Visão geral
- Bancos de dados relacionais são onipresentes, mas o que acontece quando você precisa dimensionar sua infraestrutura?
- Discutiremos a função do Spark SQL nesta situação e entenderemos por que ele é uma ferramenta tão útil para o aprendizado.
- Este tutorial também mostra como o Spark SQL funciona usando um estudo de caso Python
Introdução
Quase todas as organizações usam bancos de dados relacionais para várias tarefas, desde o gerenciamento e rastreamento de uma grande quantidade de informações até a organização e processamento de transações. É um dos primeiros conceitos ensinados a nós na escola de programação.
E sejamos gratos por isso, porque esse é um equipamento crucial no conjunto de habilidades de um cientista de dados!! Você simplesmente não pode sobreviver sem saber como os bancos de dados funcionam. É um aspecto fundamental de qualquer aprendizado de máquina esboço, projeto.
Linguagem de consulta estruturada (SQL) é facilmente a linguagem mais popular quando se trata de bancos de dados. Ao contrário de outras linguagens de programação, é fácil de aprender e nos ajuda a iniciar nosso processo de extração de dados. Para a maioria dos empregos de ciência de dados, A proficiência em SQL é mais alta do que a maioria das outras linguagens de programação.

Mas há um grande desafio com SQL: terá dificuldade em fazê-lo funcionar ao lidar com grandes conjuntos de dados. É aqui que o Spark SQL ocupa um lugar de destaque e fecha a lacuna.. Falarei mais sobre isso na próxima seção..
Este tutorial prático irá apresentá-lo ao mundo do Spark SQL, como funciona, quais são os diferentes recursos que ele oferece e como você pode implementá-lo usando python. Também falaremos sobre um conceito importante que você encontrará com frequência em entrevistas.: o otimizador de catalisador.
Comecemos!
Observação: Se você é completamente novo no mundo SQL, Eu recomendo fortemente o seguinte curso:
Tabela de conteúdo
- Desafios com escalonamento de banco de dados relacional
- Visão geral do Spark SQL
- Recursos do Spark SQL
- Como o Spark SQL executa uma consulta?
- O que é um Catalyst Optimizer?
- Executar comandos SQL com Spark
- Uso de Apache SparkO Apache Spark é um mecanismo de processamento de dados de código aberto que permite a análise de grandes volumes de informações de forma rápida e eficiente. Seu design é baseado na memória, que otimiza o desempenho em comparação com outras ferramentas de processamento em lote. O Spark é amplamente utilizado em aplicativos de big data, Aprendizado de máquina e análise em tempo real, graças à sua facilidade de uso e... a escala
Desafios com escalonamento de banco de dados relacional
A questão é por que devo aprender Spark SQL? Eu mencionei isso brevemente antes, mas vamos olhar com um pouco mais de detalhes agora.
Bancos de dados relacionais para um grande projeto (aprendizado de máquina) contém centenas ou talvez milhares de tabelas e a maioria dos recursos em uma tabela mapeia para outros recursos em outras tabelas. Esses bancos de dados são projetados para rodar apenas em uma única máquina, a fim de manter as regras de mapeamento de tabelas e evitar os problemas de computação distribuída..
Isso geralmente se torna um problema para as organizações quando desejam escalar com esse design.. Isso exigiria hardware mais complexo e caro, com significativamente mais capacidade de processamento e armazenamento. Como você pode imaginar, Atualizar de um hardware mais simples para um hardware mais complexo pode ser um grande desafio.
Uma organização pode precisar deixar seu site off-line por algum tempo para fazer as mudanças necessárias. Durante este período, perderia negócios com novos clientes que eles poderiam ter adquirido.
O que mais, uma mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que aumenta el volumen de datos, as organizações lutam para lidar com essa enorme quantidade de dados usando bancos de dados relacionais tradicionais. É aqui que o Spark SQL entra em cena..
Visão geral do Spark SQL
““
~
Hadoop y los marcos MapReduceO MapReduce é um modelo de programação projetado para processar e gerar grandes conjuntos de dados com eficiência. Desenvolvido pelo Google, Essa abordagem divide o trabalho em tarefas menores, que são distribuídos entre vários nós em um cluster. Cada nó processa sua parte e, em seguida, os resultados são combinados. Esse método permite dimensionar aplicativos e lidar com grandes volumes de informações, sendo fundamental no mundo do Big Data.... han existido durante mucho tiempo en el análisis de big data. Mas esses quadros exigem muitas operações de leitura e gravação em um disco rígido, o que os torna muito caros em termos de tempo e velocidade.
