Desbloqueo de un mundo nuevo con el algoritmo de regresión vectorial de soporte
Las máquinas de vectores de soporte (SVM) se utilizan popular y ampliamente para problemas de clasificación en el aprendizaje automático. A menudo me he basado en esto no solo en proyectos de aprendizaje automático, sino también cuando quiero un resultado rápido en un hackathon.
¿Pero SVM para análisis de regresión? ¡Ni siquiera había considerado la posibilidad por un tiempo! E incluso ahora, cuando menciono “Regresión vectorial de soporte” frente a los principiantes en aprendizaje automático, a menudo tengo una expresión de perplejidad. eu entendo: la mayoría de los cursos y expertos ni siquiera mencionan la regresión vectorial de soporte (SVR) como un algoritmo de aprendizaje automático.
Pero SVR tiene sus usos, como verá en este tutorial. Primero entenderemos rápidamente qué es SVM, antes de sumergirnos en el mundo de la regresión vectorial de soporte y cómo implementarlo en Python.
Observação: Puede obtener información sobre las máquinas de vectores de soporte y los problemas de regresión en formato de curso aquí (É grátis!):
Esto es lo que cubriremos en este tutorial de regresión de vectores de soporte:
- ¿Qué es una máquina de vectores de soporte (SVM)?
- Hiperparámetros del algoritmo de máquina de vectores de soporte
- Introducción a la regresión de vectores de soporte (SVR)
- Implementación de la regresión de vectores de soporte en Python
¿Qué es una máquina de vectores de soporte (SVM)?
Então, ¿qué es exactamente Support Vector Machine (SVM)? Comenzaremos entendiendo SVM en términos simples. Digamos que tenemos un diagrama de dos clases de etiquetas como se muestra en la siguiente figura"Figura" é um termo usado em vários contextos, Da arte à anatomia. No campo artístico, refere-se à representação de formas humanas ou animais em esculturas e pinturas. Em anatomia, designa a forma e a estrutura do corpo. O que mais, em matemática, "figura" está relacionado a formas geométricas. Sua versatilidade o torna um conceito fundamental em várias disciplinas....:
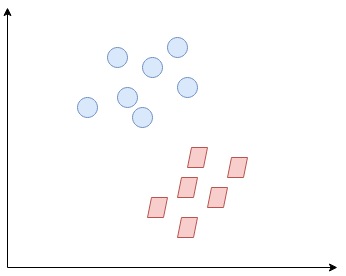
¿Puedes decidir cuál será la línea de separación? Es posible que se le haya ocurrido esto:
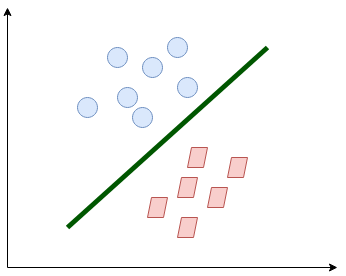
La línea separa bastante las clases. Esto es lo que esencialmente hace SVM: separación de clases simple. Agora, ¿cuáles son los datos?
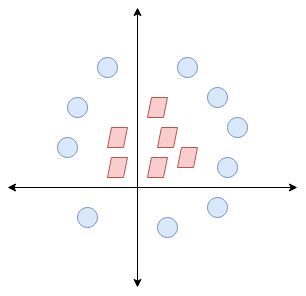
Aqui, no tenemos una línea simple que separe estas dos clases. Así que ampliaremos nuestra dimensão"Dimensão" É um termo usado em várias disciplinas, como a física, Matemática e filosofia. Refere-se à extensão em que um objeto ou fenômeno pode ser analisado ou descrito. Em física, por exemplo, fala-se de dimensões espaciais e temporais, enquanto em matemática pode se referir ao número de coordenadas necessárias para representar um espaço. Compreendê-lo é fundamental para o estudo e... e introduciremos una nueva dimensión a lo largo del eje z. Ahora podemos separar estas dos clases:
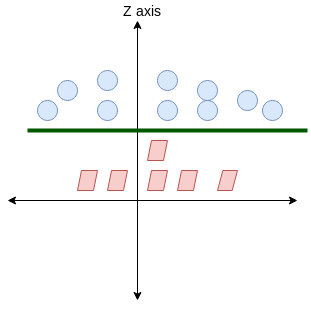
Cuando transformamos esta línea de nuevo al plano original, se asigna al límite circular como lo he mostrado aquí:
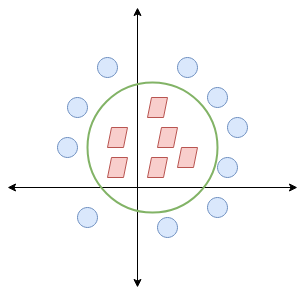
¡Esto es exactamente lo que hace SVM! Intenta encontrar una línea / hiperplano (en un espacio multidimensional) que separe estas dos clases. Luego clasifica el nuevo punto en función de si se encuentra en el lado positivo o negativo del hiperplano según las clases a predecir.
