Este artigo foi publicado como parte do Data Science Blogathon.
Introdução
Gradiente Descida é um dos algoritmos de aprendizagem de máquina mais usados na indústria. E, porém, confunde muitos recém-chegados.
Eu entendo, eu entendo.! La matemática detrás del aumento de gradienteGradiente é um termo usado em vários campos, como matemática e ciência da computação, descrever uma variação contínua de valores. Na matemática, refere-se à taxa de variação de uma função, enquanto em design gráfico, Aplica-se à transição de cores. Esse conceito é essencial para entender fenômenos como otimização em algoritmos e representação visual de dados, permitindo uma melhor interpretação e análise em... no es fácil si recién está comenzando. Meu objetivo é ajudá-lo a obter uma intuição por trás da descida gradiente neste artigo..

Entenderemos rapidamente o papel de uma função de custo, a explicação da descida gradiente, como escolher o parâmetro de aprendizagem e o efeito de ultrapassagem na descida gradiente. Vamos começar!
O que é uma função de custo?
É um Função que mede o desempenho de um modelo para quaisquer dados. Função de custo quantifica o erro entre os valores previstos e os valores esperados e apresenta-o na forma de um único número real.
Luego de realizar una hipótesis con parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... iniciales, calculamos a função Custo. E com o objetivo de reduzir a função de custo, modificamos os parâmetros usando o algoritmo de descida gradiente nos dados dado. Aqui está a representação matemática para ele:
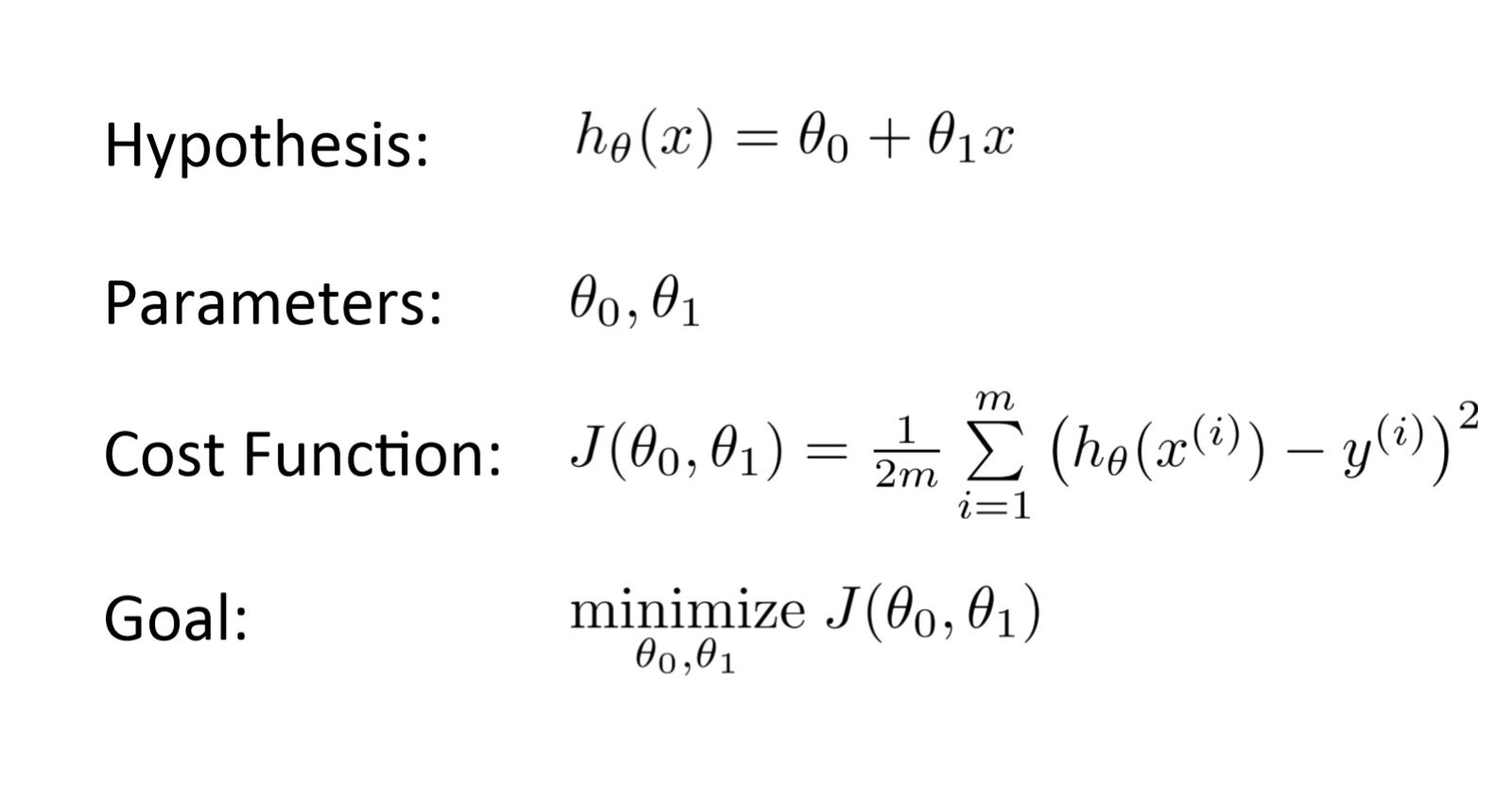
O que é descida gradiente?
A pergunta do Milhão de Dólares!
