente algunas instancias reales frente a las previstas para ver cómo funciona nuestro modelo:
# Stampa 15 rows randomly
pred_df.sample(15)
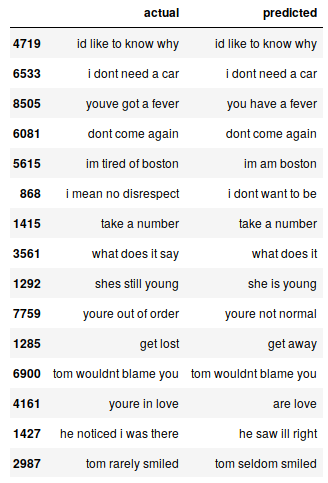
Nuestro modelo Seq2Seq hace un trabajo decente. Pero hay varios casos en los que pierde la comprensión de las palabras clave. Ad esempio, se traduce “estoy cansado de Boston” di “soy de Boston”.
Estos son los desafíos a los que se enfrentará de forma habitual en la PNL. Pero estos no son obstáculos inamovibles. Possiamo mitigare queste sfide utilizzando più dati di addestramento e costruendo un modello migliore. (o più complesso).
Puoi accedere al codice completo da questo Github deposito.
Note finali
Anche con un modello Seq2Seq molto semplice, i risultati sono abbastanza incoraggianti. Possiamo facilmente migliorare queste prestazioni utilizzando un modello di codec più sofisticato su un set di dati più ampio..
Un altro esperimento che mi viene in mente è testare l'approccio seq2seq su un set di dati che contiene frasi più lunghe. Più sperimento, più imparerai a conoscere questo spazio vasto e complesso.
Se hai commenti su questo articolo o hai domande / domanda, per favore condividilo nella sezione commenti qui sotto.





