Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Le sezioni della tua melodia principale sono una specie di graffi nella ragnatela! Indipendentemente, parole “Graffi Web” in generale si tratta di una connessione che incorpora l'informatizzazione. Un paio di destinazioni potrebbero farne a meno quando i debugger personalizzati raccolgono i loro dati, mentre ad altri non importerebbe.
Sperando che tu stia deliberatamente grattando una pagina per elementi informativi, Presumibilmente non avrai problemi. Tutto sommato, È una buona idea fare una valutazione isolata e assicurarsi di non ignorare i Termini di servizio prima di iniziare un gigantesco progetto di laurea. Per prendere confidenza con le parti legali del web scraping, dai un'occhiata alle prospettive legali sul moderno scraping dei dati web.
Perché il web scraping?
Proprio come graffiamo il web, Creiamo un codice che invia una richiesta che funziona con la pagina che abbiamo deciso. Lo specialista restituirà il codice sorgente – HTML, per la maggior parte – della pagina (o Pagine) a cui abbiamo fatto riferimento.
Fino a tempi molto recenti, Fondamentalmente stiamo facendo più di un programma web: invia interesse con un URL specifico e menziona che lo specialista restituisce il codice per quella pagina.
In ogni caso, a differenza di un programma web, Il nostro codice di scratching web non tradurrà il codice sorgente della pagina e visualizzerà la pagina in modo apparente. Tenendo conto di tutto, Penseremo a un codice personalizzato che si incanala attraverso il codice sorgente della pagina alla ricerca di parti esplicite che abbiamo dimostrato e rimuovendo tutte le sostanze che gli abbiamo insegnato a rimuovere.
Ad esempio, nel caso in cui ci aspettassimo di ottenere il totale dei dati all'interno di una tabella apparsa su una pagina del sito, Il nostro codice verrebbe formato per seguire questi metodi nella raccolta:
1 Domanda di merito (codice sorgente) di un URL specifico del lavoratore
2 Scaricare la sostanza che viene restituita.
3 Distingue i segmenti della pagina che sono critici per la tabella di cui abbiamo bisogno.
4 Concentrati e (Se è fondamentale) Riformattare quei segmenti in un set di dati che possiamo smontare o utilizzare in qualsiasi modo di cui abbiamo bisogno.
Se tutto ciò sembra particolarmente complicato, Non premere! Python e Beautiful Soup hanno caratteristiche naturali proposte per rendere questo per la maggior parte immediato.
Una cosa che è fondamentale tenere a mente: Dal punto di vista di uno specialista, Fare riferimento a una pagina tramite lo scratching web è paragonabile all'impilarla in un programma web. Esattamente quando usiamo il codice per introdurre queste richieste, Potremmo essere “Impilamento” pagine significativamente più veloci di un client standard, e quindi consumando rapidamente le risorse umane del proprietario del sito.
Dati di web scraping per l'apprendimento automatico:
Nel caso in cui si raschi i dati per l'intelligenza artificiale, Prometti di aver controllato la presenza di basse concentrazioni prima di avvicinarti all'estrazione dei dati.
Formato dati:
I modelli di intelligenza simulata possono semplicemente aumentare bruscamente la popolarità dei dati che si trovano in un'associazione semplice o simile a una tabella. In questo senso, Lo scraping dei dati non strutturati richiederà, in questo modo, Maggiore libertà di prendersi cura dei dati prima che possano essere utilizzati.
Elenco dati:
Poiché l'obiettivo principale è l'intelligenza artificiale, Quando si dispone delle posizioni o delle pagine Web che si desidera eliminare, È necessario fare una panoramica dei data center o delle origini dati che si desidera rimuovere da ogni pagina del sito. Se il caso è con l'obiettivo finale di perdere un gran numero di data center per ogni pagina del sito, Quindi è necessario tagliare e scegliere i data center che di solito sono presenti. La ragione di ciò è che così tante NA o funzionalità vuote ridurranno la presentazione e l'accuratezza del modello di intelligenza artificiale (ML) che si allena e testa con i dati.
