Observação: Este artigo foi publicado originalmente em outubro 6 a partir de, 2015 e atualizou o 13 setembro 2017
Visão geral
- Máquina de vetores de suporte explicada (SVM), um algoritmo ou classificação de aprendizado de máquina popular
- Implementando SVM em R e Python
- Saiba mais sobre os prós e contras das máquinas de vetores de suporte (SVM) e suas diferentes aplicações
Introdução
domínio algoritmos de aprendizado de máquina nem um mito. A maioria dos iniciantes começa aprendendo a regressão. É simples de aprender e usar, mas isso resolve nosso propósito? Claro que não! Porque você pode fazer muito mais do que uma simples regressão!!
Pense nos algoritmos de aprendizado de máquina como um arsenal cheio de eixos, espadas, sai, arcos, punhais, etc. Tem várias ferramentas, mas você deve aprender a usá-los na hora certa. Como uma analogia, pense em 'Regressão’ como uma espada capaz de fatiar e fatiar dados de forma eficiente, mas incapaz de lidar com dados muito complexos. Pelo contrário, ‘Support Vector Machines’ é como uma faca afiada: funciona em conjuntos de dados menores, mas em conjuntos complexos, pode ser muito mais forte e poderoso na construção de modelos de aprendizado de máquina.
A estas alturas, Espero que você tenha dominado a Random Forest, o algoritmo Naive Bayes e Modelagem de conjunto. Mas, Eu sugiro que você reserve alguns minutos e leia sobre eles também. Neste artigo, Vou guiá-lo pelas noções básicas para conhecimento avançado de um algoritmo crucial de aprendizado de máquina, apoiar máquinas de vetor.
Você pode obter informações sobre Support Vector Machines em formato de curso aqui (É grátis!):
Se você é um iniciante procurando iniciar sua jornada de ciência de dados, Você veio ao lugar certo! Confira os cursos completos abaixo, selecionado por especialistas da indústria, que criamos apenas para você:

Compreenda o algoritmo da máquina de vetores de suporte a partir de exemplos (junto com o código)
Tabela de conteúdo
- O que é máquina de vetores de suporte?
- Como funciona?
- Como implementar SVM em Python e R?
- ¿Cómo ajustar los parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... de SVM?
- Prós e contras associados ao SVM
O que é a máquina de vetores de suporte?
“Máquina de vetores de suporte” (SVM) é um sistema supervisionado algoritmo de aprendizado de máquina que pode ser usado para desafios de classificação ou regressão. Porém, usado principalmente em problemas de classificação. No algoritmo SVM, nós plotamos cada item de dados como um ponto no espaço n-dimensional (onde n é uma série de características que tem) com o valor de cada característica sendo o valor de uma coordenada particular. Mais tarde, realizamos a classificação encontrando o hiperplano que diferencia as duas classes muito bem (olhe para o instantâneo abaixo).
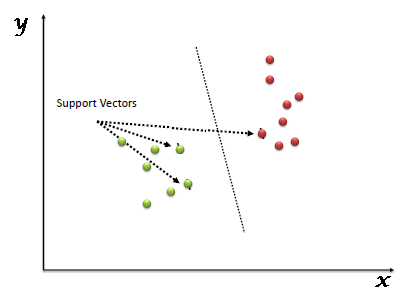
Os vetores de suporte são simplesmente as coordenadas da observação individual. O classificador SVM é o limite que melhor segrega as duas classes (hiperplano / linha).
Você pode ver as máquinas de vetores de suporte e alguns exemplos de como elas funcionam aqui.
Como funciona?
Acima, nos acostumamos com o processo de segregação das duas classes com um hiperplano. Agora a questão premente é “Como podemos identificar o hiperplano correto?”. Não te preocupes, não é tão difícil quanto você pensa!