Apache Spark é a estrutura de processamento de dados mais eficiente nas empresas hoje. É verdade que o custo do Spark é alto, pois requer muita RAM para cálculos na memória, mas ainda é um favorito entre os cientistas de dados e engenheiros de big data.
No ecossistema Spark, nós temos os seguintes componentes:
- MLlib: Esta é a biblioteca de aprendizado de máquina escalonável do Spark que fornece algoritmos de alta qualidade para regressão, agrupamento, classificação, etc. Você pode começar a criar pipelines de aprendizado de máquina usando MLlib do Spark usando este artigo: Como criar pipelines de aprendizado de máquina usando PySpark?
- Spark Streaming: Estamos gerando dados em uma escala e taxa sem precedentes agora. Como podemos garantir que nosso pipeline de aprendizado de máquina continue produzindo resultados assim que os dados são gerados e coletados? Aprenda a usar um modelo de aprendizado de máquina para fazer previsões sobre a transmissão de dados com o PySpark?
- GraphX: É uma API Spark para gráficos, um motor gráfico de rede que suporta computação gráfica paralela.
- Spark SQL: Esta é uma estrutura distribuída para processamento de dados estruturados fornecida pelo Spark
Sabemos que os bancos de dados relacionais também armazenam as relações entre as diferentes variáveis, bem como as diferentes tabelas, e são projetados de forma que possam lidar com consultas complexas..
Spark SQL é uma combinação incrível de processamento relacional e programação funcional do Spark.. Fornece suporte para várias fontes de dados e torna possíveis as consultas SQL, resultando em uma ferramenta muito poderosa para analisar dados estruturados em escala.
Recursos do Spark SQL
Spark SQL tem muitos recursos incríveis, mas eu queria destacar algumas teclas que você usará muito em sua função:
- Consultar dados de estrutura em programas Spark: A maioria de vocês já deve estar familiarizado com SQL. Portanto, você não precisa aprender a definir uma função complexa em Python ou Scala para usar o Spark. Você pode usar exatamente a mesma consulta para obter os resultados de seus maiores conjuntos de dados!!
- Compatible con ColmeiaHive é uma plataforma de mídia social descentralizada que permite que seus usuários compartilhem conteúdo e se conectem com outras pessoas sem a intervenção de uma autoridade central. Usa a tecnologia blockchain para garantir a segurança e a propriedade dos dados. Ao contrário de outras redes sociais, O Hive permite que os usuários monetizem seu conteúdo por meio de recompensas criptográficas, que incentiva a criação e a troca ativa de informações ....: Sem SQL solo, mas você também pode executar as mesmas consultas do Hive com o Spark SQL Engine. Permite compatibilidade total com as consultas atuais do Hive.
- Uma maneira de acessar os dados: Em projetos típicos de nível empresarial, não tem uma fonte de dados comum. Em seu lugar, deve lidar com vários tipos de arquivos e bancos de dados. Spark SQL oferece suporte a quase todos os tipos de arquivo e oferece uma maneira comum de acessar uma variedade de fontes de dados, como colmeia, Euro, Parquet, JSONJSON, o Notação de objeto JavaScript, É um formato leve de troca de dados que é fácil para os humanos lerem e escreverem, e fácil para as máquinas analisarem e gerarem. É comumente usado em aplicativos da web para enviar e receber informações entre um servidor e um cliente. Sua estrutura é baseada em pares de valores-chave, tornando-o versátil e amplamente adotado no desenvolvimento de software.. y JDBC
- Desempenho e escalabilidade: Ao trabalhar com grandes conjuntos de dados, há chances de ocorrerem erros entre o momento em que a consulta é executada. Spark SQL oferece suporte total a tolerância a falhas no meio da consulta, para que possamos trabalhar até mesmo com mil nós simultaneamente
- Funções definidas pelo usuário: UDF é um recurso do Spark SQL que define novas funções baseadas em colunas que estendem o vocabulário do Spark SQL para transformar conjuntos de dados
Como o Spark SQL executa uma consulta?
Como funciona o Spark SQL, essencialmente? Vamos entender o processo nesta seção.
- Análise: Primeiro, quando você consulta algo, Spark SQL encontra a relação a ser calculada. É calculado usando uma árvore de sintaxe abstrata (AST) onde você verifica o uso correto dos elementos usados para definir a consulta e, em seguida, cria um plano lógico para executar a consulta.