Etichettatura dei dati:
Il fact-checking può essere un'agonia cerebrale. In ogni caso, se è possibile accumulare i metadati necessari durante lo scraping dei dati e archiviarli come punto dati alternativo, Beneficiare delle fasi corrispondenti del ciclo di vita dei dati.
Pulito, Preparare e archiviare i dati
Anche se questa mossa può sembrare fondamentale, Di solito è forse l'avanzata più ingarbugliata e triste. Questo è il risultato diretto di un chiaro chiarimento: Non esiste una connessione valida per tutti. Dipende da quali dati hai eliminato e da dove li hai eliminati. Avrai bisogno di strategie rapide per ripulire i dati.
Soprattutto, è necessario esaminare i dati per capire quali degradazioni si trovano nelle origini dati. Puoi farlo utilizzando una libreria come Pandas (disponibile in Python). Al momento della valutazione, È necessario creare una sostanza per eliminare le deformità nelle fonti di dati e normalizzare i data center che non sono come gli altri. Dopo, Eseguirebbe controlli di grandi dimensioni per verificare se i data center hanno tutti i dati in un singolo tipo di dati. Un frammento che deve contenere numeri non può avere una linea dati. Ad esempio, Uno che deve contenere dati nella configurazione DD / mm / AAAA non può contenere dati in nessun'altra associazione. Oltre a questi controlli del piano, Le funzionalità mancanti, funzionalità non valide e quant'altro che possa interrompere il trattamento dei dati, Devono essere percepiti e corretti.
Perché scegliere Python per il web scraping?
Python è un noto dispositivo per l'esecuzione di web scratching. Il linguaggio di programmazione Python viene utilizzato anche per altre preziose attività identificate con la sicurezza della rete, Test di accesso e applicazioni misurabili avanzate. Utilizzo della programmazione Python di base, Il web scraping può essere eseguito senza l'utilizzo di altri dispositivi esterni.
Il linguaggio di programmazione Python sta diventando immensamente diffuso e le ragioni che rendono Python un solido abbinamento per i progetti di scratching web sono le seguenti:
Semplicità di punteggio
Python ha la costruzione più semplice rispetto ad altri dialetti di programmazione. Questo elemento di Python semplifica i test e un ingegnere può concentrarsi su una programmazione aggiuntiva.
Moduli integrati
Un'altra giustificazione per l'uso di Python per graffiare il web è l'incorporazione delle preziose librerie esterne che ha. Possiamo eseguire numerose esecuzioni identificate con web scratching utilizzando Python come base per la programmazione.
Linguaggio di programmazione open source
Python ha un grande aiuto dall'area locale in quanto è un linguaggio di programmazione open source.
Ampia gamma di applicazioni
Python può essere utilizzato per diversi incarichi di programmazione che vanno da piccoli contenuti di shell a grandi applicazioni web aziendali.
Moduli Python per il web scraping
Il web scraping è il percorso per sviluppare uno specialista in grado di estrarre, analizzare, scaricare e coordinare di conseguenza dati preziosi dal web. Alla fine del giorno, invece di memorizzare fisicamente le informazioni del sito, La programmazione Web Scratching caricherà e concentrerà le informazioni da diversi siti in base al nostro prerequisito.
Applicazione
È una semplice libreria scratch web Python. Si tratta di un'efficace libreria HTTP che viene utilizzata per accedere alle pagine. Con l'aiuto di Richieste, possiamo ottenere l'HTML grezzo dalle pagine del sito che potrebbero poi essere analizzate per recuperare le informazioni.
Bella zuppa
Beautiful Soup è una libreria Python per l'estrazione di informazioni da record HTML e XML. Tende ad essere utilizzato con le esigenze, dal momento che hai bisogno di un'informazione (rapporto o URL) per fare un oggetto zuppa, dal momento che non è possibile portare una pagina dal sito senza l'aiuto di nessun altro. È possibile utilizzare il contenuto Python allegato per assemblare il titolo della pagina e i collegamenti ipertestuali.