Nós entendemos:
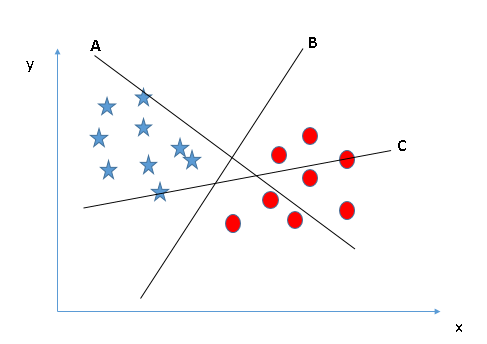
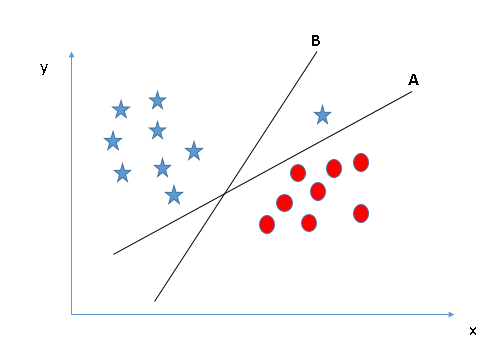
- Identifique o hiperplano correto (Cenário 1): Aqui, temos três hiperplanos (UMA, Por C). Agora, identifique o hiperplano correto para classificar estrelas e círculos.
 Você deve se lembrar de uma regra prática para identificar o hiperplano correto: “Selecione o hiperplano que melhor segregar as duas classes”. Nesta fase, o hiperplano “B” fez este trabalho de forma excelente.
Você deve se lembrar de uma regra prática para identificar o hiperplano correto: “Selecione o hiperplano que melhor segregar as duas classes”. Nesta fase, o hiperplano “B” fez este trabalho de forma excelente. - Identifique o hiperplano correto (Cenário-2): Aqui, temos três hiperplanos (UMA, Por C) e todo mundo está segregando bem as classes. Agora, Como podemos identificar o hiperplano correto?
 Aqui, maximizar distâncias entre o ponto de dados mais próximo (qualquer classe) e o hiperplano nos ajudará a decidir o hiperplano correto. Esta distância é chamada MargemMargem é um termo usado em uma variedade de contextos, como contabilidade, Economia e impressão. Em contabilidade, refere-se à diferença entre receitas e custos, que permite avaliar a rentabilidade de um negócio. No domínio da publicação, A margem é o espaço em branco ao redor do texto em uma página, que facilita a leitura e proporciona uma apresentação estética. Seu correto manejo é essencial... Vamos ver o próximo instantâneo:
Aqui, maximizar distâncias entre o ponto de dados mais próximo (qualquer classe) e o hiperplano nos ajudará a decidir o hiperplano correto. Esta distância é chamada MargemMargem é um termo usado em uma variedade de contextos, como contabilidade, Economia e impressão. Em contabilidade, refere-se à diferença entre receitas e custos, que permite avaliar a rentabilidade de um negócio. No domínio da publicação, A margem é o espaço em branco ao redor do texto em uma página, que facilita a leitura e proporciona uma apresentação estética. Seu correto manejo é essencial... Vamos ver o próximo instantâneo:
Acima, você pode ver que a margem do hiperplano C é alta em comparação com A e B. Portanto, chamamos o hiperplano correto de C. Outra razão contundente para selecionar o hiperplano com uma margem mais alta é a robustez. Se selecionarmos um hiperplano que tem uma margem baixa, há uma grande chance de classificação incorreta. - Identifique o hiperplano correto (Cenário-3):Sugestão: Use as réguas conforme discutido na seção anterior para identificar o hiperplano correto
 Você deve se lembrar de uma regra prática para identificar o hiperplano correto: “Selecione o hiperplano que melhor segregar as duas classes”. Nesta fase, o hiperplano “B” fez este trabalho de forma excelente.