Digamos que você está jogando um jogo onde os jogadores estão no topo de uma montanha e são convidados a chegar ao ponto mais baixo da montanha.. O que mais, estão vendados. Então, Que abordagem você acha que faria você chegar ao lago??
Pense um pouco sobre isso antes de ler..
A melhor maneira é observar o solo e encontrar onde a terra desce. A partir dessa posição, dar um passo em uma direção para baixo e iterar este processo até chegar ao ponto mais baixo.
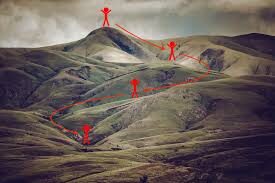 Encontrando o ponto mais baixo em uma paisagem montanhosa. (Fonte: Fisseha Berhane)
Encontrando o ponto mais baixo em uma paisagem montanhosa. (Fonte: Fisseha Berhane)El descenso de gradiente es un algoritmo de optimizaciónUn algoritmo de optimización es un conjunto de reglas y procedimientos diseñados para encontrar la mejor solución a un problema específico, maximizando o minimizando una función objetivo. Estos algoritmos son fundamentales en diversas áreas, como la ingeniería, la economía y la inteligencia artificial, donde se busca mejorar la eficiencia y reducir costos. Existen múltiples enfoques, incluyendo algoritmos genéticos, programación lineal y métodos de optimización combinatoria.... iterativo para encontrar el mínimo local de una función.
Para encontrar o mínimo local de uma função usando descida gradiente, devemos tomar medidas proporcionais ao negativo do gradiente (afastar-se do gradiente) da função no ponto atual. Se tomarmos medidas proporcionais ao gradiente positivo (movendo-se em direção ao gradiente), vamos nos aproximar de um máximo local da função, e o procedimento é chamado Ascensão gradiente.
Descida gradiente foi originalmente proposta por CAUCHY sobre 1847. Também é conhecida como a descida mais íngreme..
