Introdução
Muitos analistas interpretam mal o termo “impulso” usado em ciência de dados. Deixe-me dar-lhe uma explicação interessante sobre este termo. Boosting capacita os modelos de aprendizado de máquina para melhorar sua precisão de previsão.
Os algoritmos de reforço são um dos algoritmos mais usados em competições de ciência de dados. Os vencedores do nosso últimas hackathons concordam que estão tentando empurrar o algoritmo para melhorar a precisão de seus modelos.
Neste artigo, Vou explicar como o algoritmo boost funciona de uma forma muito simples. Eu também compartilhei os códigos python abaixo. Eu pulei as derivações matemáticas intimidantes usadas em Boosting. Porque isso não me permitiria explicar esse conceito em termos simples.
Comecemos.

o que é impulso?
Definição: O fim “Impulso” refere-se a uma família de algoritmos que transforma um aprendiz fraco em um aprendiz forte.
Vamos entender essa definição em detalhes resolvendo um problema de identificação de e-mail de spam:
Como você classificaria um e-mail como SPAM ou não? como todo mundo, nosso foco inicial seria identificar e-mails “Spam” e “sem spam” usando os seguintes critérios. E:
- O email tem apenas um arquivo de imagem (imagem promocional), você é um SPAM
- E-mail só tem link (s), você é um SPAM
- O corpo do e-mail consiste em uma frase como “Você ganhou um prêmio em dinheiro de $ xxxxxx”, você é um SPAM
- Email do nosso domínio oficial “Analyticsvidhya.com“, Não é SPAM
- E-mail de fonte conhecida, sem SPAM
Anteriormente, definimos várias regras para classificar um email em 'spam'’ o ‘no spam’. Mas, você acha que essas regras individualmente são fortes o suficiente para classificar com sucesso um e-mail? Não.
Individualmente, essas regras não são poderosas o suficiente para classificar um e-mail como 'spam'’ o ‘no spam’. Portanto, essas regras são chamadas aluno fraco.
Para transformar um aluno fraco em um aluno forte, vamos combinar a previsão de cada aluno fraco usando métodos como:
• Usando média / média ponderada
• Considerando que a previsão tem a maior votação
Por exemplo: Acima, nós temos definido 5 alunos fracos. Destes 5, 3 são votados como 'SPAM’ e 2 são votados como 'Não SPAM'. Neste caso, por padrão, consideraremos um e-mail como SPAM porque temos uma votação mais alta (3) para ‘SPAM’.
Como os algoritmos de impulso funcionam?
Agora sabemos que o momento combina uma pupila fraca, também conhecido como Aluno Básico, para formar uma regra sólida. Uma pergunta imediata que deve surgir em sua mente é: ‘Como impulsionar a identificação de regras fracas?‘
Para encontrar uma regra fraca, aplicamos algoritmos de aprendizado básico (ML) com um layout diferente. Toda vez que o algoritmo de aprendizado básico é aplicado, gera uma nova regra de previsão fraca. Este é um processo iterativo. Depois de muitas iterações, o algoritmo boost combina essas regras fracas em uma única regra de previsão forte.
Aqui está outra pergunta que pode assombrá-lo ”.Como escolhemos uma distribuição diferente para cada rodada? ‘
Para escolher a distribuição correta, estes são os próximos passos:
Paso 1: O aprendiz básico toma todas as distribuições e atribui igual peso ou atenção a cada observação..
Paso 2: Se houver algum erro de previsão causado pelo primeiro algoritmo de aprendizado básico, então prestamos mais atenção às observações que têm um erro de previsão. Mais tarde, Aplicamos o seguinte algoritmo de aprendizado básico.
Paso 3: Repita o passo 2 até que o limite do algoritmo de aprendizado básico seja alcançado ou uma precisão mais alta seja alcançada.
Finalmente, combina os resultados do aluno fraco e cria um aluno forte que, em última análise, melhora o poder preditivo do modelo. O reforço presta mais atenção a exemplos classificados incorretamente ou com erros mais altos devido a regras fracas anteriores.
