Este artigo foi publicado como parte do Data Science Blogathon.
Introdução

Web Scraping é um método ou arte para obter ou excluir dados da Internet ou sites e armazená-los localmente em seu sistema. Web Scripting é uma estratégia programada para adquirir muitas informações de sites.
A grande maioria dessas informações são informações não estruturadas em um layout HTML que posteriormente são convertidas em informações organizadas em uma página de contabilidade ou conjunto de dados., então tende a ser usado em diferentes aplicações. Há uma ampla gama de abordagens de web scraping para obter informações de sites. Isso inclui o uso de aplicativos da web, API específicas o, em qualquer caso, faça seu código para web scraping sem qualquer preparação.
Vários sites enormes como o Google, Twitter, Facebook, StackOverflow, etc. têm APIs que permitem acessar suas informações em uma organização organizada. Esta é a opção mais ideal, mas diferentes localidades não permitem que os clientes acessem muitas informações em uma estrutura organizada ou, em essência, eles não progridem tão mecanicamente. Por ai, é ideal usar Web Scraping para encontrar informações no site.

Os Web Scrapers podem extrair todas as informações sobre destinos específicos ou as informações específicas de que o cliente precisa. Preferencialmente, é ideal se você indicar as informações de que precisa para que o raspador da web simplesmente concentre essas informações rapidamente. Por exemplo, você deve raspar uma página da Amazon para os tipos de espremedores disponíveis, porém, você pode precisar apenas das informações sobre os modelos de vários espremedores e não das auditorias de clientes.
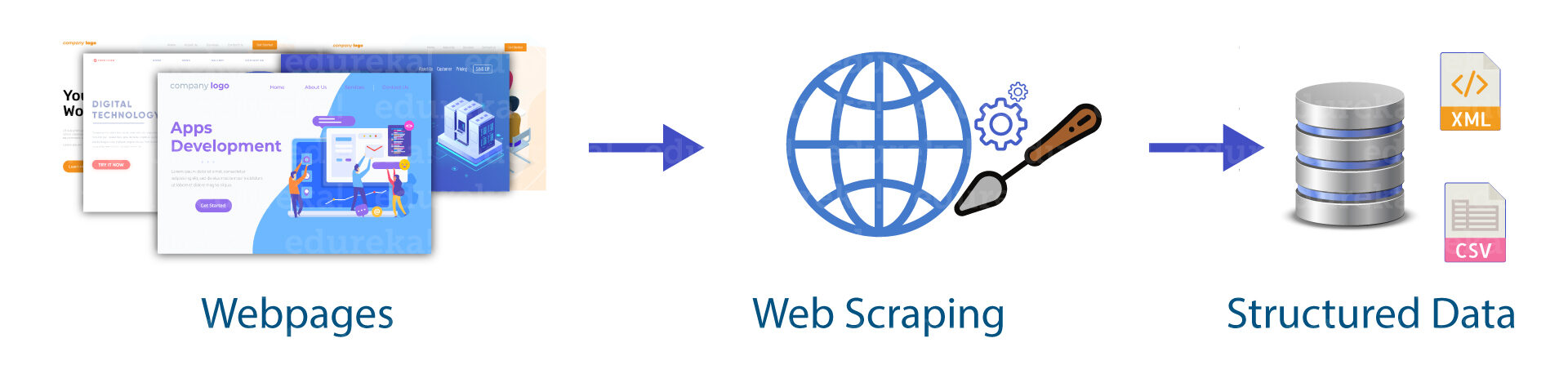
Então, quando um depurador da web precisa arranhar um site, primeiro você recebe os URLs das localidades necessárias. Nesse ponto, empilhar todo o código HTML para esses destinos e um raspador mais desenvolvido pode até mesmo concentrar todos os componentes CSS e Javascript também. Nesse ponto, o raspador obtém as informações necessárias deste código HTML e transfere essas informações para a organização indicada pelo cliente.
Geralmente, isso é como uma página de contabilidade do Excel ou um registro csv, porém, as informações também podem ser armazenadas em diferentes organizações, por exemplo, um documento JSONJSON, o Notação de objeto JavaScript, É um formato leve de troca de dados que é fácil para os humanos lerem e escreverem, e fácil para as máquinas analisarem e gerarem. É comumente usado em aplicativos da web para enviar e receber informações entre um servidor e um cliente. Sua estrutura é baseada em pares de valores-chave, tornando-o versátil e amplamente adotado no desenvolvimento de software...