Você deve se lembrar de uma regra prática para identificar o hiperplano correto: “Selecione o hiperplano que melhor segregar as duas classes”. Nesta fase, o hiperplano “B” fez este trabalho de forma excelente.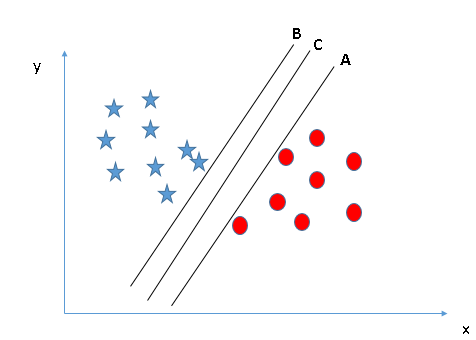 Aqui, maximizar distâncias entre o ponto de dados mais próximo (qualquer classe) e o hiperplano nos ajudará a decidir o hiperplano correto. Esta distância é chamada
Aqui, maximizar distâncias entre o ponto de dados mais próximo (qualquer classe) e o hiperplano nos ajudará a decidir o hiperplano correto. Esta distância é chamada 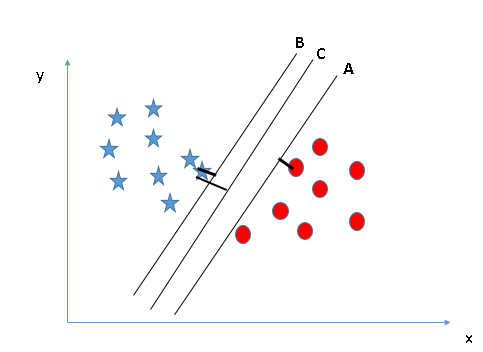
 Alguns de vocês podem ter selecionado o hiperplano B pois tem uma margem maior em comparação com UMA. Mas, aqui está o truque, O SVM seleciona o hiperplano que classifica as classes com precisão antes de maximizar a margem. Aqui, o hiperplano B tem um erro de classificação e A classificou tudo corretamente. Portanto, o hiperplano certo é UMA.
Alguns de vocês podem ter selecionado o hiperplano B pois tem uma margem maior em comparação com UMA. Mas, aqui está o truque, O SVM seleciona o hiperplano que classifica as classes com precisão antes de maximizar a margem. Aqui, o hiperplano B tem um erro de classificação e A classificou tudo corretamente. Portanto, o hiperplano certo é UMA.
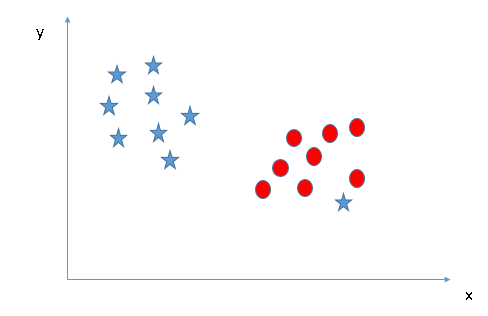
- Podemos classificar duas classes (Cenário-4) ?: A seguir, Não consigo separar as duas classes usando uma linha reta, já que uma das estrelas está no território da outra classe (círculo) como um outlier.
 Como eu já mencionei, uma estrela na outra extremidade é como um outlier para a classe das estrelas. O algoritmo SVM tem uma função para ignorar outliers e encontrar o hiperplano que tem a margem máxima. Portanto, podemos dizer que a classificação SVM é robusta para outliers.
Como eu já mencionei, uma estrela na outra extremidade é como um outlier para a classe das estrelas. O algoritmo SVM tem uma função para ignorar outliers e encontrar o hiperplano que tem a margem máxima. Portanto, podemos dizer que a classificação SVM é robusta para outliers.
- Encontre o hiperplano para separar as classes (Cenário-5): No seguinte cenário, não podemos ter um hiperplano linear entre as duas classes, então, Como o SVM classifica essas duas classes? Até agora, nós apenas olhamos para o hiperplano linear.
