Uma analogia simples para explicar a árvore de decisão versus a floresta aleatória
Vamos começar com um experimento de pensamento que ilustrará a diferença entre uma árvore de decisão e um modelo florestal aleatório..
Suponha que um banco tenha que aprovar uma pequena quantia de empréstimo para um cliente e o banco precisa tomar uma decisão rapidamente.. O banco verifica o histórico de crédito da pessoa e a situação financeira e descobre que ainda não pagou o empréstimo anterior. Por tanto, O banco rejeita o pedido.
Mas aqui está o problema: O valor do empréstimo era muito pequeno para os imensos cofres do banco e eles poderiam facilmente tê-lo aprovado em uma extensão de risco muito baixo.. Portanto, O banco perdeu a oportunidade de ganhar algum dinheiro..
Agora, Outro pedido de empréstimo chegará em poucos dias, Mas desta vez o banco apresenta uma estratégia diferente: Múltiplos processos de tomada de decisão. As vezes, primeiro verificar histórico de crédito e, as vezes, Primeiro verifique a condição financeira do cliente e o valor do empréstimo. Mais tarde, O banco combina os resultados desses múltiplos processos de tomada de decisão e decide conceder o empréstimo ao cliente.
Mesmo que esse processo demorou mais do que o anterior, O banco se beneficiou desse método. Este é um exemplo clássico em que a tomada de decisões coletivas superou um único processo de tomada de decisão.. Agora, Aqui está minha pergunta para você.: Sabe o que esses dois processos representam??

São árvores de decisão e uma floresta aleatória!! Vamos explorar essa ideia em detalhes aqui, Vamos aprofundar as principais diferenças entre esses dois métodos e responder à pergunta-chave.: Que algoritmo de aprendizagem de máquina devo usar?
Tabela de conteúdo
- Breve introdução às árvores de decisão
- Uma visão geral das florestas aleatórias
- Floresta aleatória e choque de árvore de decisão (Em código!)
- Por que a floresta aleatória superou uma árvore de decisão?
- Árvore de decisão vs. floresta aleatória: Quando você deve escolher qual algoritmo?
Breve introdução às árvores de decisão
Uma árvore de decisão é um algoritmo de aprendizagem de máquina supervisionado que pode ser usado para problemas de classificação e regressão.. Uma árvore de decisão é simplesmente uma série de decisões sequenciais que são tomadas para alcançar um resultado específico.. Aqui está uma ilustração de uma árvore de decisão em ação (Usando nosso exemplo acima):
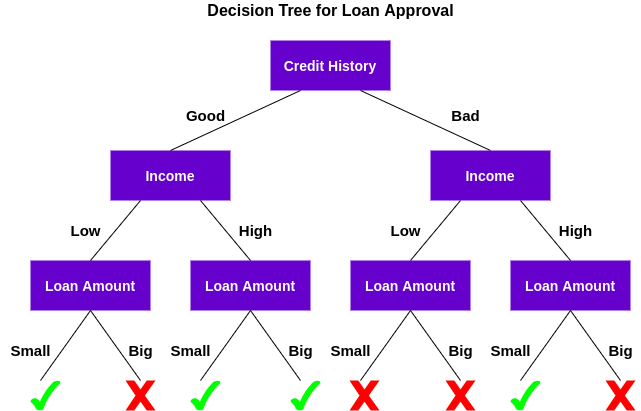
Vamos entender como essa árvore funciona..
Primeiro, Verifique se o cliente tem um bom histórico de crédito. Com base nisso, Classifique o cliente em dois grupos, quer dizer, clientes com bom histórico de crédito e clientes com histórico de crédito ruim. Mais tarde, Verifica a receita do cliente e novamente classifica-os em dois grupos. Finalmente, Verifique o valor do empréstimo solicitado pelo cliente. De acordo com os resultados da verificação dessas três características, A árvore de decisão decide se o empréstimo do cliente deve ou não ser aprovado.
Características / atributos e condições podem mudar dependendo dos dados e complexidade do problema, Mas a ideia geral permanece a mesma. Então, Uma árvore de decisão toma uma série de decisões baseadas em um conjunto de características / atributos presentes nos dados, que, neste caso, foram o histórico de crédito, renda e valor do empréstimo.