- Otimização lógica: Nesta próxima etapa, a otimização baseada em regras é aplicada ao plano lógico. Use técnicas como:
- Filtre os dados com antecedência se a consulta contiver um Onde cláusula
- Use o índiceo "Índice" É uma ferramenta fundamental em livros e documentos, que permite localizar rapidamente as informações desejadas. Geralmente, é apresentado no início de um trabalho e organiza os conteúdos de forma hierárquica, incluindo capítulos e seções. Sua correta preparação facilita a navegação e melhora a compreensão do material, tornando-se um recurso essencial para estudantes e profissionais de várias áreas.... disponible en las tablas, pois pode melhorar o desempenho, e
- Mesmo garantindo que as diferentes fontes de dados sejam reunidas na ordem mais eficiente.
- Planejamento físico: Nesta etapa, um ou mais planos físicos são formados usando o plano lógico. Spark SQL então seleciona o plano que será capaz de executar a consulta da maneira mais eficiente, quer dizer, usando menos recursos computacionais.
- Código de GERAÇÃO: Na etapa final, Spark SQL gera código. Envolve a geração de um bytecode Java para rodar em cada máquina. O Catalyst usa um recurso especial da linguagem Scala chamado “Quasiquotes” para facilitar a geração de código.

O que é um Catalyst Optimizer?
Otimização significa atualizar o sistema ou fluxo de trabalho existente de forma que funcione de forma mais eficiente, enquanto usa menos recursos. Um otimizador conhecido como Catalyst Optimizer é implementado em Spark SQL que suporta técnicas de otimização baseadas em regras e baseadas em custos.
Na otimização baseada em regras, definimos um conjunto de regras que determinarão como a consulta será executada. Ele irá reescrever a consulta existente de uma maneira melhor para melhorar o desempenho.
Por exemplo, digamos que haja um índice disponível na mesa. Mais tarde, o índice será usado para a execução da consulta de acordo com as regras e filtros ONDE serão aplicados primeiro nos dados iniciais, se possível (em vez de aplicá-los por último).
O que mais, existem alguns casos em que o uso de um índice desacelera uma consulta. Sabemos que nem sempre é possível que um conjunto de regras definidas sempre tome boas decisões, verdade?
Aqui está o problema: a otimização baseada em regras não leva em consideração a distribuição de dados. É aqui que nos voltamos para um Otimizador baseado em custos. Use estatísticas sobre a mesa, seus índices e distribuição de dados para tomar melhores decisões.
Executar comandos SQL com Spark
Hora de codificar!
Eu criei um conjunto de dados aleatórios de 25 milhões de linhas. Você pode baixar o conjunto de dados completo aqui. Temos um arquivo de texto com valores separados por vírgulas. Então, primeiro, vamos importar as bibliotecas necessárias, vamos ler o conjunto de dados e ver como o Spark irá particionar os dados em partições:
![]()
Aqui,
- O primeiro valor em cada linha é a idade da pessoa (que deve ser um número inteiro)
- O segundo valor é o grupo sanguíneo da pessoa (que deve ser uma string)
- O terceiro e o quarto valores são cidade e gênero (ambos são correntes), e
- O valor final é um id (que é do tipo inteiro)
Iremos mapear os dados em cada linha para um tipo de dados e nome específicos usando linhas do Spark:
![]()

A seguir, vamos criar um quadro de dados usando as linhas analisadas. Nuestro objetivo es encontrar los recuentos de valores de la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... de género mediante el uso de un simple agrupar por função no quadro de dados:

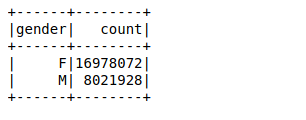

Demorou 26 ms para calcular a contagem de valores de 25 milhões de linhas usando uma função groupby no quadro de dados. Você pode calcular o tempo usando %%clima na cela privada de seu caderno Jupyter.
Agora, vamos realizar a mesma consulta usando Spark SQL e ver se melhora o desempenho ou não.
Primeiro, você precisa registrar o quadro de dados como uma tabela temporária usando a função registerTempTable. Esto crea una tabla en memoria que solo tiene como ámbito el cachoUm cluster é um conjunto de empresas e organizações interconectadas que operam no mesmo setor ou área geográfica, e que colaboram para melhorar sua competitividade. Esses agrupamentos permitem o compartilhamento de recursos, Conhecimentos e tecnologias, Promover a inovação e o crescimento económico. Os clusters podem abranger uma variedade de setores, Da tecnologia à agricultura, e são fundamentais para o desenvolvimento regional e a criação de empregos.... en el que se creó. La vida útil de esta tabla temporal está limitada a solo una sessãoo "Sessão" É um conceito-chave no campo da psicologia e da terapia. Refere-se a uma reunião agendada entre um terapeuta e um cliente, onde os pensamentos são explorados, Emoções e comportamentos. Essas sessões podem variar em duração e frequência, e seu principal objetivo é facilitar o crescimento pessoal e a resolução de problemas. A eficácia das sessões depende da relação entre o terapeuta e o terapeuta... É armazenado usando Formato de coluna Hive In-Memory que é altamente otimizado para dados relacionais.
O que mais, Você nem mesmo precisa escrever funções complexas para obter resultados se estiver familiarizado com o SQL!! Aqui, você só precisa passar a mesma consulta SQL para obter os resultados desejados em dados maiores:
![]()
Só demorou cerca 18 ms calcula as contagens de valores. Isso é muito mais rápido do que até mesmo um quadro de dados Spark.
A seguir, vamos realizar outra consulta SQL para calcular a idade média em uma cidade:
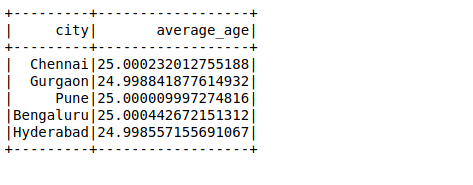
Caso de uso do Apache Spark em escala
Sabemos que o Facebook tem mais do que 2000 milhões de usuários ativos mensais e com mais dados, enfrentam desafios igualmente complexos. Para uma única consulta, precisa analisar dezenas de terabytes de dados em uma única consulta. O Facebook acredita que o Spark amadureceu a ponto de podermos compará-lo ao Hive em vários casos de uso de processamento em lote..
Deixe-me ilustrar isso usando um estudo de caso do próprio Facebook.. Uma das suas tarefas foi preparar as características para o ranking das entidades que o Facebook utiliza nos seus diversos serviços online. Anteriormente, usou a infraestrutura baseada em Hive, que exigia muitos recursos e era difícil de manter, como o pipeline foi dividido em centenas de trabalhos Hive. Em seguida, eles construíram um pipeline mais rápido e gerenciável com Spark. Você pode ler o tour completo aqui.
Han comparado los resultados de Spark vs Hive PipelinePipeline é um termo usado em uma variedade de contextos, principalmente em tecnologia e gerenciamento de projetos. Refere-se a um conjunto de processos ou etapas que permitem o fluxo contínuo de trabalho desde a concepção de uma ideia até sua implementação final. Na área de desenvolvimento de software, por exemplo, Um pipeline pode incluir agendamento, Teste e implantação, garantindo assim maior eficiência e qualidade no.... Aqui está um gráfico de comparação em termos de latência (tempo decorrido de uma ponta a outra do trabalho) o que mostra claramente que o Spark é muito mais rápido do que o Hive.

Notas finais
Abordamos a ideia central por trás do Spark SQL neste artigo e também aprendemos como usá-lo a nosso favor.. Também pegamos um grande conjunto de dados e aplicamos nosso aprendizado em Python.
Spark SQL é relativamente desconhecido para muitos aspirantes à ciência de dados, mas será útil em sua função na indústria ou mesmo em entrevistas. É um acréscimo bastante importante aos olhos do gerente de contratação..
Compartilhe suas idéias e sugestões na seção de comentários abaixo..