 SVM pode resolver este problema. Facilmente! Resolva este problema introduzindo um recurso adicional. Aqui, vamos adicionar um novo recurso z = x ^ 2 + e ^ 2. Agora, vamos plotar os pontos de dados nos eixos x e z:
SVM pode resolver este problema. Facilmente! Resolva este problema introduzindo um recurso adicional. Aqui, vamos adicionar um novo recurso z = x ^ 2 + e ^ 2. Agora, vamos plotar os pontos de dados nos eixos x e z:
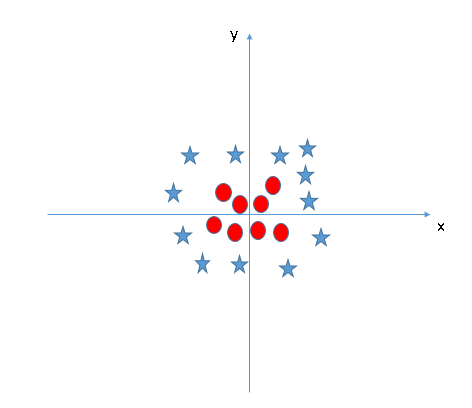
No gráfico acima, os pontos a considerar são:- Todos os valores de z seriam sempre positivos porque z é a soma ao quadrado de x e y
- No gráfico original, círculos vermelhos aparecem perto da origem dos eixos xey, levando a um valor menor de z e uma estrela relativamente longe do resultado de origem a um valor maior de z.
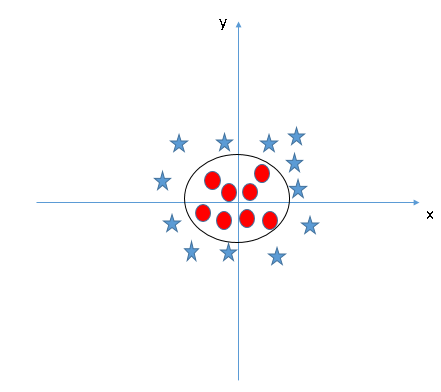
No classificador SVM, é fácil ter um hiperplano linear entre essas duas classes. Mas, outra questão candente que surge é se precisamos adicionar esta função manualmente para ter um hiperplano. Não, o algoritmo SVM tem uma técnica chamada núcleo truque. El kernel SVM es una función que toma un espacio de entrada de baja dimensão"Dimensão" É um termo usado em várias disciplinas, como a física, Matemática e filosofia. Refere-se à extensão em que um objeto ou fenômeno pode ser analisado ou descrito. Em física, por exemplo, fala-se de dimensões espaciais e temporais, enquanto em matemática pode se referir ao número de coordenadas necessárias para representar um espaço. Compreendê-lo é fundamental para o estudo e... y lo transforma en un espacio de mayor dimensión, quer dizer, converte um problema não separável em um problema separável. É especialmente útil em problemas de separação não linear. Em poucas palavras, executa algumas transformações de dados extremamente complexas, em seguida, descubra o processo para separar os dados com base nos rótulos ou saídas que você definiu.
Quando olhamos para o hiperplano no espaço de entrada original, parece um círculo:

 Como eu já mencionei, uma estrela na outra extremidade é como um outlier para a classe das estrelas. O algoritmo SVM tem uma função para ignorar outliers e encontrar o hiperplano que tem a margem máxima. Portanto, podemos dizer que a classificação SVM é robusta para outliers.
Como eu já mencionei, uma estrela na outra extremidade é como um outlier para a classe das estrelas. O algoritmo SVM tem uma função para ignorar outliers e encontrar o hiperplano que tem a margem máxima. Portanto, podemos dizer que a classificação SVM é robusta para outliers.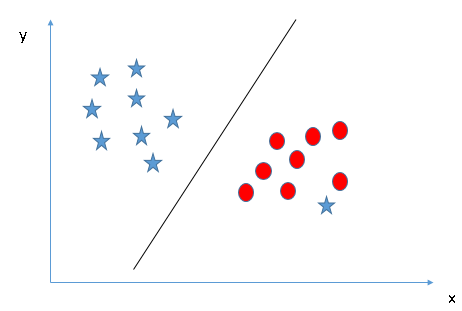
 SVM pode resolver este problema. Facilmente! Resolva este problema introduzindo um recurso adicional. Aqui, vamos adicionar um novo recurso z = x ^ 2 + e ^ 2. Agora, vamos plotar os pontos de dados nos eixos x e z:
SVM pode resolver este problema. Facilmente! Resolva este problema introduzindo um recurso adicional. Aqui, vamos adicionar um novo recurso z = x ^ 2 + e ^ 2. Agora, vamos plotar os pontos de dados nos eixos x e z: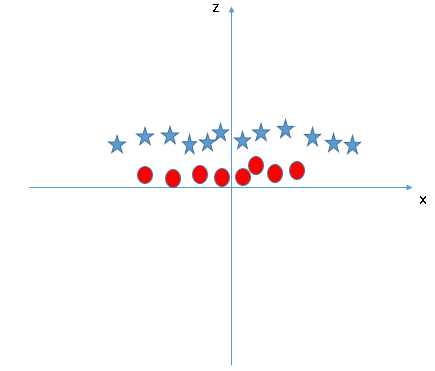
Agora, Vamos ver os métodos para aplicar o algoritmo classificador SVM em um desafio de ciência de dados.
