Este artigo foi publicado como parte do Data Science Blogathon
Introdução
A análise de sentimentos refere-se a identificar e classificar os sentimentos expressos no texto fonte.. Os tweets geralmente são úteis para gerar muitos dados de sentimento após a análise. Esses dados são úteis para entender a opinião das pessoas sobre diversos tópicos..
Portanto, precisamos desenvolver um Modelo automatizado de análise de sentimentos de aprendizado de máquina para calcular a percepção do cliente. Devido à presença de caracteres não úteis (coletivamente referido como ruído) juntamente com dados úteis, é difícil implementar modelos neles.
Neste artigo, nosso objetivo é analisar o sentimento dos tweets fornecidos pelo Conjunto de dados Sentiment140 desenvolvendo um pipeline de aprendizado de máquina envolvendo o uso de três classificadores (Regressão logística, Bernoulli Naive Bayes e SVM) junto com o uso Frequência do Termo – Frequência de documentos reversos (TF-IDF). O desempenho desses classificadores é então avaliado usando precisão e Pontuações da F1.

Fonte da imagem: Imagens do google
Exposição do problema
Neste projeto, Tentamos implementar um Modelo de análise de sentimento do Twitter que ajuda a superar os desafios de identificar os sentimentos dos tweets. Os detalhes necessários sobre o conjunto de dados são:
O conjunto de dados fornecido é Conjunto de dados Sentiment140 que consiste em 1,600,000 tweets que foram extraídos usando a API do Twitter. As várias colunas presentes no conjunto de dados são:
- objetivo: a polaridade do tweet (positiva o negativa)
- identificadores: Identificação única do tweet
- encontro: a data do tweet
- bandeira: Refere-se à consulta. Se não existe tal consulta, então não é consulta.
- Nome do usuário: Refere-se ao nome do usuário que tuitou.
- texto: Refere-se ao texto do tweet.
Canalização do projeto
Os vários passos envolvidos no Pipeline de Aprendizagem de Máquina estão :
- Importação de dependências necessárias
- Leia e carregue o conjunto de dados
- Análise exploratória de dados
- Visualização de dados variáveis de destino
- Pré-processamento de dados
- Dividir nuestros datos en subconjuntos de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... e teste
- Transforme o conjunto de dados usando o Vetorizador TF-IDF
- Papel para avaliação de modelos
- Construção do modelo
- conclusão
Comecemos,
Paso 1: importar as dependências necessárias
# utilidades import re import numpy as np import pandas as pd # plotting import seaborn as sns from wordcloud import WordCloud import matplotlib.pyplot as plt # nltk from nltk.stem import WordNetLemmatizer # sklearn from sklearn.svm import LinearSVC from sklearn.naive_bayes import BernoulliNB from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics import confusion_matrix, classificação_report
Paso 2: leia e carregue o conjunto de dados