Agora, Você deve estar se perguntando:
Por que a decisão da árvore verificar o score de crédito primeiro, não renda?
Isso é conhecido como importância de recurso e a sequência de atributos a serem verificados é decidida com base em critérios como Índiceo "Índice" É uma ferramenta fundamental em livros e documentos, que permite localizar rapidamente as informações desejadas. Geralmente, é apresentado no início de um trabalho e organiza os conteúdos de forma hierárquica, incluindo capítulos e seções. Sua correta preparação facilita a navegação e melhora a compreensão do material, tornando-se um recurso essencial para estudantes e profissionais de várias áreas.... de impureza de Gini o Ganho de informação. A explicação desses conceitos está além do escopo do nosso artigo aqui, Mas você pode conferir qualquer um dos recursos abaixo para saber tudo sobre árvores de decisão.:
Observação: A ideia por trás deste artigo é comparar árvores de decisão e florestas aleatórias.. Portanto, Eu não vou entrar em detalhes do básico, mas eu vou fornecer os links relevantes no caso de você querer explorar mais.
Uma visão geral da Floresta Aleatória
O algoritmo da árvore de decisão é bastante fácil de entender e interpretar. Mas muitas vezes, Uma única árvore não é suficiente para produzir resultados efetivos. É aqui que o algoritmo da Floresta Aleatória entra em jogo.

Random Forest é um algoritmo de aprendizagem de máquina baseado em árvores que aproveita o poder de múltiplas árvores de decisão para tomar decisões.. Como o nome sugere, É um “floresta” de árvores!
Mas, Por que chamamos de floresta? “aleatória”? Isso é porque é uma floresta de Árvores de decisão criadas aleatoriamente. Cada nó na árvore de decisão funciona em um subconjunto aleatório de recursos para calcular a saída. A floresta aleatória então combina a saída de árvores de decisão individuais para gerar a saída final..
Em palavras simples:
Algoritmo florestal aleatório combina saída de múltiplas árvores de decisão (aleatoriamente criado) Para gerar a saída final.
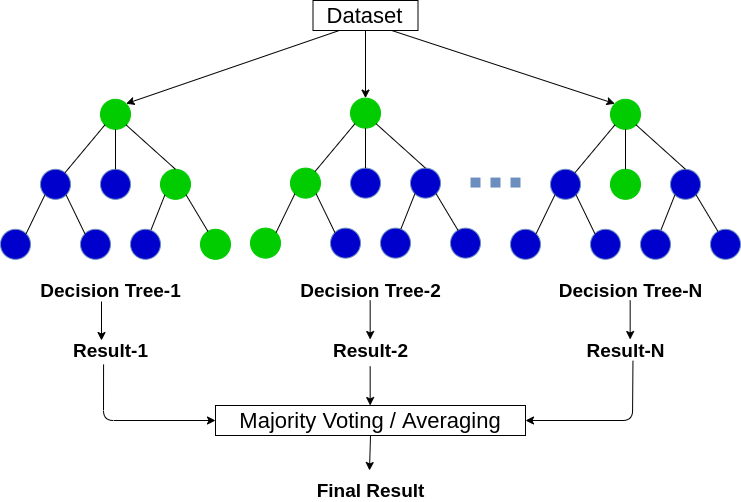
Este processo de combinação da saída de vários modelos individuais (Também conhecidos como estudantes fracos) se chama Aprendizado conjunto. Se você quiser ler mais sobre como a floresta aleatória e outros algoritmos de aprendizado de conjunto funcionam, Veja os artigos a seguir:
Agora a questão é, Como podemos decidir qual algoritmo escolher entre uma árvore de decisão e uma floresta aleatória?? Vamos vê-los em ação antes de tirar conclusões precipitadas!!
Floresta aleatória e choque de árvore de decisão (Em código!)
Nesta secção, usaremos python para resolver um problema de classificação binária usando uma árvore de decisão e uma floresta aleatória. Então vamos comparar seus resultados e ver qual se adequa melhor ao nosso problema..
Nós vamos estar trabalhando no Conjunto de dados de previsão de empréstimos por DataPeaker Plataforma DataHack. Este é um problema de classificação binária onde temos que determinar se uma pessoa deve ou não receber um empréstimo com base em um determinado conjunto de características..