Tipos de algoritmos de impulso
O mecanismo subjacente usado para conduzir algoritmos pode ser qualquer coisa. Pode ser um carimbo de decisão, um algoritmo de classificação que maximiza as margens, etc. Existem muitos algoritmos de impulso que usam outros tipos de mecanismos, O que:
- AdaBoost (Existirativo AumentarAssustador)
- Aumento da Árvore Gradiente
- XGBoost
Neste artigo, vamos nos concentrar no AdaBoost e Gradient Boosting seguidos de seus respectivos códigos python e focar no XGboost no próximo artigo.
Aumento de algoritmo: AdaBoost
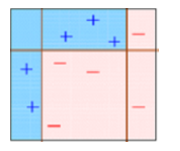
Este diagrama explica adequadamente o Ada-boost. vamos entender de perto:
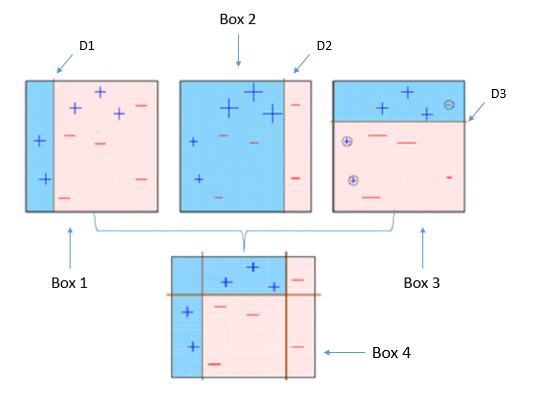
Caixa 1: Você pode ver que atribuímos pesos iguais a cada ponto de dados e aplicamos um toco de decisão para classificá-los como + (mais) o – (menos). toco de decisão (D1) gerou uma linha vertical no lado esquerdo para classificar os pontos de dados. Nós vemos que, esta linha vertical previu incorretamente três + (mais) O que – (menos). Em tal caso, atribuiremos pesos mais altos a esses três + (mais) e aplicar outro toco de decisão.
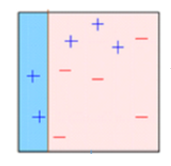
Caixa 2: Aqui, você pode ver que o tamanho de três + (mais) previsto incorretamente é maior em comparação com o resto dos pontos de dados. Neste caso, o segundo toco de decisão (D2) tentará prevê-los corretamente. Agora, uma linha vertical (D2) no lado direito deste gráfico você classificou corretamente três + (mais) classificado incorretamente. mas novamente, causou erros de classificação. desta vez com três – (menos). Novamente, vamos atribuir um peso maior a três – (menos) e aplicar outro toco de decisão.
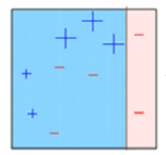
Caixa 3: Aqui, três – (menos) receber pesos maiores. Um toco de decisão é aplicado (D3) para prever corretamente essas observações mal classificadas. Desta vez é gerada uma linha horizontal para classificar + (mais) e – (menos) com base em um peso maior de observação mal classificada.
Caixa 4: Aqui, nós combinamos D1, D2 e D3 para formar uma previsão forte que tem uma regra complexa em comparação com um aluno fraco individual. Você pode ver que esse algoritmo classificou essas observações muito bem em comparação com qualquer um dos alunos fracos individuais.
AdaBoost (Existirativo Aumentaring): Funciona com um método semelhante ao descrito acima. Se ajusta a una secuencia de estudiantes débiles en diferentes datos de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... ponderados. Comece prevendo o conjunto de dados original e dê a cada observação o mesmo peso.. Se a previsão estiver errada usando o primeiro aluno, então mais peso é dado às observações que foram previstas incorretamente. Sendo um processo iterativo, continua adicionando alunos até que um limite no número de modelos ou precisão seja atingido.
Principalmente, usamos selos de decisão com AdaBoost. Mas podemos usar qualquer algoritmo de aprendizado de máquina como um aprendiz básico se ele aceitar o peso no conjunto de dados de treinamento. Podemos usar algoritmos AdaBoost para problemas de classificação e regressão.