# Importing the dataset
DATASET_COLUMNS=['alvo','IDs','encontro','bandeira','do utilizador','texto']
DATASET_ENCODING = "ISO-8859-1"
df = pd.read_csv('Project_Data.csv', codificação=DATASET_ENCODING, nomes=DATASET_COLUMNS)
df.sample(5)
Produção:

Paso 3: Análise exploratória de dados
3.1: Cinco registros principales de datos
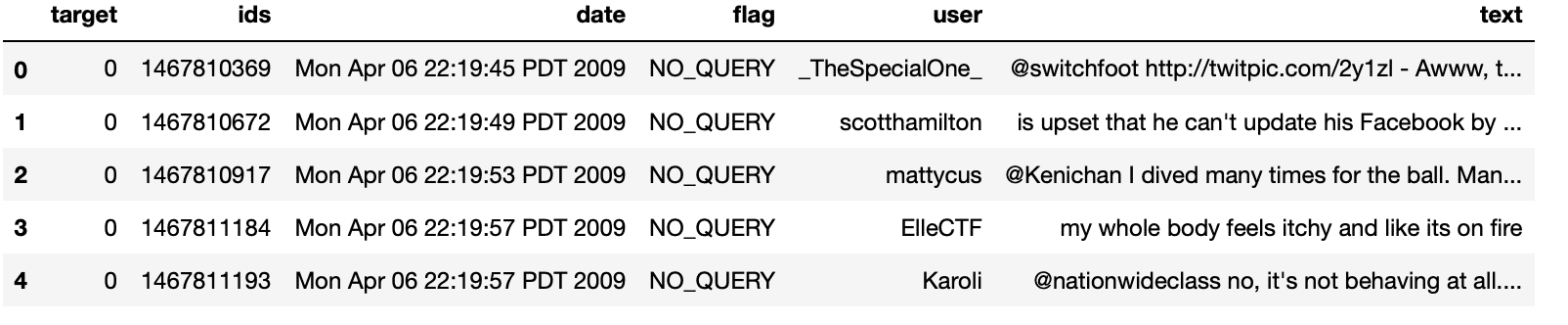
df.head()
Produção:
3.2: Colunas / características en los datos
df.columns
Produção:
Índice(['alvo', 'IDs', 'encontro', 'bandeira', 'do utilizador', 'texto'], dtype ="objeto")
3.3: Longitud del conjunto de datos
imprimir('o tempo de dados é', len(df))
Produção:
comprimento de dados é 1048576
3.4: Forma de los datos
df. forma
Produção:
(1048576, 6)
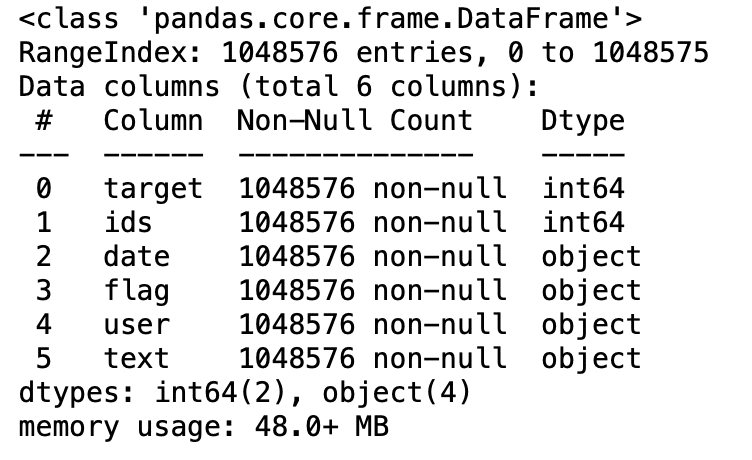
3.5: Información de datos
df.info()
Produção:
3.6: Tipos de datos de todas as colunas
df.dtypes
Produção:
target int64
ids int64
date object
flag object
user object
text object
dtype: objeto
3.7: Comprobación de valores nulos
np.sum(df.isnull().qualquer(eixo = 1))
Produção:
0
3.8: Filas y columnas en el conjunto de datos
imprimir('Contagem de colunas nos dados é: ', len(df.columns))
imprimir('Contagem de linhas nos dados é: ', len(df))
Produção:
Contagem de colunas nos dados é: 6 Contagem de linhas nos dados é: 1048576
3.9: Verifique valores objetivo únicos
df['alvo'].exclusivo()
Produção:
variedade([0, 4], dtype=int64)
3.10: Verifique el número de valores objetivo
df['alvo'].agora()
Produção:
2
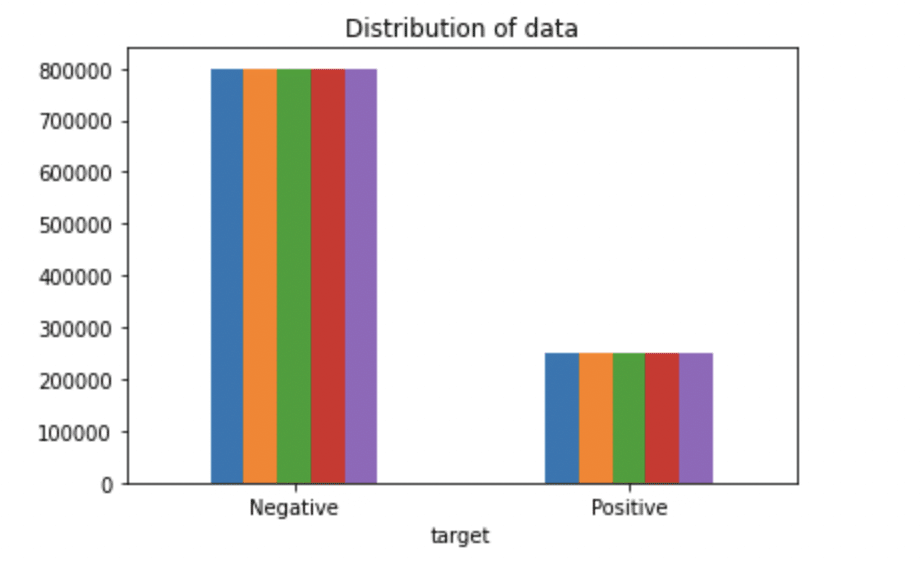
Paso 4: Visualização de datos de variáveis de destino
# Plotando a distribuição para conjunto de dados.
ax = df.groupby('alvo').contar().enredo(kind = 'bar', título ="Distribuição de dados",legend=False)
ax.set_xticklabels(['Negativo','Positivo'], rotação = 0)
# Armazenamento de dados em listas.
texto, sentimento = lista(df['texto']), Lista(df['alvo'])
Produção:
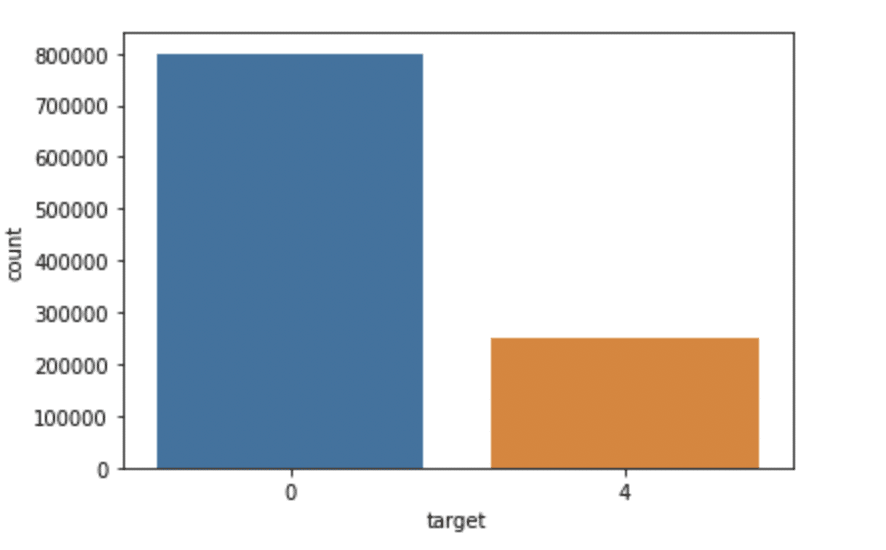
importado do mar como sns
sns.countplot(x='target', data = df)
Produção:
Paso 5: pré-processamento de dados
En la declaración del problema anterior antes de entrenar el modelo, executamos várias etapas de pré-processamento no conjunto de dados que se preocupavam principalmente com a remoção de palavras irrelevantes, excluir emoji. Mais tarde, o documento de texto é convertido em minúsculas para melhor generalização.
Subseqüentemente, pontuações foram limpas e removidas, reduzindo assim o ruído desnecessário do conjunto de dados. Depois disso, também removemos caracteres repetidos de palavras junto com a remoção de URLs, uma vez que não têm importância significativa.