Você também pode aprender sobre a operação da Support Vector Machine em formato de vídeo a partir deste Certificação de aprendizado de máquina.
Como implementar SVM em Python e R?
E Python, scikit-learn é uma biblioteca amplamente usada para implementar algoritmos de aprendizado de máquina. O SVM também está disponível na biblioteca scikit-learn e seguimos a mesma estrutura para usá-lo (biblioteca de importação, criação de objeto, modelo de ajuste e previsão).
Agora, Vamos dar uma olhada em uma declaração de problema da vida real e conjunto de dados para entender como aplicar SVM para classificação.
Exposição do problema
A empresa Dream Housing Finance cuida de todos os empréstimos hipotecários. Eles estão presentes em todas as áreas urbanas, semi-urbano e rural. Um cliente primeiro se inscreve para um empréstimo residencial, depois que a empresa valida a elegibilidade do cliente para um empréstimo.
A empresa deseja automatizar o processo de elegibilidade do empréstimo (em tempo real) com base nos detalhes do cliente fornecidos ao preencher um formulário de inscrição online. Esses detalhes são gênero, Estado civil, Educação, número de dependentes, renda, montante do empréstimo, histórico de crédito e outros. Para automatizar este processo, deram um problema de identificação de segmentos de clientes, que são elegíveis para o valor do empréstimo para que possam direcionar especificamente esses clientes. Aqui, eles forneceram um conjunto de dados parcial.
Use a janela de codificação abaixo para prever a elegibilidade do empréstimo no conjunto de teste. Tente alterar os hiperparâmetros de Linear SVM para melhorar a precisão.
Suporte a código de máquina vetorial (SVM) um R
O pacote e1071 em R é usado para criar máquinas de vetores de suporte com facilidade. Tem funções auxiliares, bem como código para o Classificador De Bayes Ingênuo. Criar uma máquina vetorial de suporte em R e Python segue abordagens semelhantes, vamos agora dar uma olhada no seguinte código:
#Import Library require(e1071) #Contains the SVM Train <- read.csv(arquivo.escolha()) Teste <- read.csv(arquivo.escolha()) # existem várias opções associadas ao treinamento SVM; como mudar o kernel, valor gama e C. # create model model <- svm(Target~Predictor1+Predictor2+Predictor3,data=Train,kernel="linear",gama=0,2,custo=100) #Predict Output preds <- prever(modelo,Teste) tabela(preds)
Como ajustar os parâmetros SVM?
Ajustar valores de parâmetros para algoritmos de aprendizagem de máquina melhora efetivamente o desempenho do modelo. Vejamos a lista de parâmetros disponíveis com SVM.
sklearn.svm.SVC(C=1,0, kernel="rbf", grau=3, gama=0,0, coef0=0,0, encolhimento=Verdadeiro, probabilidade=Falso,tol=0,001, cache_size=200, class_weight=Nenhum, verbose=Falso, max_iter=-1, random_state = None)
Vou discutir alguns parâmetros importantes que têm um impacto maior no desempenho do modelo, “núcleo”, “gama” e “C”.