Observação: Você pode ir para o DataHack plataforma e competir com outras pessoas em várias competições de aprendizado de máquina online e ter a chance de ganhar prêmios emocionantes.
Pronto para codificar?
Paso 1: Carregar as bibliotecas e conjuntos de dados
Vamos começar importando as bibliotecas Python necessárias e nosso conjunto de dados.:

O conjunto de dados consiste em 614 linhas e 13 caracteristicas, incluindo histórico de crédito, Estado civil, valor do empréstimo e gênero. Aqui, a variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... de destino es Loan_Status, indicando se uma pessoa deve ou não receber um empréstimo.
Paso 2: pré-processamento de dados
Agora vem a parte mais crucial de qualquer projeto de ciência de dados: DPré-processamento ata e féEngenharia Natural. Nesta secção, Vou lidar com as variáveis categóricas nos dados e também imputar os valores faltantes.
Vou imputar os valores perdidos nas variáveis categóricas com a moda, e para variáveis contínuas, com a média (para as respectivas colunas). O que mais, Vamos rotular codificando os valores categóricos nos dados. Você pode ler este artigo para saber mais sobre Codificação de rótulo.

Paso 3: Criando suítes de teste e trens
Agora, Vamos dividir o conjunto de dados em um 80:20 Relacionamento para treinamento e testes, respectivamente:
Vamos dar uma olhada na forma do trem criado e conjuntos de testes:

Excelente! Estamos prontos para a próxima etapa onde criaremos a árvore de decisão e modelos florestais aleatórios!!
Paso 4: Construção e avaliação do modelo
Uma vez que temos os conjuntos de treinamento e testes, É hora de treinar nossos modelos e classificar pedidos de empréstimo. Primeiro, Vamos treinar uma árvore de decisão neste conjunto de dados:
A seguir, vamos avaliar este modelo usando F1-Score. F1-Score é a média harmônica de precisão e recuperação dada pela fórmula:
![]()
Você pode aprender mais sobre esta e outras métricas de avaliação aqui:
Vamos avaliar o desempenho do nosso modelo usando a pontuação da F1:
![]()
![]()
Aqui, Você pode ver que a árvore de decisão funciona bem na avaliação dentro da amostra, mas seu desempenho diminui drasticamente na avaliação fora da amostra. Por que acha que é esse o caso?? Infelizmente, Nosso modelo de árvore de decisão é superequipado para dados de treinamento. A floresta aleatória resolverá esse problema??
Construindo um modelo florestal aleatório
Vamos ver um modelo de floresta aleatória em ação:
![]()
![]()
Aqui, Podemos ver claramente que o modelo florestal aleatório teve um desempenho muito melhor do que a árvore de decisão na avaliação fora da amostra.. Vamos discutir as razões por trás disso na próxima seção..
Por que nosso modelo de floresta aleatória superou a árvore de decisão?