Finalmente, Executamos Derivação (reduzindo as palavras às suas raízes derivadas) e Lematización (reduzindo palavras derivadas à sua forma raiz conhecida como lema) para melhores resultados.
5.1: Selecione o texto de destino e a coluna para nossa análise posterior
data = df[['texto','alvo']]
5.2: Substituição de valores para facilitar o entendimento. (atribuindo 1 ao sentimento positivo 4)
dados['alvo'] = dados['alvo'].substituir(4,1)
5.3: Imprima valores exclusivos de variáveis de destino
dados['alvo'].exclusivo()
Produção:
variedade([0, 1], dtype=int64)
5.4: Separação de tweets positivos e negativos
data_pos = dados[dados['alvo'] == 1] dados_neg = dados[dados['alvo'] == 0]
5.5: pegando um quarto dos dados para que possamos rodar em nossa máquina facilmente
data_pos = data_pos.iloc[:int(20000)] data_neg = data_neg.iloc[:int(20000)]
5.6: Combinando tweets positivos e negativos
conjunto de dados = pd.concat([data_pos, data_neg])
5.7: Deixe o texto da declaração em letras minúsculas
conjunto de dados['texto']=conjunto de dados['texto'].str.lower() conjunto de dados['texto'].cauda()
Produção:

5.8: Conjunto de definições contendo todas as palavras de parada em inglês.
lista de palavras irrelevantes = ['uma', 'cerca de', 'acima de', 'depois de', 'novamente', 'ain', 'todo', 'sou', 'a',
'e','algum','está', 'Como', 'no', 'estar', 'Porque', 'sido', 'antes de',
'ser', 'abaixo', 'entre','Ambas', 'por', 'posso', 'd', 'fez', 'Faz',
'faz', 'fazendo', 'baixa', 'no decorrer', 'cada','alguns', 'para', 'a partir de',
'mais longe', 'teve', 'tem', 'tenho', 'tendo', 'ele', 'ela', 'aqui',
'dela', 'ela mesma', 'dele', 'ele mesmo', 'seu', 'quão', 'eu', 'E se', 'no',
'para dentro','é', 'isto', 'Está', 'em si', 'somente', 'vou', 'm', 'ma',
'mim', 'mais', 'maioria','minha', "eu mesmo", 'agora', 'o', 'do', 'sobre', 'uma vez',
'só', 'ou', 'outro', 'nosso', 'nosso',"nós mesmos", 'fora', 'próprio', 'ré','s', 'mesmo', 'ela', "Shes", 'deveria', "deveve",'So', 'alguns', 'tal',
't', 'do', 'isso', "Thatll", 'a', 'deles', 'deles', 'eles',
'eles mesmos', 'então', 'lá', 'esses', 'eles', 'isso', 'aqueles',
'através', 'para', 'também','abaixo', 'até', 'para cima', 've', 'muito', 'era',
'nós', 'foram', 'o quê', 'quando', 'Onde','qual','while', 'quem', 'quem',
'por quê', 'vontade', 'com', 'ganhou', 'e', 'tu', "youd","você vai", "Youre",
"você tem", 'sua', 'seu', "você mesmo", 'vocês mesmos']
5.9: Limpiar y eliminar la lista de palabras vacías anterior del texto del tweet
STOPWORDS = conjunto(stopwordlist)
def cleaning_stopwords(texto):
Retorna " ".Junte([palavra por palavra em str(texto).dividir() se a palavra não em STOPWORDS])