Hiperparámetros del algoritmo de máquina de vectores de soporte (SVM)
Hay algunos parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... importantes de SVM que debe conocer antes de continuar:
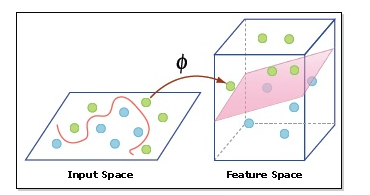
- Núcleo: Un kernel nos ayuda a encontrar un hiperplano en el espacio dimensional superior sin aumentar el costo computacional. Em geral, el costo computacional aumentará si aumenta la dimensión de los datos. Este aumento de dimensión es necesario cuando no podemos encontrar un hiperplano de separación en una dimensión determinada y debemos movernos en una dimensión superior:
- Hiperplano: Esta es básicamente una línea de separación entre dos clases de datos en SVM. Pero en la regresión de vectores de soporte, esta es la línea que se utilizará para predecir la salida continua
- Límite de decisión: Un límite de decisión se puede considerar como una línea de demarcación (para simplificar) en un lado de la cual se encuentran los ejemplos positivos y en el otro lado se encuentran los ejemplos negativos. En esta misma línea, los ejemplos pueden clasificarse como positivos o negativos. Este mismo concepto de SVM se aplicará también en la regresión de vectores de soporte
Para comprender SVM desde cero, recomiendo este tutorial: Comprender el algoritmo de Support Vector Machine (SVM) a partir de ejemplos.
Introducción a la regresión de vectores de soporte (SVR)
La regresión vectorial de soporte (SVR) utiliza el mismo principio que SVM, pero para problemas de regresión. Dediquemos unos minutos a comprender la idea detrás de SVR.
La idea detrás de la regresión de vectores de soporte
El problema de la regresión es encontrar una función que se aproxime al mapeo de un dominio de entrada a números reales sobre la base de una muestra de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina..... Así que ahora profundicemos y entendamos cómo funciona realmente la RVS.
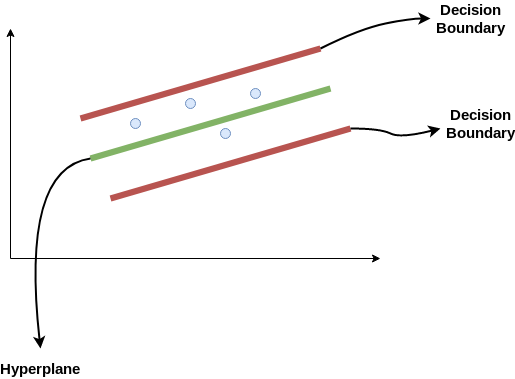
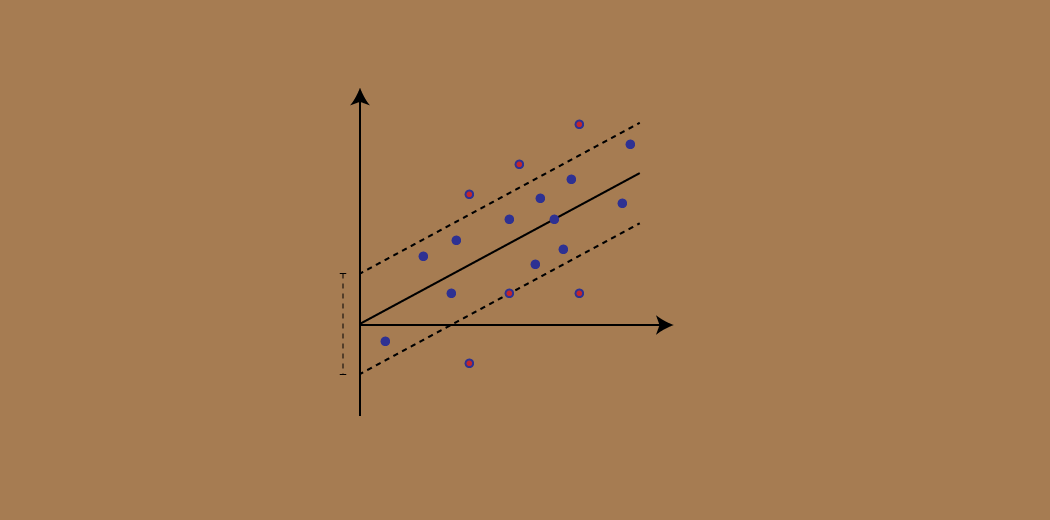
Considere estas dos líneas rojas como el límite de decisión y la línea verde como el hiperplano. Nosso objetivo, cuando estamos avanzando con SVR, es básicamente considerar los puntos que están dentro de la línea límite de decisión. Nuestra mejor línea de ajuste es el hiperplano que tiene un número máximo de puntos.
Lo primero que entenderemos es cuál es el límite de decisión (¡la línea roja de peligro arriba!). Considere que estas líneas están a cualquier distancia, Digamos “uma”, del hiperplano. Então, estas son las líneas que dibujamos a la distancia ‘+ a’ y ‘-a’ del hiperplano. Esta ‘a’ en el texto se conoce básicamente como épsilon.