Bibliotecas populares de Python para web scraping
- Petições
- Sopa linda 4
- lxml
- Selênio
- Scrapy
AutoScraper
É uma biblioteca de web scraping em Python para tornar a web scraping inteligente, automático, Rápido e fácil. Também é leve, o que significa que não afetará muito o seu PC. Um usuário pode usar facilmente esta ferramenta de coleta de dados devido à sua interface amigável.. Para iniciar, você só precisa escrever algumas linhas de código e você verá a mágica.
Você só precisa fornecer o URL ou o conteúdo HTML da página da web da qual deseja remover os dados, O que mais, um resumo das informações de teste que devemos remover dessa página. Esta informação pode ser um texto, URL ou qualquer tag HTML nessa página. Aprenda as regras de rascunho por conta própria e devolva itens semelhantes.
Neste artigo, vamos investigar o Autoscraper e ver como podemos usá-lo para remover nossas informações.

Instalação
Existem 3 maneiras de instalar esta biblioteca em seu sistema.
- Instale a partir do repositório git usando pip:
pip install git + https://github.com/alirezamika/autoscraper.git
pip install autoscraper
python setup.py install
Importando biblioteca
Só importaremos um raspador automático, pois é adequado apenas para arranhar a web. Abaixo está o código para importar:
de autoscraper import AutoScraper
Definição da função web scraping
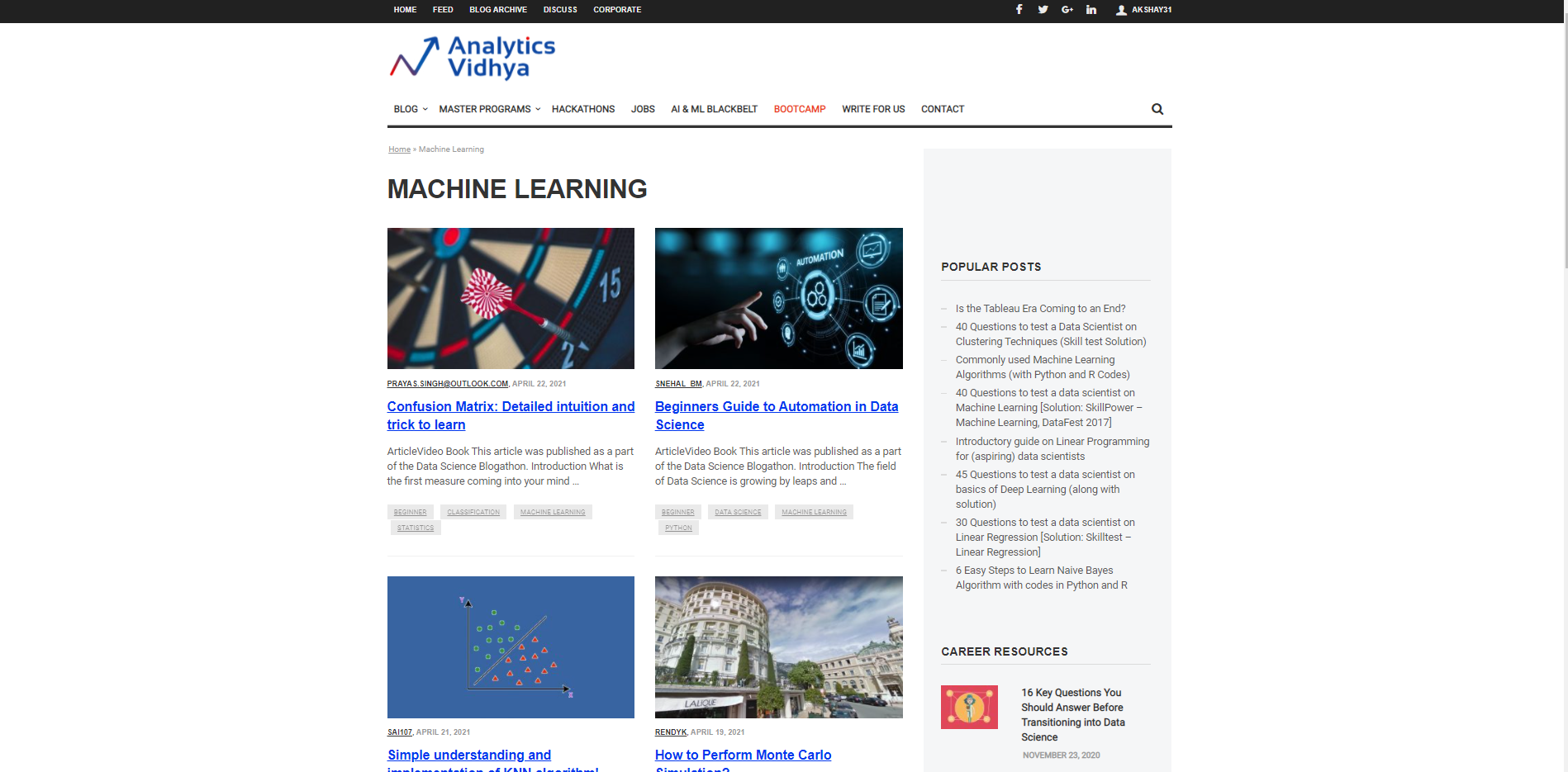
Comecemos caracterizando uma URL a partir da qual ela será usada para trazer as informações e as provas das informações necessárias a serem trazidas. Suponha que queremos pesquisar o Títulos para diferentes artigos sobre aprendizado de máquina no site DataPeaker. Portanto, temos que passar o URL da seção do blog de aprendizado de máquina DataPeaker e a segunda lista de procurados. A lista de procurados é uma lista que é Dados de amostra que queremos extrair dessa página. Por exemplo, aqui, a lista de procurados é um título de qualquer blog na seção de blog de aprendizado de máquina do DataPeaker.
url ="https://www.analyticsvidhya.com/blog/category/machine-learning/" queria_lista = ['Matriz de confusão: Intuição detalhada e truque para aprender ']
Podemos adicionar um ou mais candidatos à lista de procurados. Você também pode colocar URLs na lista de desejados para recuperá-los.
Inicie o AutoScraper
A próxima etapa após iniciar o URL e a lista desejada é chamar a função AutoScraper. Nosso objetivo é usar esse recurso para construir o modelo de raspador e realizar web scraping nessa página específica.
Isso pode ser iniciado usando o seguinte código:
raspador = AutoScraper()
Construindo o Objeto
Esta é a etapa final do web scraping com esta biblioteca específica. Aqui, criar o objeto e mostrar o resultado do web scraping.
raspador = AutoScraper() resultado = scraper.build(url, lista de procurados) imprimir(resultado)