conjunto de dados['texto'] = conjunto de dados['texto'].Aplique(texto lambda: cleaning_stopwords(texto))
conjunto de dados['texto'].cabeça()
Produção:

5.10: Limpieza y eliminación de puntuaciones
import string
english_punctuations = string.punctuation
punctuations_list = english_punctuations
def cleaning_punctuations(texto):
tradutor = str.maketrans('', '', punctuations_list)
texto de retorno.traduzir(Translator)
conjunto de dados['texto']= conjunto de dados['texto'].Aplique(lambda x: cleaning_punctuations(x))
conjunto de dados['texto'].cauda()
Produção:

5.11: Limpieza y eliminación de caracteres repetidos
cleaning_repeating_char def(texto):
retorno re.sub(r '(.)1+', r'1', texto)
conjunto de dados['texto'] = conjunto de dados['texto'].Aplique(lambda x: cleaning_repeating_char(x))
conjunto de dados['texto'].cauda()
Produção:

5.12: Limpieza y eliminación de URL
def cleaning_URLs(dados):
retorno re.sub('((www.[^s]+)|(https?://[^s]+))','',dados)
conjunto de dados['texto'] = conjunto de dados['texto'].Aplique(lambda x: cleaning_URLs(x))
conjunto de dados['texto'].cauda()
Produção:

5.13: Limpieza y eliminación de números numéricos
def cleaning_numbers(dados):
retorno re.sub('[0-9]+', '', dados)
conjunto de dados['texto'] = conjunto de dados['texto'].Aplique(lambda x: cleaning_numbers(x))
conjunto de dados['texto'].cauda()
Produção:

5.14: Obtención de tokenización del texto del tweet
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'w + ')
conjunto de dados['texto'] = conjunto de dados['texto'].Aplique(tokenizer.tokenize)
conjunto de dados['texto'].cabeça()
Produção:

5.15: Aplicación de la derivación
import nltk st = nltk.PorterStemmer() def stemming_on_text(dados): text = [st.stem(palavra) para palavra em dados] return data dataset['texto']= conjunto de dados['texto'].Aplique(lambda x: stemming_on_text(x)) conjunto de dados['texto'].cabeça()
Produção:

5.16: Aplicación de Lemmatizer
im = nltk. WordNetLemmatizer()
def lemmatizer_on_text(dados):
text = [lm.lemmatize(palavra) para palavra em dados]
return data
dataset['texto'] = conjunto de dados['texto'].Aplique(lambda x: lemmatizer_on_text(x))
conjunto de dados['texto'].cabeça()
Produção:

5.17: Separação da função de entrada e do rótulo
X=data.text
y=data.target
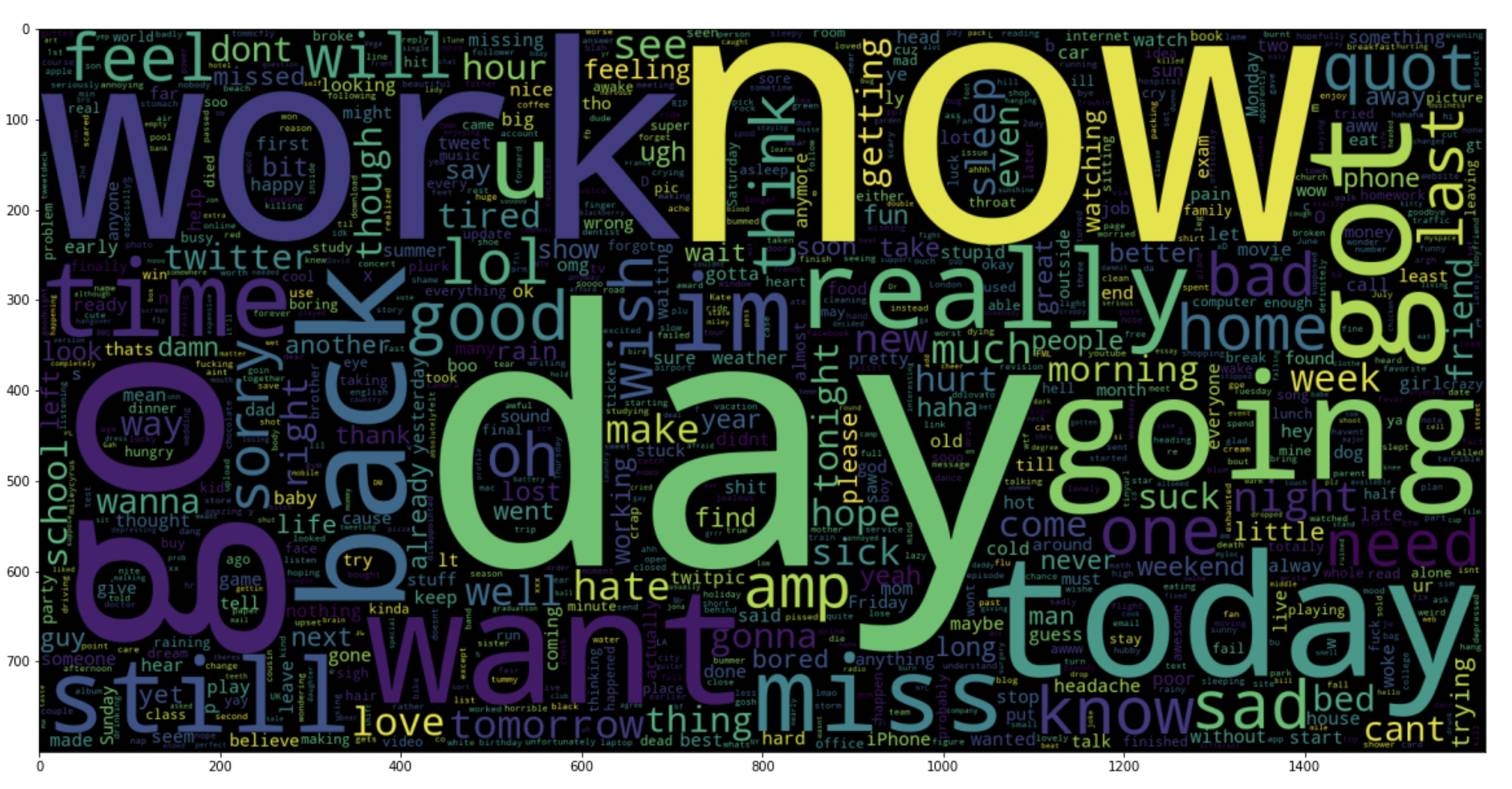
5.18: traçar uma nuvem de palavras para tweets negativos
dados_neg = dados['texto'][:800000]
plt.figure(figsize = (20,20))
wc = WordCloud(max_words = 1000 , largura = 1600 , altura = 800,
colloations=Falso).gerar(" ".Junte(data_neg))
plt.imshow(BANHEIRO)
Produção:
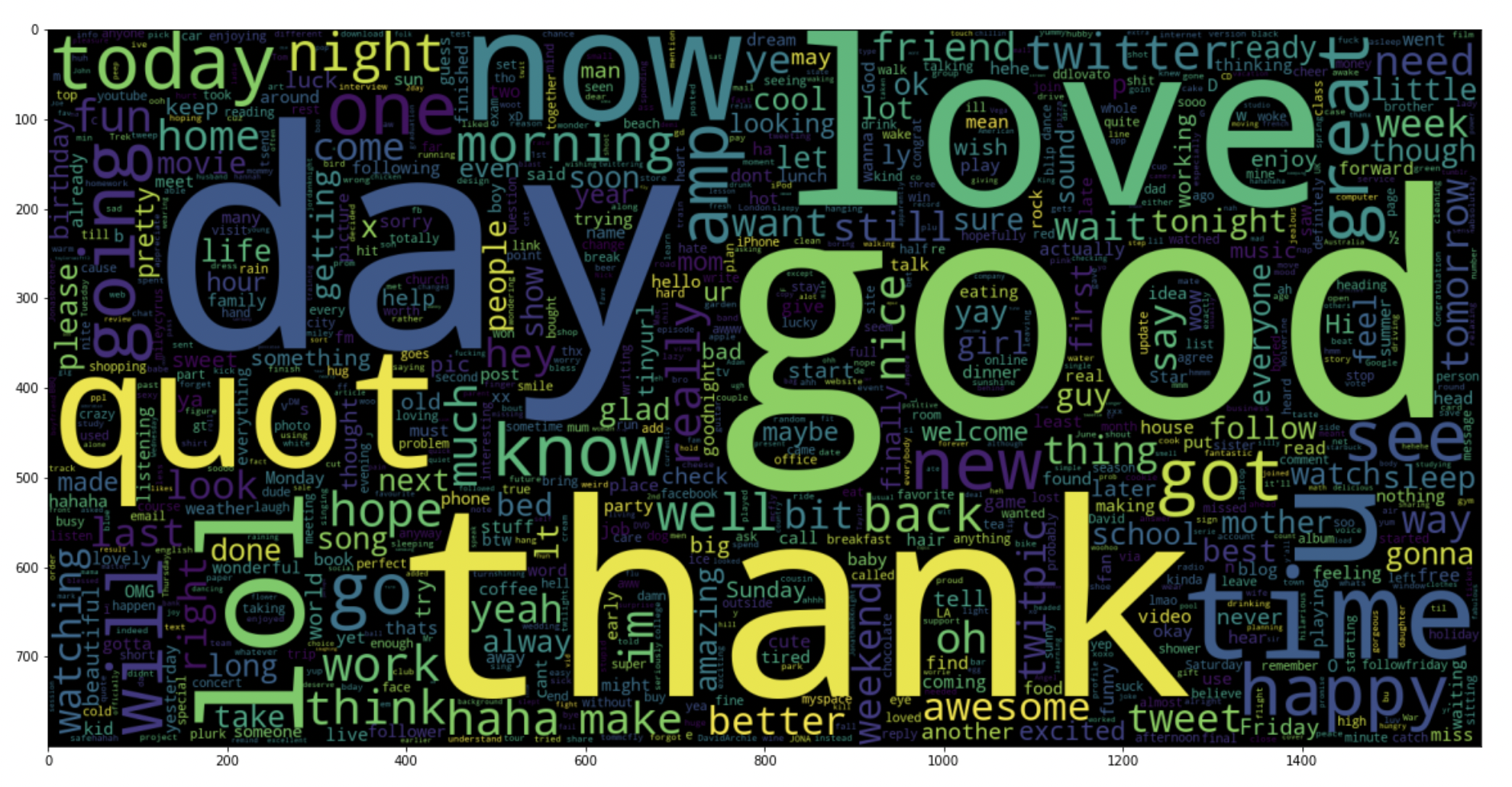
5.19: traçar uma nuvem de palavras para tweets positivos
data_pos = dados['texto'][800000:]