Suponiendo que la ecuación del hiperplano es la siguiente:
Y = wx+b (equation of hyperplane)
Entonces las ecuaciones de límite de decisión se convierten en:
wx+b= +a
wx+b= -a
Portanto, cualquier hiperplano que satisfaga nuestra RVS debería satisfacer:
-uma < E- wx+b < +uma
Nuestro principal objetivo aquí es decidir un límite de decisión a una distancia ‘a’ del hiperplano original, de modo que los puntos de datos más cercanos al hiperplano o los vectores de soporte estén dentro de esa línea límite.
Portanto, vamos a tomar solo aquellos puntos que están dentro del límite de decisión y tienen la menor tasa de error, o están dentro del MargemMargem é um termo usado em uma variedade de contextos, como contabilidade, Economia e impressão. Em contabilidade, refere-se à diferença entre receitas e custos, que permite avaliar a rentabilidade de um negócio. No domínio da publicação, A margem é o espaço em branco ao redor do texto em uma página, que facilita a leitura e proporciona uma apresentação estética. Seu correto manejo é essencial.. de Tolerancia. Esto nos da un modelo de mejor ajuste.
Implementación de regresión vectorial de soporte (SVR) e Python
¡Es hora de ponernos nuestros sombreros de codificación! Nesta secção, entenderemos el uso de la regresión de vectores de soporte con la ayuda de un conjunto de datos. Aqui, tenemos que predecir el salario de un empleado dadas algunas variables independientes. ¡Un proyecto clásico de análisis de recursos humanos!
Paso 1: importar as bibliotecas
Paso 2: leer el conjunto de datos
Paso 3: Escalado de funciones
Un conjunto de datos del mundo real contiene características que varían en magnitudes, unidades y rango. Sugeriría realizar la padronizaçãoA padronização é um processo fundamental em várias disciplinas, que busca estabelecer padrões e critérios uniformes para melhorar a qualidade e a eficiência. Em contextos como engenharia, Educação e administração, A padronização facilita a comparação, Interoperabilidade e compreensão mútua. Ao implementar normas, a coesão é promovida e os recursos são otimizados, que contribui para o desenvolvimento sustentável e a melhoria contínua dos processos.... cuando la escala de una característica es irrelevante o engañosa.
Feature Scaling básicamente ayuda a normalizar los datos dentro de un rango particular. Normalmente, varios tipos de clases comunes contienen la función de escalado de características para que realicen la escala de características automáticamente. Porém, la clase SVR no es un tipo de clase de uso común, por lo que deberíamos realizar el escalado de características con Python.
Paso 4: ajuste de SVR al conjunto de datos
El kernel es la característica más importante. Hay muchos tipos de núcleos: lineales, gaussianos, etc. Cada uno se utiliza según el conjunto de datos. Para mais informações sobre este, lea esto: Soporte Vector Machine (SVM) em Python e R
Paso 5. Predecir un nuevo resultado
Então, la predicción para y_pred (6, 5) será 170,370.
Paso 6. Visualización de los resultados de SVR (para una resoluçãoo "resolução" refere-se à capacidade de tomar decisões firmes e atingir metas estabelecidas. Em contextos pessoais e profissionais, Envolve a definição de metas claras e o desenvolvimento de um plano de ação para alcançá-las. A resolução é fundamental para o crescimento pessoal e o sucesso em várias áreas da vida, pois permite superar obstáculos e manter o foco no que realmente importa.... más alta y una curva más suave)
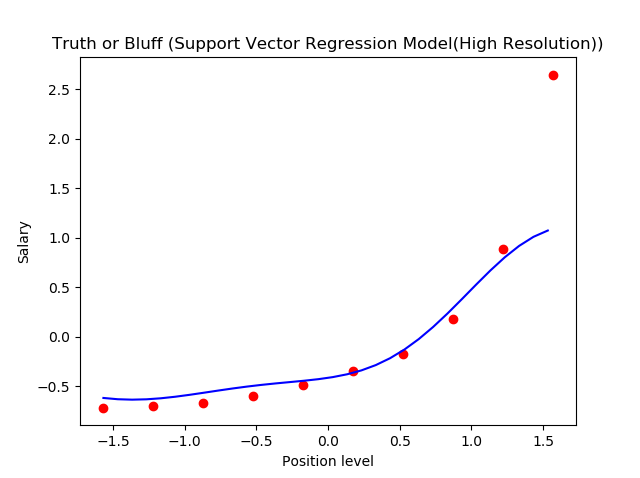
Esto es lo que obtenemos como salida: la línea de mejor ajuste que tiene un número máximo de puntos. ¡Bastante preciso!
Notas finais
Podemos pensar en la regresión de vectores de soporte como la contraparte de SVM para los problemas de regresión. SVR reconoce la presencia de no linealidad en los datos y proporciona un modelo de predicción competente.
Me encantaría escuchar sus pensamientos e ideas sobre el uso de SVR para el análisis de regresión. ¡Conéctese conmigo en la sección de comentarios a continuación e ideemos!