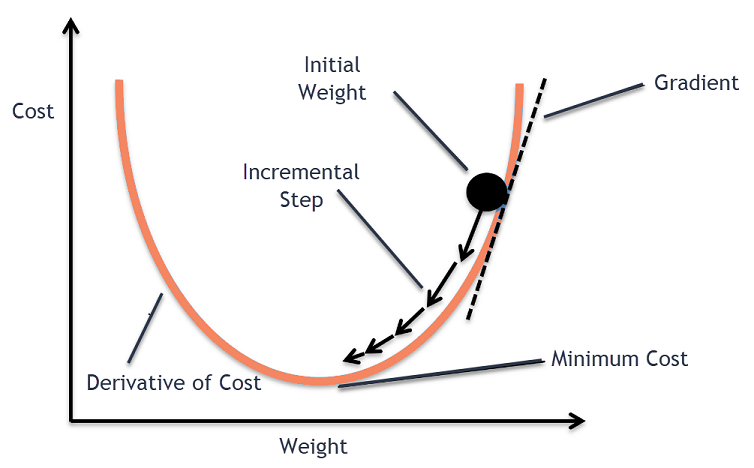
O objetivo do algoritmo de descida gradiente é minimizar a função dada (por exemplo, função de custo). Para alcançar esse objetivo, realiza duas etapas iterativamente:
- Calcule o gradiente (pendente), a derivada de primeira ordem da função naquele ponto
- Dê um passo (Mover) na direção oposta ao gradiente, a direção oposta da inclinação aumenta a partir do ponto atual em tempos alfa o gradiente naquele ponto

Alfa é chamado Taxa de aprendizagem – um parâmetro de ajuste no processo de otimização. Decida a duração dos passos.
Algoritmo de descida gradiente plotando
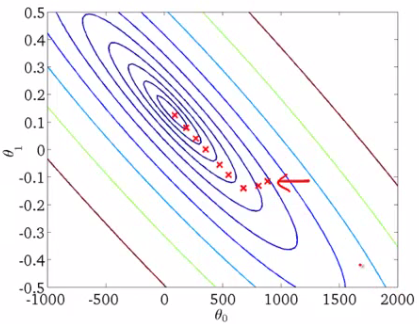
Quando temos um único parâmetro (theta), podemos graficar el costo de la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... dependiente en el eje y y theta en el eje x. Se houver dois parâmetros, podemos optar por um gráfico 3D, com custo em um eixo e ambos os parâmetros (Thetas) ao longo dos outros dois eixos.
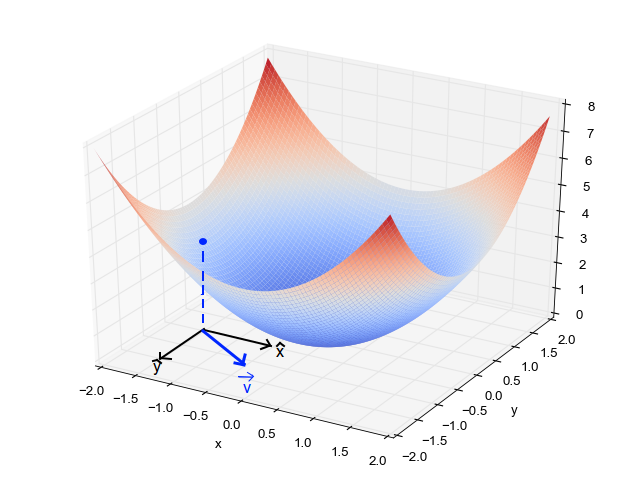
Ele também pode ser visto usando Contornos. Isso mostra um gráfico 3D bidimensional com parâmetros ao longo de ambos os eixos e a resposta como um esboço.. O valor de resposta aumenta longe do centro e tem o mesmo valor junto com os anéis. A resposta é diretamente proporcional à distância de um ponto para o centro (ao longo de uma direção).
Alfa – A taxa de aprendizado
Temos a direção em que queremos nos mover, agora devemos decidir o tamanho do passo que devemos dar.
* Deve ser escolhido cuidadosamente para acabar com os mínimos locais.
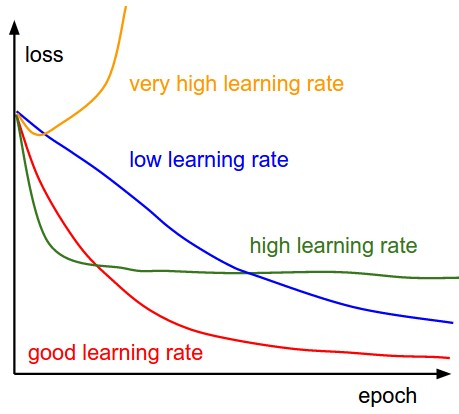
- Se a taxa de aprendizado é muito alta, Poderia EXAGERAR os mínimos e continuar saltando, sem atingir os mínimos
- Se a taxa de aprendizado é muito pequena, treinamento pode ser muito longo.