wc = WordCloud(max_words = 1000 , largura = 1600 , altura = 800,
colloations=Falso).gerar(" ".Junte(data_pos))
plt.figure(figsize = (20,20))
plt.imshow(BANHEIRO)
Produção:
Paso 6: Quebre nossos dados em subconjuntos de treinamento e teste
# Separando o 95% dados para dados de treinamento e 5% for testing data
X_train, X_test, y_train, y_test = train_test_split(X,e,test_size = 0.05, random_state =26105111)
Paso 7: Transforme o conjunto de dados usando o Vetorizador TF-IDF
7.1: Instale o vetorizador TF-IDF
vetoriser = TfidfVectorizer(ngram_range=(1,2), max_features=5000000)
vectoriser.fit(X_train)
imprimir('Não. de feature_words: ', len(vectoriser.get_feature_names()))
Produção:
Não. de feature_words: 500000
7.2: Transforme dados usando o Vetorizador TF-IDF
X_train = vectoriser.transform(X_train) X_test = vectoriser.transform(X_test)
Paso 8: Papel para avaliação de modelos
Depois de treinar o modelo, aplicamos as medidas de avaliação para verificar o desempenho do modelo. Em consequência, utilizamos los siguientes parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... de evaluación para verificar el rendimiento de los modelos respectivamente:
- Puntuación de precisión
- Matriz de confusão con trama
- Curva ROC-AUC
def model_Evaluate(modelo): # Predict values for Test dataset y_pred = model.predict(X_test) # Imprima as métricas de avaliação para o conjunto de dados. imprimir(classificação_report(y_test, y_pred)) # Compute and plot the Confusion matrix cf_matrix = confusion_matrix(y_test, y_pred) categorias = ['Negativo','Positivo'] group_names = ['True Neg','Falsos Pos', 'Falso Neg','Verdadeiros Pos'] group_percentages = ['{0:.2%}'.formato(valor) para o valor em cf_matrix.achatar() / np.sum(cf_matrix)] a primeira coisa que fazemos é identificar se os dados são estacionários ou não estacionários [f '{v1}n{v2}' para v1, v2 no zip(group_names,group_percentages)] rótulos = np.asarray(rótulos).remodelar(2,2) sns.heatmap(cf_matrix, ano = rótulos, cmap = 'Blues',fmt="", xticklabels = categorias, yticklabels = categorias) plt.xlabel("Valores previstos", fontdict = {'Tamanho':14}, labelpad = 10) plt.ylabel("Valores reais" , fontdict = {'Tamanho':14}, labelpad = 10) plt.title ("Matriz de Confusão", fontdict = {'Tamanho':18}, pad = 20)
Paso 9: Construção de maquete
En el planteamiento del problema hemos utilizado tres modelos diferentes respectivamente:
- Bernoulli Bayes ingênuo
- SVM (máquina vetorial de suporte)
- Regressão logística
A ideia por trás da escolha desses modelos é que queremos testar todos os classificadores no conjunto de dados., de modelos simples a complexos, e, em seguida, tentar encontrar o que oferece o melhor desempenho entre eles.