Você pode consultar o artigo “Como ficar esperto com aprendizado de máquina: AdaBoost” para entender os algoritmos AdaBoost com mais detalhes.
Código Python
Aqui está uma janela de codificação ao vivo para você começar. Você pode executar os códigos e obter o resultado nesta janela:
Puede ajustar los parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... para optimizar el rendimiento de los algoritmos, Eu mencionei abaixo os principais parâmetros para ajuste:
- n_estimators: Controle o número de alunos fracos.
- taxa de Aprendizagem:CControla a contribuição de alunos fracos na combinação final. Há uma troca entre taxa de Aprendizagem e n_estimators.
- base_estimators: Ajuda a especificar diferentes algoritmos de aprendizado de máquina.
Você também pode ajustar os parâmetros básicos do aluno para otimizar seu desempenho.
algoritmo de impulso: aumento de gradiente
En el aumento de gradienteGradiente é um termo usado em vários campos, como matemática e ciência da computação, descrever uma variação contínua de valores. Na matemática, refere-se à taxa de variação de uma função, enquanto em design gráfico, Aplica-se à transição de cores. Esse conceito é essencial para entender fenômenos como otimização em algoritmos e representação visual de dados, permitindo uma melhor interpretação e análise em..., treinar muitos modelos sequencialmente. Cada nuevo modelo minimiza gradualmente la Função de perdaA função de perda é uma ferramenta fundamental no aprendizado de máquina que quantifica a discrepância entre as previsões do modelo e os valores reais. Seu objetivo é orientar o processo de treinamento, minimizando essa diferença, permitindo assim que o modelo aprenda de forma mais eficaz. Existem diferentes tipos de funções de perda, como erro quadrático médio e entropia cruzada, cada um adequado para diferentes tarefas e... (y = machado + b + e, e precisa de atenção especial, pois é um termo de erro) de todo o sistema usando Gradiente descendente método. El procedimiento de aprendizaje se ajustó consecutivamente a nuevos modelos para proporcionar una estimación más precisa de la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... Resposta.
A ideia principal por trás deste algoritmo é construir novas pupilas de base que possam ser correlacionadas ao máximo com o gradiente negativo da função de perda, associado a todo. Você pode consultar o artigo “Aprenda o algoritmo de aumento de gradiente” para entender este conceito com um exemplo.
Na biblioteca Sklearn Python, Use Gradient Tree Boosting o GBRT. É uma generalização do impulso para funções de perda diferenciáveis arbitrárias. Pode ser usado para problemas de regressão e classificação.
Código Python
da importação sklearn.ensemble GradientBoostingClassifier #Para Classificação da importação sklearn.ensemble Aumento de gradienteRegressor #Para regressão
clf = GradientBoostingClassifier(n_estimators=100, taxa de Aprendizagem=1.0, profundidade máxima=1) clf.ajuste(X_train, y_train)
- n_estimators: Controle o número de alunos fracos.
- taxa de Aprendizagem:CControla a contribuição de alunos fracos na combinação final. Há uma troca entre taxa de Aprendizagem e n_estimators.
- Profundidade máxima: profundidade máxima de estimadores de regressão individuais. A profundidade máxima limita o número de nós na árvore. Ajuste este parâmetro para melhor desempenho; o melhor valor depende da interação das variáveis de entrada.
Você pode ajustar a função de perda para melhor desempenho.
Nota final
Neste artigo, Analisamos o impulso, um dos métodos de modelagem de conjunto para melhorar o poder de previsão. Aqui, discutimos a ciência por trás do impulso e seus dois tipos: AdaBoost e Gradient Boost. Também estudamos seus respectivos códigos Python.
No meu próximo artigo, Vou discutir sobre outro tipo de algoritmos de impulso que agora é um segredo de dias para ganhar concursos de ciência de dados “XGBoost”.
Você acha útil este artigo? Compartilhe suas opiniões / pensamentos na seção de comentários abaixo.