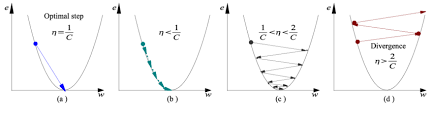
- uma) A taxa de aprendizado é ótima, o modelo converge para um mínimo
- b) A taxa de aprendizado é muito pequena., leva mais tempo, mas converge para um mínimo
- c) A taxa de aprendizagem é maior do que o valor ideal, excede, mas converge (1 / C <η <2 / C)
- d) A taxa de aprendizado é muito grande, ultrapasse e diverge, se afasta dos baixos, o desempenho diminui na aprendizagem
Observação: UMA mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que el gradiente disminuye mientras se mueve hacia los mínimos locales, tamanho do passo diminui. Portanto, a taxa de aprendizagem (alfa) pode ser constante durante a otimização e não precisa variar iterativamente.
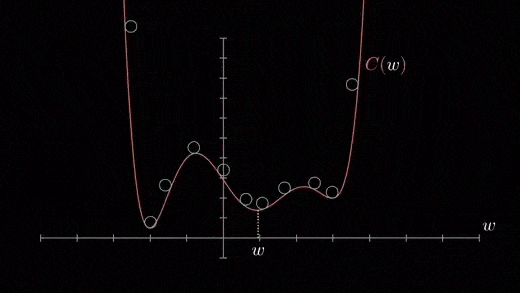
Mínimos locais
A função de custo pode consistir em muitos pontos mínimos. O gradiente pode resolver em qualquer um dos mínimos, que depende do ponto de partida (quer dizer, os parâmetros iniciais (theta)) e a taxa de aprendizado. Portanto, otimização pode convergir em diferentes pontos com diferentes pontos de partida e taxa de aprendizado.
Implementação de código de descida de gradiente em Python
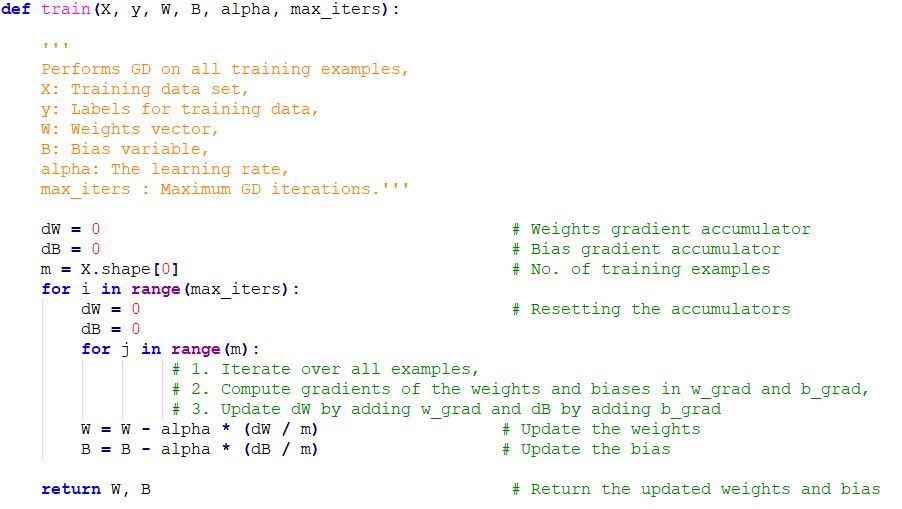
Notas finais
Uma vez que sintonizamos o parâmetro de aprendizagem (alfa) e temos a taxa de aprendizado ideal, começamos a iterar até convergir para baixos locais.