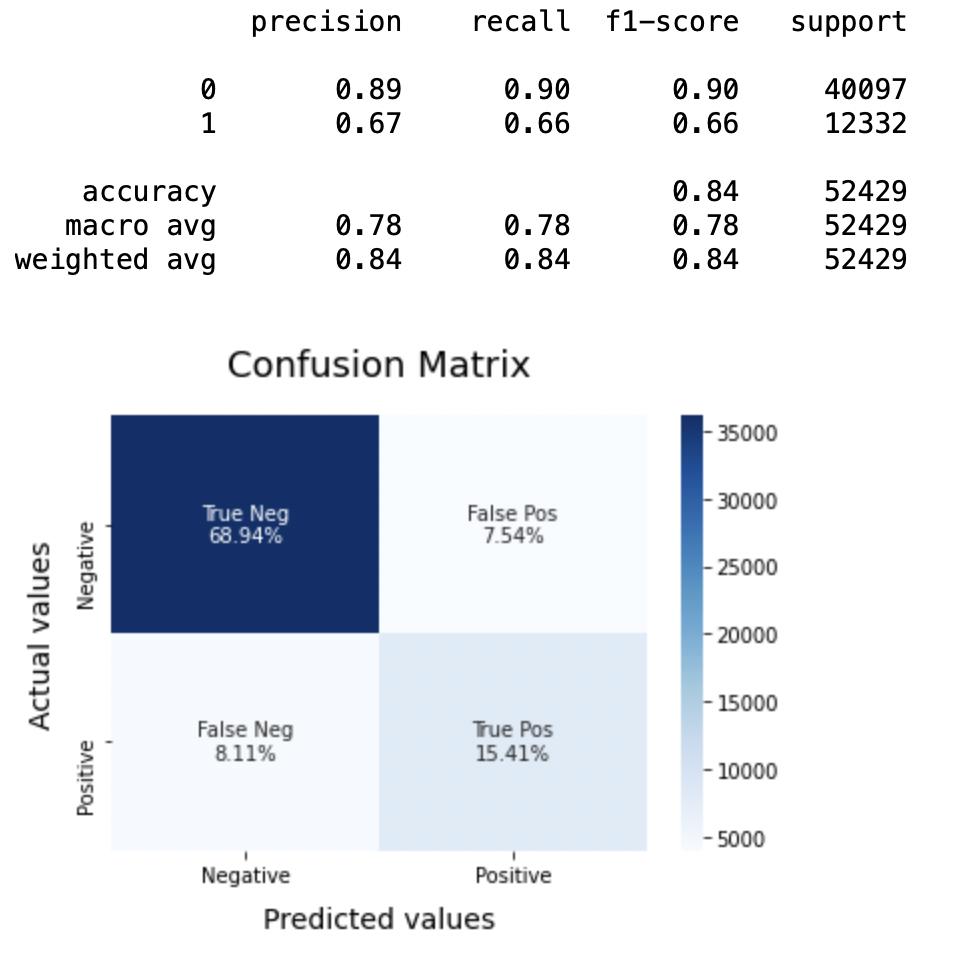
8.1: Modelo-1
BNBmodel = BernoulliNB() BNBmodel.fit(X_train, y_train) model_Evaluate(Modelo BNB) y_pred1 = BNBmodel.predict(X_test)
Produção:
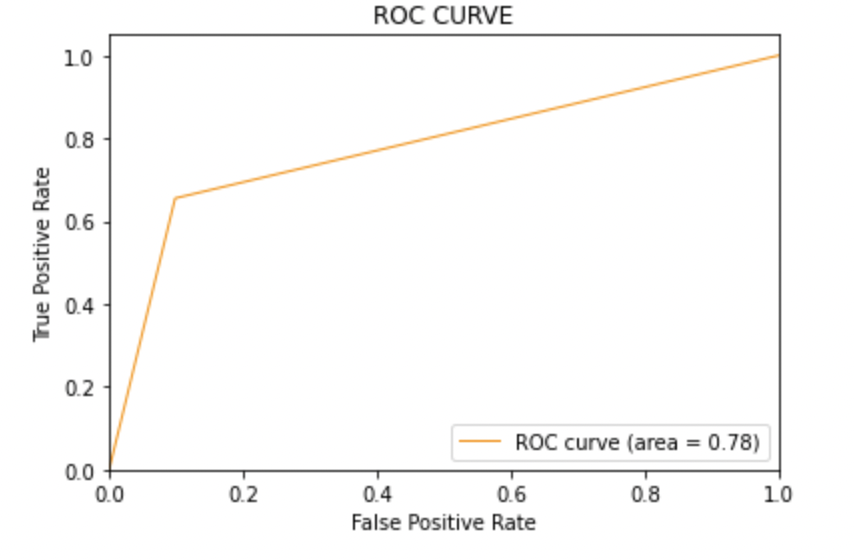
8.2: Plote a curva ROC-AUC para o modelo 1
de sklearn.metrics importação roc_curve, auc
fpr, Tpr, limiares = roc_curve(y_test, y_pred1)
roc_auc = auc(fpr, Tpr)
plt.figure()
plt.plot(fpr, Tpr, color ="darkorange", lw=1, rótulo ="Curva ROC (área = %0,2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Taxa Falsa Positiva')
plt.ylabel('Taxa Verdadeira Positiva')
plt.title('CURVA ROC')
plt.legend(loc ="inferior direito")
plt.show()
Produção:
8.3: Modelo-2:
Modelo SVC = LinearSVC() SVCmodel.fit(X_train, y_train) model_Evaluate(Modelo SVC) y_pred2 = SVCmodel.predict(X_test)
Produção:
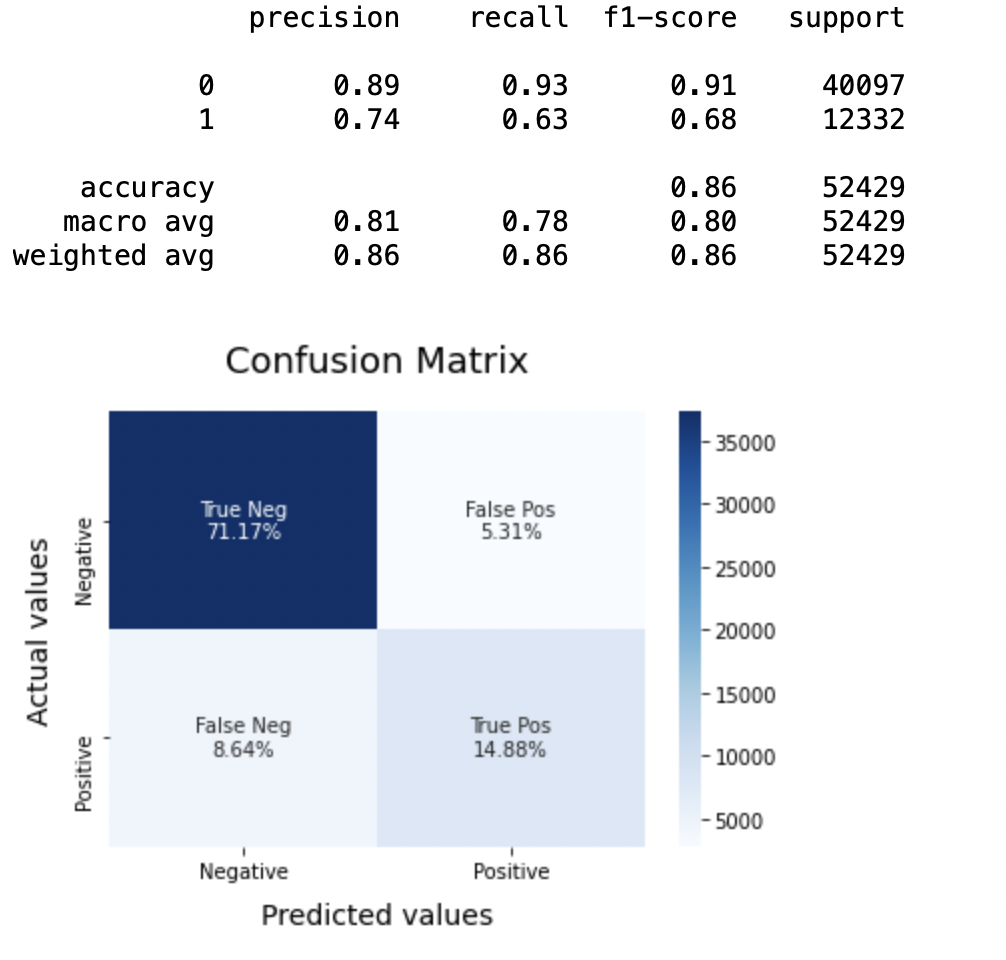
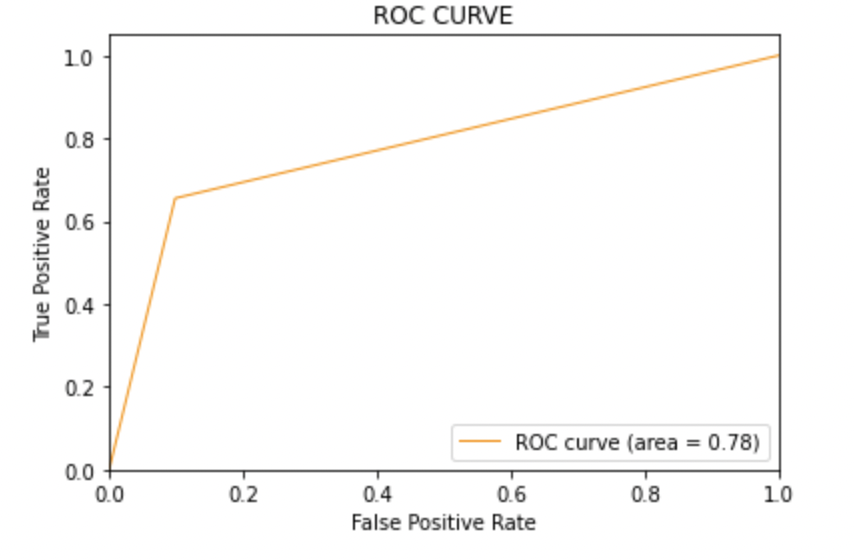
8.4: Plote a curva ROC-AUC para o modelo 2
de sklearn.metrics importação roc_curve, auc
fpr, Tpr, limiares = roc_curve(y_test, y_pred2)
roc_auc = auc(fpr, Tpr)
plt.figure()
plt.plot(fpr, Tpr, color ="darkorange", lw=1, rótulo ="Curva ROC (área = %0,2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Taxa Falsa Positiva')