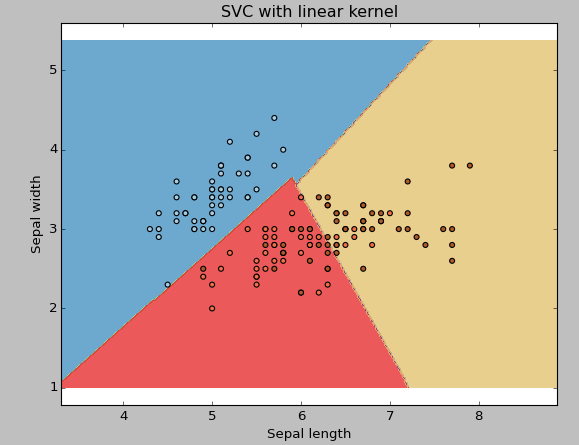
núcleo: Nós já discutimos isso. Aqui, temos várias opções disponíveis com kernel, como, “linear”, “rbf”, “Poli” as outras (o valor padrão é “rbf”). Aqui “rbf” e “Poli” são úteis para hiperplanos não lineares. Vamos ver o exemplo, onde usamos kernel linear em duas características do conjunto de dados de íris para classificar sua classe.
Suporta código de máquina vetorial (SVM) e Python
Exemplo: Tenha um kernel SVM linear
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, conjuntos de dados
# import some data to play with iris = datasets.load_iris() X = iris.data[:, :2] # nós só tomamos as duas primeiras características. Nós poderíamos # avoid this ugly slicing by using a two-dim dataset y = iris.target
# criamos uma instância de SVM e encaixamos dados. Nós não escalamos nossa # data since we want to plot the support vectors C = 1.0 # SVM regularization parameter svc = svm.SVC(kernel="linear", C=1,gama=0).ajuste(X, e)
# create a mesh to plot in
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
Xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
plt.subplot(1, 1, 1) Z = svc.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.remodele(xx.shape) plt.contorno(Xx, Aa, COM, cmap=plt.cm.Emparelhado, alfa=0,8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Emparelhado)
plt.xlabel('Comprimento do sepala')
plt.ylabel('Largura do sepala')
plt.xlim(xx.min(), xx.max())
plt.title('SVC com núcleo linear')
plt.show()
Exemplo: Use o kernel RBF SVM
Mude o tipo de kernel para rbf na linha de fundo e observe o impacto.
svc = svm. SVC(kernel="rbf", C=1,gama=0).ajuste(X, e)
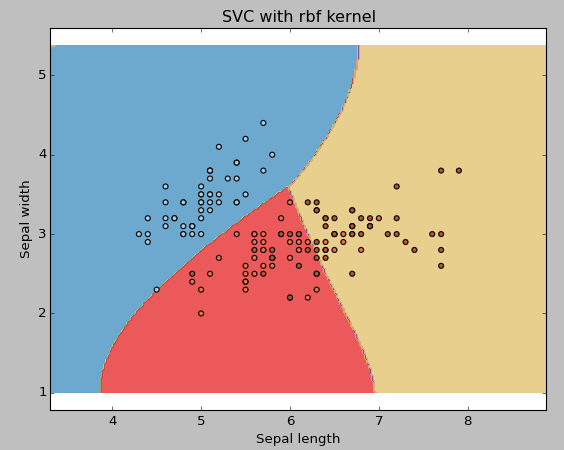
Sugiro que você opte pelo kernel SVM linear se ele tiver um monte de recursos (> 1000) porque os dados são mais propensos a serem separados linearmente em um espaço de alta dimensão. O que mais, pode usar RBF, mas não se esqueça de fazer a validação cruzada de seus parâmetros para evitar o ajuste excessivo.
faixa: Coeficiente de kernel para 'rbf', ‘Poli’ e 'sigmóide'. Quanto maior o valor gama, se intentará ajustar con exactitud el conjunto de datos de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina...., quer dizer, o erro de generalização e causará um problema de overfitting.
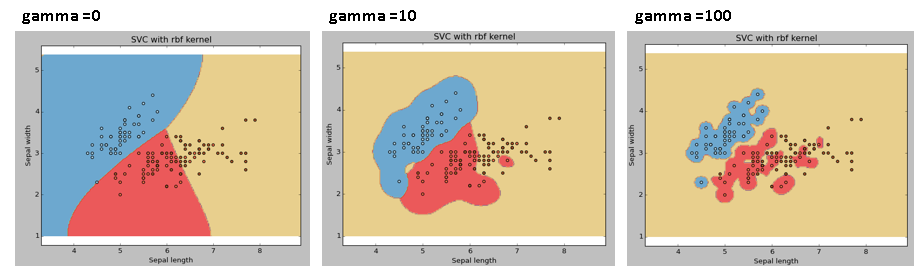
Exemplo: Vamos diferenciar se tivermos diferentes valores gama, como 0, 10 o 100.