Aqui, na foto acima, você pode ver que volta. o título dos blogs no site da DataPeaker na seção de aprendizado de máquina, de forma similar, podemos obter os URLs dos blogs simplesmente passando o URL de amostra na lista de procurados que definimos anteriormente.
url ="https://www.analyticsvidhya.com/blog/category/machine-learning/" queria_lista = ['https://www.analyticsvidhya.com/blog/2021/04/confusion-matrix-detailed-intuition-and-trick-to-learn/ '] raspador = AutoScraper() resultado = scraper.build(url, lista de procurados) imprimir(resultado)
Aqui está a saída do código acima. Você pode ver que eu passei o url na lista de procurados desta vez, como resultado, você pode ver o resultado como urls de blog

Salve o modelo
Isso nos permite salvar o modelo que temos que construir para poder recarregá-lo quando necessário.
Para salvar o modelo, use o seguinte código
scraper.save('blogs') #Forneça um caminho de arquivo
Para carregar o modelo, use o seguinte código:
scraper.load('blogs')
Observação: Além de cada uma dessas funcionalidades, o raspador automático também permite caracterizar endereços IP de proxy para que você possa usá-los para obter informações. Precisamos simplesmente caracterizar os proxies e passá-los como um argumento para a função de construção conforme mostrado abaixo:
proxies = {
"http": 'http://127.0.0.1:8001',
"https": 'https://127.0.0.1:8001',
}
resultado = scraper.build(url, lista de procurados, request_args = dict(proxies = proxies))
Para maiores informações, veja o link abaixo: AutoScraper
conclusão
Neste artigo, percebemos como podemos usar o Autoscraper para web scraping criando um modelo básico e simples de usar. Vimos vários formatos nos quais as informações podem ser recuperadas usando o Autoscraper. Também podemos salvar e carregar o modelo para usá-lo mais tarde, o que economiza tempo e esforço. O Autoscraper é incrível, fácil de usar e eficiente.
Obrigado por ler este artigo e por sua paciência.. Deixe-me na seção de comentários sobre comentários. Compartilhe este artigo, isso me motivará a escrever mais blogs para a comunidade de ciência de dados.
Identificação de e-mail: gakshay1210@ gmail.com
Me siga no LinkedIn: LinkedIn
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