plt.ylabel('Taxa Verdadeira Positiva')
plt.title('CURVA ROC')
plt.legend(loc ="inferior direito")
plt.show()
Produção:
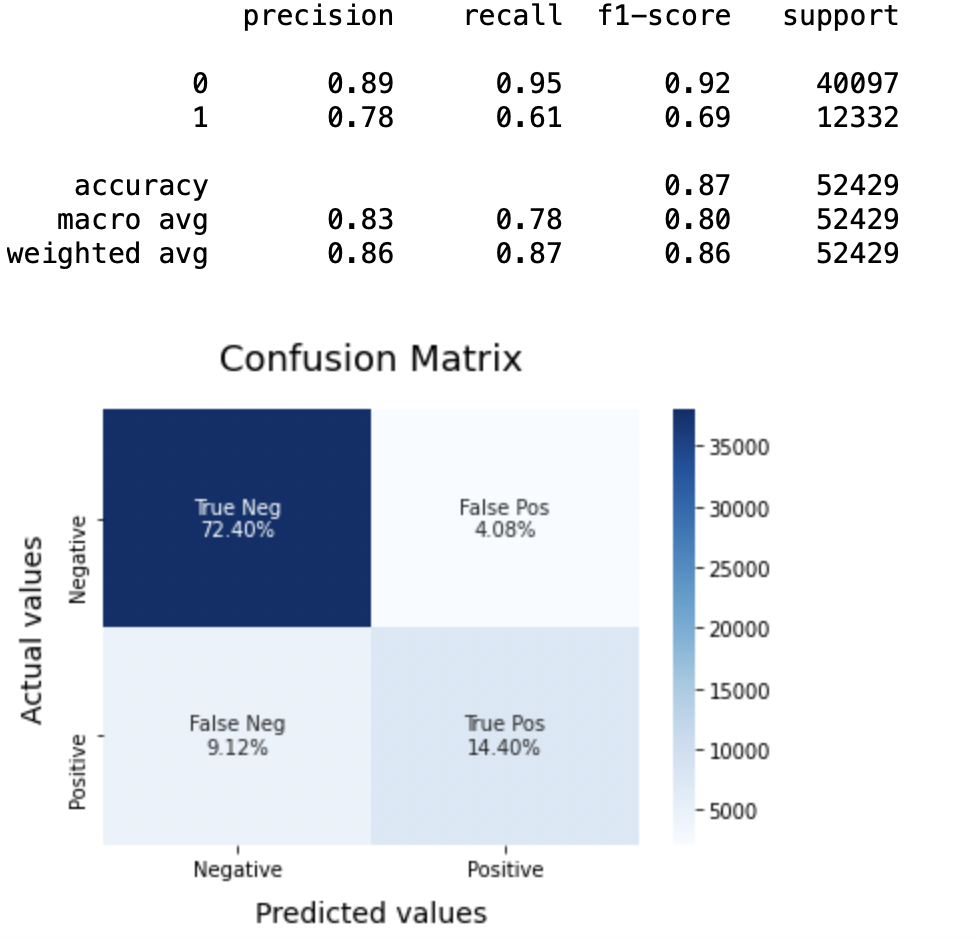
8.5: Modelo-3
LRmodel = LogisticRegression(C = 2, max_iter = 1000, n_jobs = -1) LRmodel.fit(X_train, y_train) model_Evaluate(Modelo LR) y_pred3 = LRmodel.predict(X_test)
Produção:
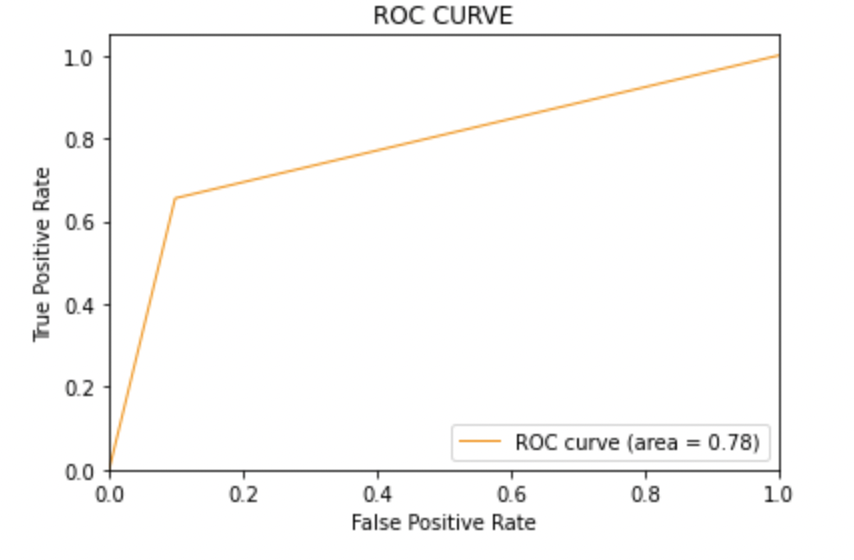
8.6: Plote a curva ROC-AUC para o modelo 3
de sklearn.metrics importação roc_curve, auc
fpr, Tpr, limiares = roc_curve(y_test, y_pred3)
roc_auc = auc(fpr, Tpr)
plt.figure()
plt.plot(fpr, Tpr, color ="darkorange", lw=1, rótulo ="Curva ROC (área = %0,2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Taxa Falsa Positiva')
plt.ylabel('Taxa Verdadeira Positiva')
plt.title('CURVA ROC')
plt.legend(loc ="inferior direito")
plt.show()
Produção:
Paso 10: conclusão
Ao avaliar todos os modelos, podemos concluir os seguintes detalhes, ou seja,
Precisão: Sobre a precisão do modelo, regressão logística tem melhor desempenho do que SVM, que por sua vez funciona melhor do que Bernoulli Naive Bayes.
Pontuação F1: As pontuações da F1 para a classe 0 e a classe 1 filho:
(uma) Aqui x é considerado como a variável dependente e y é considerado como a variável independente 0: Bernoulli Naive Bayes (precisão = 0,90) <SVM (precisão = 0,91) <Regressão logística (precisão = 0,92)
(b) Aqui x é considerado como a variável dependente e y é considerado como a variável independente 1: Bernoulli Naive Bayes (precisão = 0,66) <SVM (precisão = 0,68) <Regressão logística (precisão = 0,69)
Pontuação AUC: Todos os três modelos têm a mesma pontuação ROC-AUC.
Portanto, concluímos que a regressão logística é o melhor modelo para o conjunto de dados acima.
Em nossa declaração de problema, Regressão logística está seguindo o princípio de navalha de Occam que define isso para uma declaração de problema em particular, se os dados não tiverem suposições, então o modelo mais simples funciona melhor. Como nosso conjunto de dados não possui suposições e a Regressão Logística é um modelo simples, o conceito é válido para o conjunto de dados mencionado acima.
Notas finais
Espero que tenha gostado do artigo.
Se você quiser se conectar comigo, Não duvide em manter contato comigo. sobre Correio eletrônico
Suas sugestões e dúvidas são bem-vindas aqui na seção de comentários. Obrigado por ler o meu artigo!
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do autor.