Floresta aleatória aproveita o poder de múltiplas árvores de decisão. Sim, é verdade. não dependem da importância do recurso dado por uma única árvore de decisão. Vamos dar uma olhada na importância do recurso dado por diferentes algoritmos para diferentes características.:
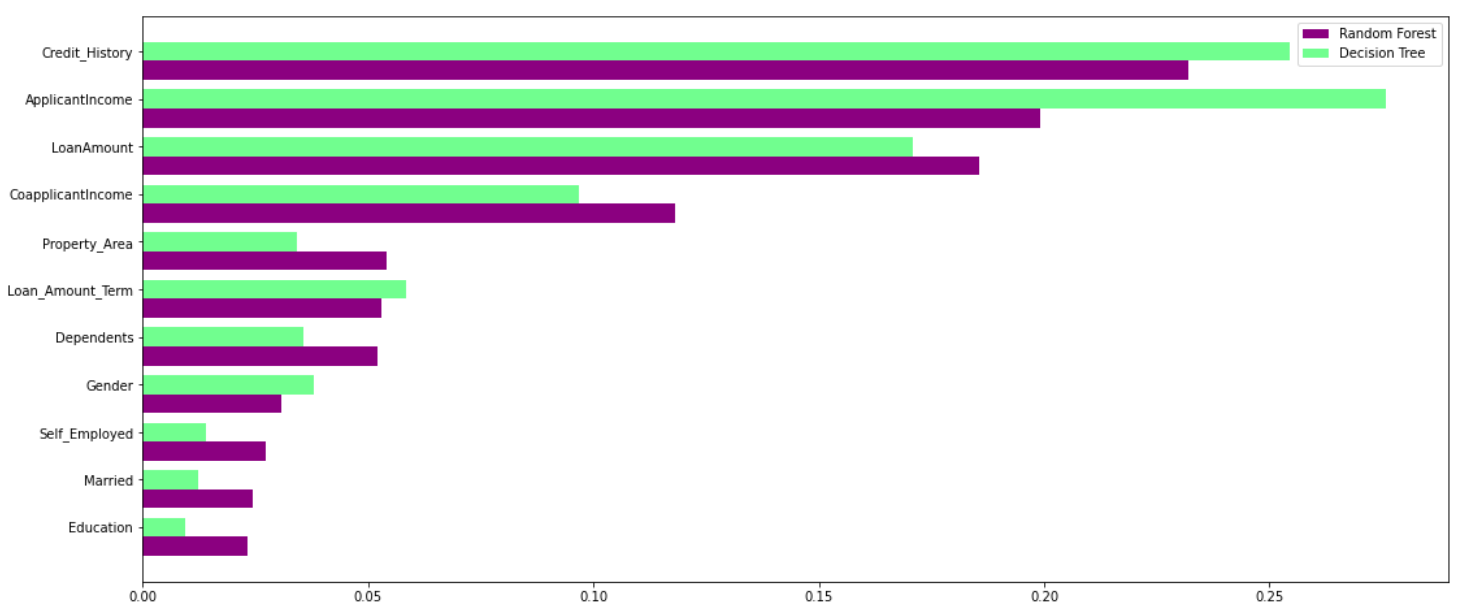
Como você pode ver claramente no gráfico acima, O modelo de árvore de decisão coloca grande importância em um determinado conjunto de características. Mas a floresta aleatória escolhe características aleatoriamente durante o processo de treinamento.. Portanto, não depende muito de nenhum conjunto específico de recursos. Esta é uma característica especial da floresta aleatória em árvores ensacadas.. Você pode ler mais sobre o saco.Classificador de árvores ING aqui.
Portanto, A floresta aleatória pode generalizar os dados de uma maneira melhor. Esta seleção aleatória de características torna a floresta aleatória muito mais precisa do que uma árvore de decisão..
Então, Qual você deve escolher: Árvore de decisão ou floresta aleatória?
Random Forest é adequado para situações em que temos um grande conjunto de dados e a interpretabilidade não é uma grande preocupação..
Árvores de decisão são muito mais fáceis de interpretar e entender. Uma vez que uma floresta aleatória combina várias árvores de decisão, torna-se mais difícil de interpretar. Aqui está a boa notícia.: Não é impossível interpretar uma floresta aleatória. Aqui está um artigo que fala sobre interpretar os resultados de um modelo florestal aleatório:
O que mais, Random Forest tem um tempo de treinamento maior do que uma única árvore de decisão. Você precisa ter isso em mente, porque à medida que aumentamos o número de árvores em uma floresta aleatória, O tempo que leva para treinar cada um deles também aumenta. Isso muitas vezes pode ser crucial quando você está trabalhando com um prazo apertado em um projeto de aprendizado de máquina..
Mas eu vou dizer isso: apesar da instabilidade e dependência de um conjunto particular de características, Árvores de decisão são realmente úteis porque são mais fáceis de interpretar e mais rápidas de treinar. Qualquer pessoa com muito pouco conhecimento em ciência de dados também pode usar árvores de decisão para tomar decisões rápidas e baseadas em dados..
Notas finais
Isso é essencialmente o que você precisa saber na árvore de decisão versus o debate florestal aleatório.. Pode ficar complicado quando você é novo no aprendizado de máquina, Mas este artigo deveria ter esclarecido as diferenças e semelhanças para você..
Você pode me contatar com suas dúvidas e pensamentos na seção de comentários abaixo.