Codice –
import urllib.request from urllib.request import urlopen, Request from bs4 import BeautifulSoup wiki= "https://www.thestar.com.my/search/?q=HIV&qsort=il più vecchio&qrec=10&qstockcode=&pgno=1" html=urlopen(wiki) bs= BeautifulSoup(html,'lxml') bs Beautiful Soup is used to extract the website page
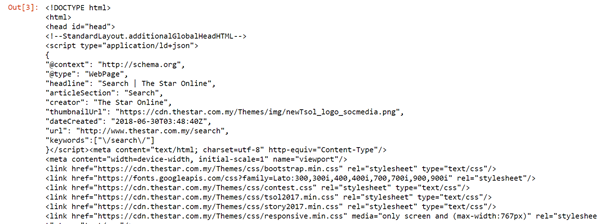
(Fonte immagine: Quaderno Jupyter)
Codice-
from bs4 import BeautifulSoup
base_url="https://www.thestar.com.my/search/?q=HIV&qsort=il più vecchio&qrec=10&qstockcode=&pgno="
# Aggiungere 1 perché intervallo Python.
url_list = ["{}{}".formato(base_url, str(pagina)) per pagina nell'intervallo(1, 408)]
s=[]
per l'URL in url_list:
Stampa (URL)
S.append(URL)
Produzione-
Il codice sopra elencherà il numero di pagine web nell'intervallo di 1 un 407.
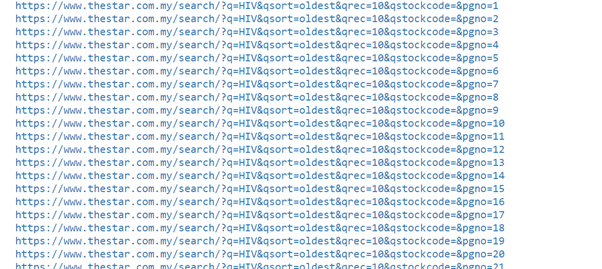
(Fonte immagine: Quaderno Jupyter)
Codice –
dati = [] dati1= [] import csv from urllib.request import urlopen, HTTPError from datetime import datetime, timedelta for pg in s: # query the website and return the html to the variable 'page' page = urllib.request.urlopen(Pg) Tentativo: search_response = urllib.request.urlopen(Pg) tranne urllib.request.HTTPError: passaggio # parse the html using beautiful soap and store in variable `soup` soup = BeautifulSoup(pagina, 'html.parser') # Estrarre il <Div> of name and get its value ls = [x.get_text(strip=Vero) per x in soup.find_all("h2", {"classe": "F18"})] ls1= [x.get_text(strip=Vero) per x in soup.find_all("Rotazione", {"classe": "Data"})] # save the data in tuple data.append((ls)) dati1.append(ls1)
Produzione-
El código anterior tomará todos los datos con la ayuda de una hermosa sopa y los guardará en la tupla.
(Fonte immagine: Quaderno Jupyter)
Codice
import pandas as p df=p.DataFrame(F,colonne=['Topic of article']) df['Data']=f1
Produzione-
panda
Pandas es un instrumento de investigación y control de información de código abierto rápido, incredibile, Adattabile e semplice da usare, basato sul linguaggio di programmazione Python.
Il codice precedente memorizza il valore nel frame di dati.

(Fonte immagine: Quaderno Jupyter)
Spero che il codice ti piaccia.
Breve introduzione
Me, Sonia Singla, Ho conseguito un master in bioinformatica presso l'Università di Leicester, Regno Unito. Ho anche realizzato alcuni progetti di data science CSIR-CDRI. Attualmente è membro consultivo del comitato editoriale di IJPBS.
Linkedin – https://www.linkedin.com/in/soniasinglabio/
I contenuti multimediali mostrati in questo articolo sull'implementazione di modelli di apprendimento automatico che sfruttano CherryPy e Docker non sono di proprietà di DataPeaker e vengono utilizzati a discrezione dell'autore.