svc = svm. SVC(kernel="rbf", C=1,gama=0).ajuste(X, e)
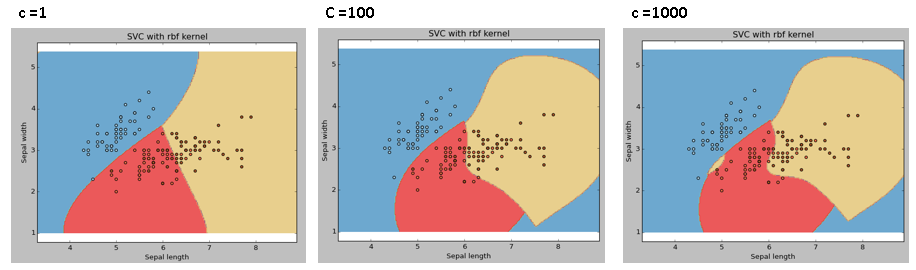
C: Parâmetro de penalidade C do termo de erro. Ele também controla a compensação entre os limites de decisão flexível e a classificação correta dos pontos de treinamento..
Devemos sempre olhar para a pontuação da validação cruzada para ter uma combinação eficaz desses parâmetros e evitar overfitting.
Um R, SVMs podem ser ajustados de forma semelhante a como são em Python. Abaixo mencionados estão os respectivos parâmetros para o pacote e1071:
- O parâmetro do kernel pode ser ajustado para tomar “Linear”, “Poli”, “rbf”, etc.
- O valor gama pode ser ajustado definindo o parâmetro “Gama”.
- O valor C em Python é definido pelo parâmetro “Custo” um R.
Prós e contras associados ao SVM
- Prós:
- Funciona muito bem com uma lacuna clara.
- É eficaz em grandes espaços.
- É eficaz nos casos em que o número de dimensões é maior do que o número de amostras.
- Usa um subconjunto de pontos de treinamento na função de decisão (chamados vetores de suporte), então também é eficiente em termos de memória.
- Contras:
- Não funciona bem quando temos um grande conjunto de dados porque o tempo de treinamento necessário é maior
- Também não funciona muito bem quando o conjunto de dados tem mais ruído, quer dizer, sobreposição de classes alvo
- SVM não fornece estimativas de probabilidade diretamente, estes são calculados usando uma validação cruzada de cinco vezes cara. Ele está incluído no método SVC relacionado da biblioteca scikit-learn do Python.
Problema de prática
Encontre o recurso adicional adequado para ter um hiperplano para segregar as classes no instantâneo a seguir:
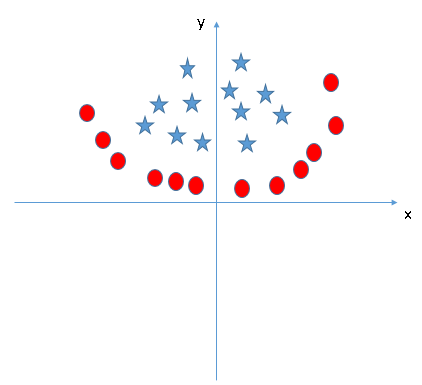
Responda el nombre de la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... en la sección de comentarios a continuación. Então vou revelar a resposta.
Notas finais
Neste artigo, analisamos em detalhes o algoritmo de aprendizado de máquina, Máquina de vetores de suporte. Falei sobre o conceito dele de trabalho, o processo de implementação em python, os truques para tornar o modelo eficiente ajustando seus parâmetros, Prós e contras, e finalmente um problema para resolver. Eu sugiro que você use SVM e analise o poder deste modelo ajustando os parâmetros. Também quero ouvir sobre sua experiência com SVM, Como você ajustou os parâmetros para evitar ajustes excessivos e reduzir o tempo de treinamento?
Você acha útil este artigo? Compartilhe suas opiniões / pensamentos na seção de comentários abaixo.





